1. 引言
集装箱logo图像的分类难点有很多,首先就在于其所处的特殊环境,集装箱在运输过程中一直风吹日晒,logo图像时常会产生褪色和破损的情况,从而造成一些主要细节的丢失,且集装箱的堆放是层级堆放,在拍摄识别的时候会出现拍摄图像目标高低不一,远近有别的情况,就会时常在识别的时候会出现差错。并且很多logo图像都是字母组成,区别不大,比如“Olvi”和“Ovl”是两个不同logo图像标志的代表。其实传统的神经网络模型在图像粗分类问题上已经产生了较好的效果,例如AlexNet [1] 、VGG [2] 、ResNet [3] 等著名的神经网络模型。不过传统的分类模型是对整张图片进行特征提取,进而忽略了对全局的把控,使得这些分类网络模型在这种破损的数据分类上表现得不尽如人意。
传统模型的特征提取存在很多不完善的情况,其中Sift [4] 算法的实时性不高,对边缘光滑的目标无法进行准确地检测,Part R-CNN [5] 需要将不同特征进行连接,接着用SVM进行分类。传统的方法,要么在识别的时候会出现偏差,要么会产生人工标签标注这种费时费力的情况。
2017年,Google提出Transformer [6] 模型用于解决自然语言类处理的问题,因为在并行计算上的优势使得其取代了RNN网络。2020年Google再次提出Version Transformer [7] 模型,用于视觉领域。本次实验即采用该模型。实验证明,ViT在图像全局结构的把握上产生了很好效果。
本文从公司的信息系统以及现场拍摄采集数据集,然后对于数据集进行预处理和图像增强操作,以此来提高图像的识别难度从而获得实验用的数据集,最后将数据集输入ViT模型中进行实验,以此来验证在不同激活函数和不同分类模型中的性能。
2. 相关技术
2.1. Vision Transformer (ViT)
Transformer是一种用于自然语言处理的网络模型,模型包含两个部分,分别是Encoder (编码器)和Decoder (解码器)。Encoder将输入的特征序列编码转为中间特征,而Decoder随机生成一个序列,再和中间序列进行结合最终输出结果。
随着Transformer在自然语言处理领域取得了成功并且广泛应用,大家逐渐将目光投向计算机视觉任务。在不改变Transformer结构的条件下,将语句的分类应用于图片中。本文的ViT网络结构模型因为是分类模型,所以只用到了Encoder而没有用到Decoder。结构如图1所示,
首先将图片分成规格相同的图片块,用Encoder对于图片块进行特征提取,不同的图片块只是整个图片的一部分,无法代表全部,因此需要将所有图片块结合成一个class token。通过添加位置编码区分token,再用多头注意力机制获得彼此之间的权重关系 [8] 。Class token具有整张图片的信息,最后用于分类。
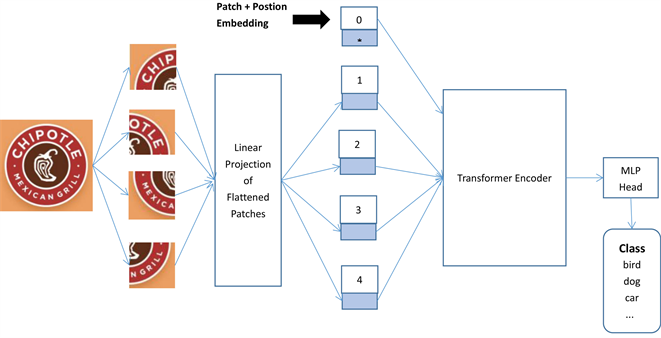
Figure 1. Structure diagram of vision transformer classification model
图1. Vision Transformer分类模型结构图
2.2. GELU激活函数
在深度学习中,卷积层之间的过渡需要非线性激活函数来处理,从而使得网络模型可以解决比较复杂的问题。如果不使用激活函数,则网络模型无论多少层,也就好比一个线性的模型,因此激活函数对卷积神经网络至关重要。
目前大多数模型采用的激活函数以RELU为主,RELU计算快且可以使得梯度快速收敛。但是RELU在输入为负数的情况下输出为0,从而会存在大量神经元失效的情况。
高斯误差线性单元(GELU [9] )是一种高性能的神经网络激活函数。GELU函数在输出为负值的情况下仍然保留了一部分输出,避免出现了RELU全部归零的问题。在计算机视觉等任务上,使用GELU作为激活函数的模型性能常常超过RELU。GELU的公式以及导数曲线图如图2所示。
(1)
其中,
是正态分布的概率函数
GELU函数的求导结果如下:
(2)
3. 算法实现
本文利用ViT模型来提取图像特征,最后进行图像分类,核心的模块主要分为五块:图像增强,特征提取策略,位置编码,图像编码,图像分类。
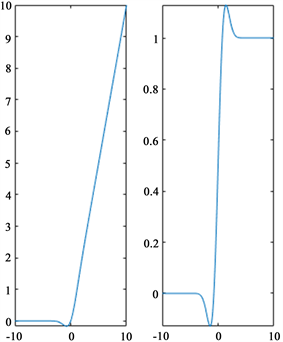
Figure 2. Curves and derivative graphs of the GELU activation function
图2. GELU激活函数的曲线和导数曲线图
3.1. 图像增强
图像增强是为了给模型增加难度,让模型适应各种各样的训练数据,从而达到一个很好的验证效果,本次图像增强中采用的是自动增强法,图像有翻转,倒置,对比度,饱和度等16种操作,每种操作数值不一,产生的概率不一,从而极大的提升了图像的多样性,进而提升模型质量。效果如图3所示。左边为原始图像,右边为自动增强后的图像。
 (a)
(a)  (b)
(b)
Figure 3. Image enhancement effect
图3. 图像增强效果图
3.2. 特征提取策略
首先将图像设置成统一的H*W,输入为B*C*H*W,B为batch,C为通道数,H为高度,W为宽度,输入的时候,会将每个图像分成一个个大小相同的图片块,图片块的大小为P*P,从而个数则为N = H*W/(P*P),然后将N拉平拉长,而C也会卷积成一个高维向量D,从而得到输出为B*D*N。因为得到的N个token都是代表原图像中其中一块的特征,不具有全局性,无法去做分类,于是需要将得到的N个token融合起来产生一个新的token,称为class token,最终得到N + 1个token。由此得到维度B*D*(N + 1)。
3.3. 位置编码
位置编码是用于区分每一个token的必要方法,每个token都来自原来图像的不同位置,且相邻的token往往存在一定的联系,所以给每个token添加一个位置编码,保留token的空间位置信息,class token具有全局性,不需要位置编码。位置编码往往采用一维向量。如果本环节的各个token不用位置编码进行区分,则各个位置的token就无法区别,从而降低识别准确率。
3.4. 图像编码
Encoder图像编码中会产生自注意力机制,为了能够从多方面来考虑权重,所以采用了多头,多头的数量可以自己选择,每个token产生多个Query,Key,Value,简称q,k,v。各个token的q去寻找每个token对应的k从而得到彼此间的内积,再乘上对应的v,彼此相加得到最终输出的特征 [10] 。如此往复,进行多层编码,q,k,v会随时更新,得到最后的输出。图4是图像编码的过程图。
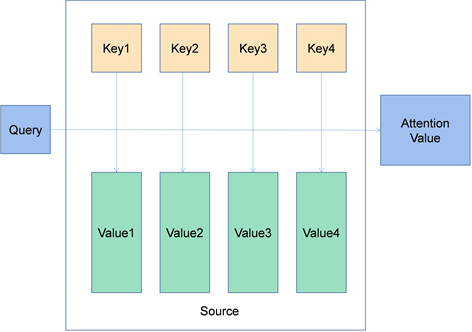
Figure 4. Process diagram of image encoding
图4. 图像编码的过程图
3.5. 图像分类
在经历多层编码之后,模型用class token作为输出进入全连接层,将维度放大到3072维再缩小进行分类,分类器会计算出在每个类别中的概率值,最终将概率值最高的类别作为标签赋予。
4. 实验结果与分析
4.1. 数据集
本文的数据集是由信息系统存储的图像数据以及现场拍摄所得,拍摄角度也是由远及近,由左到右等多角度放大和缩小拍摄,由此想确保模型的说服力。同时通过自动数据增强方法提高图像的多样性。本次实验数据共有2936张,分为59个类,其中训练集有2202张,验证集367张,测试集367张,比例是8:1:1。图5展示了部分的数据集图片。
4.2. 实验设置与评价指标
实验将图片的尺寸统一为224*224,图片块patch的大小为16*16,224/16 = 14,因此token数量为196。通过卷积将每个token的通道数3维转为768维。接着合成class token,变成197个token,class token用于输出。每个token加入一维的位置编码,class token不用位置编码。注意力机制采用12头,每个token产生12组qkv。标签平滑为0.1,训练100个epoch,采用学习率预热,优化器为Adam,batch为16,本实验通过得分作为分类指标,及通过概率转为分数作为图片的分类判断,最终输出准确率和损失值大小。
4.3. 实验结果
本次实验在训练100个epoch之后最终得到准确率为98.0000%。损失值也从4.0309降到了1.3879,准确率在中途曾经有过回流,不过在20个epoch之后,又开始呈现上升的趋势。12头注意力机制的使用对于抓准目标特征起到了很大的作用,避开了无用的背景信息,对logo图像的轮廓有清晰的定位,找准目标里的数据特征注意力机制可视化如图6所示,亮色为模型所着重关注的地方。

Figure 6. Visual image of attention mechanism
图6. 注意力机制可视化图片
4.4. 不同激活函数的对比
实验首先对于不同激活函数之间的性能做出了对比,分别采用GELU和RELU。实验表明,两者的准确率和损失值的曲线走向基本上差不多,但是RELU的准确率是95.6284%,损失函数为1.5836,相较于GELU还是略逊一筹。由此可见,本实验采用GELU作为激活函数可以得到更好的效果。图7和图8分别是两者的准确率和损失值的曲线图。
4.5. 不同模型的对比
实验同样对比了不同网络模型之间的性能,本文的对比实验选取了常用了的ResNet18,VGG16,AlexNet模型对于实验数据集进行测试。表1是模型的对比情况。

Table 1. Comparison table of different models
表1. 不同模型对比表格
实验表明,本文的模型在识别破损的集装箱logo图像方面的性能优于其他的模型,准确率更高,损失值更小。改进后的ViT模型在图像识别方面能够更好的从全局出发,把握好logo图像的整体框架结构,即使图像出现破损的情况,也能在结构轮廓上对于图像有清晰的定位和识别,本文的12头注意力机制可以很好的抓住主要特征,采用GELU激活函数也能够在输入为负值的情况下进行激活,从而产生一个缓冲的效果。最终在性能上达到了预期。
5. 结语
集装箱上的logo图像因为其所处的特殊环境,所以与其他的图像存在一定的差异,因此识别起来会有不小的难度。本次实验采用ViT模型对集装箱logo图像进行识别,多头注意力机制对于数据的特征把握得十分精确,预测了logo的轮廓,成功克服了对于残缺和变色的logo图像无法准确判断的问题,采用GELU激活函数代替RELU,使得模型在收敛的时候达到更好的效果,经过对比实验,改进后的模型的准确率达到了98.0000%,性能优于其他模型。由此验证了本文的模型能够对集装箱logo图像进行较为准确地识别与分类。也为该公司在图像识别上提供了一定的参考价值。
参考文献