1. 引言
金融时间序列是时间序列的一种,对于金融时间序列的预测分为线性预测和非线性预测。近年来,非线性预测在预测领域逐渐代替线性预测成为主流,而支持向量回归(support vector regression, SVR)作为机器学习的非线性预测的主要方法,已被广泛应用于金融时间序列的研究中。彭丽芳等 [1] 利用SVM模型对股票价格进行了预测,取得了不错的实验结果。张伟 [2] 等提出了一种遗传算法(genetic algorithm, GA)与SVM相结合的方法,将其用来预测时间序列等。但上述文献对于SVM模型中的特征参数选取不够明确。本文利用粒子群算法(PSO)优化SVR模型参数,并将之用于金融时间序列预测中。李楠楠等 [3] 利用PSO-SVM模型对供水管网爆管位置和爆管程度的诊断准确程度是可以接受的。蔡正梓等 [4] 通过PSO-SVM模型实验得出该方法能有效识别变电站视频监控火灾。
本文先阐述该模型的构建理论 [5] ;再利用该模型对金融时间序列中的股票收盘价进行预测 [6] ,用取自东方财富网的A股东北制药、沪深300指数、美股道琼斯指数作实验数据,用MATLAB作实验程序;最后将预测结果以及误差指标与传统支持向量回归(SVR)、BP神经网络和随机森林(Random Forest, RF)的预测结果以及误差指标比对,突出了该模型对金融时间序列的预测能力。
2. 研究方法
2.1. SVR模型
支持向量回归(SVR)是支持向量机(SVM)的一个重要分支,其与SVM的不同在于SVM所追求的最优超平面是使得两类以及两类以上的样本点分得更开。而SVR的样本点最终只有一类,是使所有样本点距离超平面的偏差最小。由于金融时间序列通常是非线性的,给定训练样本集:
(1)
训练样本集S是
-非线性近似的,若存在一个超平面:
(2)
下面的式子成立:
(3)
考虑到误差的存在,所以引用松弛变量
优化方程为:
(4)
约束为
(5)
(6)
(7)
其中
使函数更为平坦,进而提高泛化能力。C为惩罚系数,即对误差的容忍度,C越大,说明越不
能容忍出现误差,容易过拟合;C越小,说明模型对于误差比较宽容,但容易欠拟合。对上述优化问题引用拉格朗日函数并写出对偶形式:
(8)
约束为:
(9)
(10)
其中
为拉格朗日算子,
的表达式为:
(11)
其中核函数
用来代替内积
,
,核函数取高斯径向基核函数:
(12)
其中
作为参数,决定了数据映射到特征空间的分布,
越大,支持向量越少,
越小,支持向量越多,支持向量的个数影响着训练与预测的速度。在SVR中,选择合适的参数C和
尤为重要。
2.2. PSO算法
粒子群优化算法(Particle Swarm Optimization)是通过模拟鸟类觅食过程中的行为演化而得到的一种群体智能算法。假设鸟类群体觅食,每只鸟都共享有食物的位置的信息,寻找的过程中不断记录并依据信息更新自己的飞行方向,最后找到一个食物最多的位置。类比鸟类群体觅食,把鸟看成粒子,把食物的量看成目标函数值(适应度函数值),每只鸟所处的位置看作空间中的一个解,食物量最多的位置看成全局最优解。
假设在D维搜索空间中,有N个粒子,粒子有两个重要属性:速度和位置,速度表示粒子下一步迭代时移动的方向和距离,位置是所求解问题的一个解。则有如下速度更新公式:
(13)
位置公式:
(14)
公式(13)中第一项为惯性部分,第二项为自我认知部分,第三项为群体信息部分。k为迭代次数;
为惯性权重;
分别为个体与群体学习因子;
为区间
内的随机数,增加搜索的随机性;
为粒子i在第k次迭代中第d维的速度向量;
为粒子i在第k次迭代中第d维的位置向量;
为第i个粒子在第k次迭代中第d维的最优位置,即个体最优解;
为群体在第k次迭代中第d维的最优位置,即群体最优解;以及能够计算出的个体最优适应值
与群体最优适应值
。
3. PSO-SVR模型
对于上文所提到的SVR模型中的参数C与
,二者会影响SVR预测模型的精度。先用PSO优化算法去得到最优参数C与
,再带入到SVR中就会提高模型的精度。给出如下步骤,如图1所示:
1) 确定样本数据,输入粒子群规模N,粒子维度D,惯性权重
,学习因子
,最大迭代次数。
2) 初始化个体的位置
与速度
,并计算出初始个体与群体适应度函数值。
3) 运用公式(13)与公式(14)更新每个粒子的速度和位置并计算个体与群体适应度函数值,选出历史最优适应度函数值。
4) 判断是否满足迭代终止条件,若不满足,返回步骤3)。
5) 若满足,输出最优解。把输出的最优解作为SVR模型的参数进行建模。
6) 用步骤5)优化后的SVR模型进行预测回归。
4. 实证研究
4.1. 数据来源
选取来源于东方财富网的A股东北制药2022年1月至2022年12月、沪深300指数2021年1月至2022年12月、美股道琼斯指数1月至2022年12月的收盘价作为实验数据。用前三期收盘价作为输入,第四期收盘价作为输出训练模型。取前4/5为训练集,取后1/5为测试集。
4.2. 评价指标
本文采用平均绝对误差(MAE)、均方误差(MSE)、平均绝对百分比误差(MAPE)、决定系数(R方)、测试时间作为模型评价指标。
(15)
(16)
(17)
(18)
4.3. 实验结果与分析
对数据进行归一化处理后采用粒子群优化算法来优化SVR中的参数C与
,这里由于只需要优化两个参数,所以粒子群维数
,取学习因子
,粒子群规模
,最大迭代次数为100,将数据带入到PSO模型后得到适应度曲线如图2所示,最优参数如表1所示。
利用上述得到的最优参数对SVR进行建模得到PSO-SVR模型。用传统k折交叉验证求得的SVR模型、BP神经网络以及RF模型与本文模型进行实验比对,评价指标比对结果如表2所示,预测结果如图3所示,残差如图4所示。

Table 1. Optimal parameters for the different experimental data
表1. 不同实验数据最优参数
Table 2. Comparison diagram of the evaluation indicators of the different models
表2. 不同模型评价指标对比图
由表2可以看出相比于SVR,PSO-SVR不仅各项评价指标要优于前者,而且能大大缩短测试时间;本文模型除了测试时间,其余各项指标均优于BP神经网络与RF模型。
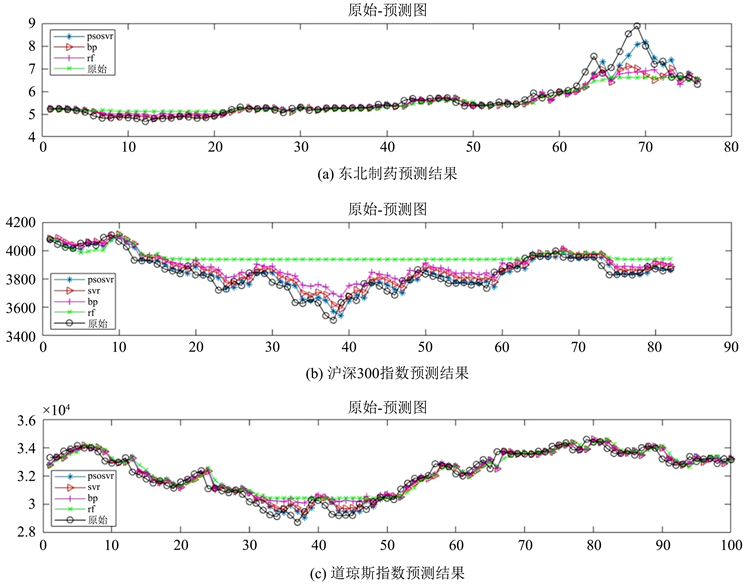
Figure 3. Comparison of the prediction results of the different models
图3. 不同模型预测结果对比
由图3可以观测出,对于平稳金融时间序列而言,四种模型的预测能力都令人满意,但在东北制药第60个测试数据之后、沪深300指数第10至第65个测试数据之间以及道琼斯指数第30至第50个测试数据之间,四种模型都有不同程度的预测误差,但也能看出PSO-SVR模型误差最小,其次是SVR模型和BP神经网络,最后是RF模型。模型精度还不够高的原因可能有:1) 实验中使用的金融时间序列的特征指标有限,仅仅使用了实验数据的收盘价。2) 实验中使用的金融时间序列的数据的范围有限,对预测的数据有一定影响。3) 实验中使用的金融时间序列没有考虑到政策、疫情等因素对股票收盘价的影响。结合图4也能发现,虽然在三组数据中的某一部分都有四种模型的误差整体偏大的情况,但能明显观测出PSO-SVR的残差点的分布更为紧凑,可以认为该模型比较有效。
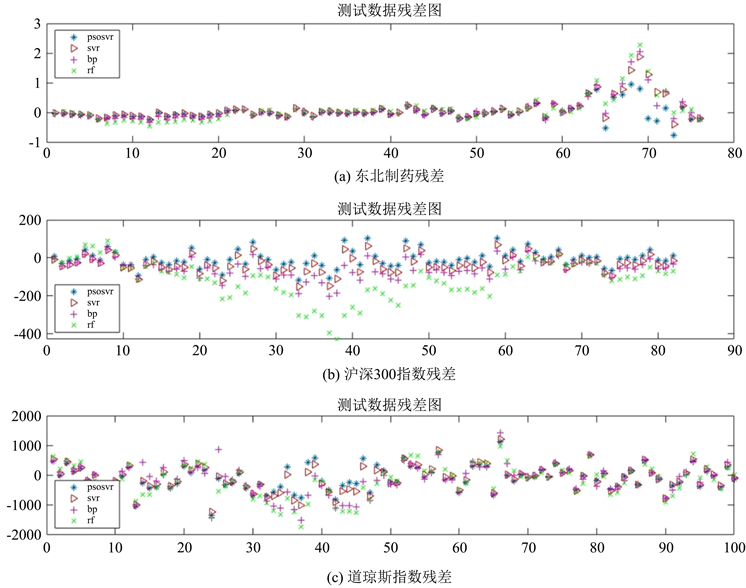
Figure 4. Comparison of residuals for different models
图4. 不同模型残差对比
5. 结果与展望
粒子群优化算法支持向量回归模型包含着PSO算法中参数少、计算快以及SVR模型学习能力强、学习速度快的优点,更重要的是PSO算法能提高SVR模型的精度。
不足之处在于该模型的实验中只是选取了前几期的收盘价作为输入,若取前期的开盘价、最高价、KJD等指标作为输入,也许会有不同的效果。所以在该模型的基础上,可从特征选取、特征降维等方面进行加深实验研究。
总之采用该模型对金融时间序列进行预测,有着减少误差降低风险的效果,仍具有良好的应用前景。
基金项目
项目名称:深度学习在数据分析中的应用研究。
项目类别:省教育厅项目。
项目批号:LJKMZ20221424。