1. 引言
随着深度学习技术在计算机视觉领域的迅速发展,场景文本检测和文字识别技术取得了巨大的进展。然而,在自然场景下,场景文本检测和文字识别面临着极端光照、遮挡、模糊、多方向多尺度等挑战 [1] ,因此,场景文本检测和文字识别的应用仍然存在一定的局限性和挑战。在工业场景下,铸造工件上的标识字符有着举足轻重的作用,通过标识字符可以查询到整个铸造过程中各个环节的详细信息,所以在铸件进出工厂过程前后,需要对铸件上的标识符进行记录。工业信息化进程如火如荼,利用OCR (Optical Character Recognition)技术自动识别记录将大幅减少人力,提高工作效率。
铸件字符检测与识别方面,与传统的图像处理方式,如二值化、图像滤波等相比,由于铸件字符前景背景相似,轮廓不清晰,自然场景下光照多变等原因,深度学习的方式对复杂背景下铸件字符识别的鲁棒性更强,可以更好地完成检测和识别的任务。
自然场景下的任意形状的文本检测和识别受到越来越多的关注,其中,因网络中未使用非极大值抑制(Non-Maximum Suppression, NMS [2] )和感兴趣区域池化(Region of interest pooling, ROI [3] )技术,而采用新颖的全卷积点采集网络和加入了图细化模块,加快了实时检测速度的PGNet [4] 网络,该网络在诸多任意文本检测和识别网络中表现突出。且PGNet网络完成了文本端到端的检测,进一步加快了识别速度,加速其在工业场景下的落地。其次,场景文本检测数据集中鲜有铸件字符数据集,针对该情况,采用谷歌于2020年提出的RandAugment [5] 工具,对已有的数据集进行数据增强,增强网络模型的鲁棒性。并针对PGNet论文中的损失函数进行了优化。
2. 全卷积神经网络
2.1. 卷积神经网络与全卷积神经网络(Fully Convolutional Networks, FCN [6] )的区别
卷积神经网络主要由卷积层和全连接层组成。卷积层通过卷积操作在输入图像上提取特征,生成一系列的特征图。这些特征图可以被认为是图像的分类器,它们可作为后续层的输入。全连接层则负责对特征进行分类和输出最终的预测结果。整个卷积神经网络的训练是通过反向传播算法来完成的,即将误差从输出层反向传播到网络的每一层,以对权重进行更新。这样,就可以通过训练让网络自动学习图像中的不同特征,并获得更好的分类效果。全连接层的作用是将这些特征图映射为一个包含分类类别数量个元素的特征向量。该向量中的每个元素代表一个类别的概率值,表示输入图像属于该类别的可能性大小。这个向量包含了整个输入图像的特征信息,用于对图像进行分类。如AlexNet是一种深度学习模型,用于对图像进行分类。该模型针对ImageNet数据集进行了训练,并且可以对一张输入图像进行分类,输出一个包含1000个元素的向量。这个向量中的每个元素都表示输入图像属于一种不同的类别的概率大小。AlexNet模型通过学习大量图像数据来提取图像的特征,并生成包含相应类别概率值的向量作为分类结果。
FCN是在语义分割领域提出的,语义分割的任务是对图像中的每一个像素进行类别的划分。卷积神经网络(CNN)在卷积层之后通常会使用全连接层和归一化处理等方法,来得到一个固定长度的特征向量,从而得到分类结果。全卷积神经网络(FCN)采用卷积和下采样操作提取输入图像的特征,并生成一系列的特征图。在反卷积层中,将最后一个卷积层的特征图进行上采样操作,以获得与输入图像大小相同的输出图像。与常规卷积神经网络不同的是,FCN可以接受任意大小的输入图像,因为它没有全连接层。这种架构针对图像分割问题非常有效,可以实现像素级别的标记,对于图像识别、语义分割和目标检测等任务有着广泛的应用。这种方法更适合用于图像分割和语义分割等任务,可以同时处理不同大小的图像,提高了模型的灵活性和实用性,实现对每一个像素点的类别划分。
2.2. FCN中的1 × 1卷积层
在FCN中,我们使用1 × 1卷积层增加了通道维度,这个通道维度的大小为21,以便于对每个粗略输出位置预测每个类的分数。这个1 × 1卷积层的作用是将原来的输出转换为分类分数矩阵,其中每个数值表示属于某个类别的置信度,然后我们使用反卷积层对这个粗略输出进行双线性插值上采样,将其扩大成与输入图像相同大小的输出图像。这个过程最终会生成一个像素级别的预测结果,对输入图像中每个像素都进行了分类预测,并且输出的每个像素都对应了一个置信度分数。1 × 1卷积层的使用可以带来两个主要的好处:首先,与使用全连接层相比,1 × 1卷积层不会破坏图像的空间结构,因为它只在通道维度上做卷积,不改变原始图像的宽高;其次,由于1 × 1卷积层的输入大小是任意的,因此可以轻松地将其应用于任何尺寸的图像,而全连接层的输入大小取决于图像的大小,因为它需要考虑图像的每个像素。这便使得1 × 1卷积层成为一种极为灵活的设计选择,可以用于多种图像处理任务中,而且具有很高的效率。因此,1 × 1卷积层在图像处理任务中更具灵活性和通用性,能够更好地适应不同尺寸的图像和不同的网络结构设计。FCN融合了图像深层和表层的信息,使得结果更加准确。
3. 连接时序分类机制
时序分类是机器学习中一类复杂的任务,它的目标是根据输入的时间序列数据,预测输出类别标签。它在很多领域中都得到了广泛的应用,如文本分类、语音识别、股票市场分析等。时序分类任务是在机器学习领域中一个重要的研究课题,它与传统的分类任务不同,它不仅需要考虑输入特征,还需要考虑输入特征之间的时间顺序。 [7] 因此,时序分类涉及到多种机器学习技术,如深度学习、聚类分析等。
时序分类任务的方法主要分为两类,其一是基于传统机器学习技术的方法,例如基于统计的方法、支持向量机方法、K近邻方法等;其二是基于深度学习技术的方法,例如CNN、RNN、LSTM (Long Short-Term Memory)等。基于传统机器学习方法的时序分类,主要是通过对时间序列数据进行预处理,然后使用传统机器学习算法进行分类。而基于深度学习的时序分类,则主要是利用深度神经网络对时间序列数据进行特征抽取和分类。在文本分类领域,时序分类可以用来分析文本中的文本序列,从而准确地预测文本的类。
卷积神经网络提取图像的像素特征,循环神经网络提取图像的时序特征,而CTC (Connectionist Temporal Classification)则归纳字符间的连接特性。它消除了对数据预分割的需要,并允许网络直接训练序列标记。
3.1. 对齐问题
在语音识别领域中的语音转文字和光学字符识别(Optical character recognition, OCR)中的字符图片转字符序列问题中,循环神经网络(Recurrent neural networks, RNN)对序列数据的处理较为合适,但是RNN的输入是字符级别的,如图1所示。如果网络的输出与真实标签的长度不一致,无法计算loss。并且字符级别的标注在实际标注中是耗费大量精力,不易获得的。除此之外,虽然通过解码规则(合并相邻的重复字符,去掉空)可以解决网络输入和真实标签长度不一致的情况下也可计算损失,但是会出现多个解码结果对应同一个真实标签的情况,如“-dd-o-gg-”和“—d-oo-g”都可以解码成“dog”。CTC loss解决了上述两个问题。
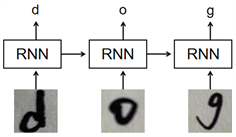
Figure 1. RNN network identification diagram
图1. RNN网络识别过程示意图
3.2. 前向–后向算法
CTC [8] 损失的计算对象是softmax矩阵,softmax矩阵的大小是时间序列的维度与类别数的乘积。前向–反向传播计算的过程是对softmax矩阵进行解码的过程。CTC在计算loss时,计算的本质是对概率的归纳,即找到像素区域对应的概率最大的字符。
对于标签序列l,前向变量
定义为:由F函数将长度为t的路径映射到长度为u/2前缀序列l的概率和。后向变量
被定义为:当附加到对
有贡献的任何路径时,从t + 1开始完成l的所有路径的总和概率。
3.3. 损失的计算
CTC损失函数L(S)被定义为在一些训练集S中正确标记所有训练样本的负对数概率:
因为函数是可微分的,所以它可以通过反向传播来计算它对网络权重的导数,然后可以用任何基于梯度的非线性优化算法对网络进行训练。
4. 图卷积神经网络
4.1. 图卷积网络简介
图卷积神经网络(Graph Convolutional Neural Network, GCN)是一种深度学习模型,用于对图像等非欧几里得数据进行分析和建模 [9] 。GCN网络结构示意图如图2所示,与传统的卷积神经网络不同,GCN可以处理图像、语言和生物网络等非欧几里得结构数据。
GCN的基础是图卷积操作,它通过将节点的特征与相邻节点的特征进行卷积操作来更新节点的表示。具体来说,假设每个节点都有一个特征向量,我们可以用这个向量来表示节点的属性。然后,对于每个节点,我们可以通过将其特征向量与其相邻节点的特征向量进行卷积来更新其特征表示。这样一来,我们可以利用节点间的关系信息来进行节点表示的更新。
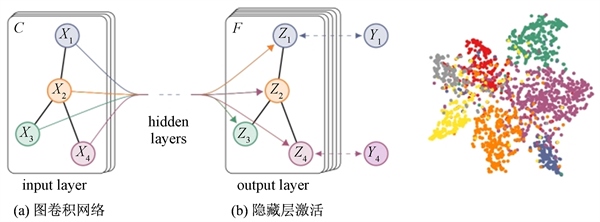
Figure 2. Schematic diagram of multi-layer graph convolutional network (GCN) for semi-supervised learning, whose input channel is C and output layer is F feature mapping. The graph structure (the edges are shown as black lines) is shared between layers
图2. 用于半监督学习的多层图卷积网络(GCN)的示意图,其输入通道为C,输出层为F特征映射。图结构(边缘显示为黑线)在层之间共享
使用GCN进行分类或预测时,通常将已有图像的节点和标签作为训练数据,进行监督学习。模型的目标是学习到一个映射函数,能够将节点的特征向量映射到给定的标签。训练过程中,我们需要最小化预测值与真实标签之间的差异,通常使用交叉熵损失函数进行优化。
总的来说,GCN是一种灵活且强大的神经网络,适合于处理非欧几里得结构的数据,它已经在许多领域取得了成功的应用,例如社交网络分析、图像分类、推荐系统等。通过这种方式,节点之间复杂的交织关系可以通过堆叠多个GCN层来建模。
4.2. GCN与CNN的不同点
首先两者处理的数据不同。图卷积神经网络的作用和卷积神经网络实际上是一样的,都作为一个特征提取器,不同点在于两者处理的数据不同。CNN处理的是矩阵形式的数据,其数据形式是以像素点的排列为基础,这种类型的数据排列整齐,称为欧几里得结构(Euclidean Structure)。众所周知,图结构即为拓扑结构,是一种非欧几里得结构(Non Euclidean Structure),其特点是排列不整齐,具体表现为:对于数据中的某一点,很难定义其邻居节点,或者不同节点的邻居节点数不同 [10] 。如公共汽车站的路牌,社交网络等等。
其次,在进行特征提取时,两者采用的方式也不同。对于卷积神经网络,提取特征采用卷积的方式。图的特征提取主要分为空域(vertex domain)方法和频域(spectral domain)方法。空间域是指一个由图像元素组成的空间,也叫图像空间。空间域处理是指以长度或距离为自变量,在图像空间中直接对像素值进行处理的方法。这种处理方法通常包括对图像进行增强、滤波、锐化等操作。频域是指以频率或波数为自变量的空间。在图像处理中,可以将图像转换到频域中,为图像处理提供更广阔的空间。频域处理包括傅里叶变换、滤波、频域增强等操作。这种处理方法通过对图像频谱进行操作,可以实现对图像颜色、对比度、锐度等特征的调整和优化。空间域和频率域可以相互转换。频域处理主要用于与图像空间频率相关的处理。如图像恢复、图像重建、图像锐化、图像平滑、噪声抑制、辐射变换、边缘增强、频谱分析、纹理分析等处理与分析。
4.3. 网络结构
图卷积网络的核心公式是
,其中,对于给定的无向网络
其中V中包含网络中所有的N个结点,
,E代表结点之间的边
,邻接矩阵
中的元素可以为二进制编码也可以是权重实数;度矩阵
;结点的特征向量矩阵为
,其中N为结点数,C为特征向量的维数。
5. 实验结果分析
5.1. 数据增强
5.1.1. 针对数据量不足
大多数场景文本识别(scene text recognition, STR)模型依赖于标记后的数据集进行训练 [11] ,然而没有足够大且公开可用的标记真实数据集。由于STR模型是使用真实数据进行评估的,因此训练和测试数据分布之间的不匹配导致模型性能不佳,尤其是在受噪声、伪影、形变等影响的自然场景文本图片上。本文采用谷歌于2020年提出的数据增强工具RandAugment,它由36个为STR设计的图像增强函数组成,每个函数都模拟了某些文本图像属性。
RandAugment的数据增强类型可归结为8大类,分别为blur、camera、geometry、noise、pattern、process、warp和weather。其中模糊可分为虚焦模糊(DefocusBlur)、高斯模糊(GaussianBlur)、运动模糊(MotionBlur)、缩放模糊(ZoomBlur);摄像头即是对摄影各参数的变换,包括亮度(Brightness)、对比度(Contrast)、jpeg压缩(JpegCompression)、像素化(Pixelate);几何形状变换包括透视(Perspective)、旋转(Rotate)、收缩(Shrink);噪声添加可选择高斯噪声(GaussianNoise)、脉冲噪声(ImpulseNoise)、散点噪声(ShotNoise)、斑点噪声(SpeckleNoise);模式变换可分为添加椭圆网格(EllipseGrid)、网格(Grid)、水平网格(HGrid)、矩形网格(RectGrid)、竖直网格(VGrid);变换包括自动对比度变换(AutoContrast)、色彩变换(Color)、均衡变换(Equalize)、反转变换(Invert)、偏光变换(Posterize)、锐度变换(Sharpness)、日光变换(Solarize);弯曲变换包括曲线变换(Curve)、扭曲变换(Distort)、拉伸变换(Stretch);天气变化包括雾(Fog)、霜(Frost)、雨(Rain)、阴影(Shadow)、雪(Snow)。不同的实验结果表明,使用此类方法后,准召的提升大于1%。
对于另外的一些数据增强方法,比如CutOut,Mixout,由于在场景文字图像中有一个字符和多个字符的情况,每个字符占据一个小区域。删除一个区域或混合两个图像将消除文本图像中的一个或多个字符,文本的含义因此而改变,故不采用此类方法。
采用RandAugment方法对数据集中的图片进行数据增强,原图如图3所示,增强后的效果如图4~7所示:

Figure 4. Adjust the AutoContrast of the original image
图4. 对原图像进行自动对比度(AutoContrast)调节变换

Figure 5. Distort the original image
图5. 对原图像进行扭曲(Distort)变换

Figure 6. Add EllipseGrid transformation to the original image
图6. 对原图像进行添加椭圆网格(EllipseGrid)变换

Figure 7. Brightness transformation of the original image
图7. 对原图像进行亮度(Brightness)变换
5.1.2. 针对不规则、弯曲文本
由于铸件形状存在多样性,有圆台体的,如制动缸、制动杆、螺丝,有扁平体的,如制动夹钳,导致字符的形状有弯曲和水平形式。其次,由于摆放位置和拍摄角度的原因,如某些铸件字符不易正面拍摄,会导致拍摄到的字符序列发生不规则的扭曲。基于以上问题,在PGNet网络的基础上加入STN矫正模块 [12] ,达到双重保险。
空间变换基础:图像的几何变换包括透视变换和仿射变换,透视变换又称为投影变换、投射变换、投影映射,透视变换是将图片投影到一个新的视平面,它是二维
到三维
、再到另一个二维
空间的映射。
1) 2D仿射变换(affine):
平移变换:
旋转变换:
缩放变换:
2) 3D透视变换(projection)
平移变换:
旋转变换:
缩放变换:
STN矫正模块的基本原理是对原图像进行矩阵变换,参与运算的是可学习的参数矩阵。矫正过程是可以进行梯度传导,支持端到端的模型训练。以一维向量为例,
代表原图像的矩阵表示,
、
是可学习的参数,
是矫正的结果。运算过程如图8所示。
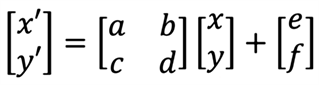
Figure 8. STN correction algorithm calculation process
图8. STN矫正算法计算过程
5.2. 优化损失函数
PGNet论文中,TCL模块的损失应用Dice loss。由于本文研究的字符数据集的字符序列较长,要求拍摄的前景范围大,文本区域自然变小。而Dice loss对小文本识别不友好。故本文采用CTC-Loss + Center-Loss作为损失进行网络的学习。Center-Loss最早用于人脸识别任务,用于增大类间距离,减小类内距离 [13] 。Center-Loss主要用于图像识别领域,训练数据的标签为一个固定的值,而对于OCR识别来说,其本质上是一个序列识别任务,特征和label之间并不具有显式的对齐关系,和CTC-Loss的组合很好的解决了上述问题。通过对badcase的分析,发现识别的一大难点是相似字符多,容易误识别。CTC Loss + Center Loss的算法思想:先将提取出的特征和对应的标签,计算Center-Loss,再将计算出的Center-Loss结果乘以系数然后和CTC-Loss求和。
5.3. 实验结果与性能分析
5.3.1. 实验环境
本次实验的实验环境如表1所示。此次研究利用复兴号动车组上的制动缸、制动杠杆、制动夹钳等铸件进行图片采集。采集图片共477张,为不同背景,不同光照等实际场景下的铸件图片。经过RandAugment数据增强和筛选(去除不合实际的图片),最终共有数据1700张,根据PGNet网络数据划分的要求,将这1700张数据按照8:1:1进行划分,得到训练集、测试集和验证集。其中200张验证集中的图片不参与模型的任何训练和验证过程,作为改进模型和原始模型结果对比的数据集。
模型采用PaddleOCR框架,PaddleOCRLabel工具进行标注,其中,每个检测框采集14个点。

Table 1. Experimental environment list
表1. 实验环境列表
5.3.2. 实验结果

Figure 9. Identification result of PP-OCR algorithm
图9. PP-OCR算法识别结果

Figure 10. Improved PGNet network recognition results
图10. 改进的PGNet网络识别结果
图9为PP-OCR算法的识别结果,从结果来看,只用于水平文本检测识别的网络无法识别弯曲文本,通过改进的PGNet网络,见图10,识别结果较好。

Figure 11. Unimproved PGNet network identification results
图11. 未改进的PGNet网络识别结果
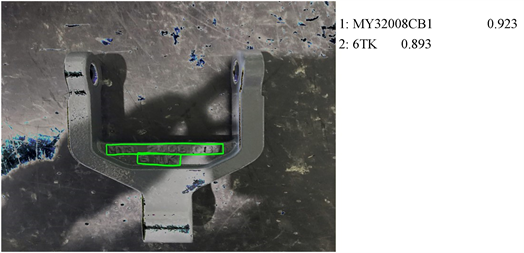
Figure 12. Improved PGNet network recognition results
图12. 改进的PGNet网络识别结果
对比图11、图12,未改进PGNet网络识别结果将数字6识别为字母S,并且错误的将数字8识别为数字6。其他识别结果如图13、图14所示。
通过实验发现,改进前后的PGNet网络检测结果的召回率基本一致,所以主要分析两者检测结果的准确率,即识别对的字符数占总识别出来字符数的比例,可以反应识别错和多识别的情况。
5.3.3. 待改进的地方
通过实验结果发现,易混淆字符对是误识别的主要来源。其中,易混淆的字符对有0和O、0和D、0和Q、5和S、C和G等。这将是下一步研究重点解决的问题。其次,对于损失函数的选择:不同的OCR识别任务,结论可能会有所不同。后续可以尝试Focal-CTC,ACE-CTC,相信会带来不同程度的提升效果。
最后,最终的识别模型要应用于端侧部署,所以权衡好模型的速度和精度也是待实验的部分。
6. 结论
本文针对工业场景下对铸件字符识别的需求,提出改进的PGNet网络,利用RandAugment工具进行数据增强,加入了STN矫正模块,使得弯曲文本的矫正更加准确,改进了损失函数,使用对相似字符鲁棒性更好的Center-Loss和CTC-Loss的组合。以上改进点都在保证效率的情况下,提高了识别的准确率。