1. 引言
随机前沿分析法是测算技术效率的一种参数模型,该模型在实证方面有着广泛使用,主要应用于农业、工业、金融行业等产业的技术效率测算,技术效率反映了决策单元对现有资源有效利用的能力。随机前沿模型为各行各业调整投入决策,实现产出最大化提供科学依据。
Aigner等 [1] 首先提出随机前沿分析法,自该方法被提出,学术界在该模型的构建与估计方面有着丰富的研究成果,已有学者对面板随机前沿模型进行梳理,如边文龙和王向楠 [2] 从效率是否时变的角度总结了面板数据随机前沿模型的研究结果;王韧和李志伟 [3] 从误差分布、时变特征和模型形式等方面梳理面板随机前沿模型的历史演变和发展。目前,空间随机前沿模型是随机前沿模型中的研究热点,许多学者对空间随机前沿模型的构建与估计做研究,如于倩倩等 [4] 构建了地理加权随机前沿模型;Simwaka [5] 提出考虑误差项空间相关性与时间相关性的空间面板随机前沿模型;林显佳 [6] 构建了考虑空间滞后因变量和空间误差自相关的三种不同形式的空间随机前沿模型,包含截面模型和面板模型,且每个模型均有三个不同无效率项分布假设;蒋青嬗等 [7] 构建了考虑个体固定效应的真实固定效应空间随机前沿模型;Tsukamoto [8] 构建了空间自回归面板随机前沿模型;蒋青嬗和李毅君 [9] 从技术效率时变和非时变两个层面分别构建空间门限随机前沿模型;任燕燕等 [10] 提出动态面板数据空间随机前沿模型并使用广义矩估计方法解决模型的内生性,但假设无效率不随时间变化,在研究对象的时间跨度较长时,该假设不符合实际情况。总的来说,关于随机前沿模型的文献不计其数,但少有文献研究生产函数错误假设的问题,即生产函数不含非线性函数,默认了各经济变量之间的关系是线性的,然而,现实生活中各经济变量之间不仅存在线性关系也存在大量的非线性关系,生产函数形式设定不正确将导致技术效率估计有偏不一致。
在生产函数错误假设问题的研究中,学者们认为应当放宽生产函数的假设形式,考虑利用非参数估计方法来解决此类问题,如Kumbhakar等 [11] 认为随机前沿模型的形式或者单边误差的分布假设是错误的,提出了基于局部极大似然技术的处理非参数随机前沿模型的新方法;Assaf等 [12] 认为生产函数不一定代表真正的前沿技术,构建非参数随机前沿模型并使用张量积傅里叶基拟合未知生产函数,但Kumbhakar等 [11] 和Assaf等 [12] 的非参数随机前沿模型不考虑空间效应,模型中的所有决策单元相互独立,这违背了地理学第一定律,将导致技术效率的测度结果存在较大偏误。蒋青嬗等 [13] [14] 构建一个同时包含随机前沿模型和回归模型的半参数空间零无效率随机前沿模型,模型引入空间效应和非参数模型,即生产函数由线性部分和非线性部分共同组成,然而非参数模型只允许有一个输入变量。
综上所述,虽有许多文献各自弥补了模型的一个不足之处,但少有在空间随机前沿模型中考虑生产函数形式错误假设的问题研究,当研究的问题存在前后相互关联的关系且研究内容的时间跨度较长时,静态模型不能很好地进行客观拟合分析,非时变无效率项也不能反应实际情况,因此,研究具有时变效率的非参数动态随机前沿模型具有实际意义。相比于极大似然估计法,贝叶斯估计方法在函数推导方面较为简便,且因复合误差项的非对称性,模型采用贝叶斯估计的效果比最小二乘法的好。鉴于此,本文构建非参数动态空间随机前沿模型,允许无效率项时变,通过多元B样条逼近未知生产函数,利用贝叶斯估计实现模型估计。本文首先介绍了非参数动态空间随机前沿模型的一般形式及其相关假设,其次给出了模型的条件后验分布、参数抽样过程和模型估计精度评估方法,最后对模型进行数值模拟。
2. 基本模型及假设
模型的一般形式设计如下:
(1)
其中,
,
,
为t时刻第i个生产单元的产出指标;
是一个未知函数,
是空间权重矩阵元素,表示生产单元i和生产单元
的空间相关关系,
表示为t时刻第i个生产单元的K个投入指标,式(1)中假设
,
,且用如下线性组合估计未知函数:
(2)
(3)
其中,
,
,
,
为某一可能组合的样条张量积的节点数,S表示K个投入指标所有可能组合的数量。
为多元B样条基向量,
为q阶B样条函数。系数向量
服从多元正态分布,即
,Λ为正定矩阵。
式(1)可以用矩阵形式如下:
(4)
其中,
,
,
,
均为N维向量,w为
阶的空间距离矩阵,
为
的样条基矩阵,具体如下:
(5)
若令
,
,
为N阶单位矩阵,则式(4)转变为如下式(6):
(6)
其中,
,
。
3. 模型的贝叶斯估计
3.1. 参数的先验分布假设
将无效率项视为未知参数,模型的未知参数为
,对样条基系数
的分布假设参考了Yoo等 [15] 的处理方式,节点个数
服从泊松分布,其他未知参数参考蒋青嬗等 [7] 、任燕燕等 [10] 文章中关于模型参数的分布假设,本文对所有未知参数的假设如下:
,
,
,
,
,
,
,
其中,
和
分别是空间权重矩阵
的最小和最大特征值。
3.2. 条件后验分布
由复合误差项的分布假设和式(6),可得到随机误差项
的概率密度函数如下:
(7)
则
和
的联合密度函数:
(8)
由联合分布函数和先验分布可得到联合后验分布,从联合后验分布中推导出各参数后验分布,简记
,
,各参数将分别从以下对应的分布函数中抽样:
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
其中,
;
;
;
。
3.3. 参数抽样
从以上所得到的参数条件后验分布可知,参数
的抽样可通过Gibbs抽样来完成,参数
,
可通过MH方法进行抽样。对参数
的抽样过程可整理为以下5个步骤:
1) 对所有参数赋予初值,记为
;
2) 给定参数的初值
,通过MH算法来更新参数
,记更新后的值为
;
3) 给定参数
的值,通过Gibbs算法来更新参数
,记更新后的值为
,根据
和
即可获得
;
4) 给定参数
的值,通过MH算法来更新参数
,记更新后的值为
;
5) 给定参数
的值,通过Gibbs算法来更新参数
,记更新后的值为
;同理更新
,更新后的值记为
这样便完成了从初始状态
转移到下一个状态
,然后再以
代替初值,重复进行步骤1至步骤5直到收敛,最后用后验样本均值来估计所有参数。
从M次迭代中取最后的M/3个观测值数据,计算各参数
的平均值作为参数估计值,计算
的均值作为非参数模型估计值。
3.4. 数值模拟评估方法
考察参数
的标准差、偏差、均方误差和平均绝对误差。考察非参数模型
的均方误差、平均绝对误差和拟合优度。同时,为观察非参数模型估计值与真实值的数据分布情况,给出对应的核密度曲线图。标准差、偏差、均方误差、平均绝对误差越小,模型估计精度越高,非参数模型估计值与真实值之间的核密度曲线越贴近则估计精度越高。
4. 数值模拟
对所建模型进行数值模拟。设计2组模拟:
1) 模拟一:
样本量为
,被解释变量数量为1,解释变量数量为2,数值均由均匀分布
产生。对于非参数模型,阶数
,系数
的先验分布中超参数
,
。误差的后验分布超参数
,
。空间权重矩阵为对角线上为零的0-1对称矩阵,矩阵大小为
,为减少区域间的外生影响对空间权重矩阵标准化。假设模型中生产函数形式如下:
(17)
2) 模拟二:
样本量为
,其他设定与模拟一相同。
两组模拟分别产生符合上述假设的数据用于数值模拟,模拟迭代1000次,取最后1000/3个观测值的平均值作为参数估计。非参数动态空间随机前沿模型的估计精度结果详见表1。
据表1所示:模型的估计量精度较高,总体上模型的估计精度随样本量的增加而提高,但参数
的偏差表现不稳定。当样本量为200时,参数
的偏差和均方误差均高于样本量为100时的,但参数
的标准差和平均绝对误差比样本量为100时的低,表明
估计量的偏差表现不稳定。当样本量为200时,其余参数
的标准差、偏差、均方误差和平均绝对误差均比样本量为100时的低,非参数模型
的均方误差和平均绝对误差均比样本量为100时的低,其拟合优度比样本量为100时的高,表明参数
的估计精度随样本量增加而提升。
从核密度曲线图上看,多元B样条具有良好的拟合能力。以下展示两组数值模拟中非参数模型
的核密度曲线图。图1(a)和图1(b)分别展示了模拟一和模拟二中非参数模型的核密度曲线图,其中,
为非参数模型,
为真实生产函数,核密度曲线越靠近则估计精度越高。

Table 1. Estimation accuracy results of nonparametric dynamic space stochastic frontier model
表1. 非参数动态空间随机前沿模型的估计精度结果
注:结果展示将标准差、偏差、均方误差、平均绝对误差和拟合优度五个指标依次上下排列。
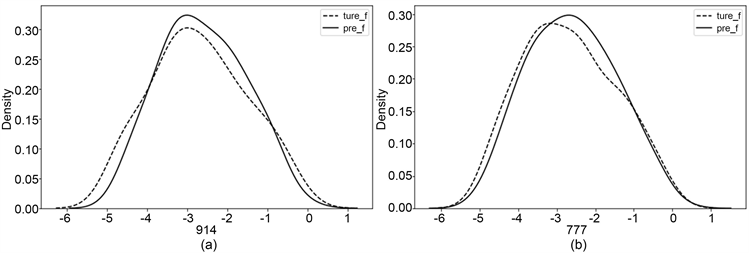
Figure 1. Kernel density estimation plots of non-parametric models in Simulation 1 and Simulation 2
图1. 模拟一和模拟二的中非参数模型的核密度估计图
5. 总结
本文构建一个非参数动态空间随机前沿模型,利用多元B样条逼近未知生产函数,运用贝叶斯方法对该模型进行估计,数值模拟表明:多元B样条具有良好的拟合能力,模型的估计精度随样本量的增加而提高,无效率项方差的偏差表现不稳定。非参数动态空间随机前沿模型放松了生产函数为线性关系的假设条件,拓宽了随机前沿模型的使用范围。