1. 引言
随着全球环境不断恶化,温室气体排放,尤其是CO2排放,已经成为世界共同关注的问题,根据国际能源署的分析数据,2021年全球与能源相关二氧化碳排放量增至363亿吨,全球二氧化碳排放量的绝对增幅超过20亿吨,均创历史新高,其中,我国二氧化碳排放量超过119亿吨,占全球总量的33%。面对碳减排的严峻形势,我国政府意识到这不仅会导致全球环境恶化,而且会影响我国的国际形象和声誉,因此向世界做出“二氧化碳排放力争于2030年前达到峰值、于2060年实现碳中和”(以下简称“双碳”目标)的承诺。为了实现这一目标,精准预测碳排放强度走势,实施行之有效的低碳经济政策具有至关重要的意义。
面对日趋严峻的碳减排形势,国内外学者不断深入对碳排放预测的研究,碳排放预测主要可以分为两种:一种是基于时间序列预测技术,这类模型仅使用预测变量的历史数据,比如,应用ARIMA [1] 、Logistic [2] 等统计模型取得令人满意的预测效果,但统计学方法在数据规模、稳定性、分布等方面都有一定的要求,鉴于这种局限性,越来越多的学者使用机器学习方法进行预测研究,例如,赵成柏 [3] 、Niu [4] 等基于神经网络模型对各自国家的碳排放强度做出预测,尽管人工神经网络具有很强的提取非线性信息的能力,但无法处理小规模数据,因此吴振信 [5] 、Wang [6] 等应用传统及改进的GM(1,1)模型预测并且精度较高;另一种是基于多变量预测技术:碳排放是一个复杂的系统,不仅受过去信息的影响,还受其他因素的影响,Wang等 [7] 利用STIRPAT模型定量分析与人口、富裕度和技术进步之间的关系,进行碳排放预测,Hang [8] 、Cao [9] 、Ma [10] 等基于改进的GM(1,N)模型预测碳排放,考虑了碳排放的多种影响因素,包括社会、经济和环境因素。
多变量灰色预测模型作为灰色理论的重要分支,已经被广泛应用于生产生活的具体实践中 [11] ,为了进一步提高GM(1,N)模型的预测精度,很多学者对其进行了有价值的改进,比如考虑到时滞现象广泛存在,黄继 [12] 、毛树华 [13] 、王正新 [14] 等学者都分别提出了多变量灰色时滞模型,案例分析表明新模型能够有效地解释变量间的时滞关系。丁松引入线性交互关系的作用项,构建基于交互作用的IEGM(1,N)的模型 [15] ;Tien引入一个控制参数到GM(1,N)模型的微分方程构建中,并结合卷积积分求解白化方程,记改进模型为GMC(1,n)模型 [16] ;丁松对于虚拟变量控制的GM(1,N)模型,给出了具体的模型构建方法和严格的数学证明 [17] ;Zeng在传统灰色微分方程右边增加一个线性修正项h1(k − 1)和灰作用项b,记为NGM(1,N)模型 [18] ;Pei等利用插值函数优化GM(1,N)模型背景值,并通过遗传算法对插值系数最优求解 [19] 。针对现实系统中非线形特征的问题,周伟等考虑因素间非线性关系,提出非线性GM(1,N,
)和GM(1,N,
)优化模型,并运用BP神经网络对模型进行拟合求解 [20] ;王正新通过引入幂指数,提出多变量灰色幂模型及其派生模型 [21] ;丁松等基于各驱动因素在不同阶段对系统行为变量的差异化作用效果,构建多阶段驱动控制的多变量离散灰色幂模型 [22] ;Wang和Ye将幂指数思想引入灰色多变量预测模型中,构建了NGM(1,N)模型 [23] ;针对多变量时滞非线性系统的预测建模问题,构建了累积时滞非线性多变量离散灰色ATNDGM(1,N)模型,给出了模型参数求解方法 [24] 。
在回顾有关GM(1,N)模型及其扩展的研究现状后,我们发现上述灰色模型在结构上大多具有线性特征,这的确为模型的构建和求解带来了方便。然而碳排放是一个复杂的系统,不仅受过去信息的影响,还受其他因素的非线性影响,多种因素对碳排放还存在复杂的时滞效应。为此,本文在GM(1,N)模型的基础上,考虑相关因素的滞后效应,通过幂指数体现相关变量对系统行为变量的非线性特征,并利用蜻蜓算法求解幂指数,进一步提升了模型的泛化能力,再通过改进后的模型对我国碳排放量进行预测,研究结果为我国未来产业发展和政府决策提供参考。
2. 时滞GM(1,N)幂模型
2.1. 模型构建
定义1设系统行为序列为:
,相关因素序列为:
,
为正整数,且
。设相关因素的
期滞后序列为
,
为
的一阶累加生成(1-AGO)序列,
为
的紧邻均值生成序列,则称:
(1)
为具有时滞特征的GM(1,N)幂模型(Delay Grey Power Model of N Variables),记为DGPM(1,N)模型。其中:a为系统发展系数,
为驱动项,
为驱动系数,
为的幂指数,
为时滞参数,反映了第i个相关变量在经过时滞
个时刻后对系统行为变量的非线性作用,
为灰常数项。
定理1 根据参数
、
和常数项
的取值,有如下结论:
1) 当
时,DGPM(1,N)模型退化为GM(1,N)幂模型;
2) 当
且
时,DGPM(1,N)模型退化为时滞GM(1,N)模型;
3) 当
且
时,DGPM(1,N)模型退化为GM(1,N)模型。
证明 1) 将
代入式(1),则DGPM(1,N)模型可表示为:
(2)
即为GM(1,N)幂模型。
2) 将
且
代入式(1),则DGPM (1,N)模型可表示为:
(3)
即为时滞GM(1,N)模型。
3) 将
且
代入式(1),则DGPM(1,N)模型可表示为:
(4)
即为GM(1,N)模型。
定理2设
,
,
如定义1所述,
则参数列
的最小二乘法满足:
1) 当
且
时,
;
2) 当
时,
;
3) 当
时,
。
证明 将
代入模型可得,
即
(5)
1) 当
且
时,B存在逆矩阵,方程存在唯一解,即
;
2) 当
时,B满秩分解为
,得到B的广义逆矩阵为:
(6)
则
(7)
3) 当
时,B为列满秩矩阵,F可取为单位矩阵,则
,故而可得
(8)
4) 当
时,B为行满秩矩阵,E可取为单位矩阵,则
,故而可得
(9)
定义2称
(10)
为DGPM(1,N)模型的白化微分方程。
定理3设
,
,
,
如定义1所示,B、Y、
如定理2所述,则
1) DGPM(1,N)模型白化方程的解为
(11)
2) 当驱动因素序列变化幅度较小时,模型驱动项可以被视为灰常量,则近似时间响应函数序列为:
(12)
3) 一阶累减还原式为:
(13)
证明 1) 由白化微分方程式(10)可得通解公式
(14)
其中C为待定常数。将初始条件
代入式(14),可得
(15)
将式(15)代入式(14)便可得式(11),定理3中(1)得证。
2) 将驱动项看作灰常量,则白化微分方程的通解为
(16)
其中C为待定常数。将初始条件
代入式(16),可得
(17)
将式(17)代入式(16)便可得式(12),定理3中(2)得证。
3) 利用一阶累减还原算子即可证明定理3中(3)的结论成立。
2.2. 时滞期pi识别
在DGPM(1,N)模型构建过程中,时滞参数的识别和计算是核心之一,为了充分利用影响因素包含的信息,本文基于灰色扩维识别和灰色关联分析识别驱动因素及其滞后期
,以提高建模预测精度。具体思路如下:
定义3设系统行为序列
,相关因素序列
如定义1所示,依据灰色扩维识别方法,可以得到
个与
等长的扩维子序列:
设影响因素
的
期滞后序列
与系统行为序列
的灰色绝对关联为
,公式如下:
其中,
和
为
和
的始点零化象。设关联度阈值为r,若存在
,则称
为系统的强关联因素。
定义4
、
、r、
如定义3所示,假设
为系统的强关联因素,有:
1) 当仅存在
使得
时,
滞后于
,则该序列可作为驱动因素,将
和
均纳入DGPM(1,N)模型对
进行模拟和预测。若存在多个子序列均满足
,
,记
,
的滞后参数为
。
2) 当仅存在
使得
时,
与
同期,即为滞后期为0的特殊情况,直接将
纳入DGPM(1,N)模型对
进行模拟和预测;
3) 当仅存在
使得
时,
先行于
,则该序列不被纳入DGPM(1,N)模型,因为无法获取将来数据,不满足建模条件。
2.3. 幂指数优化
在DGPM(1,N)模型中,反映相关因素变量对系统行为特征变量非线性作用关系的幂指数
是未知的,它直接影响模型的精度,在建模过程中,必须事先确定参数的具体数值,然后通过最小二乘法构建B和Y矩阵来才能估计出参数列,进而获得模型的时间响应函数进行模拟和预测。为此,本文以建模数据的误差最小化为准则,采用以下目标函数:
(18)
如式(18)所示,该函数具有非线性特性,一般方法难以计算,为了获得最优的幂指数和背景值权重,必须接近上述函数的最小值,为此,本文与大多数带参数的灰色预测模型类似,利用非线性智能优化算法找出最优参数。蜻蜓算法(Dragonfly Algorithm, DA)是受蜻蜓群体的捕食和迁徙行为启发所提出的一种群搜索智能算法 [25] ,该算法不仅具有粒子群算法的个人认知和社会认知能力,同时结合了布谷鸟算法中Levy飞行行为,在算法寻优过程中能够有效避免陷入局部最优,提高算法的搜索性能,为此选用DA算法来求解模型的最优参数。根据以往对DA算法的研究,其一般流程主要可以概括为:
首先,根据式(18)中的目标函数建立向量和适应度函数,可以表示为:
(19)
其次,设置参数:确定种群规模N、当前迭代次数t、最大迭代次数T以及优化变量上下限,随机初始化初始位置X和步长
,并用模型中的参数构建初始位置坐标
,计算个体的适应度并排序,记录和保存当前最优解。
为了在空间中模仿蜻蜓的飞行方式和位置更新,DA算法设置了步长向量和位置向量。步长向量定义如下:
(20)
其中s为分离权重,a为对齐权重,c为聚集权重,f为猎物权重因子,e为天敌权重因子,w为惯性权重。蜻蜓算法原理是模拟蜻蜓寻找食物,并躲避敌人时的群集动态过程,主要可以分为以下5种行为模式:
① 分离。个体与同类分开的行为,避免发生碰撞。
(21)
其中
表示分离度,X表示当前个体的位置,
表示相邻第j个个体的位置,N表示个体的数量。
② 对齐。个体在飞行时与相邻个体之间的速度匹配。
(22)
其中
表示对齐度,
表示相邻个体速度。
③ 聚集。个体与相邻同类之间彼此聚在一起的集群行为。
(23)
其中
表示聚集度。
④ 捕食。个体为生存搜寻猎物的行为。
(24)
其中
表示食物吸引度,X+表示食物位置。
⑤ 避敌。个体出于生存的本能,需时刻警惕天敌的行为。
(25)
其中
表示天敌排斥度,X−表示天敌的位置。
位置向量的表达式为:
(26)
如果附近没有蜻蜓,蜻蜓的位置将使用Levy飞行方程进行更新:
Levy函数计算如下:
(27)
(28)
其中,
表示莱维飞行随机搜索路径,
表示随机生成数,
是一个常数。
然后,更新食物源位置X+、天敌位置X−以及s、a、c、e、f和w,再按公式(21)~(25)更新S、A、C、E和F,按公式(20)和(26)~(28)更新步长和位置。
最后,当适应度函数满足终止条件时,确定幂指数和和背景值权重,即迭代至最大次数。
2.4. 建模步骤
时滞GM(1,N)幂模型的构建过程具体包括以下几个步骤:
Step1:收集并处理原始数据;
Step2:运用灰色关联识别驱动因素和滞后期,并纳入模型构建;
Step3:将MAPE作为个体适应度函数构建优化模型,利用蜻蜓算法求解非线性参数
;
Step4:将幂指数代入参数列
,计算模型的拟合预测值,检验模型的精度,若不通过,转Step1重新分析相关因素及其参数;
Step5:采用GM(1,1)模型或时间序列模型对各驱动因素
进行预测;
Step6:根据各驱动因素
的预测值,利用DGPM(1,N)模型预测系统行为序列
。
3. 实证分析
精准预测碳排放,有利于制定科学的减排路径,对于我国发展低碳经济具有重要的参考意义。为了验证新模型在实际应用中的有效性,本文将灰色预测模型应用于我国未来二氧化碳排放评估,本文分别建立经典GM(1,N)模型、GM(1,N)幂模型、时滞GM(1,N)模型以及DGPM(1,N)模型,将它们的结果进行比较,寻求最优的模型形式,并对我国未来碳排放进行预测。
3.1. 数据来源与分析
从我国二氧化碳排放量历史数据来看,如表1所示,2000年前,中国二氧化碳排放量增速基本稳定于5%左右;2001年~2010年,中国二氧化碳排放量保持高速增长,一度高达18%;在2011年以后,中国开始实行较为严格的环保政策,再加上节能减排技术的应用以及居民环保意识的加强,碳排放增速开始下降,基本保持在5%以下,该背景下的建模数据量有限,时序长度仅为12年;另外,碳排放问题的来源和成因较为复杂,尤其是受到经济发展、能源消费、产业结构等众多因素的影响,并且影响作用强度未知、互动关系不确定,并且它们之间极可能存在非线性关系。而灰色预测理论以有限信息源的不确定问题为研究对象,通过对部分信息已知的小样本信息挖掘和开发,提取有价值信息,从而实现对系统未来发展趋势的准确描述。另外,从新信息优先原理角度,相较于往期数据,新数据含有更丰富的趋势信息,有利于把握未来发展方向,因此,从中国碳排放特征及新信息优先角度考虑,灰色预测模型适用于预测中国碳排放趋势。
本文选择我国碳排放量X1 (百万吨)为系统特征变量(数据来源:《世界能源统计年鉴2022》)。首先,经济的增长是中国CO2排放量暴增的最主要驱动因素;其次,化石能源燃烧则是人类活动排放二氧化碳的主要活动方式,中国是全球最大的能源生产国、消费国和二氧化碳排放国,近88%的二氧化碳排放来自能源系统;另外,产业结构也是影响碳排放量非常重要的因素之一,作为能源消耗和二氧化碳排放的最主要领域,我国工业领域碳排放占全国碳排放总量的70%左右,工业领域碳达峰是我国“双碳”目标实现的最重要决定因素。基于本文碳排放主要影响因素,选取国内生产总值X2 (亿元)作为经济水平指标,能源消费总量X3 (万吨标准煤)和能源效率X4 (吨/万元)作为衡量我国能源消费情况的指标,第二产业占比X5 (%)作为衡量我国产业结构的指标,相关影响因素自2010至2021的数据整理如表所示(数据来源:《中国统计年鉴2022》)。可以发现,所有变量的量纲和数量级都不一致,在计算过程中比较容易出现矩阵漂移的情况,故本文采取初值化方法进行预处理。

Table 1. Statistical values of carbon emissions and related factors in China
表1. 我国碳排放及影响因素统计值
3.2. 驱动因素选取与滞后效应分析
首先,利用2.2节构造的时滞灰色关联模型确定各影响因素在不同时滞时期与我国碳排放量关联度值,结果如表2所示。然后在分析过程中,确定我国碳排放总量的强关联因素选取的阈值是
,确定碳排放量的驱动因素。最后选取最大关联度值对应的时滞长度作为时滞期,进而确定输入模型的相关因素序列。
Table 2. Correlation values of influencing factors at different time lags
表2. 影响因素在不同时滞期下的关联度值
由表2可知,国内生产总值在不同时滞长度下与碳排放总量的关联度值均小于阈值,表明国内生产总值不是碳排放量的强关联因素,因此暂不将X2纳入DGPM(1,N)模型中。能源消费总量在不同时滞长度下与碳排放总量的关联度值均大于阈值,表明能源消费总量是碳排放量的强关联因素,同时可以看出关联度在时滞期为3时达到峰值,从三期序列往两边呈现递减趋势,因此将X3纳入DGPM(1,N)模型中,并将时滞参数p3取3。能源效率随着滞后期的增大呈现增长趋势,说明能源效率的变化对碳排放的影响存在滞后效应,但可以看出时滞期取时都没有达到阈值,因此暂不将X4纳入DGPM(1,N)模型中。产业结构与碳排放量的关联度在滞后期为3时达到阈值,说明其对碳排放的影响存在明显滞后性,因此将X5纳入DGPM(1,N)模型中,并将时滞参数p5取3。
3.3. 模型构建与对比
根据3.2节的对驱动因素的识别和时滞分析,假设X1表示我国碳排放总量,X3表示能源消费,X5表示产业结构,建立我国碳排放总量DGPM(1,N)模型:
首先,利用DGPM(1,N)模型对2014年~2019年我国碳排放量进行模拟,将平均绝对百分误差MAPE选作适应度函数,构建优化模型,再利用蜻蜓算法求得非线性参数,拟合误差为1.16%。
其次,利用最小二乘法求得参数列,代入参数可得DGPM(1,N)的时间响应函数;
最后,利用时间响应函数对2020年~2021年的碳排放数据进行测试,测试误差为0.54%。模拟和测试阶段结果如表3所示。
Table 3. Comparison of fitted and tested values of China’s carbon emission models
表3. 我国碳排放量模型的拟合和测试值比较
为了检验DGPM(1,N)模型的有效性,本文选择GM(1,N)模型、时滞GM(1,N)模型、和GM(1,N)幂模型作为对比模型,其模拟和测试阶段结果也如表3所示,可以看出,DGPM(1,N)模型的拟合和测试误差均低于其他模型。其中,GM(1,N)模型的拟合效果都不太理想,GM(1,N)模型的拟合误差达5.29%。时滞GM(1,N)模型在传统GM(1,N)模型的基础上考虑驱动项的滞后效应,虽然拟合效果没有明显变好,但2020年~2021年测试误差明显有所下降,因此预测我国碳排放量需要考虑相关因素的滞后效应;GM(1,N)幂模型的拟合误差为1.29%,明显小于前三种模型,这是由于GM(1,N)幂模型引入幂指数考虑驱动因素对碳排放量的非线性作用,但GM(1,N)幂模型测试阶段误差反而更高,达3.8%,因此也不适用于我国碳排放未来趋势预测。而本文提出的DGPM(1,N)模型不仅考虑驱动因素对碳排放量的非线性作用,同时进一步讨论驱动因素的滞后效应,因此模拟和测试精度都比较较高,平均拟合误差为1.16%,测试误差为0.54%。
3.4. 碳排放未来预测
由3.2节可知,DGPM(1,N)模型对2014~2021年我国碳排放量模拟和测试效果都明显优于其他模型,因此本节选用DGPM(1,N)模型进一步对2022~2025年我国碳排放的整体走向及结构变动进行预测,以期对未来我国节能减排目标的实现进行合理预估,提供有效的政策建议。在进行后续预测之前,根据新信息优先原理,本文利用新陈代谢GM(1,1)模型预测相关因素的数据,然后将新数据代替旧数据输入模型,从而获得我国2022~2025年碳排放总量数值,结果如表4所示。根据表1和表4绘制出我国2013~2025年的碳排放整体趋势曲线(图1)。由图可知,我国碳排放依然保持增长趋势,需要采取相关的政策措施来减缓碳排放增速。
Table 4. Predicted value of carbon emissions and intensity in China
表4. 我国碳排放量及碳排放强度预测结果
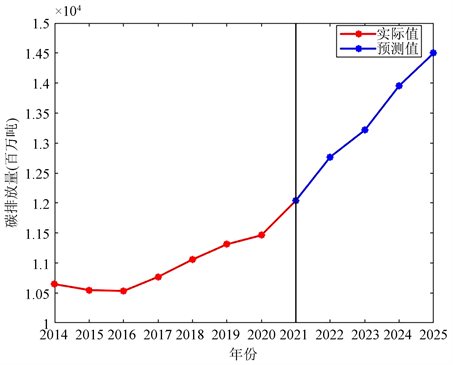
Figure 1. Overall trends in carbon emissions in China (2014~2025)
图1. 我国碳排放总量整体趋势(2014~2025)
为了判断我国能否达成“十四五”规划纲要中的减排目标,即到2025年,单位国内生产总值二氧化碳排放比2020年下降18%,本文在预测国内生产总值的基础上,同样对2022年~2025年的碳排放强度进行预测,结果如表4所示,可以看出,我国碳排放强度在未来将继续保持下降的发展态势,这一趋势与我国加快推进“碳达峰,碳中和”目标相一致。但2020年我国碳排放强度为1.1308吨/万元,从预测结果来看,2025年我国碳排放强度为0.9644吨/万元,比2020年下降14.76%,无法完成既定18%的目标,因此,中国继续按部就班地推进碳减排是远远不够的,需要采取更强有力的政策措施,加快经济社会发展全面绿色转型,进一步夯实碳达峰碳中和工作基础。
4. 结论与建议
本文基于时滞的GM(1,N)幂模型,预测了我国2022~2025期间二氧化碳排放趋势。新模型不仅满足了GM(1, N)的原始性质,而且有效地反映了驱动因素的非线性作用和时滞效应,保证了小样本情况下的模型预测精度。此外,利用蜻蜓算法优化其非线性参数,确定时间响应函数的最优值,进一步提升了模型的泛化能力。本文利用该模型对我国碳排放进行实证分析,结果表明,DGPM(1,N)模型具有较高的模拟和测试精度,可以用来准确预测部分未知系统的行为。
由3.4可知,中国碳减排强度虽未能达到“十四五”约束性目标,但是差距尚可弥补,通过继续深化改革,加大力度推进减排措施的实行,有望于2025年达成18%的约束性目标。本文将从主要影响因素方面,为中国政府制定节能减排政策提供以下建议:
1) 优化能源消费结构,推动新型能源体系建设。
首先,要重点控制化石能源消费,化石燃料燃烧是中国主要的二氧化碳排放源,占全部二氧化碳排放的88%左右。煤炭是我国能源消费的主体,只有降低煤炭消费比重,才能从根本上提高能源利用效率。世界主要发达国家已就减排工作达成“退煤”的共识。比如,德国决定到2030年完全退出煤炭的使用;波兰、加拿大等众多发达国家表示将在2030至2040年间逐步淘汰煤电。“去煤化”已成为各国能源结构调整的大趋势。但对于中国而言,完全“去煤”可能需要更长时间,但应有计划加快煤炭减量步伐,助力“双碳”目标实现。其次,要提高清洁能源在我国消费结构中所占的比重,根据碳达峰的行动方案,我国提出到2030年,非化石能源消费比重达到25%左右。因此,在保障我国能源系统安全稳定的前提下,大力发展清洁能源是必然的选择。清洁能源具备环境友好、资源丰富、可循环利用等优势,如今,中国在光伏发电、海上风电等绿色能源的发展规模和技术上有了大幅提升,但清洁能源产业起步较晚,还需继续创新推广清洁能源技术,推动能源清洁化转型。
2) 深度调整产业结构,推动重点领域节能降碳。
首先,积极促进第二产业内部绿色低碳转型调整,工业是我国能耗和排放的主体,但同时也是我国实体经济的基石,面临降能耗与稳制造两难选择,要促进新兴技术与绿色低碳产业深度融合,遏制高消耗、高排放、低水平项目的盲目发展,逐步淘汰落后产能和化解过剩产能,建设高水平产业体系;其次,要提高第三产业的比重,发展高质量服务业。在数字经济的背景下,促进数字赋能型、知识驱动型及消费导向型新兴服务业发展,既能提高产值,又能减少能源消耗。是要大力培植绿色低碳产业,加快发展节能环保、清洁生产、清洁能源、生态环境、绿色服务等新兴产业,逐步形成煤炭产业和非煤产业占比合理、良性互动的产业格局。
3) 打造政策支撑体系,推动发展方式绿色转型。
实现“双碳”是一项复杂的系统性工程,需要深度的管理创新、科技创新、金融的支持和企业的参与,而且政策性很强,既要防止一刀切、简单化,又要防止转型缺乏力度,多措并举才能深刻地推动中国经济社会发展全面绿色转型。首先,绿色金融是低碳经济发展的重要支撑,可以考虑更多借助绿色金融产品,完善全国碳排放权、排污权及用能权交易市场及体系,以市场化原则引导更多社会资本进入绿色低碳领域,充分利用市场机制控制减少碳排放。其次,政府财政补贴可以促进企业进行绿色创新。在政府补助方式中,财政补贴对新能源企业开展环保事业、进行绿色创新的促进作用最为明显的。