1. 引言
随着我国工业化、城镇化的快速发展,空气污染逐渐演变为一个形势严峻的问题。其中能源消耗量的持续增加所带来的空气污染问题,不仅对人们的日常生活有影响,甚至危害到了居民的身体健康 [1] 。已有学者证实,污染的空气中存在如PM2.5、一氧化碳(CO)、二氧化硫(SO2)、二氧化氮(NO2)、臭氧(O3)等污染物颗粒。上述高浓度的污染物可能会危害健康,严重导致死亡 [2] 。在上述污染物中,PM2.5是一个重要的衡量空气污染程度的指数,所以对PM2.5浓度的预测,以及在预测精度方面进行突破,是目前研究的热点和难点。
近年来,国内外学者关于PM2.5这一指标的预测做出了大量研究,包含以下几个方面:基于传统统计模型的预测研究、基于机器学习模型的预测研究、基于深度学习的预测研究以及基于混合模型的预测研究。方晓婷等 [3] 采用线性回归方法进行建模,使用气温、风速、湿度、风向等气象因素对PM2.5做预测,回归模型预报准确率较高。沈劲等 [4] 利用聚类和多元回归相结合的方法建立空气质量预报模型,准确地预测了顺德区的PM2.5浓度。
随着机器学习技术蓬勃发展,有研究采用单个机器学习模型对PM2.5浓度进行预测。Huang Keyong等 [5] 建立随机森林模型,通过气溶胶数据、气象参数数据对历史PM2.5浓度进行预测,模型表现良好。王敏等 [6] 采用BP人工神经网络模型来预测PM2.5浓度的空间变异,证实了BP人工神经网络在准确预测PM2.5浓度方面的优势。任才溶等 [7] 提出了一种基于随机森林的PM2.5浓度等级预测方法,并证实了该方法具有较好的精确度、召回率与F值。司志鹃娟等 [8] 建立改进型灰色神经网络组合模型预测天津市空气质量状况,模型的预测结果相比传统灰色神经网络组合模型更可靠。刘拥民等 [9] 基于提出一种新型XGBoost-ARIMA混合预测模型,且该方法与经典预测模型相比具有更低的平均绝对误差和希尔不等系数。Wang Ping等 [10] 提出了ARIMA-SVM组合模型提取空气质量数据的高维特征并进行预测,模型表现出可靠和准确的预测性能。徐艳平等 [11] 利用随机森林回归构建城市空气质量预测模型,并证实其具备较好的学习能力与泛化能力。从上可以看出,利用机器学习方法进行污染物浓度预测可以进一步提升预测精度。
传统的机器学习模型有着较高的准确率但模型的扩展性较差,难以捕捉到空气质量数据的时空变化。深度学习模型可以通过深度网络对空气质量数据进行时空建模,从而得到更精确的预测结果 [12] 。郑洋洋等 [13] 建立基于深度学习库Keras (一种高层神经网络API)的长短期记忆循环神经网络(LSTM)模型对太原市空气质量指数进行仿真预测,并证明该模型具有预测精度高、范围广等优点。宋飞扬等 [14] 提出基于时空特征的KNN-LSTM的PM2.5浓度预测模型,并以哈尔滨市10个空气质量监测站的污染物数据进行实验,结果证实了KNN-LSTM模型能有效提高LSTM模型的预测精度。戴李杰等 [15] 应用支持向量机(SVM)和粒子群优化(PSO)算法建立滚动预报模型,对PM2.5未来24小时浓度进行预报,结果证实提出的模型优于径向基函数神经网络(RBFNN)等模型。
空气中的PM2.5浓度既受到气象因素的影响,也受空气污染物的影响 [16] ,但现有的PM2.5浓度预测研究大都只采用单一影响因素来进行预测。基于此,本文在上述理论的基础上,尝试将气象数据、空气污染物数据和PM2.5浓度历史数据结合,区别于传统统计学方法与传统机器学习方法,构建CNN-LSTM组合模型,对未来单日短期PM2.5浓度进行预测,从而提升预测准确率和数据处理效率,以期为环境监测部门及社会公众提供更为准确的预测信息。本文的创新之处在于使用组合模型来预测兰州市PM2.5浓度,并有效提高了预测精度。
2. 研究数据及方法
2.1. 研究数据
本文以兰州市2016年3月1日至2022年3月31日逐日历史空气质量浓度数据和气象数据(共2181条)为研究对象,其统计性描述如表1所示。其中,由于官方网站的反爬虫限制,空气质量浓度数据来自天气后报网(http://www.tianqihoubao.com/aqi/lanzhou.html),包含PM2.5、PM10、NO2、CO、O3、SO2;气象数据来自2345天气王网站(https://tianqi.2345.com/)和美国国家海洋大气管理局(NOOA)官方网站(https://www.ncei.noaa.gov/maps/daily/),包括最高气温、最低气温、风向、风速、天气。上述网站的数据均来源于官方的当日天气预报信息,因此可以将其作为本研究提出的CNN-LSTM模型的研究对象。在使用的数据中,对于个别缺失的数据,通过线性插值法进行填补。

Table 1. Descriptive statistics of air quality and meteorological data in Lanzhou
表1. 兰州市空气质量数据和气象数据描述性统计
2.2. 研究方法
2.2.1. 卷积神经网络(Convolutional Neural Networks, CNN)
卷积神经网络 [17] 是一种深度神经网络,一般由输入层、卷积层、池化层、全连接层和输出层组成,卷积和池化层一般应用于特征工程,全连接层用于特征加权,相当于一个“分类器”。网络自身具有“局部链接”和“权重共享”特征,简化了网络链接的复杂程度,提高了模型对抽象特征的提取能力,在一定程度上缓解了全连接网络训练速慢和易陷入过拟合的问题。
其中,卷积层相当于对输入数据进行“滤波”操作,通过卷积计算提出输入数据集中的建模特征,在高维空间挖掘输入数据特征向量关联关系。卷积计算的原理是输入数据与卷积核的乘积和,经过卷积层得出输入数据的特征集。卷积层计算过程如式(1)所示。
(1)
式中:
为卷积计算;F为卷积层的输入;w表示卷积核的权重参数;C、Hf、Wf分别为卷积核的通道数、高度和宽度。
CNN网络池化层是在卷积层后获取的特征基础上进一步提取特征,保留卷积后主要特征的同时降低网络复杂度,提高模型特征提取的效果。一般情况,通过求取目标区域的最大值或者平均值压缩数据特征。基于这种特性,本文使用了一维卷积对空气质量数据的时空特征做特征提取。
2.2.2. 一维卷积
如前所述,一维卷积能够更好的提取时序数据的高维特征。一维卷积借助了卷积神经网络的卷积核参数权值共享的特性,大大了减少参数数量,不仅满足了避免过拟合,也节省了训练的时间。图1展示了一维卷积的过程,其中x1~x9为时序输入,o1~o7为经过卷积操作之后的得到高级特征,图1中的卷积核由3根连线组成,即每一个卷积核提取三个输入数据的特征,每一根连线上有对应的权重值,且整个操作共享此套超参数。
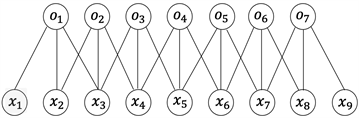
Figure 1. One-dimensional convolution process
图1. 一维卷积过程
2.2.3. 长短期记忆网络(Long Short-Term Memory, LSTM)
循环神经网络(Recurrent Neural Network, RNN)是一类以时间序列为输入的递归神经网络 [17] 。循环神经网络的输入条件决定了它在处理时间序列时具有天然的优势,而它的参数共享的结构特性又使得它能够更好的学习序列的非线性特征。长短期记忆网络(Long Short-Term Memory, LSTM)是循环神经网络的改进模式,由Hpchreiter等 [18] 在1997年提出,通过引入输入门、输出门、遗忘门三种“门”结构来实现信息的筛选和记忆。
图2是LSTM网络中的一个基本细胞单元,
代表了前一时刻(t − 1时刻)的细胞状态,
代表了前一时刻(t − 1时刻)细胞的隐藏层状态,
表示当前时刻(t时刻)的输入,
是一次更新后的细胞状态(记忆单元),
则为一次更新后的隐藏层状态,也是后续细胞单元的输入。如前所述,细胞单元内部的三个门结构负责对细胞状态和隐藏层状态进行更新,分别是遗忘门
、输入门
和输出门
。三个门的具体功能为:遗忘门
决定保留多少上一时刻(t − 1时刻)的细胞状态
到当前时刻的细胞状态
,输入门
决定保留多少当前时刻(t时刻)的输入
到当前时刻的细胞状态
,输出门决定保留多少当前时刻的(t时刻)细胞状态
到输出
。这里区别于传统的RNN直接将上一时刻隐藏层输出
作为历史状态的反映,LSTM网络通过细胞内部自循环的记忆单元,将上一时刻的细胞状态
作为历史状态的反映,不断更新网络的隐藏层状态,在实践中证明有更好的时序处理能力及适用性。具体的细胞更新过程为式(2)~(7):

Figure 2. Cellular structure of LSTM network
图2. LSTM网络的细胞结构
(2)
(3)
(4)
(5)
(6)
(7)
式中:
、
、
、
、
、
、
、
为LSTM模型的超参数,是每个门结构的权重和偏置,在训练过程中需要不断进行更新;
和
为模型隐藏层的激活函数,目的是提高模型的非线性拟合能力。
2.2.4. CNN-LSTM组合预测模型
为了更好地融合CNN网络和LSTM网络的优点,提出了CNN-LSTM组合神经网络基本结构,其构建流程如图3所示。
首先使用CNN网络提取输入变量特征,然后构建高维映射空间时序性特征向量,最后将结果输入到LSTM网络训练。将输入变量构造为2181 × 1 × 23的矩阵向量输入到CNN网络,并对其进行一维卷积操作,卷积后使用1个池化层提取特征,卷积核设为1 × 3,卷积核的个数设为128,1层池化核为1 × 1,池化层通过取最大值进行降维,卷积层和池化层的移动步长均设定为1,激活函数为ReLU函数。依据上述卷积和池化原理,计算得到n个128通道的1 × 1特征矩阵,通过拉伸生成n个长度为128的一维向量,该向量为LSTM网络输入变量。得到组合模型各层参数数量如图4。
模型的创新性主要体现在以下方面:1) 利用一维卷积对输入数据进行处理,有效的提取到了时序数据的高级特征,大大地减小了特征映射的深度;2) 构建组合模型,利用LSTM网络训练一维卷积处理之后的时序数据,提高了模型的预测精度。
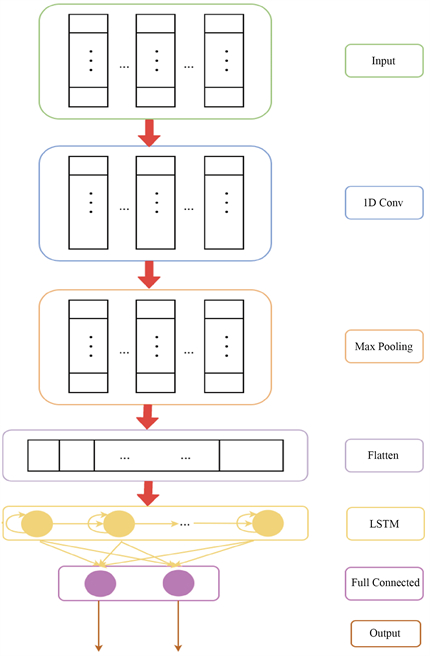
Figure 3. Framework diagram of combination model
图3. 组合模型框架图
2.2.5. 评价指标
为了评估模型的效果,本文采用决定系数(R2)、均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)这4个常见的评价指标对模型的精度进行比较。其中,RMSE、MAE和MAPE衡量的是模型预测值与真实值之间的偏差,模型在这些指标上的值越低反映模型的效果越好;R2反映了模型预测值与真实值之间的偏离程度,模型在该指标的值越高反映偏离程度越低,模型的效果越好。4种评价指标表达式如下:
(8)
(9)
(10)
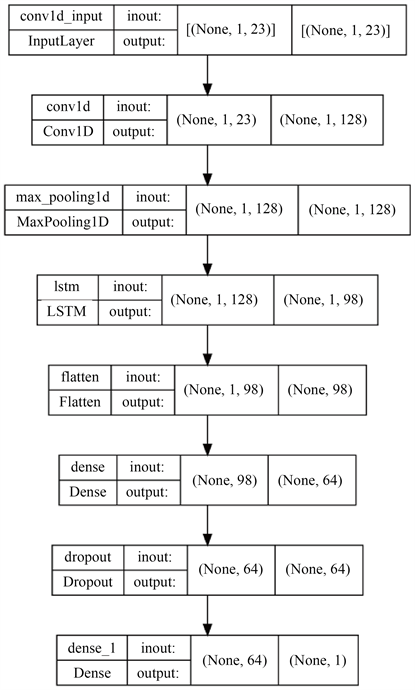
Figure 4. Parameter structure diagram of each layer of the combined model
图4. 组合模型各层参数结构图
(11)
式中,n为样本数据的数量;
为预测结果;
为真实值;
表示真实值的平均值。
3. 结果与讨论
3.1. 相关性分析
3.1.1. PM2.5与其它大气污染物的相关系数
由于PM2.5浓度变化不仅会受到其他大气污染物的影响,也会受到气象因素的影响 [19] 。因此,首先对研究区域PM2.5浓度与其它污染物变量(PM10、SO2、NO2、CO、O3)的数据进行了相关性分析。结果如表2所示,PM2.5与各污染物之间均存在一定的相互关系。其中PM10与PM2.5之间的线性相关性极强,呈线性正相关;而SO2、NO2、CO、O3与PM2.5之间的线性相关关系较弱。
Table 2. Correlation coefficient between PM and other air pollutants
表2. PM2.5与其它大气污染物的相关系数
3.1.2. 气象因素对PM2.5浓度的影响
其次,对PM2.5浓度与气象数据进行相关性分析,结果如表3所示。PM2.5与气象因子存在一定的相关性,其中PM2.5与风速呈正相关关系,与最高温度、最低温度和风向呈负相关关系。
Table 3. Correlation coefficient between PM and meteorological factors
表3. PM2.5与气象因素的相关系数
3.2. LSTM模型及CNN-LSTM组合模型的对比分析
由于PM2.5浓度属于时间序列数据,因此按照日期顺序划分训练集(60%)和测试集(20%),同时在测试集上还划出了一部分作为验证集(20%)。根据训练集和验证集的损失来进行网格搜索、调节参数,最终使用训练好的模型对测试集的数据进行预测。图5为两模型对测试样本的预测效果图,结果显示,CNN-LSTM组合模型和单个的LSTM模型都预测效果都表现良好,但组合模型的最终呈现效果更优。
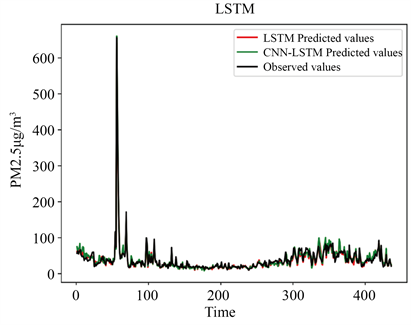
Figure 5. The prediction effect of the two models
图5. 两模型的预测效果图
为了更加直观地对比两模型的预测效果,表4给出了两种模型的4类评价指标。结果显示:预测结果中,两模型训练的拟合优度(R2)差别较小,但CNN-LSTM混合网络对测试样本的预测误差要明显低于LSTM模型。呈现出更高的预测精度。
Table 4. Prediction effect evaluation of different networks
表4. 不同网络的预测效果评估
3.3. 讨论
本文使用气象数据、空气污染物数据以及PM2.5浓度历史数据构建了CNN-LSTM组合模型。以兰州市为研究区域,进行未来单日PM2.5浓度预测,得到的RMSE、MAE和MAPE值为6.98、4.82和0.74,小于单个LSTM模型的7.42、5.04和0.76。本文借助卷积神经网络中的卷积层的特性,使用一维卷积对时间序列中重要特征进行提取,然后将处理后的数据作为输入传到LSTM网络进行训练,最终得到测试集的预测结果。该模型不仅考虑了数据的时间序列特征,又兼顾了其他污染物浓度和气象因素对PM2.5浓度的影响,对比单个的LSTM模型,CNN-LSTM模型在预测误差上存在优势。
4. 结论
如今,空气质量方面的问题日渐成为一种社会问题,而PM2.5浓度是一个反映空气质量优良程度的重要指标,因此,如何实现PM2.5浓度的精准预测也成为目前的研究热点。基于此,本文充分考虑了PM2.5浓度的时间序列特性,并结合其他有影响的污染物因子和气象因子建立面板数据的组合模型。首先,本文根据气象数据和污染物浓度的时间序列使用一维卷积提取重要特征信息,卷积后得到了多个通道的特征图。其次,经过池化操作得到一个一维的向量,将向量作为长短期记忆网络的输入进行训练。最后,为了比较模型的效果,使用单个的长短期记忆模型进行对比分析,实验结果表明组合模型的预测效果明显优于单一模型,验证了组合模型在污染物浓度预测中的高效性。
基金项目
国家自然科学基金项目(11961039, 11801243)。
NOTES
*第一作者。
#通讯作者。