1. 引言
当前国际环境瞬息万变,我国作为全球第二大经济体,时刻受到各种“黑天鹅”事件的影响,因此及时发现并妥善处理经济转型中的金融风险就变得更加重要。而企业作为市场经济的主要参与者,其信用风险备受学术界和金融界的关注,早在《巴塞尔协议》中,就阐述了关于企业信用风险预测的相关内容并将预测信用风险列为金融活动中必不可少的内容。实际上,企业信用风险是金融风险中很重要的一环,随着商品经济的发展和企业的成长,企业已经不是经济活动中孤立的个体,而是在各类经济活动中与多个企业紧密联系,如果对某个企业信用风险处理不当,极易导致发生系统性金融风险。因此,对企业进行正确的信用评级就显得尤为重要。
传统的信用风险评估方式有主观定性分析方法 [1] ,如取决于专家打分的方法:5C法、5P法和5W法等。该类方法主观性极强,可信度偏低。有利用财务数据的评分方法,比如Altman使用多元判别建立的Z-score信用评分模型 [2] ,以及利用Logit模型和Probit模型建立的评估方法。这类方法对数据要求较高,需要服从正态分布,使得模型应用受限。其他的还有量化管理模型,如KMV模型,Credit-metircs模型 [3] 等。
如今,随着计算机技术的快速发展,机器学习在很多领域中展现出极好的效果,经典的算法如KNN、SVM、NB和LSTM等已经有着广泛的应用。Golbayani等应用多种机器学习技术来预测企业信用评级 [4] 。神经网络模型也在其中得到了应用,杨保安等人将神经网络算法应用于评估企业的财务风险状况,直接验证了神经网络算法在信用风险评估方面的有效性 [5] 。随着图神经网络的出现,相关模型被应用到贷款担保网络中,企业被视作图中的节点,公司间的借贷关系看作为边,从而利用图网络模型完成公司的信用评价 [6] 。Feng等则将公司指标看作顶点,将公司映射为一张图,并对其进行分类 [7] 。
在本文中我们同样将公司财务指标看作顶点,并计算各指标之间的相似度,将每个公司映射为一张图,并利用图神经网络模型进行图的表示学习,进而构建对各公司的信用评价模型。
2. 图的基础知识
1) 图
是一种数学模型,将企业关系抽象成节点V和边E。图G的顶点集记为
,边集记为
。
2) 邻接矩阵A:若节点i和节点j之间存在连接关系(边),则邻接矩阵A中对应的元素
值为1,否则该元素的值为0,A为一个对称矩阵。
3) 拉普拉斯矩阵L:由对角矩阵和邻接矩阵组合而成。
(1)
4) 路(path)
是一个非空图,其顶点集和边集分别为
(2)
这里的
均互不相同,顶点
和
由路P连接(link),并称它们为路的端点或顶端;而
称为P的内部顶点。一条路P的边数称为路的长度。
5) 若
是一条路且
,则称图
为圈。一个无圈图,即不含任何圈的图,亦称为森林,而连通的森林即称为树。
6) 图神经网络是在“图”这种非欧空间数据上挖掘数据特征的关联联系进行深度学习的技术。目前图神经网络能够处理多种图结构,包括无向图、有向图、边信息图、异构图、动态图。
7) 设G是无向图,
的顶点度是指G中与x关联的边的数目(一条环要计算两次),记为
。顶点度为d的顶点称为d度点。
和
分别表示G的最大和最小顶点度。
即
,
。
设G是一个连通图,
,则称G是一个最大度有限制的连通图。
生成树:含有n个顶点但只有
条边的连通图为生成树。
最小生成树:即图中所有生成树里权重和最小的生成树(图1)。
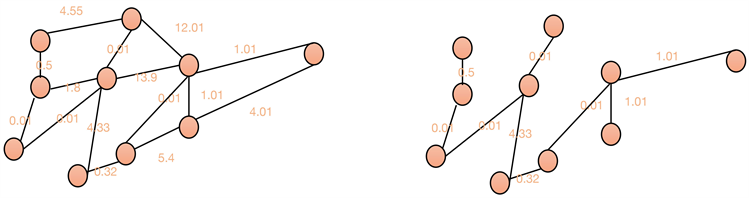
Figure 1. Schematic diagram of the minimum span ning tree
图1. 最小生成树示意图
3. 模型整体框架
如图2,本文所提出的模型主要分为三部分:
第一步:企业的图映射。
1) 企业数据输入
获取每家企业2014~2021年累计8年的标准化年报数据,每个指标对应一个根据时间排序的8维向量,从而29个指标形成8 × 29的矩阵,作为企业的输入数据。
2) 顶点相似度矩阵
将每个指标(矩阵每列)看作一个顶点,每对顶点之间的相似度由其对应8维向量的夹角值来定义,夹角越小的指标顶点间相似度越高,遍历所有顶点对,从而得到29 × 29的顶点相似度矩阵。
3) 图映射的构造
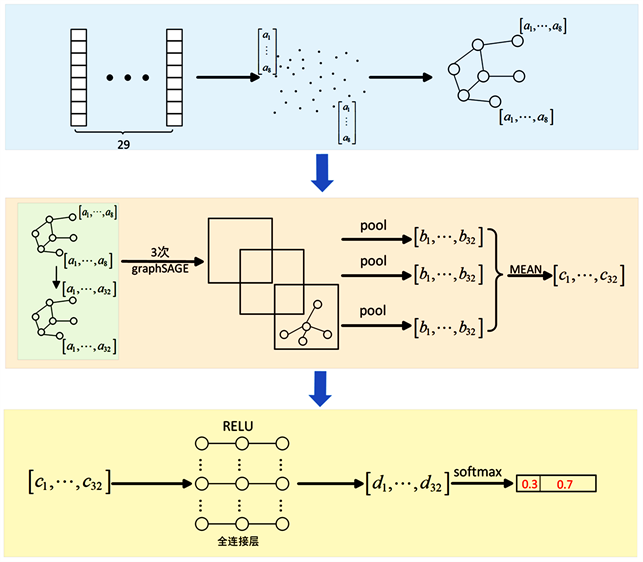
Figure 2. Overall flow chart of the model
图2. 模型整体流程图
根据顶点相似度矩阵,将顶点之间相似度作为边权值,构建由29个指标顶点形成的最大赋权支撑图,利用生成树算法记录加入的边集合,将企业映射为具有最大相似度的最小连通图,记作Corp_Tree。在这里为了防止出现极大度的顶点,我们对生成树的最大度进行了限制,这里将最大度设置为7,总顶点数的四分之一。
循环上述过程,完成所有企业的图映射,并结合企业YY评级给定对应映射图的标签,保存入数据库中。
第二步:图的嵌入表示。
将第一步的数据导入,包含映射图及其标签。
1) 首先对每个节点赋一个24维的特征向量,拼接到节点的8维特征向量上,使每个节点的特征向量为32维;
2) 然后将在图上进行三次GraphSAGE操作,得到的结果分别进行池化Pool操作输出3个32维特征向量;
3) 最后将这3个向量做平均MEAN,得到图的嵌入向量。
第三步:MLP分类器。
将第二步生成的图的嵌入向量输入两层的全连接神经网络中,然后隐藏层用Relu函数激活,最后一层使用softmax函数输出分类向量。
3.1. 图池化
本文使用TopKPooling方式为模型池化,如图3所示。
TopKPooling实际上就是对图的节点进行剪枝,剔除得分低的节点,生成新的图,公式为:
(3)
(4)
(5)
(6)
3.2. 损失函数设计(Cross Entropy Loss)
本文使用交叉熵来衡量企业风险真实概率分布与预测概率分布之间的差异,交叉熵的值越小,说明本模型的预测效果越好。
交叉熵公式为:
(7)
其中,
为真实概率分布,
为概率预测分布。
本文我们处理的主要是多分类问题,交叉熵函数对于多分类问题也是适用的,因此这里我们选择它作为损失函数。
4. 实验验证
4.1. 指标选取
目前,我国企业信用风险评估体系仍然存在部分问题,评估指标的选取并不完善。陈丽君基于电商平台融资模式,提出了一种互联网供应链金融模式下小微企业融资信用风险评估体系 [8] 。迟仁勇等人综合使用非上市中小企业硬指标(包括销售收入、资产负债率、税前利润增长等信息)和软指标(包括企业家特征等信息)对企业信用风险也有较大影响 [9] 。段翀利用中小企业财务数据与同行业上市企业信息,提出了一种结合PFM模型和倾向匹配得分法的中小企业信用风险评估方式,来评估中小企业市场价值 [10] 。
本文基于前人对企业信用风险的研究 [11] [12] [13] [14] [15] ,综合考虑企业的偿债能力、盈利能力、营运能力、获现能力和发展能力五个方面,从中选取了总资产、货币资产、净资产、总债务、带息债务、净债务、经营活动现金流、投资活动现金流、筹资活动现金流、主营业务收入、主营业务利润、EBITDA、净利润、主营业务利润率、主营业务收入增长率、总资产报酬率、净资产回报率、EBITDA/营业总收入、经营性现金流/EBITDA、流动比率、速动比率、存货周转率、资产负债率、短期债务/总债务、带息债务/总投入资本、现金比率、货币资金/总债务、获息倍数、EBITDA/带息债务,总共29个指标数据。
4.2. 数据预处理
本文数据来自Wind客户端,原始数据共有49,584行,各指标格式、单位不同,差异较大,需要进行数据的清洗整理工作。
首先是处理表格中的缺失值,如某企业缺失值占比较大,则全部删除此企业的数据;对缺失值占比较小的企业采用均值填补,完善数据。
其次对数据进行标准化,消除评价指标的差异性,使各个指标都处于同一数量级上。这里采用了最常用的标准化方式,计算公式为:
,使数据的平均值为0,标准差为1,同时还能使数据具有特殊特征。
经过标准化处理后共有数据35,031行,结合YY评级数据信息,得到标准化后有评级标签的数据30,790行,包含企业数为5739个,并分别在Corp_Tree图映射结构上进行3分类、5分类和8分类的模型训练
为改变学习率来提高模型的性能,加快模型的收敛速度。这里使用了余弦退火(Cosine Annealing)和热重启(Warm Restart)两种改变学习率的方法。
4.3. 正文三分类结果分析
在Corp_Tree树结构上进行3分类时,使用热重启的学习率更新模式,损失函数变化和ROC曲线如下图4所示。
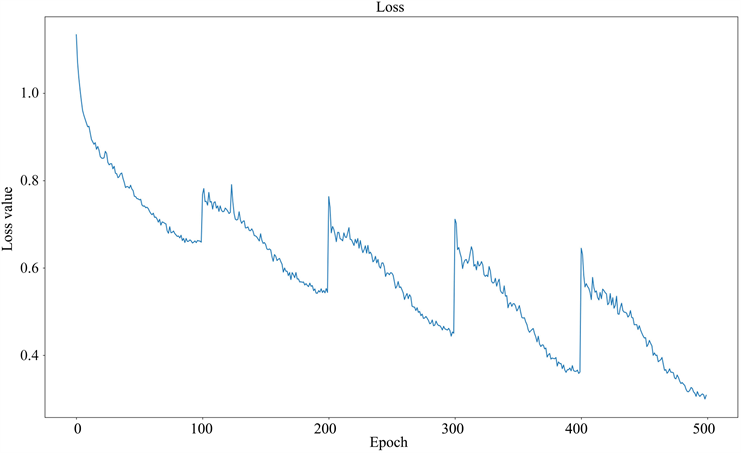

Figure 4. The results of the three-category operation on the Corp_Tree structure
图4. Corp_Tree结构上三分类运行结果
从图中可以看出,随着迭代次数的增加,损失loss值不断减少。整个过程中,学习率在0.00001和0.001之间根据余弦函数周期变动,导致准确率和loss值跟随出现波动,整体震荡下行。当Epoch超过400时,虽然训练集的损失函数仍然波动下降,但是参考测试集的损失函数发现其值开始上升,出现过拟合的现象,此时我们停止参数更新,测试集整体准确率达到72%。
根据ROC曲线我们可以看到,树结构上的分类器效果比较显著,且信用最好的层级(0类)的分类效果是最好的,模型整体能够较好的完成分类任务。
4.4. 五分类、八分类结果分析
在Corp_Tree树结构上进行5分类,同样使用热重启的学习率更新模式,所用数据与之前数据一致,损失函数变化和ROC曲线如下图5所示。
从图5中可以看出,5分类结果跟3分类大体相似,从ROC曲线的情况来看,模型建立的分类器整体仍然具有较好的效果,且信用评价最好的层级(0类)分类效果仍然最优。但是相对于3分类来说,各项分类能力出现了一定的弱化,衡量整体分类的micro平均有着明显的降低。这是因为数据总量不变,当分类类别增多时,每种类别所对应的样本数减小,一定程度影响了模型的性能。
不过我们也注意到当在Corp_Tree树结构上进行8分类评级时,虽然相对3分类情形效果出现了一定的减弱,但是整体来看,分类器依然有着较好的显著性,且信用评级最高的类别效果仍然最优,整体来说模型并没有因为每个分类对应的样本继续减少而出现效果严重下降的情况(图6)。
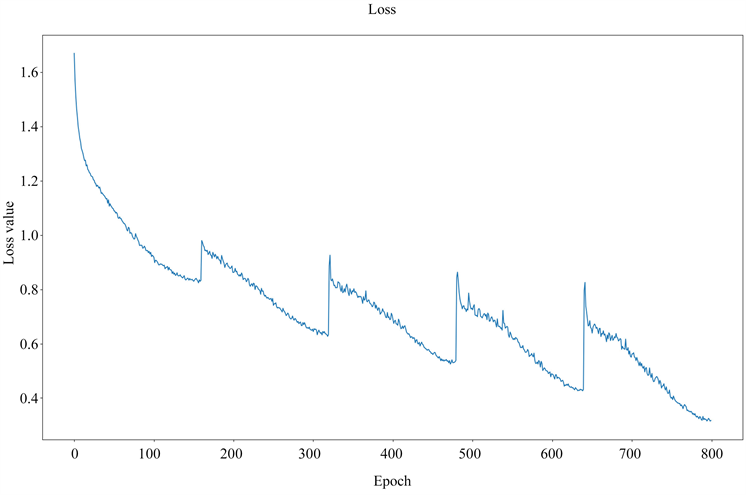
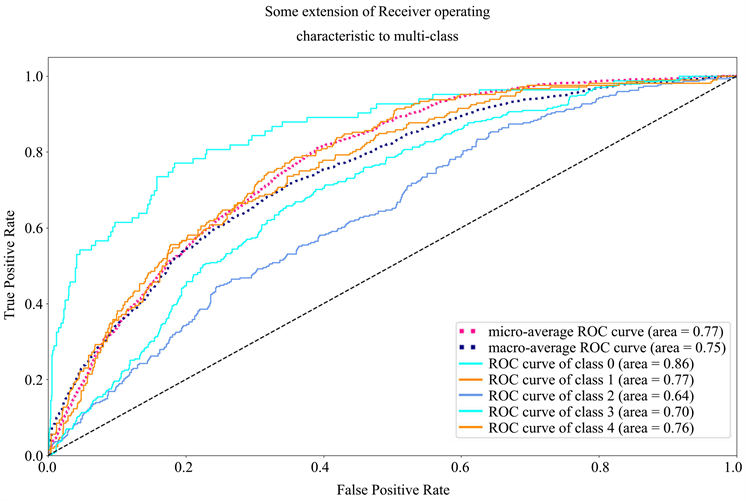
Figure 5. The results of the five-category operation on the Corp_Tree structure
图5. Corp_Tree结构上五分类运行结果
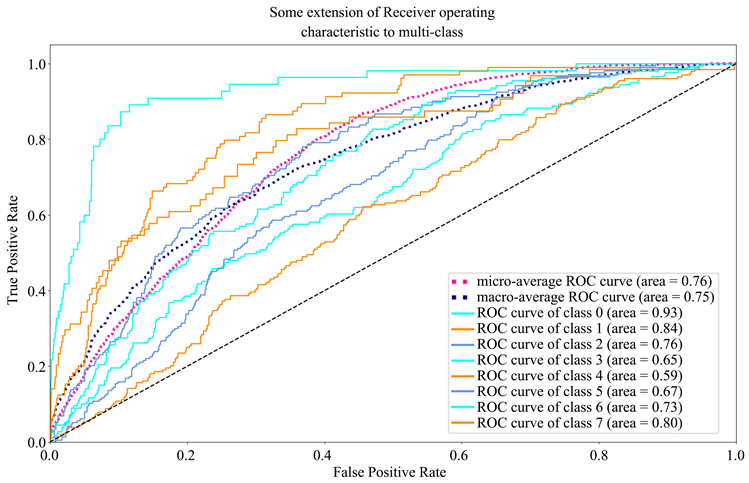
Figure 6. The results of the 8-category operation on the Corp_Tree structure
图6. Corp_Tree结构上8分类运行结果
5. 结语
本文提出了一种基于图神经网络的企业信用风险评估方法,对信用评估进行了深入的分析和研究,建立了分类模型。模型深入分析了企业各指标数据之间的关系,将各指标抽象为顶点,指标之间根据相似度来连接带权值的边,从而建立与企业对应的图,再利用图神经网络(Graph Neural Network, GNN)构建企业信用风险评估方法。
本文取得了一些较为满意的结果,为信用风险评估提供了新的研究角度。模型在Corp_Tree图映射结构上进行3分类、5分类和8分类的研究,实验结果表明,本文提出的模型根据ROC等评判分类效果显著且拥有较好的“鲁棒性”,Corp_tree结构较好地刻画了公司各指标数据的关系。