1. 引言
文本情感分类是自然语言处理的重要研究方向。随着大数据时代的到来,互联网上的时事和网购评论等文本数据呈爆炸式增长 [1] ,其中蕴含着大量带有情感色彩的文本数据。通过对这些数据挖掘和分析,可以更好地了解民众对于公共事件的看法及购物者给予商品的评价,有助于政府舆情管控和商户商业决策 [2] ,因此对文本数据进行情感分类研究具有重要意义。
2. 相关工作
文本情感分类的早期研究主要基于词典、规则以及传统机器学习方法。Bhutekar等人 [3] 将文本句子拆分为单词并通过搜索情绪词典找到相应的标签类别,然后对词标签进行分类得到情感类别。郑等人 [4] 聚焦于微博的文本顺序和话语结构,将每条微博文本看作一个数据序列,利用从数据集中挖掘的类序列规则(Class Sequence Rule, CSR)提取有效特征来支撑模型训练。然而,在面对复杂的文本数据时,设计词典、规则以及提取人工特征的方法耗时费力且泛化性差。
近年来,深度学习方法成为文本情感分类的主流 [5] ,该方法通过自身误差在神经网络模型中反向传播来训练模型,训练目标集中在如何获取表义丰富的文本特征。例如,柴源 [6] 采用Word2Vec模型学习图书评论的文本特征表示。而刘等人 [7] 以CNN-BiLSTM模型为基础融合词/句级特征来增强语义信息和丰富情感特征。此外,Pei等人 [8] 还将词性标注和情感极性信息融入预训练模型,以增强文本语义中的情感信息。然而,上述模型都是把文本当作单词序列处理,忽略了文本的句法信息。
句法信息能够直接揭示句子各组成成分之间的依存关系,有助于帮助情感分类模型关注情感关键词 [9] 。图1展示了样例文本“我当时真害怕极了”对应的句法依存树,从该句法依存树可以发现“害怕”一词位于句法依存树的中心位置,其与句中所有单词都存在着依存关系,并且中心词“害怕”能够体现整个句子的情感,因此句法信息对于情感分类任务十分重要。

Figure 1. An example of the dependency parsing tree
图1. 句法依存树样例
像LSTM (Long Short-Term Memory)这样的模型虽然能够处理文本序列信息,却无法直接处理句法信息这类树型结构数据。针对树或者图这一类数据的分析处理,Kipf等人 [10] 提出了图卷积神经网络模型(Graph Convolution Networks, GCN)。随后在情感分类任务中,以句法依存树为主要输入的GCN模型受到广泛关注。其中,Lai等人 [11] 提出一种中文细粒度情感分类模型Syntax-based GCN,该模型使用GCN处理句法信息,利用句子成分依存信息发掘能体现句子情感的情感关键词,在中文微博情感分类任务中取得了SOTA。随后,Shou等人 [12] 在Lai等人研究基础上,提出一种面向对话细粒度情感识别任务的分类模型DSAGCN,该模型是在文本编码器后直接添加注意力层来增强模型学习语义信息,通过增强语义信息来帮助模型学习句法信息,进而使得模型更有效地利用句法依存信息发掘情感关键词。由此可见,使用GCN处理树型结构的句法信息可以从句法依存关系角度捕获情感关键词,进而有助于提高情感分类任务的性能。
使用GCN建模句法信息可以从句子成分依存方面获取情感关键词,然而在情感分类任务中仅使用句法信息来发现情感关键词是过于单一的,并且在该类模型中文本编码器(例如BiLSTM)提取的上下文语义向量的主要作用是辅助GCN学习句法信息,忽略了进一步利用语义信息来从上下文语义角度发掘对情感分类任务起到重要作用的语义情感关键词。句子中细粒度的语义情感词能体现句子情感极性,其对情感分类任务的作用是不可忽视的。现有研究主要利用注意力机制来发掘文本中的语义情感词 [13] [14] 。Zhang等人 [13] 使用注意力机制识别句子中多个语义情感段,并将其与目标词语义特征进行融合来增强目标词的情感信息,最后对目标词进行情感分类。Later等人 [14] 提出了自注意力网络SANet,在情感分类实验中验证了SANet可以通过相邻单词交互发现语义情感词。由此启发,本文在引入GCN来建模句法信息的同时增加一条使用注意力机制的通道,使得模型具有关注语义情感关键词的能力。文本使用自注意力机制从上下文语义角度发掘对情感分类任务贡献大的词,并赋予较高权重,最后相加加权后的所有词向量作为句子情感向量表示,进而增强模型对语义信息的挖掘。
另外由于标注数据的成本高,现有中文情感数据集缺少句法标注信息,所以在现有研究 [15] [16] [17] 中,依存句法树的建立主要通过使用开源工具(例如:LTP [18] , Spacy等)得到,这些工具的使用无法确保任何时候建立的句法分析结果的准确性,而错误的句法信息将最终影响模型的性能。基于以上研究现状,本文提出一种面向细粒度情感分类任务的双通道分类模型(DCGCSA, Dual Channels of Graph Convolution and Self-Attention),在从句法依存和上下文语义两个角度发掘情感关键词的过程中,尽可能降低错误句法信息对情感分类任务的负面影响。该模型是双通道分类结构,一条通道注重于建模情感分类相关的句法信息,另一条通道注重于从上下文语义信息中筛选出关键的语义情感词,最终的分类结果通过一个权重系数来权衡。结合双通道分类结果能使模型分类性能不取决于单一的某个通道性能,从而在从两个方面获取情感关键词信息同时减弱开源工具带来的负面影响。本文贡献有以下三个方面:
1) 提出一种双通道分类模型DCGCSA,该模型通过双通道机制不仅可以根据句法依存和上下文语义捕获情感关键词来提高分类性能,还可以使用双通道机制减弱错误的句法信息带来的影响。
2) 增加一条使用注意力机制的通道。模型不仅可以利用编码器获得的基本语义向量来帮助学习句法信息,还能够更加充分利用基本语义向量关注对情感分类任务贡献大的语义情感关键词,增强模型发掘情感信息的能力。
3) 引入通道权衡系数,优化了双通道机制,权衡通道对情感分类结果的贡献,使得模型获取更多有效的情感信息。
3. 双通道分类模型
由于GCN对计算机算力要求较高,考虑设备性能和模型训练时间,DCGCSA采用算力要求不高的BiLSTM作为编码器,通过共享编码器句法情感关键词通道网络(Syntactic Dependency Sentiment Keywords Channel Networks, SDSK)和语义情感关键词通道网络(Syntactic Sentiment Keywords Channel Networks, SSK)的双通道分类,总体框架如图2所示。
3.1. 文本编码器
BiLSTM是RNN (Recurrent Neural Networks)的一种,它由双向LSTM构成,从正向和反向两个角度更好地学习文本句子的上下文语义信息。本文使用BiLSTM作为文本编码器,提取文本语义信息。对于给定文本句子序列
,BiLSTM输出的结果是包含语义信息的特征向量公式(1):
(1)
其中
表示文本句子序列中的每个词,
表示文本句子序列的长度,
表示编码器生成的词特征向量,
为词嵌入维度,
表示编码器生成的句子的特征向量。
3.2. 句法情感关键词通道网络
对于情感分类任务,句法依存树能在句法依存关系上关注到对任务重要的词语。句法依存树的节点为词语,节点与节点的连接表示词与词之间的依存关系。模型针对句法依存树构建一张图
。其中,V是句法依存树中所有词组成的节点集,E是包含两个词之间所有依存关系的边集。节点与文本特征向量
存在一一对应关系。根据Kipf等人 [10] 和Marcheggiani等人 [19] 的研究,在依存关系中增加词自身依存和反向依存可以增强GCN的泛化能力。因此使用“0”、“1”、“1”、“1”分别标记无依存关系、自身依存关系、头到依存和依存到头的依存关系类型。依存关系通常以邻接矩阵形式输入模型,根据上述规则,生成句法邻接矩阵A (图3)。

Figure 3. An example of the dependency parsing tree and adjacent matrix
图3. 句法依存树及其邻接矩阵示例
之后GCN利用句法邻接矩阵A获取具有文本深层情感信息的句子特征Z,见公式(2):
(2)
其中,
代表激活函数,
为A的度矩阵,
为GCN神经网络的训练参数。
为了减少计算量和防止过拟合现象,将句子特征表示Z经过最大池化层得到
。再将
输入全连接层得到情感标签
(公式(3))。其中,
,
:
(3)
其中,M为预测情感类别的类别数量,
为全连接层的权重参数,
为全连接层的偏置。
3.3. 语义情感关键词通道网络
自注意力机制利用上下文语义信息使得文本序列中的每个单词关注序列中的其他单词,通过单词与单词之间的交互赋予含有情感信息的单词以其较高的注意力权重。对文本序列的每个文本符号,自注意力机制首先获取对应位置的查询矩阵Q、键矩阵K、值矩阵V,见公式(4),其中,
:
(4)
利用查询矩阵Q和键矩阵K计算单词与单词相互之间的注意力权重矩阵,并将其加权到值矩阵V (公式(5)):
(5)
加权词嵌入相加得到句子语义情感嵌入(公式(6)),其中
,
:
(6)
最后将
输入至全连接层得到情感标签
(公式(7)),其中
:
(7)
其中,
,
分别为全连接层的权重和偏置。
3.4. 损失函数
为了使SDSK和SSK联合且有效发挥作用,将两个通道的输出相加并过
得到模型预测的最终标签y (公式(8))。其中,
是通道的权衡系数。
(8)
DCGCSA使用交叉熵损失来优化SDSK和SSK的参数。为了控制梯度消失和梯度爆炸问题,DCGCSA使用随机正交矩阵初始化BiLSTM的权重矩阵,并在损失函数中加入正交化约束(公式(9)):
(9)
其中,N是样本数量,i代表样本索引,c代表情感类别标签,
。
是符号函数,如果索引为i样本的真实类别为c取1,否则取0。
表示预测索引为i样本属于类别c的概率,
是正则化系数,I是单位矩阵,W为BiLSTM的权重矩阵,通过对随机矩阵进行奇异值分解,获得的正交或近正交矩阵初始化W。
3.5. 伪代码
为了更好地说明DCGCSA模型的实现细节,本小节展示模型训练的伪代码如图4所示。

Figure 4. Pseudo code diagram of DCGCSA
图4. DCGCSA伪代码示意图
4. 实验设计及结果分析
4.1. 数据集及性能指标
本文实验采用Lai等人 [11] 文献提供的数据集和SMP2020数据集,Lai [11] 数据集由公开数据集中文计算会议测评的微博情感数据NLPCC2013和微博爬取数据构成,SMP2020数据集来自公开数据集第九届全国社会媒体处理大会会议测评的微博情绪分类数据集。实验中除去SMP2020数据集中的中性标签(无情感标签),并按照官方给定的训练集和测试集作为实验的训练集和测试集。表1是数据集Lai [11] 和SMP2020的统计信息,数据集Lai [11] 包含7类情感标签,数据集SMP2020包含5类情感标签,其中带有N/A标号的表示数据集缺失该类别情感标签:

Table 1. The statistics of the datasets
表1. 数据集统计信息
在细粒度情感分类性能评估中,采用常用的
值和
值作为评价指标。
值反映模型对各个情感类别的分类性能,
值反映模型对数据集整体的分类性能。
4.2. 实验配置及超参数设置
本文实验配置:操作系统Ubuntu16.04,CUDA 10.2,编辑环境Python3.7.9,深度学习框架Pytorch1.4.0,CPU为Intel(R) Core(TM) i9-9900k CPU @ 3.60 GHz,GPU为GeForce RTX 2080Ti。DCGCSA的超参数设置如表2所示:
Table 2. The hyper-parameters of DCGCSA
表2. DCGCSA模型超参数
除表2中参数设置外,本次实验还需要调优通道权衡系数
和正交化约束系数
。调优过程:先令
,调整
(
的取值从0到1,步长为0.1),然后修改
(
的取值从0到
,步长为10的负幂次方),再次调整
。经过参数调优,确定在不同数据集中最优通道权衡系数
和最优正则化系数
:在
、
时,使得DCGCSA在数据集Lai [11] 上的性能最优;在
、
时,使得DCGCSA在数据集SMP2020上的性能最优。
4.3. 实验流程
数据预处理:数据集数据来自微博,在实验前要对数据集进行繁体转简体、去除无用URL和邮箱等简单地数据清洗和处理。由于微博数据中存在大量的表情包,而表情包可以明显表达句子的情感,因此为了融入表情包的信息,实验前将数据集中的表情包转换成描述相应表情包的文字。
句法依存树的生成:为了提升模型训练效率,句法依存树独立于模型,在模型训练前使用哈工大工具LTP [18] 生成。生成的句法依存树以邻接矩阵形式保存成序列文件,当进行模型训练时,直接加载序列文件即可。
模型训练:每次训练设置共200轮次训练,取best模型;每个数据集训练3次,取3次的
和
的平均值作为最终实验结果。
4.4. 模型对比实验
本节为了评估DCGCSA性能,对比了该领域相关研究中的模型,其中带有*标的对比算法实验结果直接引用原文献。为了更准确地评估DCGCSA性能,增加了在数据集SMP2020的对比试验,其中N/A代表未获得实验结果。
LSTM:Ji等人 [20] 使用LSTM最后一层输出向量作整个句子的语义表示,没有考虑到上下文语义信息。
LSTM-CNN:Lai [11] 等人使用BiLSTM作为编码器,提取文本序列的语义表示,再利用CNN整合文本序列的语义表示得到整个句子的语义表示,该方法考虑到了上下文语义信息,但是保留了冗余的语义信息。
BiLSTM-Self-Attention:使用BiLSTM作为编码器,从正反两个方向获取文本序列的语义表示,再使用自注意力机制赋予上下文中具有重要语义信息的词更高的权重。
Syntax-based GCN:Lai等人 [11] 融合句法信息,利用句法信息挖掘重要的情感关键词,提出一种结合GCN和BiLSTM的模型。该模型过于依赖句法依存信息,且仅使用句法信息发掘情感关键词。另外该方法忽略语义信息的重要性,只是用语义信息来帮助模型学习句法信息。
DCGCSA分类性能是在
和
取最优值时测试的(
,在Lai [11] 中
,在SMP2020中
)。对比试验结果如表3所示,DCGCSA在两个数据集上都取到了最优的效果。
Table 3. Results of model comparative experiment
表3. 模型对比实验结果
注:表中黑体字表示最优的分类性能分数。
对比BiLSTM-Self-Attention和LSTM-CNN可以发现:加入自注意力,可以有效去除冗余的语义信息,使得模型从语义角度捕获情感关键词。对比DCGCSA、Syntax-based GCN和BiLSTM-Self-Attention的实验结果可以看到,从句法和语义方面进行情感分类的性能差别不大,两者对于情感分类任务都很重要,且可以相互补充,从句法依存和上下文语义双角度捕获情感信息的分类性能(DCGCSA)要优于单角度的分类性能。
通过对比模型在两个数据集的分类性能表现,可以发现DCGCSA在数据集Lai [11] 的表现要优于数据集SMP2020,为了探究产生这种差异的原因,观察两个数据集的训练样本和测试样本的数量比例,发现数据集Lai [11] 的比例要更大,这是主要原因之一;另外处理数据集SMP2020不够充分也是导致这种差异性的主要原因之一。
4.5. 通道权衡系数γ
为了探究通道权衡系数
对模型性能的影响,本节保持正则化系数
不变,通过改变
取值,记录模型DCGCSA的
值和
值。实验结果绘制成折线图,见图5。
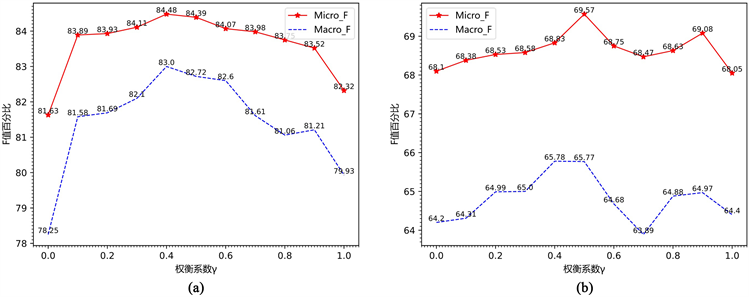
Figure 5. Channel trade factor action chart
图5. 通道权衡系数作用图
折线图的横轴为权衡系数
,纵轴为
和
百分比值(F百分比值),图5(a)是在数据集Lai [11] 的实验结果,图5(b)是在数据集SMP2020的实验结果。由图5(a)、图5(b)可知,随着权衡系数
取值增大,DCGCSA在数据集Lai [12] 和SMP2020的F百分比值呈现先增加后减小的趋势。在数据集Lai [11] 中,模型DCGCSA在
时取得最优的分类性能;在数据集SMP2020中,模型DCGCSA在
时为最优分类性能,而当
时,模型的
值要低于只有GCN的
值,出现这种情况的原因可能在于此时DCGCSA在某一类别的分类效果比较差,导致整个数据集的性能指标
值较低。从图中的变化趋势可以得到模型的分类性能随着权衡系数
取值改变而变化,说明改变权衡系数
相当于改变SDSK和SSK对最终分类结果的贡献度,调整权衡系数
可以改变SDSK和SSK对最终分类结果的影响力度。另外,权衡系数
是SDSK的通道贡献系数,而SSK的通道贡献系数为
,所以在模型DCGCSA中SDSK和SSK对模型的影响属于竞争关系,在减小权衡系数
值,减弱SDSK的影响力度时会增强SSK的影响力度。当减弱SDSK对模型的影响力度时,相当于减弱句法信息对分类的影响,进而减弱开源工具对模型造成的负面影响;而由于SDSK和SSK存在竞争关系,模型DCGCSA会加强SSK对最终分类结果的影响,进而模型DCGCSA更加注重从语义角度捕获情感关键词信息。
图5中的变化趋势表明双通道分类结构可以让模型不过于依赖句法信息,减弱使用开源工具造成的负面影响;并且可以通过调整的权衡系数
取值,使得模型使用句法提取开源工具带来的负面影响最小化的同时,最有效综合两个角度获取的情感信息,进而提高模型的分类效果。实验结果表明,使用通道权衡系数可以充分发挥双通道分类的作用,由于数据集的差异会使得最优权衡系数
的取值不同。
4.6. 正交化约束系数λ
本节探究正交化约束系数
对模型性能的影响,在数据集Lai [11] 中取权衡系数
为0.4,在数据集SMP2020中取权衡系数
为0.5,使得模型的权衡系数处于最优。改变正交化约束系数
的取值(从0开始,每次步长为10的负幂次方),记录模型DCGCSA每次
取值的
值和
值,结果见表4。
Table 4. Comparison results of penalty coefficient λ
表4. 正则化系数
对比结果
注:表中黑体字表示最优的分类性能分数,正则化系数
取0表示无正则化约束。
由表4可知,在正则化系数
为
时,模型DCGCSA在数据集Lai [11] 和数据集SMP2020的分类性能取得最优。相较于无正则化约束的DCGCSA的表现,最优正则化系数(
)的DCGCSA在数据集Lai [11] 中的
值和
值分别提高了2.33%和2.95%,在数据集SMP2020中的
值和
值分别提高了1.49%和1.88%。从最优正则化系数DCGCSA分类性能的提升,可以得出对BiLSTM的权重矩阵W加正则化可有助于模型DCGCSA分类性能的提升。
实验结果表明,加入正交化约束的DCGCSA的性能要优于无正交化约束的DCGCSA。
4.7. 注意力可视化
为了验证引入自注意力机制的DCGCSA具有捕获重要语义情感词的能力。本节使用最优DCGCSA对数据样本实例进行注意力可视化(最优DCGCSA在数据集Lai [11] 和数据集SMP2020中取最优权衡系数
和最优正则化系数
)。按词注意力进行汇总,并进行规范化处理,如图6所示。
图6中的热力图结果是以句进行展示,每个词都对应着其注意力分数,分数表示模型DCGCSA对词的关注程度,分数值越大,关注度越高,分数的颜色越深。图6(a)样例的真实情感标签为“积极”,图6(b)样例的真实情感标签为“恐惧”。
模型DCGCSA预测图6(a)样例的情感标签为“积极”,从可视化结果可看出,DCGCSA在图6(a)样例中对“快乐”、“开开心心”和“生日”的关注分数为0.142、0.107和0.048,要远高于样例中的其他词,说明模型DCGCSA可以捕获“开开心心”、和“快乐”等含有积极语义的情感关键词;DCGCSA预测图6(b)样例的情感标签为“恐惧”,对“恐惧”、“吓醒”和“噩梦”的关注分数为0.208、0.089和0.071,说明模型DCGCSA可以捕获“恐惧”、“吓醒”和“噩梦”等含有恐惧语义的情感关键词。从样例可视化结果可以得出,加入语义情感关键词通道的DCGCSA可以加深利用本文编码器获得的基本语义信息,从上下文语义角度捕获语义情感关键词,从而提高模型的最终分类性能。

Figure 6. Weight distribution thermodynamic diagram of word attention summary in the sample
图6. 样例中词注意力汇总的权重热力分布图
实验结果表明,引入自注意力机制的DCGCSA可以筛选出体现句子情感句子语义情感词,赋予这些词更高的权重,从而减少冗余无用的语义信息。
4.8. 消融实验
本节通过设置消融实验进一步验证双通道分类有效性,实验设置模型DCGCSA的正则化系数
取
。本节消融实验分别单独去除GCCN和SCN,探究只保留一条通道时的DCGCSA的分类性能,实验结果见图5。
当
时,模型DCGCSA只存在SSK。此时模型DCGCSA在数据集Lai [11] 的
值和
值为81.62%和78.25%,在数据集SMP2020的
值和
值为68.10 %和64.20%。而与单SSK的DCGCSA相比,最优双通道DCGCSA在数据集Lai [11] 中的
值和
值提升了2.85%和4.75%,在数据集SMP2020中的
值和
值提升了1.47%和1.57%。
当
时,DCGCSA只存在SDSK。与此时单SDSK的DCGCSA相比,最优双通道分类的DCGCSA在数据集Lai [11] 中的
值和
值为84.48%和83.00%,分别提升了2.16%和3.07%;在数据集SMP2020中的
值和
值为69.57%和65.77%,分别提升了1.52%和1.37%。
通过消融实验结果可知,双通道分类机制对模型DCGCSA性能提升起到了正向作用,使得模型有效结合了SDSK和SSK的分类结果,并在最优权衡系数
的调整下,使得SDSK和SSK联合发挥的作用尽量最大化。
4.9. 混淆矩阵可视化
为了探究模型DCGCSA在具体情感类别中的分类性能表现,本节对混淆矩阵结果进行可视化,如图7所示。混淆矩阵可视化可以清晰地表现出模型对具体情感类别分类的正确性以及错分后的类别。图中纵轴为样本真实标签类别,横轴为最优DCGCSA对该情感类别样本的预测标签,图中的颜色越深则表示权重越大。图7(a)和图7(b)分别展示了模型DCGCSA在数据集Lai [11] 和数据集SMP2020的混淆矩阵可视化结果。
从图7(a)可得,深色都出现在对角线上,说明模型DCGCSA在数据集Lai [11] 中能够较好地识别具体情感类别,能够将各个具体情感类别的样例较大概率的预测为正确情感标签。从图7(b)可得,模型DCGCSA在数据集SMP2020中能够较好地识别“愤怒”、“悲伤”和“积极”情感类别,能够将74%
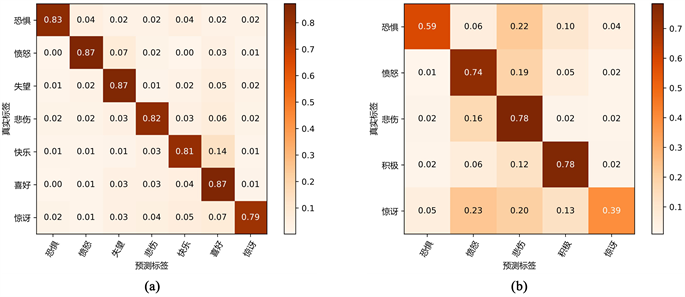
Figure 7. Results of confusion matrix visualization
图7. 混淆矩阵可视化结果
的“愤怒”样例、78%的“悲伤”样例以及78%的“积极”样例预测为真实标签,但是在“恐惧”和“惊讶”情感类别中的表现较差。22%的“恐惧”情感样例被错误分类为“悲伤”标签,10%的“恐惧”情感样例被错误分类为“积极”标签;23%的“惊讶”情感样例被错误分类为“愤怒”标签,20%的“惊讶”情感样例被错误分类为“悲伤”标签,13%的“惊讶”情感样例被错误分为“积极”标签,造成这现象的原因可能在于数据集SMP2020中“恐惧”和“惊讶”情感样本数较少。
5. 结束语
本文提出了一种双通道细粒度情感分类模型DCGCSA,该模型从句法依存和上下文语义两个角度捕获情感关键词的同时减弱了错误句法信息给模型带来的影响,并通过调优通道权衡系数来增强这种效果。模型对比实验结果表明,捕获语义情感关键词在情感分类任务中具有重要作用,不过分依赖句法信息并能捕获语义情感词的DCGCSA的分类性能要优于对比模型。消融实验结果验证了双通道分类机制的有效性。未来研究可以尝试改进模型自动学习通道权衡系数。另外,DCGCSA的SDSK只采用了简单的位置映射关系来引入依存句法信息,无法自动筛选错误的句法信息,在未来的工作中可以设计相应机制筛选错误句法信息。
基金项目
国家自然基金重点项目(92048205);南京大学计算机软件新技术国家重点实验室开放课题项目(KFKT2021B39)。