1. 引言
精算学是一个在不断发展的领域,涉及保险风险的评估,其中车辆保险是为汽车、卡车、摩托车和其他公路车辆设计的保险,它不仅为交通碰撞造成的车辆损坏和人身伤害提供财务保护,而且还对冲了交通事故中可能出现的责任车辆保险。随着科技的进步,汽车在人民的生活中已越来越普及了,保费也在持续增长,车辆保险在非寿险业务中发挥着极其重要的作用,因此研究和改善汽车保险问题已成为学术界共同关注的问题,保险公司对投保人的纯保费由两部分组成:索赔概率和期望索赔额,本文对车险索赔概率进行研究。建立预测模型时,很少有文献会考虑多重共线性,模型的过拟合,即使有研究结合了Lasso和Logistic模型来消除多重共线性与模型过拟合,却也忽略了预测因子间水平结构的不同,对所有类型的预测因子都施加相同的惩罚,我们的研究考虑到预测因子具有不同的水平结构,对不同类型的预测因子选择最适合的正则设置,同时引入了惩罚权重,来提高惩罚的性能。
在现有文献中,Logistic回归模型在保险与精算领域的应用受到了越来越多的关注,近几年已经取得了一些较好的研究成果,张连增和孙维伟(2012) [1] 年运用Logistic模型分析了车险索赔概率的影响因素,通过分析得出驾驶人年龄、行驶区域、车辆类型、车辆价值等因素对于汽车是否出险具有显著影响。孟生旺等(2017) [2] 对车险索赔概率分别建立了神经网络模型与广义线性模型,对以上两种模型进行比较,得出结论:神经网络模型对数据要求小,预测精度高,但缺点是建模类似一个黑匣子,结果缺乏可解释性。广义线性模型操作简单,可解释性强,但模型对原始数据有较多要求。王冲(2017) [3] 分别从汽车因素、驾驶人因素两大方面进行研究,基于汽车是否出险,建立了Logistic回归模型,探究影响汽车出险的因素以及各变量的重要程度,并进一步运用树模型分析了各因素之间的交互效应,从而对Logistic回归模型进行了优化。郑俊卿(2018) [4] 将Lasso回归和GLM模型相结合来预测车险索赔频率,将改进后的模型与GLM模型进行比较,结论显示改进后的模型的性能更好。卢志义和蔡静(2017) [5] 将驾驶员的性别、车型等8个变量作为预测因子,分别建立了车险索赔概率估计的Logistic回归模型和广义可加模型,结果表明,对于离散型费率因子占绝大多数的车险数据,广义可加模型并不具有明显的优势,因此在车险费率厘定实务中,若离散型费率因子较多,应选择结构相对简单的Logistic回归模型。Oelker和Tutz (2017) [6] 将多类型正则化扩展到GLM模型中,使得惩罚迭代加权最小二乘(PIRLS)算法适用于正则化GLM模型。Devriendt等(2021) [7] 设计了一种更有效的校准策略,适用于不同预测因子类型和更一般的损失函数的正则化,将方法应用在车险索赔次数的预测中,其效果要优于广义可加模型。很多研究在建立车险索赔概率预测模型时,会忽略变量之间的多重共线性和模型的过拟合,或者使用Logistic模型结合单一类型的Lasso回归来解决变量的多重共线性或模型过拟合,忽略了变量之间水平结构的不同。同时Lasso回归只是孤立的考虑各个变量,未考虑到各个变量之间的有序性,因此,本文使用Lasso及其扩展方法结合Logistic回归模型建立索赔概率预测模型,并将其与Lasso-Logistic回归模型与Logistic回归模型进行比较。
2. 模型介绍
2.1. Logistic回归模型
Logistic回归模型是一种因变量为分类变量的模型。在车险保单组合中,假设个体保单之间相互独立,每份保单是否发生索赔可以表示为一个二分类随机变量,服从伯努利分布,发生索赔的概率函数如下式所示。
, (1)
将上式进一步变换可得
, (2)
其中,
为车险索赔概率的影响因素,J表示影响因素的个数,在本文中共有9个影响因素,因此
,其中x1表示车龄,x2表示驾驶人年龄,x3表示奖惩水平,x4表示人口密度,x5表示车辆马力,x6表示车辆品牌,x7表示燃料类型,x8表示居住地区,x9表示暴露期,P表示索赔发生的概率,
表示截距项,
表示第j个车险索赔概率影响因素的回归系数,Y为响应变量,
表示发生索赔,
表示未发生索赔。
2.2. Lasso及其扩展
Lasso:Lasso惩罚将
范数应用于预测系数,其表达式如下
, (3)
表示第
个车险索赔概率影响因素的第i个水平,
表示第
个车险索赔概率影响因素中的水平个数,
表示第
个车险索赔概率影响因素的第i个水平的惩罚权重,对于由一个系数表示的连续预测变量或二元预测变量,最重要的预测因子获得非零系数。
Grouplasso:Grouplasso惩罚使用
范数,其表达式如下
, (4)
该惩罚适用于确定
是否具有足够的整体预测能力,Grouplasso惩罚对于选择有序或名义预测变量特别有用,当将其应用于有序或名义预测值时,Grouplasso不需要参考类别。
Fuse lasso:将预测值中的连续级别进行分组,Fuselasso惩罚会对后续系数之间的差异进行
惩罚,其表达式如下
, (5)
这种惩罚适用于有序变量和编码为有序变量的连续型预测变量,以捕捉非线性效应,对于有序变量,相邻预测变量的作用往往相同或者相近,因此Fuselasso在进行变量选择的同时,对相邻参数的差进行收缩,以达到相邻参数相同或相近的目的。
Generalized fused lasso:Generalized fused lasso允许用户设置一个图M (在R语言中的smurf包中自动实现),该图指示哪些系数差应被正则化,其表达式如下
, (6)
对于空间预测变量(二维预测变量),Generalized fused lasso调整了共享物理边界的城市的系数差异,对于没有任何潜在结构的名义预测值,可以使用图对所有可能的系数差异进行正则化。
2.3. 自适应惩罚权重
一个好的变量选择方法应该具有神域性质,该性质包含两层含义:模型估计的相合性,参数估计的相合性。然而Lasso并不具备这些性质,为了克服Lasso这一性质,Zou (2006) [8] 提出了自适应Lasso,自适应Lasso被定义为:
,其中
为调谐参数。直观上,这些权重以初始估计量的形式将惩罚“适应”于数据驱动的先验信息。在本文中,我们参照Gertheiss和Tutz (2010) [9] 那样设置
,并在表1中列出特定惩罚的自适应权重。
3. 实证分析
3.1. 变量来源及说明
本文采用的是法国的一组车险索赔数据,来源于R中的maidrr包,该数据集包含668,892个观测值,10个变量:nclaims表示索赔频率,power表示车辆马力(马力越大,极速越大),bm表示奖惩水平(奖惩水平越低表明驾驶员的索赔历史记录越好),brand表示车辆品牌,fuel表示燃料类型,agep表示驾驶人年龄,agec表示车龄,expo表示风险暴露期,Popden表示人口密度,region表示居住地区,表2为变量说明表:
3.2. 因素分析
对于车险索赔概率的因素分析,连续型和有序型变量运用箱线图进行初步分析。
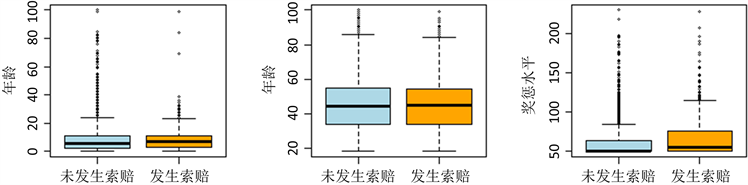 (a)(b)(c)
(a)(b)(c) 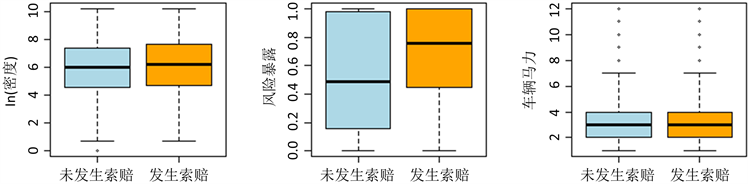 (d)(e)(f)
(d)(e)(f)
Figure 1. Automobile insurance claim factor diagram
图1. 车险索赔因素图
图1中箱子中间的一条线,是数据的中位数,代表了样本数据的平均水平,箱子的上下限,分别是数据的上四分位数和下四分位数,因此,箱子的宽度在一定程度上反映了数据的离散程度,根据图1(a)、图1(b)、图1(f)可以看出未发生索赔的驾驶人驾龄、年龄、车辆马力的中位数和发生索赔的驾驶人驾龄、年龄、车辆马力的中位数大致相等,且箱体宽度相同,因此驾驶人驾龄、年龄、车辆马力在索赔和未发生索赔两种情况下的分布大致相同,根据图1(c)可以看出发生索赔的驾驶人奖惩水平的中位数要高于未发生索赔的驾驶人奖惩水平的中位数,且在发生索赔情况下的箱体要宽于未发生索赔情况下的箱体,因此在发生索赔情况下奖惩水平的分布更加离散,根据图1(d)可以看出发生索赔的驾驶人居住地区密度的整体水平要略高于未发生索赔的驾驶人居住地区密度的整体水平,因此人口密度高的地区的驾驶人更容易发生索赔,根据图1(e)可以看出发生索赔驾驶人的风险暴露期要明显高于未发生索赔驾驶人的风险暴露期,值得注意的是发生索赔和未发生索赔二者的样本分布是不平衡的,因此以上分析的差异是否显著需要通过进一步建模进行判断。
3.3. 车险索赔概率预测模型的建立
Logistic回归的损失函数:
, (7)
n表示保单数量,
表示第
份保单是否发生索赔,
表示参数向量,
表示第t份保单的自变量观测值。
Multiple-Lasso-Logistic即在Logistic回归的损失函数上添加惩罚函数,根据不同的变量类型,在式(3)、(4)、(5)、(6)中选择适合的惩罚函数。在进行参数估计时,通过压缩系数实现对变量的选择,将没有预测能力的变量压缩为0,得到解释能力较强的变量,则Multiple-Lasso-Logistic回归模型中的系数估计值
可以写成如式:
, (8)
根据各个变量的水平结构,我们对二元预测变量燃料类型(当
时)应用Group lasso惩罚,对连续变量车龄,驾驶人年龄,车辆马力,奖惩水平,人口密度,暴露期(当
时)进行分箱处理后应用Fused lasso惩罚,其考虑到了变量之间的次序作用,对名义变量居住地区、车辆品牌(当
时)应用Generalized fused lasso,同时引入惩罚权重,本文使用表1中的自适应惩罚权重。
Fused lasso适用于有序型变量或编码为有序变量的连续型预测变量,因此本文需要对连续型变量进箱处理,进行分箱处理时须确保每一水平中的样本量不可以过少,若某一水平的样本量过少则会影响预测的精度,同时有效的分箱处理也可以提高模型的预测效果,若人为的采取等距分箱,或是主观的进行分箱,得到的不一定是最优分箱,因此本文采用R中的smbining包,基于监督离散化,利用递归分区来将数字特征分类,根据smbinning自带的ctree算法进行分裂,找出最优分割点,然后计算IV值,计算方式如下
, (9)
, (10)
其中Positivek表示经过smbining包分箱后第k组中发生索赔的样本数量,Positive表示所有组中发生索赔的样本数量,Negativek表示第k组中未发生索赔的样本数量,Negative表示所有组中未发生索赔的样本数量。N表示分组的数量,经过计算可知,车龄的IV值为0.0446,奖惩水平的IV值为0.1190,年龄的值IV值为0.0198,人口密度的IV值为0.0131,可知车龄的分箱效果最好,人口密度的分箱效果最差,分箱情况如表3。

Table 3. Bin table for continuous variables
表3. 连续变量的分箱表
在对连续型变量分箱后,采用10折交叉验证法来确定调节参数
,数据集被分成10个不相交的集合,我们将其中9个集合组成的训练样本来建立模型,然后使用剩余的集合(即验证样本)来计算误差度量。重复10次,这样每个集合正好用作验证样本一次,这10个误差测量值的平均值用作
值的误差测量值。
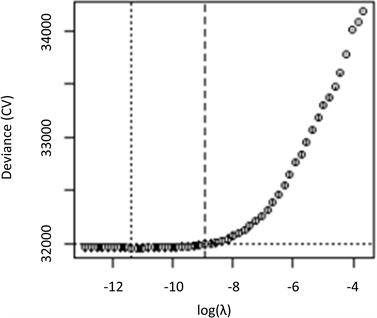
Figure 2. Diagram of harmonic parameters and deviations
图2. 调和参数和偏差的关系图
图2纵轴表示模型的偏差,横轴为
,图中每个点表示调和参数
取值对应的偏差值,随着
的变大,惩罚力度也会变大,于是便有更多的系数值被压缩为0,因此需要找到一个合适的
值,可以看出随着调和参数
值的增加,偏差逐渐变小,图中两条虚线分别表示lambda.min和lambda.1se,本文选取后者,即一个方差范围内最精简模型的
值,即
,得到
值后,利用R软件的smurf包建立多类型Lasso的Logistic回归模型,模型的参数估计值如表4所示。
从表4可以看出,有参数估计和参数再估计两列数据,参数估计是有惩罚的情况下得到的参数估计
值,因此会有一定偏差,再估计值根据参数估计的结果,将系数被压缩为0的变量去除,然后不设置惩罚,重新估计的系数将具有与正则化估计相同的非零和融合系数,但不会有偏差。
根据上表可得:
, (11)
将上表参数可视化,可以更加清楚地看出各个变量对索赔是否发生的影响。
根据图3(a)可以看出,相对于驾龄低的驾驶人,驾龄高高的驾驶人发生索赔概率更低,图3(b)显示了年老的司机发生索赔的概率更高,因此保险公司需承担更高的风险。图3(c)的趋势总体是呈上升的,具有高奖惩水平(索赔历史记录越差)的驾驶人发生索赔的概率越高,图3(d)表明人口密度高的地方更容易发生索赔,因此对保险公司来说风险更高,图3(e)显示动力强劲的汽车比动力较弱的汽车具有更高的风险,图3(h)显示居住地区的系数大多数被压缩为了0,因此对索赔是否发生的影响不大,但可以看出编号为R73的地区不容易发生索赔,编号为R74和R82的地区相对于其他区更容易发生索赔,从参数估计图中可以看出很多水平进行了融合,与标准GLM相比可以很好地(并且自动地)降低了维度(图3)。
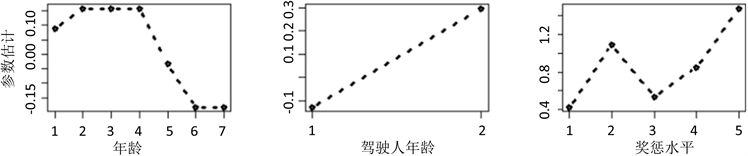 (a)(b)(c)
(a)(b)(c) 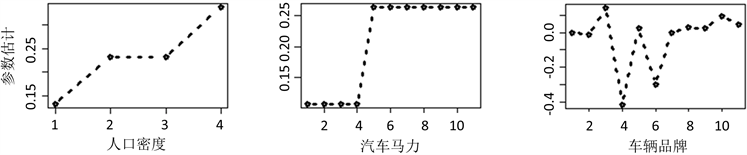 (d)(e)(f)
(d)(e)(f) 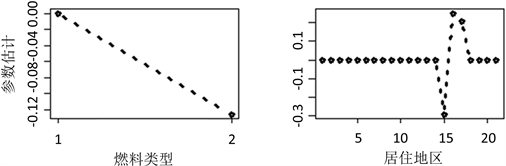 (g)(h)
(g)(h)
Figure 3. Parameter estimation plot
图3. 参数估计图
3.4. 模型的评价与比较
本文在比较不同模型的拟合效果时主要采用赤池信息准则(AIC),和贝叶斯信息准则(BIC),即如下:
, (12)
, (13)
其中k是模型参数个数,L是对数似然函数,n为样本数量,赤池信息准则(AIC)提供了权衡估计模型复杂度和拟合数据优良性的标准,BIC信息准则与AIC相似,用于模型选择,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,表5为各个模型的AIC,BIC值,可以看出Multiple-Lasso-Logistic模型表现的最好。
Table 5. AIC and BIC comparison table for each model
表5. 各个模型的AIC和BIC比较表
AUC是二分类模型的评价指标,是ROC曲线下方的面积,ROC曲线由两个变量TPR和FPR组成,这个组合以FPR对TPR,即是以代价对收益。
x轴为假阳性率(FPR):所有的负样本中,分类器预测错误的比例
, (14)
y轴为真阳性率(TPR):所有的正样本中,分类器预测正确的比例
, (15)
AUC的范围为0到1之间,AUC值越接近1,模型的预测效果越好,表6表示各个模型的AUC。
Table 6. AUC comparison table for each model
表6. 各个模型的AUC比较表
标准的Logistic回归模型会将所有变量纳入模型中,因此也会纳入一些不显著的变量,可能会扭曲参数的估计结果,Multiple-Lasso-Logistic会针对到变量的水平结构,对其应用合适的正则化方法,将预测能力弱的变量压缩为0,筛选出预测能力最强的变量,同时还能将作用相同水平进行融合,有效地降低了变量维度,根据表5,表6可以看出,Multiple-Lasso-Logistic回归模型的AIC和BIC都是最小的,其AUC值和Logistic回归模型的大小相同,结合以上三个模型评价指标可得Multiple-Lasso-Logistic回归模型的性能最优。
4. 小结
研究车险索赔概率时,现有文献中,对于处理多重共线性以及模型过拟合问题时,大多文献未考虑到车险因子水平结构的不同,本文针对不同结构的车险因子水平,采用Lasso及其扩展方法选择具有预测能力的因子。本文对法国的一组车险索赔数据分别建立了logistic回归模型,Lasso-Logistic回归模型,Multiple-Lasso-Logistic回归模型,结果表明Multiple-Lasso-Logistic回归模型性能最优。标准的logistic回归模型会将不显著的变量也纳入模型中,往往会扭曲参数估计的结果,因此本文使用lasso及其扩展方法来改进logistic回归模型,相比于lasso回归考虑到了变量之间水平结构的不同。
本文利用AIC,BIC,AUC三个评价指标对模型的性能进行评价,Multiple-Lasso-Logistic回归模型不仅可以筛选出预测性能最高的变量,且可以将作用相同的水平进行融合,有效地降低了变量维度,使模型变得更精炼。同时Multiple-Lasso-Logistic回归模型可以帮助保险公司有效识别风险,进行风险分类,对不同风险级别的被保险人采用不同的保费策略提供一定的参考价值。