1. 引言
单图像超分辨率重建(Single Image Super-Resolution, SISR)旨在从退化的低分辨率(Low Resolution, LR)图像中恢复相应的细节更丰富、视觉质量更好的高分辨率(High Resolution, HR)图像 [1]。近年来,基于深度卷积神经网络(Convolutional Neural Network, CNN)的SR模型因其在恢复或生成图像高频细节方面的显著性能而流行起来。虽然这些方法已经取得了不错的性能,但由于计算成本高、存储空间大等原因,并不能很好地应用于实际生活中。因此,在保持网络轻量化的同时又能获得更好性能的模型就成为了新的探索方向。常用的策略之一是引入递归机制,如DRCN [2] 和DRRN [3]。另一个是探索轻量化的网络结构,如CARN [4] 、IDN [5] 、IMDN [6] 、RFDN [7] 等。这些模型都专注于构建更高效的网络结构,在一定程度上减少了模型参数的数量,但也导致了性能的下降,难以重建出边缘细节丰富的图像。
近年来,随着自然语言处理(Natural Language Processing, NLP)中Transformer [8] 技术的不断发展,如何将其应用于计算机视觉任务已成为一个热门话题。Transformer可以对图像中的长期依赖性进行建模,这种强大的特征表示能力有助于恢复图像的纹理细节。虽然,基于Transformer的方法能够更好地提取图像中的长期依赖关系,但是CNN提取局部特征的能力仍是不可替代的,这些特征能够在不同的视角下保持自身的稳定性,有助于图像的理解和重建。因此,我们建议将CNN和Transformer融合,充分利用二者的优点,实现高效的SR图像重建。
为此,本文提出一个用于SISR的轻量级融合CNN-Swin Transformer网络(Lightweight Fusion CNN-Swin Transformer Network, LFCSTN)。在LFCSTN中,我们同时使用CNN和Swin Transformer [9] 来构建网络结构中的一个分支,称为轻量级融合CNN-Swin Transformer模块(Lightweight Fusion CNN-Swin Transformer Module, LFCSTM)。该模块主要由局部特征提取块(Local Feature Extraction Block, LFEB)、Swin-Transformer块(Swin-Transformer Block, STB)和增强空间注意力(Enhanced Spatial Attention, ESA) [10] 组成。对于CNN部分,我们专注于局部特征提取,LFEB主要由级联的卷积层、GeLU激活函数和高效通道注意力块(Efficient Channel Attention, ECA) [11] 组成。对于Transformer部分,我们利用Swin-Transformer的移动窗口机制来学习图像的长期依赖关系。然后,我们使用增强空间注意力(ESA)来进行上下文信息融合,从而利用学习到的局部信息和全局信息进一步细化纹理细节。同时,为了保留特征图的细节和边缘,我们基于Chen等人提出的动态卷积 [12] 思想设计了一个多路径动态卷积块(Multi-path Dynamic Convolution Block, MDCB)作为我们的边缘增强策略,这有助于图像的最终恢复质量。本文的主要工作:
1) 我们提出了一种新的轻量级混合模型用于SISR任务,将CNN和Swin Transformer相结合,有效的融合了图像丰富的局部和非局部特征。
2) 我们研究了动态卷积技术,并提出了一种面向边缘的多路径动态卷积块作为整体网络结构的一个分支,在可接受的计算成本内,有效提高了模型的性能,并取得了更自然的视觉效果。
2. 相关工作
2.1. 基于CNN的SISR
得益于CNN强大的特征表示能力,近年来基于CNN的SISR方法取得了很大的进展。例如,2014年,Dong等人提出的SRCNN [13] 首次将CNN应用于SISR,并在当时取得了极具竞争力的效果。2017年,Lim等人在EDSR [14] 中提出了一种增强残差块来训练深度模型,并且去掉了批量归一化层。为了建立更有效的SISR模型,RCAN [15] 提出了一种具有残差结构和通道注意力机制的深度残差网络。除了这些深度网络,近年来也提出了许多轻量级的SISR模型。例如,Ahn等人利用级联机制提出了CARN [4]。Zheng等人利用群卷积提出了IDN [5],结合短期和长期特征,对模型大小进行压缩。然后,他们改进了IDN的模型结构并提出IMDN [6],引入信息多蒸馏块,有效的提取了分级特征。Liu等人进一步将IMDN的信息多蒸馏块改进为残差特征蒸馏块提出了RFDN [7]。虽然这些模型都取得了较好的结果和视觉表现,但它们都是纯基于CNN的模型。这意味着它们只能提取局部特征,不能学习图像的全局信息,并不利于图像纹理和边缘细节的还原。

Figure 1. The complete architecture of lightweight fusion CNN-Swin Transformer network (LFCSTN)
图1. 轻量级融合CNN-Swin Transformer网络(LFCSTN)整体结构
2.2. 基于Transformer的SISR
Transformer在自然语言处理(NLP)中的突破启发了研究者们在计算机视觉任务中使用自注意力(Self Attention, SA) [8] 机制。Transformer中的SA机制可以有效地捕捉序列元素之间的长期信息,并在一些高级视觉任务中取得了令人映像深刻的结果,如图像分类,图像检测和分割。其中,ViT [16] 是第一个用Transformer代替标准CNN的工作。为了生成序列元素,ViT将2D图像块扁平化成一个向量并将它们输入到Transformer中。Chen等人提出的IPT [17] 是一个非常大的预训练模型,用于基于视觉Transformer的各种低级视觉任务中。Liang等人提出的SwinIR [18] 将Swin Transformer直接迁移到图像恢复任务中,并取得了很好的效果。Lu等人提出的ESRT [19] 通过轻量级Transformer和特征分离策略减少了GPU内存消耗。但这些模型都没有充分考虑将CNN和Transformer融合,很难在模型大小和性能之间达到最佳的平衡。
3. 本文方法
3.1. LFCSTN整体结构
如图1所示,LFCSTN主要有四个部分组成:浅层特征提取、轻量级融合CNN-Swin Transformer模块(LFCSTM)、多路径动态卷积块(MDCB)和图像重建。我们将
和
分别定义为输入LR图像和重建SR图像。首先,我们假设给定一个低分辨率图像
,其中H和W分别为LR图像的高度和宽度,C表示特征通道数。我们使用3 × 3卷积层从
中提取浅层特征
为
(1)
其中,
表示卷积层,
表示提取的浅层特征。然后将提取出来的浅层特征分别作为LFCSTM和MDCB输入
(2)
(3)
其中,
表示第n个LFCSTM模块的映射,
表示第n个LFCSTM的输出,
表示MDCB的映射,
表示MDCB提取到的边缘特征。然后,我们将
输入到一个卷积组中,进一步提取图像的深层特征
(4)
其中,
表示提取的深层特征,
表示用于提取图像深层特征的卷积组,主要由3 × 3卷积层和LeakyReLU激活函数组成。最后将
和
同时输入图像重建模块得到SR图像
。
(5)
其中
代表亚像素卷积层。关于LFCSTM和MDCB更详细的部分,我们将在之后的小节进行介绍。
3.2. Swin Transformer块(STB)
STB作为LFCSTM中的Transformer分支部分,结构如图2(b)所示。Swin Transformer的构建方法是将 Transformer 块中的标准多头自注意力(Multi-Head Self-Attention, MSA) [8] 模块替换为基于移动窗口的模块,其它层保持不变。首先,我们假设给定大小为
的浅层特征
作为STB的输入,Swin Transformer
将输入重塑为
的特征,方法是将输入划分为不重叠的
的局部窗口,其中
是窗口的总数。然后,再为每个窗口分别计算局部注意力,得到局部窗口特征
。对于局部窗口特征
,
查询、键和值矩阵:Q、K和V的计算公式为
(7)
(8)
(9)
其中
、
、和
是在不同窗口间共享的投影矩阵,
。
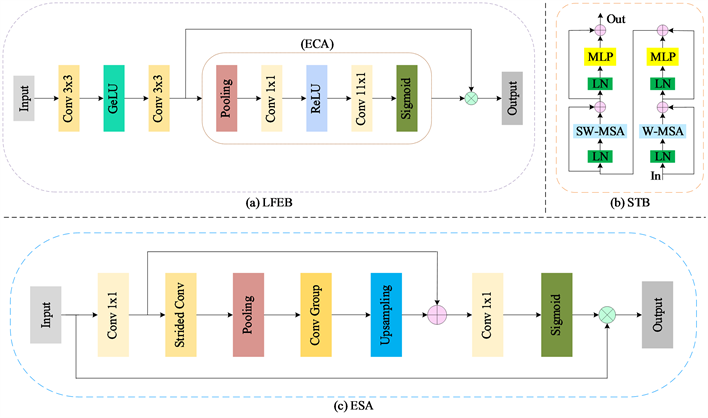
Figure 2. (a) Local feature extraction block (LFEB); (b) Swin Transformer block (STB); (c) Enhanced spatial attention (ESA)
图2. (a) 局部特征提取块(LFEB);(b) Swin Transformer块(STB);(c) 增强空间注意力(ESA)
然后,通过自注意力机制在局部窗口内计算注意力矩阵
(10)
其中B是可学习的相对位置编码,d为
维度。
接下来,使用一个多层感知机(Multi-Layer Perceptron, MLP)层进行进一步的特征转换,MLP由两个全连接(Fully Connected, FC)层和GeLU激活函数组成。在每个MSA模块和MLP层之前应用了层归一化(Layer Norm, LN)层,并对两个模块使用了残差连接,整个过程可以表示为
(11)
(12)
基于窗口的自注意力模块会缺乏跨窗口的连接,这限制了网络的整体性能。因为了引入跨窗口连接,同时保持非重叠窗口高效的计算能力,Swin Transformer的作者提出了一种移动窗口分区的方法。其中,W-MSA和SW-MSA分别表示使用规则和移动窗口的多头自注意力,同时移动窗口分区则意味着在分区之前将特征
移动
像素。
3.3. 局部特征提取块(LFEB)
LFEB作为LFCSTM的CNN分支部分,其主要作用是对输入图像的浅层特征
做进一步提取,逐步细化提取的特征,得到局部特征
。在卷积层部分,我们选择使用GeLU激活函数,相比于ReLU激活函数,GeLU激活函数引入了随机正则的思想,直观上更符合自然的认识。为了进一步提升特征的表达能力,考虑到模型的性能和复杂度,我们在卷积层之后引入了计算复杂度低且能保持高性能的高效通道注意力(ECA)机制,具体结构如图2(a)所示。同时,为了缓解梯度消失的问题,我们在卷积层之后加入了残差连接,LFEB的整体流程可以表示为
(13)
(14)
(15)
其中,
为ECA机制。当得到局部特征
后,我们利用增强空间注意力(ESA)块将
和
进行特征融合,从而得到更精确的特征,这一个步骤可以表示为
(16)
其中
表示ESA机制,结构如图2(c)所示。至此,我们得到了LFCSTM的输出
以作为后续模块的输入。

Figure 3. Multi-path Dynamic Convolutional Block
图3. 多路径动态卷积块(MDCB)
3.4. 多路径动态卷积块(MDCB)
针对参数量较少的轻量级网络,为了更好的学习图像的边缘信息,这需要对模型进行更精细的设计。Lu等人在ESRT中提出了使用高频滤波模块(High-Frequency Filtering Module, HFM) [19] 来保留特征图的细节和边缘,这不可避免的增加了模型的计算复杂度和特征冗余,从而导致视觉上不自然的SR图像。因此,我们基于动态卷积的思想,设计出了一个多路径动态卷积块(MDCB)作为整体模型的边缘增强分支,目的是有效的提取重要的边缘信息,同时过滤掉无用的特征。我们提出的MDCB以可接受的计算成本和参数量获得了比ESRT更好的性能和视觉效果。如图3所示,给定大小为
的浅层特征
作为输入
(17)
其中
表示1 × 1卷积层,我们利用1 × 1卷积层作为过渡层,得到过渡特征
,这便于后续更有效的提取特征。然后,我们将过渡特征
作为后续三条路径的输入,其中path1和path3由单个的3 × 3卷积层组成,path2为卷积组,由级联的3 × 3卷积层、LeakyReLU函数、1 × 1卷积层和Sigmoid函数组成。值得注意的是,path2和path3将通过逐元素相乘的方式进行特征聚合,再通过一个3 × 3卷积层输入到动态卷积部分。至此,我们通过多路径进行特征提取的流程可以表示为
(18)
(19)
其中,
和
分别表示经path1、path2和path3得到的特征信息,
、
和
分别表示path1、path2和path3路径。在获得
和
后,我们采用动态卷积来进行边缘信息的学习。如图3中Attention部分所示,利用注意力机制得到接下来每个卷积核的权重。Attention部分与SENet [20] 类似,不同点在于最后采用SoftMax函数来生成两个自适应权重,动态的调节卷积核参数来提取图像的边缘特征。给定输入过渡特征
,动态卷积的具体操作如下
(20)
(21)
其中,
表示全局平均池化(Global Average Pooling, GAP)操作,
表示全连接层,
表示ReLU函数,
表示SoftMax函数。
和
分别表示两个自适应权重值。最后,我们通过一个残差连接得到边缘特征
用于SR图像重建。
4. 实验
4.1. 数据集和评价指标
在本文研究中,我们使用包含800张训练图像的DIV2K [21] 数据集来训练我们的LFCSTN模型,并使用了5个基准数据集,包括Set5 [22] 、Set14 [23] 、BSD100 [24] 、Urban100 [25] 和Manga109 [26] 进行性能比较。本文采用PSNR和SSIM作为评价指标,评价SR图像在YCbCr颜色空间Y通道上的性能。为了进行性能的比较,我们也提供了模型的参数数量作为参考。
4.2. 训练细节
在训练过程中,我们采用水平翻转和垂直翻转进行数据增强。与此同时,模型使用Adam优化器进行训练,
,
,学习率设置为5 × 10-4。损失函数采用L1损失函数,与L2损失函数相比,它可以产生更清晰的图像。然后,我们在PyTorch框架下使用一个NVIDIA TITAN RTX显卡进行模型的训练。
4.3. 与各SISR模型对比
在表1中,我们将LFCSTN与其他SISR模型进行了比较:VDSR [27] 、LapSRN [28] 、EDSR [14] 、CARN [4] 、IMDN [6] 、RFDN-L [7] 、ESRT [19]。其中,CARN、IMDN、RFDN-L、ESRT为轻量级SISR模型。显然,我们的LFCSTN在所有放大倍数下都获得了最好的客观评价指标结果。可以看出,虽然CARN在性能上接近我们的LFCSTN,但它的参数数量几乎是LFCSTN的三倍。同时,RFDN-L和ESRT的参数数量接近LFCSTN,但LFCSTN取得了比它们更好的结果。此外,我们可以观察到LFCSTN在放大倍数×3上取得了最好的结果,这证明了我们的模型的有效性。

Figure 4. Visual comparison with SISR models
图4. 与各SISR模型的可视化比较

Table 1. Qualitative and quantitative comparisons with SISR models show the best results in bold
表1. 与各SISR模型定性定量比较,最好的结果已加粗表示
在图4中,我们还提供了LFCSTN与其他SISR模型在放大倍数×4上的视觉比较。视觉上容易观察到,RFDN-L的效果是和我们最接近的,但其重建出的SR图像仍然存在着部分伪影。而我们的LFCSTN重建的SR图像则包含更少的伪影和更丰富的纹理细节,尤其是边缘和线条。这得益于我们提出的面向边缘的MDCB带来的提升,它可以学习到图像更多的边缘信息。这进一步验证了我们提出的LFCSTN的有效性。

Figure 5. The trade-off between the number of model parameters and performance on Urban100 (×4)
图5. 在Urban100 (×4)上模型参数数量和性能之间的比较
此外,如图5所示,我们还提供了模型参数数量和性能之间的权衡分析可视化。显然,我们可以观察到LFCSTN在模型的大小和性能之间实现了更好的平衡。
4.4. 消融实验
为了验证我们提出的MDCB以及LFCSTM组件的有效性,我们设计了3组对比实验。在表2中,我们分析了使用和不使用各组件的模型的性能。可以看出,在边缘信息最丰富的Urban100数据集上,我们的LFCSTN如果去掉MDCB,PSNR值明显从26.49下降到26.25,这说明我们提出的MDCB可以很好的处理和学习复杂图像的边缘信息,从而提升模型的重建效果。
5. 结论
在这项工作中,我们为SISR任务提出了一种轻量级融合CNN-Swin Transformer网络(LFCSTN)。LFCSTN首先通过STB来学习图像特征的长期依赖性,再利用LFEB来提取图像的局部信息,并通过增强空间注意力机制(ESA)进行特征融合。另外,我们提出了一个多路径动态卷积块(MDCB)以较低的计算成本来学习图像的边缘特征,并取得了较好的视觉效果。大量实验表明,我们的LFCSTN不仅在模型性和计算成本之间取得了最好的结果,而且重建出的SR图像的具有清晰的纹理和边缘细节,整体画面更佳真实且自然。
Table 2. Effects of components on model performance on Urban100 (×4)
表2. 在Urban100 (×4)上各组件对模型性能影响
基金项目
四川省科技厅项目(编号:2021Z005)。
NOTES
*通讯作者。