1. 引言
随着社会的快速发展,老年人口日益增长,老年人的健康和安全问题日益引起社会关注。在现代社会,越来越多的老年人居住在独自生活的环境中,缺乏及时的照顾和照料,这使得老年人的安全问题成为一个备受关注的问题 [1] 。为了解决老年人的安全问题,许多技术方案被提出,其中最有前途的技术之一是轻量级人体动作识别技术 [2] 。
从国内社会来看,新中国建立以来,尤其是改革开放之后,我国的老年人人口数量称逐年上升之势。联合国资料显示,我国已于2000年步入老龄化社会,且己呈现出“未富先老”的姿态,人口老龄化超前于社会的发展、社会保障制度不健全、家庭模式的改变也导致家庭养老功能弱化等一系列的现实向我们展示,加强对老年人的权益保护已迫在眉睫 [3] 。但是截至到目前为止,我国尚未在法学领域对老龄化社会的到来带来的为问题做出相应的应对措施,仅一部《老年人权益保障法》(2012年12月28日通过,2013年7月1日实施)已经不足以全面的保护老年人的合法权益;我国《民法通则》和《民通意见》对于成年人监护制度的规定也只有几条,且只包含了欠缺民事行为能力的精神病人,立法理念落后,对于老年人的监护问题没有涉及 [4] 。所以必须利用法律手段,将老年人纳入成年人监护体制中,设立老年人监护制度,为老年人尤其是高龄老人的人身健康和财产管理设立保护措施,弥补老年人尤其是高龄老人意思能力或行为能力的缺陷,弥补社会保障体系不健全对老年人的人身和财产权益保护带来的不足,更好的应对人口老龄化给中国带来的挑战。从国际社会上看,近些年来人权保护的呼声日益高涨,对比社会交易安全和第三人的利益价值,人的自由和尊严价值显得更为重要 [5] 。“维护本人的生活正常化”和“尊重本人的自我决定权”理念为多数国家接受,并在本国的关于成年人监护立法的制定和修改中被纳入,大陆法系的德国、日本,英美法系的英国、美国等,尤其是日本,其修改本国的成年后见制度的背景与我国相识,都为我们以后修改我国的监护制度,建立我国的老年人监护制度提供了有益的借鉴 [6] 。
本文将介绍如何利用轻量级人体动作识别技术实现老年人的安全监控。首先,本文将介绍人体动作识别技术的基本原理和算法。其次,本文将介绍如何利用轻量级算法实现人体动作识别,以及如何将该算法应用于老年人的安全监控。最后,本文将讨论轻量级人体动作识别技术在老年人安全监控领域的应用前景。
2. 人体动作识别技术的基本原理
人体动作识别算法是一种基于计算机视觉技术的研究方向。Turaga等人 [7] 认为,“人体动作”的特点是通常由一个人执行的简单运动模式,而“活动”则更为复杂,涉及少数人之间的协调行动,并研究了识别人类行动和活动的主要方法。Poppe [8] 集中讨论了图像表示和动作分类方法,Weinland等人 [9] 的主要研究内容也集中在行动表示和分类的方法上。Popoola和Wang [10] 的研究内容重点是用于监控应用的上下文异常人类行为检测。Ke等人 [11] 研究了静态和移动摄像机的人类活动识别方法,涵盖了许多问题,如特征提取、表征算法、人体动作检测和分类。Aggarwal和Xia [12] 对基于3D数据的人类动作识别进行了研究,特别是对使用消费者3D传感器如Kinect [13] 传感器获得的RGB和深度信息进行了研究。
早期的人体动作识别算法主要基于传统的计算机视觉技术,如特征提取、分类器等。近年来,随着深度学习技术的发展,人体动作识别算法也逐渐向基于深度学习的算法发展。Cheng等人 [7] 使用基于方法的分类法研究了人类动作识别的方法,其中所有的方法被分为两类:单阶段识别方法和双阶段识别方法。此外,Vrigkas等人 [14] 将人类活动识别方法分为两个主要类别,包括“单模态”和“多模态”。然后,他们分别对这两类方法进行了研究。Subetha和Chitrakala [15] 的研究内容主要集中在人类活动识别和人–物交互方法上。Presti等人 [16] 对基于三维骨架的人类动作识别进行了研究,总结了相关的技术方法,人类动作识别中常见的方法主要是使用手工设计的局部特征,如HOG/HOF [17] [18] ,SIFT [19] ,或SURF [20] 。此外,这些方法还在视频处理中进行了扩展,以获得更强的鲁棒性,如Cuboids [21] 和HOG3D [22] 。
人体动作识别算法的基本原理是通过对人体姿态和动作的分析,提取出与动作相关的特征,然后将特征输入分类器进行分类。其主要包括以下几个步骤:
1) 数据采集和预处理:采集人体动作视频数据,并对数据进行预处理,如去除噪声、归一化等;
2) 特征提取:通过对视频数据进行分析,提取与动作相关的特征。传统的特征提取方法主要包括手工设计特征和基于卷积神经网络的特征提取方法。手工设计特征主要是通过对视频中的像素进行处理,提取出与动作相关的信息,如人体的轮廓、关节位置等。而基于卷积神经网络的特征提取方法是通过训练网络,自动学习特征;
3) 分类器:将提取出的特征输入到分类器中进行分类,常用的分类器包括支持向量机、随机森林和深度神经网络等;
4) 动作识别:根据分类器的输出结果,识别出视频中的动作。
3. 轻量级人体动作识别技术
3.1. 循环神经网络算法原理
循环神经网络(Rerrent Neural Network, RNN)在推算视频中各种动作的复杂动态的过程中具有显著优势 [23] ,因为它的结构允许存储和访问时间序列的长范围背景信息。RNN和多层感知器的主要区别在于循环连接的存在,如图1所示。
在图1中,
表示第t步的输入,
表示第t步隐藏层的状态,是网络的记忆单元,
是第t步的输出。由图1可知,RNN可以学习从以前整个历史时刻的输入映射到每个输出节点。然而,由于“梯度弥散问题”,它们的训练非常困难 [24] 。长短期记忆(Long Short Term Memory, LSTM)方法 [25] 已被提出来解决这些问题,其结构如图2所示。
图2描述了LSTM的结构和它的信息流,其中包括一个输入门
、一个输出门
、一个遗忘门
、一个输出状态
和一个存储单元状态
。信息流由下述公式描述。
上式中,
表示sigmoid激活函数,
表示网络在t时刻的输入,所有矩阵W表示单元之间的连接权重,
表示两个矩阵间对应位置的元素进行乘积。通过用两个独立的隐藏层实现双向处理数据的双向RNNs不仅能够利用以前的上下文,而且还能够利用未来的上下文。通过用LSTM单元取代双向RNNs架构中的非线性单元,我们可以得到双向LSTM,如图3所示。
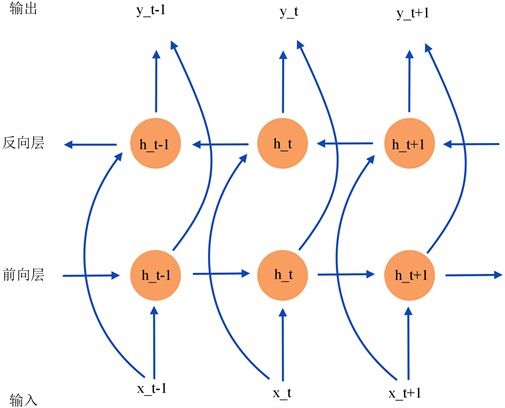
Figure 3. Structure of a Bidirectional-LSTM
图3. 双向LSTM结构图
在图3中,每个圆形节点分别代表LSTM单元。
3.2. 卷积神经网络与长短时记忆神经网络的组合架构
RNN-LSTM的主要优势是能够对时间序列的长期背景信息进行建模。这一优势使RNN-LSTM成为包括人类动作视觉信息在内的时间序列数据的最佳序列学习器之一 [26] 。而CNNs在图像数据的特征提取性能具有显著的优势,因此,本文采用CNNs与LSTM结合的组合架构来实现人体动作识别,提高老年人安全实时监控的可靠性与准确性,本文提出的CNN-LSTM的结构如图4所示。
由图4可知,CNN-LSTM网络的输入数据为2D图像,RGB图像的大小为256 × 256。经过CNN进行特征提取,将提取到的视觉特征信息展开为二维序列,经过LSTM对人体行动序列数据的计算后送入注意力机制模块中,由注意力机制模块对人体行动序列数据进行注意力打分,使得模型对重要信息更加关注,同时对冗余信息进行剔除。最后将包含注意力得分的人体行动序列数据送入全连接层,即可得到人体行动的类别识别。其中,各个阶段的网络参数如表1所示。

Figure 4. Structure of a Bidirectional-LSTM
图4. 双向LSTM结构图

Table 1. CNN-LSTM network parameters description
表1. CNN-LSTM网络参数说明
由表1可知,整体网络共包含11层,其中池化层及数据展开层因不含可训练的权重参数,不单独算作一个隐藏层。CNN-LSTM网络的最终输出为人体行动的类别。
4. 应用轻量级人体动作识别技术实现老年人安全实时监控
老年人安全问题一直是一个备受关注的问题,尤其是在现代化社会,许多老年人居住在独自生活的环境中,缺乏及时的照顾和照料。通过使用轻量级人体动作识别技术,可以实现对老年人的安全监控,减少老年人发生意外事件的概率。
老年人安全实时监控系统的设计如图5所示:
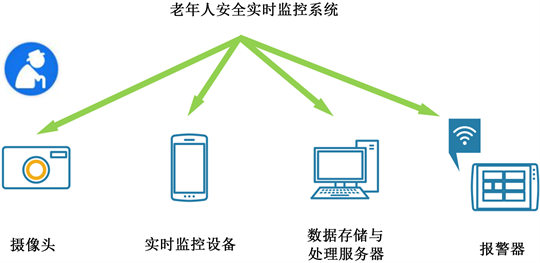
Figure 5. Real-time monitoring system composition for the safety of the elderly
图5. 老年人安全实时监控系统构成
本文提出的轻量级人体动作识别算法采用CNN与LSTM级联的组合架构,使用的硬件平台信息如表2所示。
Table 2. Hardware platform description
表2. 硬件平台参数说明
本文实验中主要涉及的软件平台及版本说明见表3。
Table 3. Software platform and version description
表3. 软件平台与版本说明
本文提出的人体动作识别算法在训练过程中使用的批大小为16,梯度优化方法使用Adam优化器,训练步数为10,000步,在不同学习率的情况下,模型的收敛情况如图6所示。
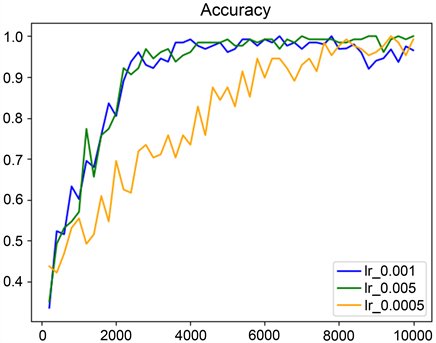
Figure 6. The convergence of the model with different learning rates
图6. 使用不同的学习率时模型的收敛情况
由图6可知,当学习率设置为0.0005时模型的收敛速度显著降低,学习率设置为0.001与0.005时模型的收敛速度相差不大,但学习率设置为0.005时效果略佳。为验证本文提出的人体动作识别算法的有效性,与时空注意力时间段网络(Spatial-Temporal Attention Temporal Segment Network, STA-TSN) [27] 、多模态视觉Transformer (Multi-Modal Video Transformer, MM-ViT) [28] 和时空交叉注意力Transformer (Spatio-Temporal Cross Attention Transformer, STAR-Transformer) [29] 算法在公开数据集UCF101 [30] 上进行了对比测试,训练过程中的准确率变化如图7所示。
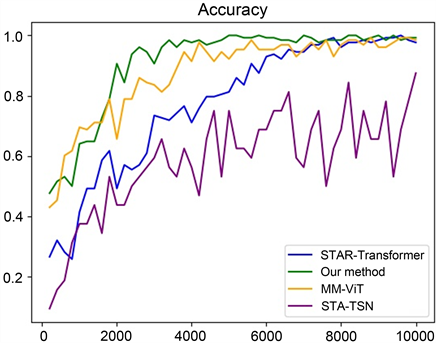
Figure 7. Accuracy curves of different models using the same environment and parameters
图7. 使用相同的环境及参数时不同模型的准确率变化曲线
由图7可知,STA-TSN算法在训练阶段的检测效果并不理想,本文提出的人体动作识别算法的收敛速度最快,且与STAR-Transformer、MM-ViT算法的识别准确率均达到较为理想的效果。四种算法在测试集中的检测结果如表4所示。
Table 4. Detection speed and average accuracy of different models on the test set
表4. 不同模型在测试集上的检测速度及平均准确率
由表4可知,本文提出的人体动作检测算法与其它主流算法相比检测速度最快、参数量最少、检测准确率最高,验证了本文提出的人体动作识别算法的可靠性与准确性。
5. 结束语
随着人工智能技术的不断发展,轻量级人体动作识别技术成为实现低功耗、低带宽设备上实时人体动作识别的有效手段。本文采用了CNN与LSTM级联的组合架构来实现轻量级人体动作识别算法,与其它主流算法相比具有显著优势,验证了本文提出的人体动作识别算法的可靠性与准确性,为老年人安全实时监控系统奠定了基础。
虽然轻量级人体动作识别技术在资源受限的设备上可以实现实时人体动作识别,但是其分类精度仍需要进一步提高,特别是在复杂场景下的分类精度还有待改进。因此,未来的研究可以重点关注轻量级算法的性能优化和多模态数据的融合,以提高轻量级人体动作识别技术在实际应用中的性能和精度。此外,在老年人安全监控系统的应用中,还需要考虑隐私保护等问题,以避免因技术的应用而侵犯老年人的隐私权。
总之,轻量级人体动作识别技术在老年人安全监控、健康管理、体育训练等领域都有广泛的应用前景。通过对人体动作识别算法的研究和优化,我们可以在低功耗、低带宽等受限资源的设备上实现实时人体动作识别,进一步推动智能化技术的发展,促进智能化生活的实现。
NOTES
*通讯作者。