1. 引言
随着当今社会信息技术的飞速发展,数据量呈现几何级数增长,社会逐步进入大数据时代,普通的单机系统已经无法满足复杂的海量数据计算以及应对实际场景下的高并发连接处理请求和强大的容错机制。大规模分布式集群计算机系统作为单机系统的扩展和延伸,由于其高性能、高扩展、高可用的特性迅速得到了人们的关注,越来越多的边缘服务系统采用集群的思想 [1] 。随之而来的,在大规模分布式集群系统环境下,如何保证集群系统的安全性、如何使集群系统更加高效且稳定的运行,成为了亟待解决的问题 [2] 。
为了更好地发挥集群系统性能,使集群系统正常工作并充分利用节点的资源,对集群系统资源以及其计算节点的各个性能指标进行实时地监控预警就变得尤为重要 [3] [4] [5] [6] 。计算机分布式集群监控领域存在一些各具特色的开源的监控软件系统 [7] ,但都存在一定的局限性。Nagios是一款企业级的开源监控软件,文献 [8] 设计并实现了一个基于Nagios的服务框架,该框架可以自由的检测各种主机和服务资源,当监控对象发生异常或者异常恢复的时候还能提醒指定的用户。但Nagios也存在着缺点,它针对服务失效后的成功监测率不尽如人意。文献 [9] 设计了一种基于Zabbix的网络监控系统,针对不同网络中的主机硬件资源和应用程序软件资源进行有效监控预警,因其良好的稳定性和普适性,可广泛应用于企业的服务器和应用程序的监控中。但Zabbix在及时响应系统故障方面有待改进,同时前端展示界面较为简陋。
本文利用Prometheus [10] [11] [12] 和Grafana [13] [14] [15] 以及睿象云的优势特性及功能,再经本文设计的集成中间部件调节,实现了一个集成中间件监控预警系统,通过此系统实现了对集群服务系统的资源监测和异常预警,能有效提高系统监测能力,更迅速地响应系统故障,降低系统资源消耗。此系统主要由三个部分构成:
1) 监控:本文设计的集成中间部件采集到监控数据后对数据进行格式转换,再由Prometheus主动去中间部件拉取监控数据。实现了对集群系统各指标的实时监控,包括监控信息的采集、存储、计算和实时查询与历史信息查询,如中央处理器(Central Processing Unit, CPU)负载、CPU利用率、内存利用率、GPU利用率、服务运行状态和服务饱和度等;
2) 展示:本文设计的集成中间部件对接开源可视化组件Grafana,利用自定义传输协议将监控信息传输到Grafana,以此进行监控指标的前端可视化界面展示;
3) 预警:Grafana配置数据源为集成中间部件后会进行告警界限的配置,当指标结果超过指标预设阈值后,Grafana会告知第三方智能告警平台睿象云,让其实现多种方式告警。
此集成中间件系统经集成中间部件调节,监控、展示、预警三大模块的数据流通,能全方位保障大规模分布式集群系统的安全稳定运行,当系统发生故障时,后台管理人员能及时收到通知并做出快速反应,将损失降到最低。
2. 系统功能概述
集成中间件监控预警系统对各主机硬件性能指标、应用程序服务运行状态和饱和度信息提供了采集、存储和实时查询以及历史信息查询等功能,并对采集的指标信息进行前端可视化界面展示,同时在展示组件内部对各监控指标进行自定义告警规则设定,超过告警阈值后采用多种方式执行告警。系统总体功能如图1所示。
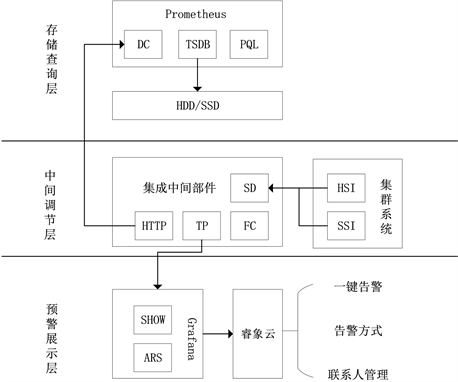
Figure 1. System overall function design
图1. 系统整体功能设计
集成中间部件的数据汇总模块SD (Summarization of Data)主动收集边缘服务系统的硬件资源信息HSI (Hardware Resource Information)和软件资源信息SSI (Software Resource Information),经数据格式转换模块FC (Format Conversion)转换数据格式后,Prometheus的数据采集模块DC (Data Collection)通过集成中间部件暴露的HTTP接口来主动拉取主机性能监控指标和软件资源监控指标;监控指标的数据存储由Prometheus的时序数据库模块TSDB (Time-series Database)完成,其会定期拉取监控数据并按照时间序列的方式存储在本地磁盘中;和关系型数据库的SQL类似,Prometheus也内置了数据查询语言PQL (Prometheus Query Language),其提供对时间序列监控数据丰富的查询,聚合以及逻辑运算的能力 [16] 。
集成中间部件对接跨平台的开源可视化组件Grafana,将获取的监控信息通过信息传输模块TP (Transport Protocols)传输给Grafana后,可利用展示模块SHOW在前端监控界面进行集群系统监控数据的展示,同时也可以在告警规则设置模块ARS (Alarm Rule Setting)上自定义各项监控指标的告警规则。当超过预设的预警阈值时,利用集成的第三方智能告警平台睿象云进行多种方式告警,并提供一键告警、多种方式告警和告警联系人管理等功能。
3. 集成中间件监控预警核心技术
3.1. 监控技术
本文监控技术主要靠集成中间部件的SD实现,其安装在目标主机上,充当一个agent [17] 的角色,其采集到监控数据后,将其组织成K/V的形式发送给集成中间部件,之后集成中间部件的FC将数据转换为Prometheus能理解的时间序列数据形式。集成中间部件会暴露出一个HTTP接口供Prometheus查询,Prometheus通过基于HTTP的pull的方式来周期性的拉取数据,同时集成中间部件可调用PromQL对监控数据进行查询。集成中间部件和集群系统以及Prometheus的数据流向接口如图2所示。
FC组件根据格式转换算法DFCA(Data Format Conversion Algorithm) [18] 将SD收集到的K/V类型数据Data进行数据类型转换,转换后的时间序列数据格式Samples如下所示:
{
其中,metric name为指标名称,{}里面为标签,它标明了当前指标样本的特征和维度,最后面的Svalue则是该样本的具体值。
DFCA算法伪代码如下所示:
PromQL查询举例如下所示:
求CPU第一个核内核态在使用时间上过去一分钟的增长量
increase(node_cpu_seconds_total{cpu=’1’,mode=”system”}[1m])
由于边缘服务系统内监控指标多种多样,本文在此选取部分硬件、软件指标进行说明。
3.1.1. 硬件指标采集原理
集成中间部件的SDClient通过读取主机系统文件来采集主机的硬件性能指标,如CPU、内存、GPU、磁盘、网络等相关信息。采集后的数据由FC组件根据DFCA算法进行格式转换。
主要监控内容如表1所示。

Table 1. Hardware monitoring object
表1. 硬件监控对象
3.1.2. 软件指标采集原理
软件监控数据同样由集成中间部件的SDClient进行采集,然后利用本文集成中间部件的FC组件内的DFCA算法进行格式转换。SDClient采集的软件信息主要包括两个:
1) 应用程序服务的运行状态信息
举例说明,IP地址为10.1.1.190的服务器内部Kafka服务运行状态,具体数据如下所示:
kafka_status{exported_job=”kafka-metric-899”,host=”10.1.1.190”}1
此数据表明IP地址为10.1.1.190的服务器内部的Kafka服务正常运行。
集成中间部件的SDClient对服务运行状态信息的采集主要依据心跳算法E-H实现 [19] 。该算法基于Redis [20] [21] ]作为通信缓冲区实现,各服务周期性往Redis发送累加的心跳值,SDClient会根据每个服务的唯一K-V值去Redis取到各服务的心跳值,若本周期取到的心跳值是上一周期服务心跳的累加后的结果,证明服务正常工作,若本周期取到的心跳值等于上一周期的心跳值,证明服务失效,此时SDClient会将服务失效信息以K/V形式推送给集成中间部件的SDServer,中间部件的FC组件利用DFCA算法转换数据格式并提供HTTP接口,以便Prometheus主动拉取监控数据。
该算法的伪代码如下所示:
2) 应用程序服务的饱和度信息
本文设计了一种服务饱和度的计算方法,该算法可以根据主机硬件性能所得出的服务理想处理能力以及服务主动推送的实际处理能力来计算得出服务工作时的饱和度,集成中间部件通过SD获取到饱和度指标信息并传输给Grafana后,Grafana可自定义对饱和度划分级别,分为服务过载、服务饥饿、服务正常,当服务过载或者服务饥饿时能够由睿象云执行告警,使得系统管理人员及时处理问题,实现整个系统的资源负载均衡 [22] 。
对于影响服务理想处理能力的硬件选取的多个维度和指标的集合,定义为G (Group),这个集合包含N个维度和指标R (Rule),既
。每一个硬件维度或指标都对应一个理想情况下的处理能力值V (Value),每个处理能力对应一个权值K,表示在总理想处理能力值中该类规则的比重。则按照如下的格式,对服务理想处理能力进行计算:
(1)
对于服务实际处理能力可由服务在特定周期T内的总负载L得出,
(2)
因此,服务饱和度计算公式如下所示:
(3)
由上述服务饱和度计算公式(3)可以看出,饱和度计算的关键因素有四个:一是服务实际运行时的处理能力。二是硬件指标和维度集合,这决定了饱和度计算模型的动态结构。三是维度和指标的数字化赋值,需要进行标准化定义来确保各项指标采用同一套数值系列来描述处理能力。四是维度和指标的权值,决定了各维度在计算结果中的比重并直接影响计算结果。
这里给出的是普适性的饱和度计算方法和规则,读者可根据特定业务需求选择不同的维度和指标的集合,针对特定场景下的服务饱和度进行计算。
综上,监控技术的实现主要是依靠集成中间部件的SD组件实现,其依附在被监控系统上,充当“侦察兵”的角色,收集好数据后再利用本文FC组件内的DFCA算法进行格式转换,之后监控数据再流向Prometheus或者Grafana,实现了完整的数据流通过程和实时监控功能。
3.2. 监控信息交互功能设计
集成中间件监控预警系统在对边缘服务系统进行监控后,需要对监控信息进行展示,方便用户与被监控系统进行直观交互。本文采用第三方跨平台的开源可视化组件Grafana与集成中间部件进行对接,完成交互功能。
交互功能主要依靠本文自定义的传输协议MWP (Monitoring and Warining Protocol)来实现,其优势在于提高信息的规范性、简化信息的解析、提升监控数据传输速率、缩短故障响应时间。集成中间部件通过TP组件将获取的监控信息以MWP协议进行封装后传输给Grafana,用户可在交互界面上与系统进行交互。协议格式如图3所示。
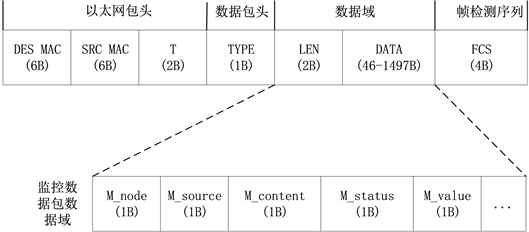
Figure 3. Schematic diagram of MWP protocol
图3. MWP协议示意图
MWP协议以五元组形式M (M_node, M_source, M_content, M_status, M_value)表示的DATA字段核心内容为主要传输数据。其中:M_node代表IP地址;M_source代表资源类别,分硬件资源和软件资源;M_content代表监控内容,如服务运行状态、服务饱和度、CPU利用率等等;M_status代表状态,分正常状态(细分为服务过载、服务正常、服务饥饿)和失效状态;M_value代表监控指标具体值。由于所需监控指标根据实际系统设计各不相同,此协议具有良好的通用性与扩展性,可在此基础上自定义需要传输的数据信息。
受制于篇幅影响,这里选取集群服务器资源信息进行展示,如表2所示。用户可根据这些交互信息了解边缘服务系统情况,同时通过交互功能也能掌握监控系统运行情况。
实验所需的集群系统包含8个服务器节点,各节点内存均为30.75GiB,CPU核数均为8核。
Table 2. Summary table of cluster server resources
表2. 集群服务器资源总览表
3.3. 预警技术
本文设计了一种可视化部件和预警部件之间进行集成的通用流程方法。首先在预警部件中设计一个专门的告警模块,并在此模块中对各种数据源进行分类;其次在预警部件建立专门的身份对照系统,以此分辨不同的数据源;最后通过Http通信的方式,将预警部件和可视化部件的ARS (告警规则设置模块)进行绑定,从而进行数据的集成和传输。具体集成流程如图4所示。
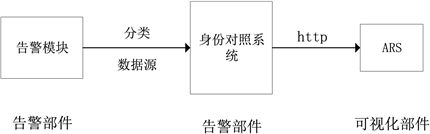
Figure 4. Integration between visualization and warning
图4. 可视化和预警间集成
本文系统选用国内第三方智能告警平台睿象云集成Grafana来实现告警功能。其主要优势功能包括:1) 多样化的告警通知方式;2) 一键告警功能;3) 告警联系人管理功能,可对联系人进行分组和划分通知优先级别;4) 历史告警查询功能。
Grafana集成睿象云的具体流程图如图5所示。

Figure 5. Flow chat of Grafana integrated with Cloud Alert
图5. Grafana集成睿象云流程图
4. 集成中间件监控预警系统整体协同工作过程
第三章内容主要是介绍集成中间件监控预警系统中三大核心技术(监控模块、可视化模块、预警模块)各自的工作流程及其原理,现就本文设计的集成中间部件是如何调节其余三大模块和整个系统协同工作的过程做详细介绍。
1) 集成中间部件的SDClient安装在集群系统中,主动获取到集群系统的硬件资源和软件资源,将资源以K/V形式发送给集成中间部件的SDServer。其中,SDClient主要依靠读取集群系统文件来获取硬件资源信息,同时依靠心跳算法E-H和服务饱和度计算公式获取软件资源信息。
2) 集成中间部件的SD获取到集群系统资源信息后,通过集成中间部件的FC组件将SD组件收集到的K/V形式数据通过DFCA算法转换为Prometheus能够理解的时间序列数据格式。
3) 集成中间部件对接Prometheus以对集群系统进行精密监控,其提供监控指标采集、查询、存储等功能。Prometheus的DC组件通过集成中间部件主动暴露的HTTP接口来主动拉取转换数据格式后的主机性能监控指标和软件资源监控指标,集群系统资源信息由TSDB组件完成,按照时间序列方式存储在本地磁盘中,同时Prometheus自带查询语言PQL供集成中间部件调用。
4) 为实现监控数据可视化功能,集成中间部件对接Grafana,由SHOW组件进行可视化展示。集成中间部件的TP组件采用高速安全的MWP协议对监控数据进行封装后再传输给Grafana进行可视化展示,能在很大程度上提升集群系统监控数据的传输速率,经后续实验验证能缩短从服务失效到系统管理人员发现服务失效的响应时间,最大程度降低损失。
5) Grafana对接睿象云来进行预警功能实现。Grafana的ARS组件内部能对集成中间部件的TP组件传输过来的监控指标数据进行自定义的告警规则设置和告警阈值设定。睿象云能在监控数据超过阈值后进行多种方式告警以及提供一键告警和告警联系人管理等功能。
本文设计的集成中间件监控预警系统通过集成中间部件作为中间调节层,协同Prometheus、Grafana、睿象云三者,实现了对集群系统全方面的监控预警,经后续实验验证,较传统集群监控系统而言提升了成功检测到集群系统资源失效的几率,节省了集群系统资源,并使集群系统管理人员快速收到系统异常通知,将损失降到最低。
5. 实验
5.1. 实验背景及环境
本文实验平台在Linux环境下基于国家自然基金项目“面向公交视频识别及智能分析的可扩展的并行GPU处理架构及应用系统”所搭建,此分布式集群系统平台由一台二级交换机和8台服务器组成,服务器配置信息则如表3所示。集成中间体监控预警系统是它的一个组成部分,其余组件为Kafka抓取模块、AI模型模块、Redis通信缓存模块、Docker封装模块,HBase存储模块,后台资源调度模块。
Table 3. Server configuration information
表3. 服务器配置信息
在测试中,集群服务系统各节点之间相互通信传输数据形成数据闭环,整个过程中,集成中间体监控预警系统一直在动态且实时地监控集群服务系统的资源与节点的状态信息,为集群服务系统的安全性和稳定可靠性提供必要保障。
本文主要依据三个指标来进行本文系统实验,并与现有的Nagios [23] 和Zabbix [24] 集群监控系统对比。这两个集群监控系统经过了时代的沉淀,能较完美符合集群系统监控要求,且是当前市面上非常流行的集群监控系统,被众多企业和组织广泛使用。当然,市面上也存在一些新颖的集群监控系统,但这些监控系统都聚焦于监控云系统,对本文课题实际项目采用的集群系统效果不好。
1) 监测率:监测率是指成功检测到服务失效的次数与服务总失效次数的比率;
2) 响应时间:响应时间是指系统服务失效到系统管理人员成功收到告警通知的时间间隔;
3) 系统资源消耗:本文系统的监控模块能实时监控系统资源(内存、CPU等)。选取固定时间段,统计此时间段内服务失效和服务正常时CPU和内存的平均利用率,以此体现本文系统运行时消耗系统资源的情况。
5.2. 实验结果
在本文实验环境中让5组实验里的每组内1000个服务失效,以此来模拟实际生产环境中服务宕机的突发情况,然后统计计算得出监测率和平均响应时间。实验对比结果如图6,图7所示。
由图6可以看出,本文研究的集成中间件监控预警系统平均达到了93%的监测率,相比于Nagios的89%平均监测率和Zabbix的90%平均监测率而言有着显著提升。相较于传统集群监控系统,本文系统在监测率方面提升了约3个百分点,这是由于集成中间部件的SD组件在实时监控方面具有较大优势,本文系统在对监控信息的采集、处理、上报方面进行了优化提升。同时由图7可以看出,本文研究的系统在及时响应系统故障方面也具较大优势,这是由于本文设计的MWP协议在传输速度方面具有一定的优势,能及时对监控信息进行传输,做到实时性。
当服务失效时,本文系统会及时响应故障,消耗一定的系统资源。由表4可看出,在集群系统服务正常和服务失效两种情况下,本文系统在降低系统资源消耗方面均比传统集群监控系统有一定程度上的提升。这是由于在设计监控系统时做到了轻量级原则,同时集成中间部件和其他模块之间进行信息交互时做到了高效率、高针对性,不做无用功。
Table 4. Resource consumption comparison table
表4. 资源消耗情况对比表
由此可说明,本文设计的集成中间体监控预警系统能准确检测和及时报警边缘服务集群系统出现的异常,同时可在一定程度上减少系统资源消耗,保障了服务系统的安全性,使其稳定运行。
6. 总结
本文设计并实现了一种集成中间件监控预警系统,通过集成中间部件进行调节,基于Prometheus对系统进行全方位监控,实现了当系统启动,将任务指标推送到集成中间部件后由Prometheus主动拉取,再利用MWP协议传输监控数据至Grafana进行可视化展示,并且搭配睿象云进行告警的整体流程,形成了一套一站式的边缘服务集群系统监控预警服务解决方案。经实验验证能提升系统监测率,缩短故障响应时间,减少集群系统资源消耗,保障了边缘服务集群系统的安全性和稳定可靠性。接下来我们将对如何通过监控预警得到的信息实现系统的整体资源负载均衡问题做进一步的探讨和研究。
基金项目
国家自然科学基金(61572325);上海重点科技攻关项目(19DZ1208903)。