1. 引言
设AD是一种使人记忆力衰退、大脑功能缓慢且逐渐变异的智力丧失表现的疾病。该病严重可以直接影响患者认识和感觉心理综合功能的严重缺失,尤其严重的后果是患者大脑神经皮质生理机能的严重丧失,包括正常人的逻辑记忆力、判断能力、抽象思维表达能力等。AD的特点是神经原纤维缠结、神经元和突触丢失、β淀粉样斑块的累积,所导致脑功能和行为出现变化。早期诊断和预测AD可以延缓患者的发病,可能延长患者的寿命,对整个社会具有重要的科学意义。因此,有效的早期诊断和预测AD的患病概率是预防AD的有效手段 [1]。通过人工智能计算方法对AD数据进行分析和建模,提取和发现影响AD诊断和预测的关键症状。由于数据集中不同的量表有各自的优势和局限性,因此需要综合的考虑各种表格,从而诊断和预测AD。特征提取算法有的仅支持离散属性的特征变量、有的仅支持连续属性的特征变量、也有的两者皆可支持。本文根据有关特征对阿尔茨海默病进行智能化诊断并建立相关数学模型。用附加的大脑结构特征和认知行为特征来设计阿尔茨海默病的智能诊断,本文采用的是基于成对分类法的SVM实现AD的智能诊断,从简单的SVM二分问题向高维的五分类问题逐渐优化,使得问题简单化然后对五类数据分别探索并验证模型的效果。
2. 模型假设与符号说明
1) 假设本题附件中提供的数据均真实可信。
2) 假设每个样本间相互独立、互不关联,并且他们的各指标之间互不干扰(表1)。
3. 基于成对分类法的SVM实现AD的智能诊断
3.1. 模型原理介绍以及模型的优点
3.1.1. 模型原理介绍
支持向量机建立于结构风险最小原理的基础至上,以间隔最大化为学习策略,其算法本质是求解凸二次规划的最优化算法。由于支持向量机依靠接近平面的若干支持向量建立分界线或超平面,因此能够凭借有限的样本信息获取现有条件下的全局最优解,避免了神经网络方法可能面临的样本过少的局部最优解问题,同时具有较好的泛化能力。如下图所示,即为简单的二分类支持向量机。
3.1.2. SVM的优势
SVM的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。其次SVM主要擅长应付样本数据线性不可分的情况,主要通过核函数和松弛变量来实现。其次由于分类器仅由支持向量决定,SVM还能够有效避免过拟合。
3.1.3. 敏感性分析
在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。先将数据集划分为10份,每次取其中9份用来训练,1份用于测试,最终得到十次测试结果的平均值(外层交叉验证)。每次在用9分数据进行训练时,如果模型需要调参,则可进一步在训练过程当中进行交叉验证(内层)。通过每次取9份中的8份数据用于训练,剩余的一份用于验证,用9次的均值来对当前参数做出评估(图1)。
结合数据集观察每个数据特征在随机森林中的每颗决策树上做了多少贡献,然后取平均值,最后对比特征之间的贡献大小。总结一下就是:特征重要性是指,在全部单颗树上此特征重要性的一个平均值,而单颗树上特征重要性计算方法事:根据该特征进行分裂后平方损失的减少量的求和。
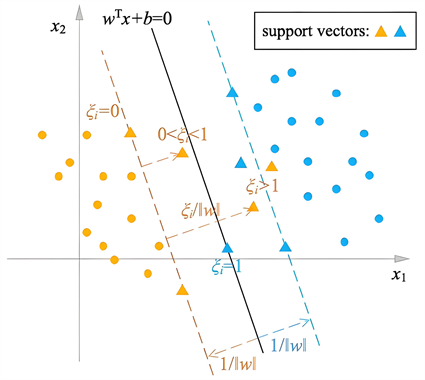
Figure 1. Binary classification support vector machine
图1. 二元分类支持向量机
特征
在整个模型中的重要程度为:
其中,M是模型中树的数量。特征
在单独一个树上的特征重要度为:
3.2. 数据预处理
选取了:
'CDRSB','ADAS13','MMSE','RAVLT_forgetting','RAVLT_perc_forgetting','LDELTOTAL','FAQ','mPACCdigit','mPACCtrailsB','Ventricles','Hippocampus','Entorhinal','Fusiform','MidTemp','ICV'
十六个指标 [2] 作为自变量,DX_bl作为因变量。即指标的数量是2425,维度为16。
Step1:数据的归一化 [3]
其中
是第i个指标的权重,
是第i个指标的平均值,
为第i个指标的标准差。
Step2:使用网格搜索法找到最优内核函数
支持向量机核函数中,不同的超参数设置,机器学习给出的结果也会不一样,因此,也会影响到对结果的评价指标。而人们往往会追求一个“最好”的结果,因此,就需要在众多超参数的取值范围中选取一个“最优”的值进行设置。因此,使用网格搜索等手段,均是为了寻找好的超参数。利用网格搜索技术调整各项参数以取得最好的评价分数。
支持向量机中的内核函数有:
线性核函数:
多项式核函数:
高斯核函数:
Sigmoid核函数:
Step3:建立五分类的二次型 [4] 规划问题:
目标函数:
;
优化目标函数为:
;
约束条件:
。
在目标函数中,为了提升准确度,消除噪声与异常样本的影响,引入松弛变量,表达式如下:
为更容易解决该目标优化问题,本文采用引入拉格朗日乘子的方式,将优化问题转化为对偶问题其表达式如下:
Step4:绘制ROC曲线。
ROC曲线正是通过不断移动分类器的“阈值”:
1) 假设已经得出一系列样本被划分为正类的概率Score值,按照大小排序。
2) 从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。
3) 每次选取一个不同的threshold,得到一组FPR和TPR,以FPR值为横坐标和TPR值为纵坐标,即ROC曲线上的一点。
本文是一个五分类问题,可以根据所分的类别和测试样本的数量(2425)的概率矩阵,从而计算各个阈值的假正例率(FPR)和真正例率(TPR),从而绘制出5条ROC曲线。最后对5条ROC曲线取平均,即可得到最终的ROC曲线。
3.3. 模型的求解
3.3.1. 核函数的选择
将数据带入建立好的的模型,通过python求解,得出当核函数为linear,惩罚系数C = 1,核函数系数为scale时,F1-score为0.71,为最优结果,评估表如下:(表2)。
3.3.2. ROC曲线
一个特定的分类器 [5] 和测试数据集,每一个实例都会得到一个分类结果,通过统计,利用上述公式,可以得到一组FPR和TPR结果,通过python绘制出ROC曲线:(图2)。
由上图中可以看出当核函数为linear,惩罚系数C = 1,核函数系数为scale时,本分类器对于判断CN有64%准确率,判断AD有80%准确率,判断LMCI有68%准确率,判断SMC有58%准确率,判断EMCI有76%准确率,具有较好的测试效果。
3.4. 随机森林求解
我们将自变量作为输入,因变量作为目标导入随机森林工作箱,并按照一定的比例将这些样本分为两类进行处理:训练集(80%)、测试集(20%)。
3.4.1. 自变量和因变量的选择
其中自变量选取AGE、PTGENDER、pteachat、PTRACCAT、MMSE、ADAS11、ADAS13、RAVLT_immediate、RAVLT_learning、RAVLT_forgetting、RAVLT_perc_forgetting、FAQ、mPACCdigit、ADASQ4_bl、LDELTOTAL_BL,共15个自变量;选择DX_bl作为因变量。
3.4.2. 随机森林决策树数量及模型训练方法的确定
接下来我们需要选定决策树的数量以及模型的训练方法来完成对模型的训练。经过大量的尝试,最终我们选用决策树数量为71,模型训练方法为ExtraTreesClassifier。
3.4.3. 随机森林模型的训练结果与模型评估
1) 各个参数的选择(表3)

Table 3. Correlation of Alzheimer’s disease with data characteristics
表3. 阿尔茨海默病与数据特征的相关性
2) 模型的评估
采用sklearn库中metrics的classification_report方法对模型准确率进行求解,经过大量的尝试得出随机森林的n_estimators选择为时81,模型准确度最高。如图1~3所示:
观察上图可得出整个模型震荡幅度较大,且在随机森林n_estimators选择为时81,模型准确度最高。最终结果聚为五类和三类,可视化效果如图4所示。
3.5. 多元神经网络 [6] 模型的求解
我们首先需要定量地研究不同数据特征对于阿尔兹海默症的影响,考虑引入人工神经元模型,图5展示了人工神经网络基本单元的神经模型。
其中,
属于样本特征,
是权重(也叫连接系数),
是指各个样本特征的权重值之和,
时指激活函数这里我们采用默认内置relu函数:上述模型可以归纳成为以下公式:
我们选取了LDELTOTAL_BL,mPACCdigit,FAQ,ADAS13,AGE,MMSE,ADAS11,PTEDUCAT,RAVLT_perc_forgetting共9项数据特征作为大脑结构特征和认知行为特征的特征标签;接下来我们需要选定隐藏神经元的个数以及模型的训练方法 [7] 来完成对模型的训练 [8]。经过大量的尝试,最终我们选用隐藏神经元个数为9,模型训练方法为贝叶斯正则化。阿尔茨海默病的智能诊断方案参考区间最终如表4所示。
当个人同时所检测出来的各项数据特征同时满足上表的参考范围可初步断定该个体患有阿尔兹海默症。
Table 4. Intelligent diagnosis solutions
表4. 智能诊断方案
4. 关于阿尔兹海默的诊断标准
4.1. 关于ApoE基因方面的诊断
根据本文的研究并结合相关临床案例分析 [9],ApoE (Apolipoprotein E,载脂蛋白E)基因是与AD关系最相关的基因。ApoE有3个等位基因:ApoE-Ɛ2、ApoE-Ɛ3和ApoE-Ɛ4。Farrer等的研究发现,91%的ApoE-Ɛ4纯合基因携带者在68岁左右发病,约47%的ApoE-Ɛ4杂合基因携带者在76岁时发病,而在ApoE-Ɛ4非携带者中,仅20%在85岁时才发生AD。研究结论是患者携带的Ɛ4基因的数量越多,患者的发病时间就越早。研究表明,ApoE与Aβ代谢有密切关系,其中,ApoE-Ɛ4对Aβ沉积所形成的老年斑有较强影响,并促进了脑淀粉样血管病的发生,两者是AD的最主要病理特征。
Table 5. Pathological characteristics of exercise affecting cognitive dysfunction in clinical experiments [3]
表5. 临床实验中运动影响认知功能障碍患者的病理特征 [3]
4.2. 对患者进行量表诊断 [9]
临床医师需要充分考虑患者的海马体的情况,还有受访时的年龄、是否患过精神疾病和ADAS13,LDELTOTAL,LIMMTOTAL,MOCA,RAVLT.perc.forgetting,COPYSCOR,MMSE,EcogSPTotal,FAQ,EcogPtTotal量表。并且对于患者的随访也要有针对性地选择这些量表测验。DBN的结果表明,对临床医师判断患者患病时长的建议,要注意海马体和内嗅随着时间的变化情况,以及ADAS13量表等。这为临床医师通过已知的特征信息来辅助诊断患者实际所处的患病阶段有帮助 [10]。
4.3. 关于阿尔兹海默症的早期干预
关于MCI与AD早期患者的干预措施主要通过运动进行影响认知功能障碍患者(表5)。