1. 引言
机械臂在工业领域的广泛应用将人类从繁杂的体力劳动和重复工作中解放出来了。机械臂的物件抓取、机械焊接、油漆喷涂和制造装备等都涉及机械臂的轨迹跟踪问题 [1]。迭代学习控制适用于非线性强耦合和重复性运动的系统,可以广泛应用于机械臂等执行重复任务的被控对象 [2]。机械臂运行过程中信息会丢失一部分,进而会导致每次迭代的长度不一致 [3] [4]。通过神经网络对系统的内部和外部干扰进行逼近,可以提高跟踪控制的精度 [5]。因此,本文通过迭代学习原理和神经网络方法在迭代长度变换的情形下研究机械臂的变长度误差跟踪具有重要意义。
基于自适应模糊迭代学习控制方法,文献 [6] 研究了系统约束和随机变化的迭代长度问题。基于迭代学习控制方法,文献 [7] 研究了一类多输入多输出非线性系统在迭代长度变化的轨迹跟踪问题。基于势垒复合能量函数构造的一种自适应迭代学习控制方法,文献 [8] 研究了在状态对准条件下的多输入多输出非线性系统的变迭代长度轨迹跟踪问题。基于牛顿极值求值算法的迭代学习控制方法,文献 [9] 研究了多轴系统轮廓运动精度控制的问题。基于反馈控制和自适应迭代控制结合的方法,文献 [10] 降低了初始状态不匹配对工业机器人跟踪性能的影响。基于神经网络自适应迭代学习控制方法,文献 [11] 研究了由任意初始偏移引起的问题。基于分布式迭代学习控制方法,文献 [12] 研究了多智能体框架下高速列车速度和位移跟踪控制的问题。基于迭代平均算子的迭代学习控制方法,文献 [13] 研究了具有非均匀迭代长度跟踪的问题。然而,文献 [7] [8] [9] 没有考虑系统的初值变化问题和参数估计值因逐点收敛导致上下界不固定的问题。文献 [11] [12] 没有考虑迭代过程中信息丢失,而造成的迭代不等长的问题。文献 [13] 的控制器设计是基于压缩映射方法,无法使当前迭代的信息充分利用。
综上所述,基于迭代学习控制和神经网络方法,本文将在具有外部干扰和模型不确定性的情况下研究机械臂变长度误差轨迹跟踪问题:1) 与文献 [7] 相比,本文针对任意初始偏移引起的问题,设计期望误差轨迹。2) 与文献 [10] 相比,本文针对迭代学习过程的不等长问题,引入一个虚拟跟踪误差,补偿未运行区间的误差信息。与文献 [13] 相比,本文可以充分利用迭代信息。3) 与文献 [8] 相比,更新率采用饱和函数代替,能够有效避免估计值因逐点收敛导致上下界不固定的问题,且本文考虑了系统的不确定性和外部干扰,用RBF神经网络对其进行逼近,提高精度和收敛性。
2. 问题陈述
考虑机械臂动力学模型:
(1)
其中,
为迭代次数,
,
,
,分别为关节位置,关节速度和关节加速度,
为对称正定的惯性矩阵,
为向心–科里奥利矩阵,
为重力矩阵,
为系统模型不确定性和外部扰动在内的有界干扰,
表示系统控制输入。为了方便后续描述,定义
,
,
。
机械臂有以下特性:
参考文献 [14] [15],机械臂具有以下特征:
性质1:矩阵
,是斜对称矩阵,即对任意向量
,
性质2:对于任意的向量
和任意的已知向量
,存在一个未知的时变参数向量
,使得以下等式成立:
(2)
其中,
是一个回归矩阵。
引理1 [16] :对于标量ai,定义其饱和函数:
(3)
其中,
为ai的上限和下限,且
。
对于向量
和向量
,定义
,
,
若
,则有:
(4)
对于矩阵
和
,定义
,其中
,且
为
的上限和下限,若
,则有以下不等式成立:
(5)
引理2:对于向量
有
(6)
对于矩阵
(7)
引理3:定义向量
,向量
和矩阵
,有:
(8)
本文做出如下假设:
假设1:在时间
内,实际轨迹
、
是连续可导的。
本文中
是随迭代次数变化的,T是期望迭代长度。对于随机变化的迭代长度问题,需要考虑两种情况,
和
。在
中,迭代在期望长度内,且已经满足下次迭代所需数据。在
中,迭代数据超过期望长度,因此不需要参与下次迭代更新数据,被直接舍去,所以本文只考虑
的情况。当
时,系统已经完成本次迭代,控制器不再参与系统运行,但更新律仍需将上次的迭代信息记录到未运行区间,使得每次迭代都能是
的更新信息。根据上述描述,定义
和
分别表示
的最小值和最大值,对
时设计了控制器。
假设2 [17] :Tk是一个随机变量,它的概率分布函数为
(9)
其中,
是一个连续函数。
注1:假设2描述了随机变量
的分布情况。当
,表示
,实际操作长度
不能大于
;
时,系统有一定概率运行至最大迭代长度,进而保证在迭代次数趋于无穷时,
的情况可以出现无穷次。所以概率分布函数
不需要事先知道,这是因为迭代学习控制律的设计与
无关。综上描述假设2是一个通用公式,在大多数实际应用中是满意的。
本文针对系统(1)设计控制器
,使得当迭代次数k趋向于无穷时,关节位置
能够在指定区间
内跟踪期望轨迹
,即,在区间
,当
时,系统以概率1的情况下使
。
3. 控制设计
3.1. 相关变量设计
定义状态跟踪误差
、
和期望误差轨迹
如下:
(10)
(11)
(12)
(13)
其中,公式中的
为先前指定的修正时刻。根据公式(10)~公式(12)得到:
(14)
(15)
注2 [18] :采用了迭代学习控制跟踪的理想条件
来设计控制律。但是在机械臂系统实际运行中,迭代会受到扰动,所以这一条件会被破坏,相关成果不在适用。因此本文通过构造期望误差轨迹(12)来放宽迭代学习控制的初值理想条件,解决迭代初值变化的问题。
当系统(1)运行到
时刻,迭代过程会返回到其初始状态,开始下一次迭代,因此迭代过程只能跟踪时间区间
的信息。由于
是随机变化的,本文需要设计虚拟误差变量,补偿未运行部分的误差信息。虚拟误差变量设计如下:
(16)
(17)
(18)
控制器设计分为
和
两个情况讨论。为了证明所提出的迭代学习控制律的收敛性,需要在时间间隔
内补偿丢失的控制信息。因此引入一个二进制0或1的随机变量
。
表示系统(1)在第k次迭代的t时刻依旧可以运行,此事件的概率为p(t)。所以
和
可表示为如下:
(19)
(20)
自适应径向基函数神经网络(RBFNN)将用于估计公式(36)中的非线性不确定项dk(t)。具体表示如下:
(21)
其中,
为dk的估计值,
为神经网络的控制输入。
为最优神经网络权值
的估计值,m是隐含层中的神经元节点数。
是具有隐层输出函数
的RBFNN激活函数,高斯函数选择如下:
(22)
其中,
是神经元节点的中心,
是神经元的宽度。存在一组最优神经网络权值
使得以下等式成立:
(23)
其中,
定义为如下表达式 [19] :
(24)
且,
为神经网络的逼近误差向量,满足
。
3.2. 迭代分析
为了让系统(1)在整个迭代过程中保持稳定,分成了两种情况讨论,情况1:
和情况2:
。
情况1:
(以下公式中时间t省略)
构造李亚普诺夫函数
,根据
设计虚拟控制器
:
(25)
(26)
(27)
将公式(26)求导并结合公式(11)和公式(17)有:
(28)
根据公式(18)得到:
(29)
公式(29)代入公式(28)得到:
(30)
则设计虚拟控制器为:
(31)
将公式(31)代入(30)得到:
(32)
对公式(27)进行求导得到:
(33)
公式(33)中,等号右边第一项根据公式(11)和(18)可化简得到:
(34)
由公式(1)可得到:
(35)
将公式(11)、(18)、(34)和(35)代入公式(33)得到:
(36)
根据性质1和性质2可得到:
(37)
因此,设计的实际控制器为:
(38)
其中,
为
的估计,
为
的估计,
为的
估计,
大于零的常数。
将公式(38)代入公式(37)得到:
(39)
定义
(40)
将公式(40)代入(39)得到:
(41)
将公式(14)和公式(17)代入公式(26)可得到:
(42)
将公式(15)、公式(17)、公式(18)和公式(31)代入公式(27)可得到:
(43)
根据公式(32)、公式(41)、公式(42)和公式(43)结合,有:
(44)
接下来设计
时的更新率设计如下所示:
(45)
其中,
为大于零的常数,
并且
表示上限和下限。假设
,则
在
这个饱和界限内。
(46)
其中,
为大于的常数,
,并且
表示上限和下限。假设
,则
在
这个饱和界限内。
(47)
其中,
为大于零的常数,
并且
表示上限和下限。假设
,则
这个饱和界限内。
注3:为了保证估计值在预定范围内的有限性,可以使用完全限幅学习律。通过饱和函数的性质,学习算法的整个右侧是饱和的,并且确保每个参数的估计在预先指定的区域内。
情况2:
在
时的更新率设计如下所示:
(48)
(49)
(50)
其中,
,
,
。此时系统(1)已经完成了本次迭代,因此不需要加入控制器,依旧需要保留上一次更新数据。该时刻不参与控制器设计,且不含
和
的相关信息。
根据更新率(48)~(50)得到:
(51)
当k = 0时,得到如下等式:
(52)
引理4:对于常数
,向量
,矩阵
,分别有:
(53)
引理5:对于常数
,向量
,矩阵
,分别有:
(54)
4. 稳定性分析
定理1:根据机械臂系统(1),在设计的控制律(38)和更新率(45)~(50)下,保证迭代次数k趋于无穷大时,跟踪误差以概率为1在
上收敛到零。
证明:整个证明过程分了三个步骤,分别为步骤1:证明复合能量函数随迭代次数单调递减,步骤2:证明k = 0时,复合能量函数在
是有界的,步骤3:证明关节位置
能够实现对期望轨迹
的跟踪。
步骤1:证明复合能量函数随迭代次数单调递减。
情况1:
(以下公式中时间t省略)。
设计复合能量函数
如下:
(55)
根据公式(25)和公式(55)得到:
(56)
结合公式(42)和公式(43),公式(56)可化简得到:
(57)
迭代到第k次的差值为
,则有:
(58)
将公式(44)和引理4代入公式(58)得到:
(59)
情况2:
。
设计复合能量函数
如下:
(60)
其中,
是情况1在
时刻的复合能量函数。公式(60)中
设计如下:
(61)
根据情况1得到,
。现在只需证明
是随迭代次数单调递减的。根据公式(61)得:
(62)
将公式(51)代入公式(62)得到:
(63)
(64)
根据情况2描述,
在
上小于等于0。
综上所述,根据情况1和情况2分析,复合能量函数在[0, T]区间上任意时刻的值随迭代次数增加而单调减。
步骤2:证明k = 0时,复合能量函数在
是有界的。
情况1:
(以下公式中时间t省略)。
根据公式(55)可得到:
(65)
对公式(65)进行求导得到:
(66)
将公式(32)、(41)和引理5代入公式(66):
(67)
其中,
,L是一个大于等于零的常数。则
,即
在
内有界。
情况2:
根据公式(60)可得:
(68)
其中,
是情况1在
时刻的复合能量函数,根据情况1得到,
是有界的。现在只需证明
是有界的。根据公式(61)得到
:
(69)
将公式(52)代入公式公式(69)可得到:
(70)
因为
在
是连续且有界的,所以存在常数
使得 [20] :
(71)
将公式(71)代入公式(70)得到:
(72)
根据公式(72)得到,
是有界的。所以
在
是有界的。根据情况1和情况2描述,得到复合能量函数在[0, T]是有界的。
步骤3:证明关节位置
能够实现对期望轨迹
的跟踪。
根据步骤1和步骤2得到在
时:
(73)
公式(73)进一步可得:
(74)
根据假设2 [21] 可得,
时,系统迭代到第k次的t时刻已经停止运行。
时,系统迭代到第k次的t时刻依旧在运行。根据公式(17)、公式(19)和公式(74),当迭代k趋于无穷时得:
(75)
所以,当系统的迭代次数
时,系统
成立,使得
收敛到0,即关节误差
可以跟踪到期望误差轨迹所以根据本文设计的期望轨迹误差(12)可得,在时间
上关节误差
以概率1收敛至0,意味着关节位置
能够实现对期望轨迹
的跟踪。
5. 仿真实验
本文考虑一个2自由度机械臂系统:
(76)
其中,
,
,
,
,
,
,
,
,
,
,
,
,
,
。回归矩阵
,
,
。
系统的期望轨迹qd表示为
,期望迭代长度
设置为6 s,
分布在[4, 6] s,初值
,机械臂系统参数设置为
,
,
,
。
定义性能指标
和表现跟踪状态随迭代次数变化
。其中
表示迭代长度,
表示采样间隔。
P1:采用本文设计实际控制器(38)和更新率(45)~(47)。
P2:机械臂自适应迭代学习控制,控制器设计为
,迭代自适应参数更新率设计为
。

Figure 1. Joint position q11,k and expected position signal qd1
图1. 关节位置q11,k和期望位置信号qd1
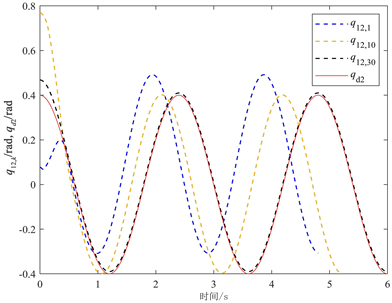
Figure 2. Joint position q12,k and expected position signal qd1
图2. 关节位置q12,k和期望位置信号qd2
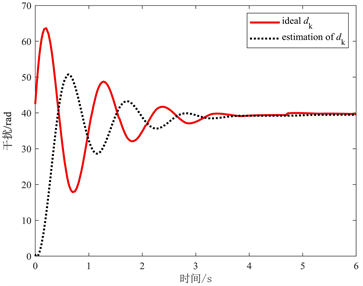
Figure 4. Approximation of dk by the 30th iteration iteration RBF neural network
图4. 第30次迭代的RBF神经网络对dk的逼近
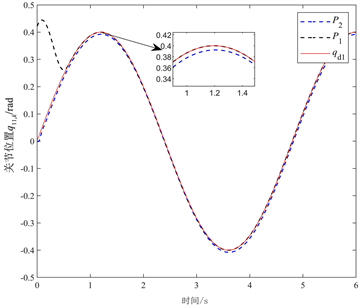
Figure 5. Joint position q11,k tracking comparison
图5. 关节位置q11,k跟踪对比
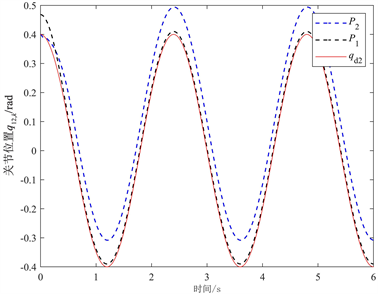
Figure 6. Joint position q12,k tracking comparison
图6. 关节位置q12,k跟踪对比
图1和图2分别表示机械臂系统的关节位置q11,k和q12,k对期望轨迹qd1和qd2的跟踪效果。由图1和图2可知,在任意初始状态下,经过足够多的迭代以后,本文所提的控制方法能够实现关节位置在指定区间跟踪期望轨迹,且在30次迭代之后,两个关节位置的跟踪精度均优于前面的跟踪精度。图1和图2还可以看出实际操作长度随迭代次数k随机变化的情况。图3描述了性能指标随迭代次数的变化趋势。随着迭代次数的增加,本文所提方法能够有效提高跟踪误差的收敛性能。通过图4可以看出RBF神经网络在Tmax = 6 s时,基本可以完全跟踪到干扰dk。图5和图6分别表示P1和P2两种控制方法下关节位置q11,k和q12,k对期望轨迹qd1和qd2的跟踪效果。由图5和图6可得,随着迭代次数k的增加,关节位置q11,k和q12,k对期望轨迹qd1和qd2的跟踪越来越精确。
6. 结论
基于RBF神经网络和迭代学习方法,本文解决了机械臂在任意初始状态下和迭代不等长的轨迹跟踪问题。针对机械臂系统的初始值问题,引入期望误差轨迹,使系统可在任意初始值时跟踪到期望轨迹。针对迭代过程不等长的问题,设计了虚拟控制器,使跟踪控制误差的收敛性也能在整个期望的迭代长度上得到保证。针对机械臂系统中的内外部干扰问题,采用RBF神经网络进行处理,提高跟踪的精确性。利用能量函数证明跟踪误差沿迭代轴渐近收敛到零,所提出新的迭代学习控制算法也可以解决传统的迭代学习控制问题。