1. 引言
过去三四十年中,中国经济依托人口优势,向发达经济体发起赶超。而以欧美为代表的发达国家已经历了超过百年的工业化历程。学者刘泽浩认为在当前市场动荡情况下,相比于受疫情直接冲击的零售、工业、能源和航空旅游等行业企业,投资者依然更加相信过去几年一直强势的科技股,并且相信这些科技企业也将影响着后疫情时代人类社会的发展方向 [1] 。中美在金融市场上的差距体现在很多方面,在产业结构上,美国的服务业及高科技产业在经济总量中已经占比很高。而中国经济经过四十年的飞速发展,传统制造业已经实现了超越,但在高科技和服务业等领域仍处于追赶状态。在股票市场中,A股市场中个人投资者较多,市场非理性程度较高,也造成了A股市场长期的高波动、高换手的现象。更剧烈的短期波动、更大的投机氛围会造成投资者更关注股价短期波动,而降低对估值等中长期指标的关注。而美国作为发达国家,市场起步早,金融监管体系较为完善,市场相对有序。而且与我国股票市场不同的是,国外市场虽然没有涨跌停,但市场自我纠错和调节的能力很强,长期来看比较稳定。而国内市场虽然有涨跌停的限制,但波动性却非常大,容易暴涨暴跌。其次,发达国家的投资工具相对丰富齐全,而国内尚处于金融初级阶段,投资工具还在不断的补充和完善过程中。
GARCH模型在对股票波动性分析方面一直受到众多学者青睐。邹娜和张伟运用GARCH类模型对股票市场波动性的集群现象进行了分析,并选取出了最优模型 [2] ;在对中国市场股票波动率模拟方面,周林利用实际波动率衡量标准和损失函数评价指标对GARCH类模型的波动率进行模拟并对中国市场的预测效果进行了实证研究,得出了在模拟期EGARCH模型的模拟效果相对最优的结论 [3] ;康建林等人应用GARCH模型对我国股票波动率进行应用预测分析得出了较好结果 [4] ;孙丽丽选取美的集团股票日收盘价作为研究对象,构建GARCH、SAARCH、APARCH模型对美的集团股价波动性进行分析发现SAARCH模型能较好地反映美的集团股价波动的集聚性 [5] ;刘国旗应用非线性GARCH模型预测中国股市波动,得出QGARCH模型对中国股市的波动性具有较好的预测能力 [6] 。
GARCH模型给出了对波动性进行描述的方法,为大量的金融序列提供了有效的分析方法,是迄今为止最为常用、最为便捷的异方差序列拟合模型。同时,为了拓宽GARCH模型的使用范围,提高GARCH模型的拟合精度,许多统计学家从不同的角度,构造出很多GARCH模型的衍生模型。
2. 模型及分布类型介绍
2.1. 模型介绍
GARCH模型 [7]
一个完整的GARCH(p,q)模型的结构如下:
,
且满足:
、
、
。
EGARCH模型 [7]
为了拓宽GARCH模型的使用范围,提高GARCH模型的拟合度,统计学家从不同的角度出发,构造了很多GARCH模型的衍生模型。Nelson在1991年提出了指数GARCH模型,即EGARCH模型,模型结构如下:
EGARCH模型的第一个改进是放松了对GARCH模型的参数非负约束,表达式
中的参数不需要任何非负假定;第二个改进是引入加权扰动函数
,通
过特殊的函数构造对正负扰动进行非对称处理。
GJR-GARCH模型 [8]
非对称GARCH模型,即GJR-GARCH (或称为TGARCH)模型的提出,同样解除了传统GARCH模型对其本身参数施加非负约束的限制,是另外一个能够反应杠杆效应的波动率模型。GJR-GARCH(p,q)模型假设:
且满足如下限制条件:
,
。
2.2. 分布类型介绍
正态分布 [9]
若随机变量X的密度函数为
则称X服从正态分布,记作
。称
时的正态分布为标准正态分布。
t分布 [9]
设随机变量
与
独立且
,则称
的分布为自由度为v的t分布,记为
,其概率密度函数为:
其中v代表自由度。
偏态t分布(ST) [10]
通过调节t分布的尾部厚度来生成偏t分布。首先,已知t分布的随机变量为:
,其中
和
均为独立的随机变量。则通过修改
,使
,即可得到偏态t分布
下随机变量Z的密度函数为:
记作
,其中
表示V的密度函数。若
,则为一般的学生t分布;若
,则变为
的密度函数。
3. 实证分析
3.1. 数据的选择
本文选择纳斯达克证券交易所的苹果(AAPL)和特斯拉(TSLA)以及香港交易所的百度集团(9888)和腾讯控股(0700)共四支股票的交易数据。且采用对数收益率对收盘点位进行计算,表达式为:
.
通过观察四支股票的日收益序列的时序图(如图1所示),我们发现均存在波动聚集现象。
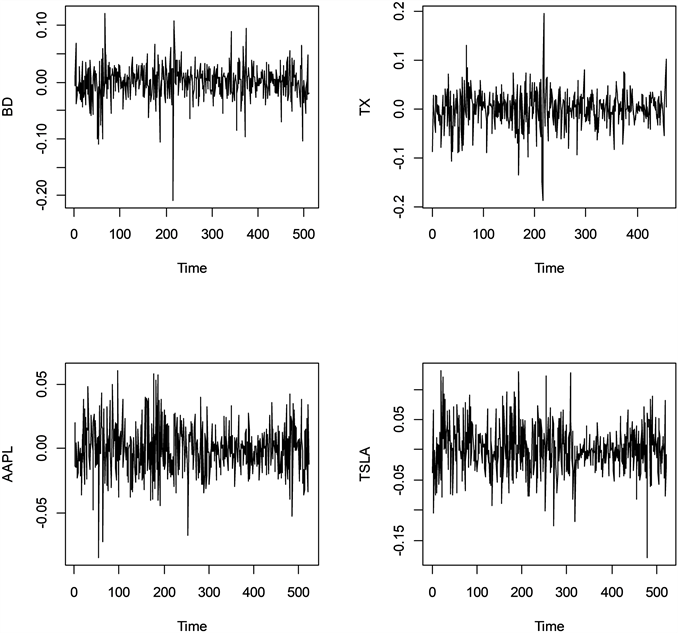
Figure 1. Diagram of daily return sequence of four stocks
图1. 四支股票的日收益序列的时序图
紧接着,对四组收益序列进行基本统计分析,如下表1所示,收益序列0700的均值为0.0007、中间值为0.0030、偏度为−0.7804,表现为作左偏且为中等偏态分布类型;收益序列9888的均值为0.0012、中间值为0.0039、偏度为−0.3386,表现为作左偏;收益序列AAPL的均值为−0.0002、中间值为−0.0005、偏度为−0.0449,左偏程度较低;收益序列TSLA的均值为0.0007、中间值为−0.0012、偏度为0.0372,为轻微右偏。

Table 1. Basic statistical of four return series
表1. 四组日收益率序列基本统计表
3.2. 数据的检验
对四组日收益序列进行正态性检验、自相关性检验、异方差性检验、平稳性检验见表2。采用Jarque-Bera统计量作为正态性检验指标,根据结果显示,四组日收益序列的Jarque-Bera统计量分别为:878.12、226.92、26.768、45.745,且p值均接近0,所以拒绝服从正态分布的原假设,表明这四组收益率序列均为非正态分布;采用Ljung-Box统计量对收益序列的自相关性进行检验,该统计量在无序列相关的零假设下,服从自由度为12的t分布。根据检验结果可知,四组序列收益率平方的Ljung-Box统计量分别为19.033、14.864、8.8887、15.277,且p值均接近0,故拒接无自相关的零假设,表明四组数据收益率的平方均存在自相关现象;采用LM统计量检验各序列的异方差性,表中LM (12)指ARCH效应的拉格朗日乘数检验,在没有ARCH效应的零假设下,统计量服从自由度为12的t分布。结果显示,各序列的p值均接近0,故拒绝无ARCH效应的零假设,认为各序列存在ARCH效应;为了避免序列的平稳性影响模型的拟合效果,采用ADF检验来对各收益率序列进行单位根检验。检验结果显示,各序列的Dickey-Fuller值分别为−7.8628、−8.3115、−7.6493、−6.6199,且p值均小于0.01,故拒绝存在单位根的原假设,认为各收益率序列是平稳的。
Table 2. Statistical table for testing each return series
表2. 各收益率序列检验统计量表
综合上述各检验统计量指标,各收益率序列存在明显的尖峰厚尾效应,JB检验同样否认了各收益率服从正态分布的假设,LM检验表明收益率存在ARCH效应,而LB检验表明收益率的平方存在自相关现象,因此可以采用条件异方差模型来分析收益率序列的波动特性。
3.3. GARCH族模型的建立
本文将分别基于正态分布、t分布、偏态t分布的GARCH、EGARCH、TGARCH来建模。EGARCH是从GARCH衍生出的模型,可用于解释“杠杆效应”,“杠杆效应”是指金融资产收益率的涨和跌对未来波动性的影响是不同的。TGARCH模型即是在GARCH模型的基础上考虑到杠杆效应,引入一个虚拟变量来表示正负冲击对金融资产收益率的影响。
下表中
为收益率的均值,
为方差方程的常数项,
为方差方程的ARCH项系数,
为GARCH项系数,
反映杠杆效应的大小。参数
和v为概率分布中的参数,其中v控制尖峰高度和尾部厚度,
控制偏斜度。
Table 3. Comparison table of estimating results of various models fitting the return series 0700
表3. 拟合收益率序列0700各模型的估计结果对比表
Table 4. Comparison table of estimating results of various models fitting the return series 9888
表4. 拟合收益率序列9888各模型的估计结果对比表
Table 5. Comparison table of estimating results of various models fitting the return series APPL
表5. 拟合收益率序列APPL各模型的估计结果对比表
Table 6. Comparison table of estimating results of various models fitting the return series TSLA
表6. 拟合收益率序列TSLA各模型的估计结果对比表
通过观察表3~6,对比得出如下结果:
在参数估计方面,收益序列0700拟合的GARCH模型除GARCH项系数显著性不高外,其它各参数均较为显著。而在添加处理杠杆效应的参数
之后,EGARCH模型在t分布和偏态t分布的信息分布假设条件下拟合效果要优于TGARCH模型。同时,通过信息准则可以判断出,在信息分布为偏态t分布时,收益序列0700的拟合效果整体较优;根据信息准则AIC和BIC判断,收益序列9888在信息分布为偏态t分布的假设条件下的拟合效果要优于假设条件为正态分布和t分布的模型。且除EGARCH模型方差方程的常数项不显著外,各参数估计结果的显著性均较好;与前两组收益率序列相比,通过AIC和BIC可以发现,收益序列APPL在信息分布为t分布的假设条件下模型的拟合效果相对最优。而且在参数估计方面,EGARCH模型的GARCH项系数
和杠杆系数
均较为显著;最后,观察AIC和BIC可知,收益序列TSLA与收益序列APPL具有相同的信息选择偏向,即在信息分布为t分布的假设条件下,我们所选取的GARCH族各模型的拟合效果最好。但有所不同的是,在参数估计方面,TGARCH模型的参数估计结果显著性较为出色,且在正态分布假定条件下的TGARCH模型的参数拟合效果最好。
结合不同收益序列对不同分布下的GARCH族模型的拟合效果,可以看出:
具有杠杆效应的EGARCH和TGARCH模型在拟合科技公司股票方面具有相对较好的效果,且TGARCH模型在处理杠杆效应方面要略优于EGARCH模型。
4. 结论
本文选取能够代表中国科技公司的“腾讯(0700)”和“百度(9888)”两支股票,以及能够代表美国科技公司的“苹果(AAPL)”和“特斯拉(TSLA)”两支股票的收益率序列进行分析,得出如下结论:其一,中美两国就科技公司股票方面收益率序列存在波动性差异较大的问题。根据收益率序列时序图的观察以及基本统计分析中偏度和峰度指标的统计,可以发现,属于美国的两家科技公司“苹果(AAPL)”和“特斯拉(TSLA)”的收益率序列的波动情况要小于属于中国的两家科技公司“腾讯(0700)”和“百度(9888)”,即前者在科技股方面收益率的稳定性要高于后者。其二,模型结果显示,GARCH族模型能够较好地拟合科技类公司股票的收益率序列。且在拟合中国的两家科技公司股票收益率序列时,选择基于t分布的EGARCH会得到较好的拟合效果;而在拟合美国的两家科技公司股票收益率序列方面,选择偏向基于正态分布的TGARCH模型。