1. 引言
图像拼接在视觉SLAM、三维重建 [1] [2] 、全景图像拼接以及医学等诸多领域被广泛应用 [3] ,是数字图像处理技术和计算机视觉领域的重要技术。在实际应用中,以Auto-Stitching等为代表的图像拼接商用软件得到广泛应用,这些软件大多基于全局的对齐方法 [4] [5] [6] ,当相机拍摄角度位置发生较大偏差、不满足单点透视要求时,很难实现准确对齐,导致拼接图像发生模糊和错位。
解决该问题的关键在于拼接过程中的特征点检测和对齐能力两方面,国内外学者对这两方面进行了研究。Lowe [7] 等提出了尺度不变特征变化(scale-invariant feature transform, SIFT)算法,通过构造差分金字塔的形式和利用高斯微分函数检测和描述特征点,该算法能够在图像旋转、尺度变化、光照变化和噪声等情况下提取出稳定的特征点,但存在误匹配。Bay [8] 等提出了加速稳健特征(speeded up robust features, SUFR)算法,通过积分图的形式检测特征点,在提取效率上对SIFT算法进行了优化,但在检测特征点的尺度不变性方面有所降低。Rublee [9] 等提出ORB (oriented fast and rotated brief)算法,该算法在特征点检测上使用快速检测(features from accelerated segment test, FAST)算法,并通过灰度质心法为特征点添加方向,在描述符生成上提出快速定向二进制描述符,有效加速了算法的效率,但该算法不能充分解决尺度不变性问题,且在光照变化较大时,提取的特征点效果不佳。Gao [10] 等使用双单应性变换(dual-homography warping, DHW)的方法,
将图像分为远平面和地平面,对应区域分别投影,该方法相比全局投影方法在对齐能力上有所提升,但对大视差图像拼接效果依然较差。许越 [11] 等通过全局单应性先对图像进行对齐和网格划分,根据特征点分布调整变换矩阵,提高图像的对齐能力。Julio Zaragoza [12] 等提出的APAP (As-Projective-As-Possible Image Stitching)算法,利用传统的SIFT算法提取兴趣点,使用随机采样一致算法(Random Sample Consensus, RANSAC)筛选错误点,进行局部平面变换将图像划分为网格形式,通过移动线性变换(moving direct linear transformation, MDLT)对每个网格形变矩阵进行高斯加权,这种方法在很大程度上解决了由视差引起的全景图错位和重影问题,但对特征点和正确匹配率要求较高。Chang [13] 等提出在重叠区域采用投影变化,在非重叠区域采用相似变换的版投影变换方法,能够解决在重叠区域扭曲现象,但面对大视差图像时仍然需要结合APAP模型进行拼接。Lin [14] 等在APAP模型的基础上提出了尽可能投影(Adaptive As-Natural-As-possible, AANAP)算法,将投影变换、相似变换和仿射变换相结合,使拼接的图像在视觉上效果更佳。文献 [15] 使用改进的ORB算法和APAP模型进行图像拼接,提升了拼接的效率,但ORB算法提取的特征点不具备尺度不变性,并且在光照变化较大时不能够提取出稳定的特征点。
以上对大视差图像拼接的研究,大多使用传统的特征点提取方法进行特征点检测或是对现有模型APAP模型进行改进,但APAP模型非常依赖提取点的准确性和重复性。近年来随着深度学习技术不断发展,基于深度学习的特征提取在鲁棒性、稳定性方面都优于传统特征提取,因此,本文提出一种深度学习和APAP模型结合的大视差图像拼接算法。在特征点提取上采用基于学习的SuperPoint网络 [16] 进行特征提取,使用基于学习的SuperGLue网络 [17] 寻找最优匹配点和剔除垃圾点,最后通过APAP模型进行局部投影变换进行拼接,利用加权融合方法 [18] 进行融合。该方法能够融合深度学习在特征点提取上的鲁棒性、正确匹配率优势,提高最后拼接图的质量。
2. 总体技术框架
基于学习和APAP模型结合的图像拼接算法流程图如图1,分为图像采集、图像预处理、图像匹配和图像融合几部分。
图像预处理环节解决图像包含噪声、尺寸不一等问题,将输入的两张图像,先进行缩放处理,将大小统一为640 × 480,其次对图像进行灰度化和高斯滤波处理,最后得到相应的灰度化图像。
图像配准包含特征点检测、特征点匹配、图像拼接三部分,是研究的重点。特征点检测使用基于学习的SuperPoint模型进行提取,对图像进行卷积池化,得到特征点和描述子。特征点匹配使用SuperGlue网络,通过在得分矩阵最后增加一层垃圾通道得到增广矩阵,将表现能力低的特征点进行剔除,将得分能力强、匹配率高的特征点进行保留,最小化特征点间的代价矩阵,得出最优匹配关系。最后在APAP模型中将原始图像进行网格划分,估计出图像间对应网格中局部投影变换模型,对局部变换模型进行高斯加权,最后通过局部变换模型实现图像的拼接。
为解决拼缝还使用加权融合算法对图像进行融合。

Figure 1. Overall technical flow chart of image mosaic
图1. 图像拼接总体技术流程图
3. 基于深度学习的大视差图像拼接算法
3.1. 特征点检测
文使用DeTone D [16] 等设计的SuperPoint网络结构进行特征点检测,SuperPoint是一种轻量级、端到端的特征点及描述子提取网络,网络框架主要由共享编码器和解码器两部分组成,如图2所示,其中解码器由兴趣点解码器和描述符解码器组成。
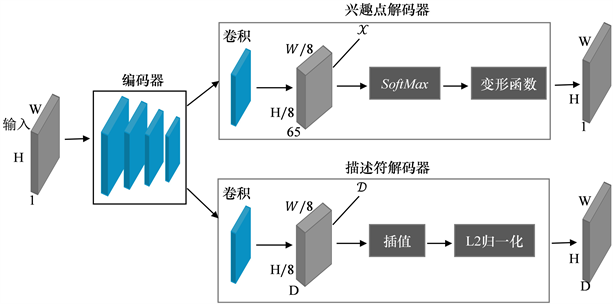
Figure 2. SuperPoint Network Structure
图2. SuperPoint网络结构
编码层采用VGGNet [19] 架构中的卷积层,当输入图像的尺寸为
,经过编码层的卷积、池化后输出的张量尺寸为
,其中
,
,将低维输出的张量
组成的像素称为单元。编码层将输入的图像
映射到较小空间尺寸和具较大深度通道F的中间张量
,其中
,
,
。
兴趣解码器将输入的
(65代表8 × 8的局部区域外加一个额外的无兴趣点的通道)张量进行计算处理,输出尺寸为
的张量,并输出尺寸为的张量
,D表示描述符解码器的通道深度,然后解码器执行描述符的双三次插值,最后执行
标准化输出描述符。为了恢复为
,在特征点检测和描述符的解码器出均使用上采样。
3.2. 特征点匹配
SuperGlue是通过卷积神经网络进行图像特征点匹配,对两张图像中提取到的特征点和描述子输入到网络中,输出两张图像之间的匹配关系,特征点主要是通过求解可微分最优传输问题来进行匹配。如图3为SuperPoint网络结构。
SuperGlue网络主要由注意力图神经网络和最优匹配层组成,如图3所示。其中注意力图神经网络层由关键点编码和注意力聚合网络构成,关键点编码将关键点和描述子编码为一个向量,通过多层感知机(Multilayer Perceptron, MLP)将低维向量映射为高维向量。为了得到表现更强的描述符
,使用自注意力层和交叉注意力层交替更新。关键点位置和描述子的融合后的每个特征点i的初始表示为
。
(1)
其中
表示图像上第i个特征点,
表示第i个描述子,MLP表示多层感知机。
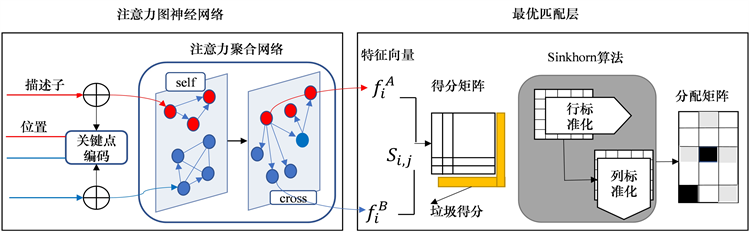
Figure 3. SuperGlue network structure
图3. SuperGlue网络结构
注意力聚合网络中模拟人来回浏览匹配过程,使用自注意力和交叉注意力交替聚合。在图像I上的更新公式可以表示为如下:
(2)
其中
、
表示图I上第i个特征点在L层的中间表达式,
表示自注意力和交叉注意力特征聚合,在图像
上采用类似的方式进行更新。
在最优匹配层最大化总得分
,得到分配矩阵P,其中
为匹配分数值,对注意力聚合网络中得到的描述符
和
进行内积运算得到匹配得分如式3所示。利用Sinkhorn算法 [20] 求解分配矩阵,得到最佳匹配。
(3)
3.3. APAP模型拼接
完成特征点的提取和匹配后,使用APAP模型求取图像间的局部投影变换模型,然后完成拼接和融合。假设图像A和B为一组需拼接的图像,则它们检测出的特征点对为
和
,特征点对之间的对应关系为:
(4)
齐次坐标p和q对应的变换关系表示为:
(5)
在上式中矩阵
,
,由于p和q在同一个方向,满足
,因此,将特征点p和q带入可求得矩阵H:
(6)
将上式可以转化为
,即
(7)
求出的h可以表示为:
(8)
求出单应性矩阵H后,通过Moving DLT算法对每个小方格中的局部单应性矩阵进行高斯加权,则网格内的局部单应性矩阵可以表示为:
(9)
其中,j为将图像划分为
的图像块的数量,
为每个网格中的高斯权重,得到每个网格中的局部单应性矩阵后,通过变换参数完成图像拼接。
3.4. 图像融合
由于视差等因素,图像配准后存在拼接痕迹,因此,采用加权平均融合算法 [18] 对图像进行融合。通过取权重的方式对重叠区域中待融合点赋予贡献值,使拼接后的画面自然平滑过渡,提升拼接图质量。加权融合算法公式如式10所示。
(10)
其中
为融合后图像的灰度值,
为左侧图像的灰度值,
为
在图像上除去重叠区域后的区域,
为右侧图像的灰度值,
为在
图像上除去重叠区域后的区域,拼接后重叠区域为S,
和
为重叠区域的一个权值,并且
,
。本文采用渐入渐出法计算权值,权值计算公式如式11所示:
(11)
其中,D为两幅图像中重叠区域的长度,d为重叠区域中待融合点与左边界点的距离。
3.5. 算法性能评价
对特征匹配中的匹配性能,采用重复率和正确匹配率对算法性能进行评价,重复率在整个匹配过程中占据重要位置,重复率的高低以及稳定程度都会影响最终的匹配结果和特征点的鲁棒性。对重复性和正确率的性能测试都是基于Mikolajczyk标准数据集测试,对于传统的匹配算法,使用SIFR、ORB、SUFR算法提取特征点,然后用快速最近邻算法进行匹配,最后用随机抽样一致(random sample consensus, RANSAC)算法 [21] 进行提纯。
重复率的计算 [22] 定义如下。
(12)
其中,
为待匹配图像中对应的特征点个数,
和
分别为源图像和待匹配图像中检出的特征点个数。
正确率的 [22] 定义如下:
(13)
其中,MatchScore为正确匹配率,
为正确匹配点的个数,
为对应特征点的个数。
和
为源图像A和待拼接图像B中对应特征点的坐标,H为图像A映射到图像B的投影变换模型,
表示图像A映射到图像B中对应特征点的坐标,对映射后的
和
求取欧式距离,距离小于
的点为正确匹配的点。
为了评价拼接图的质量,本文采用通用型无参考图像质量评价算法,NIQE (natural image quality evaluator, NIQE)算法 [23] 对拼接图的质量进行评价,NIQE指标越小,图像质量越高。NIQE算法评价图像质量主要是对原图像进行图像特征提取,通过提取的特征拟合多元高斯(MGV)模型,计算模型参数v和
,计算公式如下:
(14)
其中
为提取出的图像特征,v和
为MGV模型的均值和方差。再进行待评估图像特征的提取,拟合多元高斯(MGV)模型,计算模型参数
和
,通过计算评估图像与多元模型(MGV)之间的距离来对图像质量进行评价 [23] :
(15)
其中
为原图像和待评估图像的MGV模型均值和方差,NIQE指标越小,图像质量越高。
4. 实验结果及分析
4.1. 测试数据及环境
为了验证本文算法的有效性,分为两部分进行实际验证,分别为特征匹配性能和拼接性能,并用传统的算法进行比较。在特征匹配中采用Mikolajczyk标准数据集进行匹配性能测试,该数据集包含图像模糊(bikes),光照变化(leuven),图像压缩(ubc),视点变化(wall),在图像拼接性能中采用公用大视差图像拼接实验数据集进行测试,在进行实验前,将两组数据集图像的分辨率调整为640 × 480。
实验硬件测试环境为Intel(R)Core(TM)i7-11800H 2.30GHz,内存为16.0GB,编程平台为PyCharm2020,编程语言是python语言。并调用OpenCV等所需库。SIFR、SUFR和ORB算法是调用OpenCV中相应的算法函数。
4.2. 特征匹配性能分析
对特征匹配中的匹配性能,采用重复率和正确匹配率对算法性能进行评价,并与传统SIFT、SUFR和ORB算法进行对比分析,其中使用Repeatability%表示图像中提取体征点的重复率,该值越稳定,表示提取特征点鲁棒性越强。MatchScore评价图像间的正确匹配率,MatchScore值越大,正确匹配率越高。
图4和图5为本文算法和传统算法提取出的特征点可视化图以及特征点匹配可视化图,图像为Mikolajczyk数据集中模糊变化图像,上面为原图像上特提的特征点,下面为模糊图像上提取的特征点,可以看出本文所提算法提取出的特征点是一些纹理剧烈变化、结构变化明显的点,分布比较均匀。在匹配方面对不同数据集都能达到稳定的匹配效果。

Figure 4. Visualization of feature points
图4. 特征点可视化图

Figure 5. Visualization of feature point matching
图5. 特征点匹配可视化图
如图6和图7为本文算法和传统匹配算法在重复率和正确匹配率的比较图,其中(a)、(b)、(c)及(d)分别为Mikolajczyk标准数据集中图像模糊变化(bikes)、图像光照变化(leuven)、图像压缩(ubc)和图像视点变化(wall)。1_2至1_6分别表示第一张图和后面每张图像匹配。
从图6(a)、图6(b)以及图6(c)可以看出,SuperPoint + SuperGlue算法面对bikes、leuven以及ubc数据集时,提取出特征点的重复率都比较稳定,并且重复率也比较高,而传统的ORB算法重复率下降比较明显,SIFT、SUFR算法在bikes和leuven数据集上重复率虽然能够维持稳定,但重复率相比本文算法要低20%左右。在ubc数据集上,传统算法的重复率下降非常明显,本文算法依然维持稳定。在wall数据集上,本文算法重复率虽然有所变化,但相比传统算法本文算法依然趋于稳定,重复率高出传统算法30%左右。说明本文算法相比传统特征匹配算法对不同场景下获取的图像都能提取出稳定的特征点,特征点的鲁棒性较强,在进行图像匹配时能够在一定程度上消除匹配误差,提高匹配的正确匹配率。
 (a) bikes
(a) bikes  (b) leuven
(b) leuven  (c) ubc
(c) ubc 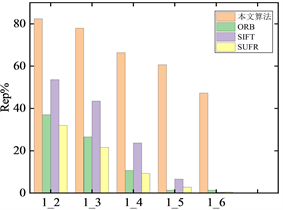 (d) wall
(d) wall
Figure 6. Comparison of repetition rates
图6. 重复率比较
 (a) bikes
(a) bikes 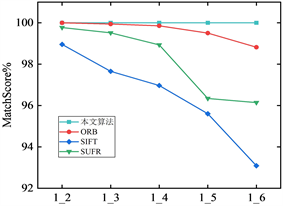 (b) leuven
(b) leuven 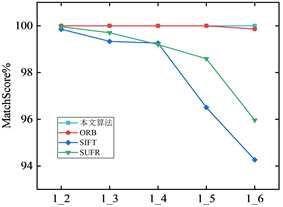 (c) ubc
(c) ubc 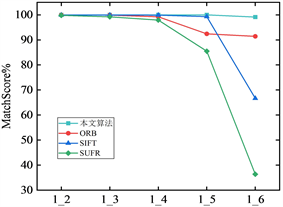 (d) wall
(d) wall
Figure 7. Comparison of correct matching rates
图7. 正确匹配率比较
在正确匹配率方面,图7显示本文所使用算法在四种数据集上几乎能够达到99%的正确匹配率,匹配率维持稳定,变化不大,能够在不同场景下进行正确匹配,虽然在有些数据集上和其它传统算法正确匹配率相差不大,但整体上优于传统算法。可见本文所提算法的描述能力更强,匹配率更高。
4.3. 图像拼接性能
本文采用公共图像拼接数据集,通过ORB、SIFT、SUFR算法和本文的深度学习算法对待拼接的两幅图像进行特征提取和匹配,然后用APAP模型计算出图像间的局部投影变换模型,完成拼接。
如图8为本文算法用上面四种数据集图像拼接出的效果图,显示拼接出的效果图也符合人眼视觉效果,基本上消除了由于视差带来的重影问题。

Table 1. NIQE values of different algorithms
表1. 不同算法的NIQE值
表1为本文算法和传统算法进行拼接后图像质量NIQE结果,可以看出,在进行大视差图像拼接时本文算法(SuperPoint + SuperGlue)在匹配的准确率和重复性方面都略优于传统的算法,在进行大视差图像拼接时,本文算法(SuperPoint + SuperGlue + APAP)最后拼接出的图像质量评价指标NIQE相比传统(ORB, SIFT, SUFR + RANSAC + APAP)算法拼接出的图像质量评价指标NIQE降低6.5%左右。
5. 结论
本文提出的深度学习和APAP模型相结合的大视差图像拼接方法,采用SuperPoint网络进行特征提取和描述符,用SuperGlue进行特征点筛选和最优匹配,利用筛选出的特征点求取原图像和待匹配图像之间的全局单应性矩阵,使用APAP模型将图像进行网格划分,将全局单应性通过Moving DLT算法对每个小方格进行高斯加权,求出图像间的局部投影变换模型,最后完成拼接。
通过实验表明,本文所提算法和传统的ORB、SIFT和SUFR算法相比,重复率高出传统算法20%左右,在各种数据集上提取的特征点趋于稳定,有很强的鲁棒性。正确匹配率方面也优于传统算法,本文算法达到99%的正确匹配率。面对具有大视差的图像时,拼接出的图像质量效果也较好,基于深度学习的算法(SuperPoint + SuperGlue)在匹配的准确率和重复性方面都优于传统的算法。
基金项目
广西重点研发计划项目(2021AB01021)。
NOTES
*通讯作者。