1. 引言
密码算法在硬件设备上运行会产生功耗消耗、电磁辐射、热量消耗等敏感信息。通过利用这类泄露的秘密信息对密码进行分析的方法称为侧信道攻击。能量分析属于侧信道攻击的一种常见攻击方法,其本质上利用了数据依赖性和操作依赖性两类。Kocher [1] 在其开创性文章KJJ99中就基于上述理论证实:对于功耗分析攻击没有保护的智能卡很容易被破坏。侧信道攻击使含密码的各种芯片设备安全遭到巨大挑战。
能量分析包含简单能量分析(SPA, Simple Power Analysis) [2] 、差分能量分析(DPA, Differential Power Analysis) [3] 等。能量分析亦可分为有学习和无学习两类。有学习的能量分析包含模板攻击(TA, Template Attack) [4] 、随机攻击(SA, Stochastic Attack) [5] 。有学习的能量分析中,攻击者拥有与目标设备相同的类型的设备,并使用多元正态分布对能量迹构建汉明重量或者中间值模板,最终使用这种模板对密钥进行恢复。
对于密码的软件实现中,为了保证密码算法的实现不受功率分析攻击,最经典的则是掩码技术 [6] 和乱序技术 [7] ,另外一种则是隐藏技术 [8] 。密码设备的能量消耗依赖于算法执行过程中所处理的敏感中间值,掩码技术和乱序技术则是针对该中间值进行“掩盖”,从而切断敏感中间值与能量消耗之间的相关性来达到防御侧信道攻击。
近年来随着机器学习的发快速发展,各种有学习的神经网络构建的高效模型涌现,如基于cnn的侧信道攻击模型、基于mlp的侧信道攻击模型等。本文针对低熵掩码技术和S盒乱序技术提出基于vit-transformer的新型侧信道攻击模型。
2. 相关概念
2.1. 高级加密标准(AES)
高级加密标准 [9] 是当今最流行的加密标准。它是一种对称密码算法,可以在各种平台上有效地实现。它还可以用于身份验证。因此,对于许多安全相关的应用来说,它是一种很有吸引力的算法。AES算法限定明文分组长度为128 bits,而密文长度可分文128、192、256 bits,因此AES有三个版本:AES-128、AES-192、AES-256,相应的迭代轮数分别为10、12、14。如下表1所示。

Table 1. Relationship between AES algorithm’s grouping, key length and encryption rounds
表1. AES算法的分组、密钥长度和加密轮数的关系
AES加密具体过程为密钥和明文首先进行第一个轮密钥加,之后各轮AES进行加密循环过程,除最后一轮不包含列混淆操作。包含4个基础循环步骤:字节替换(SubBytes)、行移位(ShiftRows)、列混淆(MixColumns)、轮密钥加(AddRoundKey)。每个步骤具体如下:
1) 字节替换(SubBytes):通过非线性替换函数(S盒)把每个字节替换成相应的字节。
2) 行移位(ShiftRows):将每行以字节为一个单位进行循环式移位。
3) 列混淆(MixColumns):经过行移位后的矩阵乘一个固定矩阵得到一个混淆矩阵。
4) 轮密钥加(AddRoundKey):矩阵的每一个字节与该次循环的子密钥做异或运算。
字节替换是AES算法中唯一非线性变换处理,非线性变换不受控,因此绝大多数功耗泄露都发生在该步骤。掩码以及sbox乱序防护对策也是针对此处泄露而设计。
2.2. SBOX乱序和加掩方案
加掩方案是使用一个称为“掩码”的随机值(攻击者无法获取该掩码),它与中间值混合,导致攻击者无法预测功耗。掩码核心思想是将每个敏感变量X随机分割为
份
,且满足
这样的群运算 * (例如x异或、模加法)。通常
(掩码)为随机抽取而
(掩码变量)满足
,参数d通常称为掩码阶数。当执行时(即当所有的掩码在不同的时间被处理时),d阶掩码能至少抵御
阶泄露。
乱序变换在侧信道防御中也是一种简单且有效的对抗的手段,它通过引入随机数使密码设备在执行加密过程中对其操作顺序随机化。乱序变换将敏感变量X信号分布于t个不同时间泄露信号
。如
果分布均匀,那么对于每一个i,
对应于对X的操作的概率是
。因此,X上瞬时泄漏的信噪比降低了
t。乱序应用很简单,与保护层的性质(线性或非线性)无关。此外,当应用于非线性层时,乱序变换通常比高阶掩蔽的成本要低得多。由于高阶掩蔽是昂贵的(额外电路资源),而且一阶掩码可以轻松被攻破,所以一个自然的想法是将乱序与一阶掩码结合使用。
2.3. 卷积神经网络
卷积神经网络 [10] 主要由卷积层、池化层、全连接层。卷积神经网络通过卷积层(卷积神经网络的核心)对输入的数据进行特征提取,然后将提取的特征数据作为池化层的输入,池化层通过最大池化或平均池化这两种操作来降低数据维度,其具有平移不变性。在实际的使用中,卷积层、池化层、全连接层的层数和大小都可以根据具体的情况而调节。在侧信道攻击中常使用一维的卷积核池化,具体如图1所示。
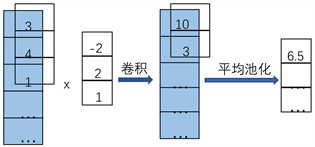
Figure 1. One-dimensional convolution and pooling
图1. 一维卷积与池化
2.4. ViT
2017年Vaswani等人 [11] 提出自注意机制且完全抛弃RNN和CNN等网络结构来构建一个全新的网络结构Transformer。因该网络没有任何卷积操作,具有高度并行能力,能有效缩短训练时间。其后Dosovitskiy等人 [12] 基于Transformer模型提出ViT,此模型在计算机视觉领域效果甚好,吸引众多领域的研究者使用。ViT模型如图2所示。
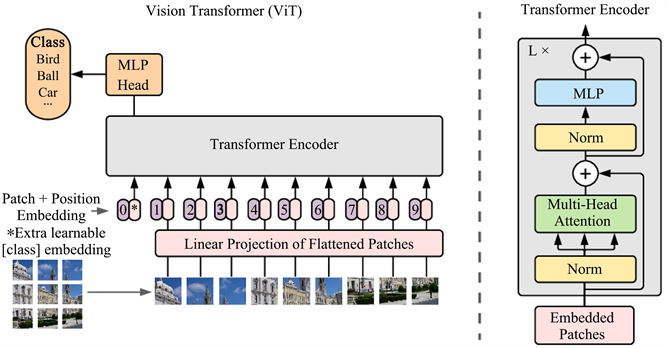
Figure 2. Vision transformer model
图2. Vision Transformer模型
ViT模型在结构上摒弃了Transformer的Decoder部分,只保留了Encoder。在编码时(上图右部分Embedded Patches),ViT首先对一个图片划分为n * n个固定大小的patch输入,然后需要对每一个patch再映射到实际需求的一个维度(使用一个layer层对其映射,或者使用一个卷积层操作)。ViT使用了包含查询、键和值的自注意机制,自注意力机制能对大量数据中重要数据进行注意,而忽略不重要的数据。
3. 基于ViT模型设计
本节主要介绍改造VIT模型,该模型对Embedded Patches层、Multi-head Attention层、MLP层做了调整,以便使该模型更好的适用于Sbox乱序和加掩方案的攻击。VITSCA模型结构如图3所示。
3.1. 嵌入层
能迹样本作为模型的输入,嵌入层会对样本做初步的处理,提高注意力模块对重要样本的注意。嵌入层采用一维卷积层,一维卷积能将能迹样本的一个CPU时钟采样周期缩短为一个样本,且该卷积层的特点在于卷积核不共享权重,能对多个位置的能耗信息进行交叉组合,对后续掩码以及Sbox乱序攻击达到预处理效果。
3.2. 注意力机制
LC嵌入编码后,直接进行注意力编码,使用基于标准VIT模型修改的模型。在标准VIT模型中:输入来源于Patch Embedding模块加上Position Embedding模块数据;自注意力编码部分使用一个查询向量Q和一个键值对集合(KV)。基于ViT模型修改模型:输入与输出形状相同,以便叠加N层自注意编码,使其能对大量数据进行训练,得到更好的训练效果;自注意编码部分使用权重矩阵cls_token (单独生成且固定)对输入序列计算单向注意力,用于的对序列样本进行加权处理。cls_token表示样本的权重,权重大小表示样本的重要程度,既样重要本的权值大,非重要样本的权值小。对有效提高对掩码和Sbox乱序攻击效果。对于编码器的输入X与输出cls_token满足如下公式:
(1)
(2)
公式(1)中:self_attention函数为自注意机制主要函数。其中右边X为自注意力机制的输入部分,它来源LC层输出,且其映射为K。而Q为cls_token所映射而来,并且self_attention函数输出作为下一轮
样本输入(即K)。
称为缩放因子,当乘积在数量级上增长时,其会将softmax函数推向具有极小梯度的区域。为了抵消这种影响,可以对点积扩展
倍。f函数为注意力函数,其均包含一层multiply、Dropout、Dense层。f函数可以提高模型拟合能力和模型表达能力。
公式2中:cls_token经过Dense后数据,将其映射为原本的cls_token维度后作为下一轮的Q。cls_token单独为一个注意力加权序列,从始至终都将分类信息保存在一个固定大小的序列中,有利于控制过拟合。经过多层的注意力得到多个cls_token,对所有cls_token做平均,提高模型的准确度。
特别注意的是在f函数中,通过注意力加权后(对于注意力机制中的多头是采用所有头部信息取和还是求每一个头部信息的均值会在第四节中实验分析中论述),用相同Dense映射为与cls_token大小相同的向量,得到和注意力多头大小的cls_token维度的序列。好处如下:
1) 注意力头编码序列长度为注意力头数,可以尽快降低数据复杂度(筛除无效样本)。
2) 这种编码合并了所有嵌入样本的信息,全局性更强。
3) 模型的复杂度由头数和注意力块的内部维度决定。
经过注意力编码后,注意力头编码序列长度缩短,可以有效控制模型大小,以便使用更大批次进行训练。注意力编码是全局组合,使用模型可以尽早开始寻找能耗的非线性组合方式,以便从大量数据中进行学习,找到重要的样本点进行攻击。
3.3. 分类层
自注意模块中最终输出有两类如公式(1)和公式(2),其中公式(1)的数据将会被舍弃,而公式(2)的输出cls_token保存了样本权重(即最终的分析特征),也做为分类器的输入。分类器设计为三层的残差块,有且仅包含一层dense层和Dropout层。分类层最终输出一般为256。
4. 实验设计与结果分析
4.1. 实验环境和数据
实验环境为搭载了4块NVIDIA GeForce RTX 2080 Ti GPU的服务器,所创建模型基TensorFlow2.0搭建,并在改实验环境进行模型训练以及侧信道攻击。
数据1采用DPAcontest国际侧信道大赛的DPA_contestv4_2。该数据具有sbox乱序防护和低熵掩码防护措施。该数据在AtmelATMega-163智能卡上以AES-256实现,其该包含80,000条能迹,采用16种不同的密钥,每个密钥有5000个能迹,每条能迹样本大小为1,704,402。DPA_contestv4_2采用加掩防护与Sbox乱序相结合的技术。该数据方案通过掩码将敏感数据进行屏蔽,且引入乱序索引数组的方式分别对AES算法的第一轮与第十轮中16个非线性S盒变换的执行顺序进行随机化保护,进而能够在单条能量曲线上有效隐藏S盒能量泄露的产生位置。由于样本点大,不能对整个样本进行攻击,只需对泄露区间样本攻击。s盒输入
被掩码
屏蔽,s盒
又被
屏蔽,S盒输入与输出存在相同的寄存器中,寄存器活动可记为
,
和
是平衡的,但
与
不平衡。本实验对该数据划分,60,000条能迹作为训练集,20,000条能迹作为验证集。
数据2使用ASCAD SCA Database提供的ASCAD,该数据具有掩码防护措施。ASCAD由50,000条训练集和10,000攻击集组成,每条能迹包含700样本点,样本点包含AES第一轮加密和第三个Sbox输出操作的能耗信息。(在第1轮加密中,与密钥关联的第1个字节和第2个字节未受到掩码保护,即前2个字节的掩码为0,其余14个密钥字节掩码都是随机的)。
4.2. 实验指标
Standaert等人 [13] 指出侧信道攻击中的标准度量是成功率和猜测熵。本文采用猜测熵作为模型的评价指标。猜测熵是指在攻击一个子密钥时,子密钥在候选子密钥队列中的平均排名。当攻击一个sbyte的子密钥时,我们需要使用模型计算各种猜测子密钥的得分,即根据能耗向量,使用训练好的模型“预测”猜测中间值的概率(一般取其对数值),以此作为猜测子密钥的得分。根据各猜测子密钥的得分对它们进行降序排序,猜测熵越小,模型质量越好。猜测熵如公式(3):
(3)
其中,
表示密钥猜测最终得分,
表示获得正确密钥得分,ge为猜测熵。
4.3. 实验分析
4.3.1. 数据集DPA_contestv4_2的实验分析
本文将基于ViT的侧信道模型与基于MLP、一维卷积的攻击进行了对比。本文建立上述三个攻击模型后,用60,000能迹训练集对其进行训练,20,000能迹对其验证。
多数神经网络模型在训练前都会设置一些模型参数,如多层感知器网络中的隐藏层数量,大小和激活函数等。由于这些参数是执行前指定的,而不是模型中学习的参数,因此被称为超参数。攻击模型的超参数设置比较困难,因此需要使用超参数寻求器,它们包含:网格寻优器、贝叶斯寻优器、随机寻优器,本文模型使用的是随机寻优器。使用超参数寻优器的目的是对超参数的各种取值进行交叉组合,使用超参数的每个组合配置模型,然后进行模型训练。根据模型最终使用验证集取得的猜测熵,确定并保存最佳模型。
由于DPA_contestv4_2能迹样本点数量庞大,因此只截取一小部分样本(该小段只包含了一个S盒的加密能耗,剩下S盒的能耗就成了噪音)作为输入。该部分样本包含了剔除大量噪声样本仅保留了有关掩码防护和Sbox乱序部分的能耗泄露。采用上文提到注意力机制中的多头采用所有头部信息取和的攻击效果如图所4示。
CNN模型,在所需能迹数为1时猜测熵达为52.9,而在19条时为0;MLP模型,在所需能迹数为1时猜测熵为15.7,在18条时为0;VITSCA模型,在所需能迹数为1时猜测熵为1.5,在10条能时为0。从图4可以看出本文提出的基于ViT侧信道攻击模型能对存在少量噪音的数据进行学习而得到一个有学习的攻击模型,验证了本文提出的模型有效性,且在攻击效果上明显优于传统MLP模型和CNN模型。
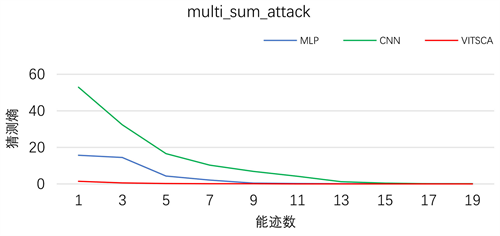
Figure 4. Average guess entropy of MLP, CNN and VITSCA sum on DPA_contestv4_2
图4. MLP、CNN、VITSCA和在DPA_contestv4_2的猜测熵
由于图4实验只截取了整个能迹的一小段,且无其他噪音。通过能迹规律,将样本数扩充至一轮S盒的时(一轮S盒包含16个S盒),此时样本点的数量达到了47,000,并且训练集中包含大量噪音,对模型的训练形成严重干扰。采用上文提到注意力机制中的多头采用每一个头部信息取和的攻击效果如图5所示。
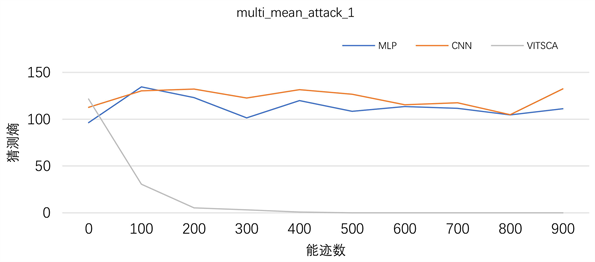
Figure 5. Average guess entropy of MLP, CNN and VITSCA mean on DPA_contestv4_2
图5. MLP、CNN、VITSCA均值在DPA_contestv4_2上的猜测熵
对于MLP模型和CNN模型,随着能迹数的增加,猜测熵几乎大于100以上,可知当样本点为47,000时MLP和CNN对此数据无效。对于VITSCA模型,随着能迹数的增加,猜测熵逐渐减少,当能迹数为500时为0,可知本文提出的模型对具有对Sbox乱序和低熵掩码数据攻击的有效性。
4.3.2. 数据集ASCAD的实验分析
ASCAD样本集大小只有700,直接将全能迹作为样本点,依旧使用MLP、CNN、VITSCA实验结果如图6所示。

Figure 6. Average guess entropy of MLP, CNN and VITSCA mean on ASCAD
图6. MLP、CNN、VITSCA均值在ASCAD上猜测熵
从图中可以看出MLP以及CNN模型猜测熵都在100以上,可以MLP和CNN模型无效。VITSCA模型猜测熵随着能迹数增大而减少,当能迹为300时,猜测熵为0。由此再次证明本文提出模型的有效性。
5. 结束语
本文基于Vision Transformer模型,提出针对低熵掩码和sbox乱序的有学习的神经网络模型。该模型主要针对ViT模型的Attention部分做了重要修改,主要设计cls_token作为对样本集权重的注意,权重的大小作为评判标准。本文模型与传统的MLP模型和CNN模型进行分别在DPA_contestv4_2和ASCAD数据集上进行实验对比。在DPA_contestv4_2数据上进行了两种方案的实验,两种方案的结果证明了该模型的有效性,也即针对掩码和Sbox乱序防护密码算法的有效攻击。
基金项目
四川省科技计划资助(项目号:2021ZYD0011)。
NOTES
*通讯作者。