1. 引言
注视行为表明了一个人的视觉注意力,可以指明一个人对什么感兴趣,有助于破译和预测人们的互动、意图或行为 [1] [2] [3] 。人类有一种非凡的能力,可以察觉别人的目光方向,根据别人的目光来确定他们的注视目标,确定别人的注意力 [4] 。然而,自动执行和量化这些仍然是一个具有挑战性的问题。注视行为分析的研究分为注视估计和注视目标检测 [1] [5] [6] 。注视估计指的是确定人的注视方向(通常在3D中),而不是准确定位场景中的人在看哪里 [7] 。相反,注视目标检测是推断场景中每个人(2D或3D)正在看哪里 [1] [3] [8] 。本文讨论了在第三人称视角下的二维图像中的注视目标检测,在这方面,以往工作提出了由两条路径组成的基于卷积神经网络架构。其中一条路径从全局图像中学习特征嵌入,另一条路径则对待测注视目标的人的头部图像进行建模 [9] [10] 。方法 [9] [10] 进行了空间建模,Chong等人 [5] 通过对全局场景和头部图像随时间的嵌入进行建模(即应用时空建模),扩展了上述的双路径架构。 [5] 方法相对于早期研究结果有所改善,但仍缺乏对场景深度的理解。因此沿着注视方向,不同深度有多个可能被注视的目标,就会导致错误预测。 [1] [11] 通过集成深度图像,解决这一缺陷。Fang等人 [1] 还依赖于头部姿态检测,眼睛检测和眼睛特征提取。这样的模型虽然提高了注视目标检测精度,但是现实生活中可能容易出错,例如,当眼睛不可见或不可检测时。 [11] 使用辅助网络估计场景深度、此外还使用伪标签进行3d注视方向估计。 [11] 的性能依赖于可靠的深度和方向伪标签。
我们不需要监督注视角度,这简化了我们的训练过程。与 [5] 不同的是,我们只应用了空间处理,但仍然能够检测到视频中的每一帧的注视目标。与 [1] [11] 类似,我们使用深度图像。使用三条路径来处理:1) 头部图像,2) 全局场景图像,3) 深度图像,深度图是通过独立的单目深度估计从RGB图像 [12] 中获得的。因为我们不需要检测头部姿态和眼睛位置,我们的计算成本更低,比 [1] 简单。与 [11] 不同的是我们的模型没有使用额外的模块来估计头部特征的注视方向。我们使用头部模块隐式的学习注视方向特征。本文研究了不同的方式对于注视目标估计任务的有效性。我们进行了全面的实验分析。不仅我们所提出的方法,而且它的一些变体也超过了现有方法的精度。
训练好的注视目标检测模型的泛化能力对其在实际中的应用至关重要。然而,实证分析表明,当在与训练数据集不同的数据集上的测试时,注视目标检测模型的性能显著降低。基于此,本文研究了域自适应问题,并提出了一种新的域自适应方法集成到所提出的注视目标检测模型中。显著提高了结果。我们研究的主要贡献可以概括为以下几点。
提出了一个新颖包含深度信息的注视目标检测模型,用于检测第三人称视角捕获的2D图像中的注视目标。我们在几个基准数据集上的实验证明了所提模型的性能优于当前的注视目标检测方法。
我们研究了注视目标检测的域自适应问题,并提出了预测一致性的目标域嵌入表示。设计了预测一致性损失,使其能够测量源域和目标域之间的位移。该方法提高了对目标域数据集的性能。
2. 相关工作
下面,我们描述了注视目标检测任务的相关研究。总结了域自适应的研究概况,重点介绍了域适应在注视行为分析和视觉数据的应用。
2.1. 注视目标检测
注视目标检测在多个领域都有应用,如人机交互系统、计算机视觉和机器人技术。其中重要的时理解感兴趣的对象,预测行动 [13] [14] 等等。现有的注视目标检测工作依赖于特定的传感器(眼动仪 [3] ,VR/AR设备 [15] ,RGBD摄像机 [6] [16] 等)或适用于特定设置(面对面会议)或用于注视行为分析(相互注视 [17] ,共同注视 [18] [19] )。另一种分类时关于目标在二维图像 [4] [5] [9] [10] [20] 还是三维空间 [6] [16] [21] [22] 。
本文主要研究在无约束环境下第三人称视角下采集的二维单幅图像的注视目标检测问题。 [10] 是最早的注视目标检测深度学习架构之一,它呈现双路径架构。一个分支获取场景图像来估计显著性(所谓的显著性路径),另一个分支(所谓的注视路径)使用头部图像作为输入对注视方向建模。并且将头部位置信息注入注视路径,显著提高注视目标检测结果。后面的工作 [4] 采用了上述的双通路架构,其他工作 [1] [5] [9] [11] [20] 采用了双通路架构集合头部信息注入。不同的是Chong等人 [4] 扩展了 [10] 的架构,通过同时学习注视角度和显著性来检测不在场景中的注视目标(所谓的帧外注视目标)。Chong [4] 还集成了CNN-LSTM,处理注视和显著性路径的特征嵌入,学习时间上的注视行为。尽管 [5] [9] [10] [20] 提出的模型能够有效的处理注视目标检测任务,但是他们都未能解决场景深度对注视目标检测任务的影响。例如,在注视方向上有多个物体,它们的场景深度不同,这些方法很难确定正确的注视目标。针对于场景深度问题, [1] 利用深度信息和三维注视去除场景深度的影响。然而 [1] 的计算量很大,因为它需要检测头部姿势和眼睛。Jin等人 [11] 的模型也包括深度场景信息,他们设计了和 [5] 一样的预测注视的主要网络。此外为了提高性能,加入场景深度信息,他们引入了两个辅助网络,一个用于学习场景深度特征,另一个用于学习三维注视方向特征。
我们的工作在几个方向与现有技术不同。首先,与 [9] [10] [20] 不同,我们不需要监督凝视角度。与 [5] [9] [10] [20] 不同的是,我们采用单目深度估计方法 [12] 获得深度图像,通过处理人的相对深度改善空间建模。与 [5] 不同的是,我们不仅利用头部特征调节场景信息,还使用头部特征调节深度信息,从而提高性能。另外,我们只依赖于空间信息,没有进行时空数据的处理。我们提出了一种三路径网络,同时学习头部特征、场景特征和深度特征,并使用头部特征对场景特征和深度特征调节。不使用 [1] 中应用的头部姿势和眼睛图像。与 [11] 不同的是,我们的工作不需要额外的深度和方向伪标签,也不需要额外的网络来显示的学习3D注视方向。
与现有技术相比,我们的框架实现了更好的性能,甚至超过了人类的性能。重要的是,针对于二维图像注视目标检测任务,我们提出了简单但有效的域自适应方法,以提高网络的泛化性。
2.2. 域自适应
无监督域自适应(UDA),是一种被广泛研究的方法,用于处理训练数据和测试数据属于不同分布时由于域间隙产生的问题。UDA将仅使用源域的监督训练模型推广到缺乏标签的目标域。关于UDA可以分为三部分1) 基于差异的技术 [23] [24] [25] ,试图在特征级别上最小化源域和目标域之间的距离。2) 对抗方法 [26] [27] ,具有生成器和鉴别器,并试图让生成器创建的特征尽可能接近源域。并且使用鉴别器来促进域混淆。3) 利用自监督学习 [28] [29] [30] 减少域位移。
针对注视估计任务的域自适应相对较少,对于注视目标检测问题,利用添加梯度反转的域分类器,混淆源域和目标域。以及应用RGB→Depth和Depth→RGB模态转换。对于注视估计问题Kell [31] 采用 [32] 的对抗性判别域自适应,其中判别器识别图像特征为二值分类任务,并根据注视估计任务的左右对称性,通过计算原始图像和水平翻转图像的注视,最小化两者之间的角度差。Yu [33] 从注视重定向的监督解决注视域自适应问题,因为不同的人的眼睛结构会导致域间隙,从而导致表现不佳。为了解决问题Yu [33] 从现有的参考样本中生成合成眼图像,并定义注视重定向损失以及循环一致性损失。
然而这些方法大部分都是针对于注视估计的域自适应问题,针对于注视目标检测域自适应问题,我们在注视目标检测模块和我们定义的域分类器之间注入一个梯度反转层。我们还引入预测一致性的嵌入来消除源和目标域之间的间隙。

Figure 1. Domain adaptive gaze target detection model architecture
图1. 域自适应注视目标检测模型架构
3. 方法
模型的整体架构如图1所示。我们用上标s表示为源域,上标t表示为目标域。我们的模型将源域场景RGB图像
、深度图像
、头部图像
、头部位置掩码
和目标域场景RGB图像
、深度图像
、头部图像
、头部位置掩码
作为输入。其中深度图像D是通过对场景RGB图像X使用最先进的单目深度估计器 [12] 得到。头部位置掩码M通过对头部位置的像素值设置为1,其余位置像素值设置为0得到。模型输出两个和场景图像相同大小的注视热图,源域注视热图
,目标域注视热图
,注视热图中像素值最大的像素点位置为预测的注视位置。除了预测注视热图,我们的模型还输出InOut,InOut表示注视目标在帧内的概率,当注视目标在帧内时InOut = 1。
我们模型在Chong [5] 的基础上,加入了深度信息。它与RGB图像一起提供了更加丰富的场景信息。与Chong [5] 不同的是,我们还加入了域自适应模块,包括添加梯度反转 [34] 的域分类器和预测一致性嵌入。下面我们将模型分为两部分介绍:注视目标检测模块和域自适应模块。
3.1. 注视目标检测模块
该模块由三个子模块组成:头部模块(HN)用于处理头部图像,并生成头部调节特征。场景模块(XN)用于处理场景图像X。深度模块(DN)用于处理深度图像D。预测模块(PN),用于生成注视热图和注视目标是否在帧内的判断。
头部模块:给定RGB场景图像
,我们对目标人物头部进行裁剪得到头部图像
。使用ResNet-50后面跟一个平均池化层,对头部图像进行特征提取,得到头部特征
,同时使用三个最大池化层处理头部位置掩码
,拉伸之后与头部特征
拼接。拼接特征经过一个全连接层得到头部调节特征
。
(1)
场景模块:场景模块的主干结构与头部模块相同为ResNet-50。该模块以场景图像
和头部位置掩码
的拼接作为输入提取场景特征。并且将场景特征的每一个通道乘以头部模块生成的头部调节特征
,得到加权的场景特征
。
(2)
其中
为通道乘法。我们通过将场景特征和头部调节特征相乘,使得网络关注头部朝向场景中的物体上,这与 [1] [5] 一致。
深度模块:深度模块具有和场景模块相同的主干架构和相同的维度输入。该模块以深度图
和头部位置掩码
的拼接作为输入提取深度特征。和场景模块一样,我们将深度特征的每一个通道乘以头部模块生成的头部调节特征
,得到加权的深度特征
。
(3)
其中
为通道乘法。我们通过将深度特征和头部调节特征相乘,通过头部特征包含的头部姿态信息,去除场景深度影响。
预测模块:我们将场景特征
和深度特征
的通道和输入到编码器Encode,得到最终的注视特征
。预测模块输出2D注视热图
和注视目标在帧内的概率
。为了获得2D注视热图,我们使用多层解码器Decode,它将最终的注视特征作为输入:
(4)
此外我们还将最终的注视特征
经过三个全连接层计算注视目标在帧内的概率
:
(5)
3.2. 域自适应模块
域自适应模块由两个部分组成。1) 域分类器:它决定注视特征是属于源域还是目标域。2) 一致性嵌入:它使得源域和目标域的注视特征对齐,以提高注视目标检测的性能。
注视目标检测模块权重对于源域和目标域共享。经过注视目标检测模块,源域和目标域得到对应的注视热图
和
。注视热图最大像素值位置为预测的注视目标位置。我们使用
表示源域第i个样本的预测注视目标位置,其对应的注视特征为
,对应的注视位置标签为
。使用
表示目标域第j个样本的预测注视目标位置,其对应的注视特征为
。我们通过源域和目标域的预测注视目标位置约束注视特征,使得源域和目标域的注视特征对齐。
域分类器:域分类器在源域和目标域之间执行二分类,我们使用注视特征作为域分类器的输入。域分类器通过梯度反转层 [34] 连接在注视目标检测模块上。梯度反转层在反向传播训练时将梯度乘以某个常负数。梯度反转层确保学习到的特征尽可能不区分源域和目标域。
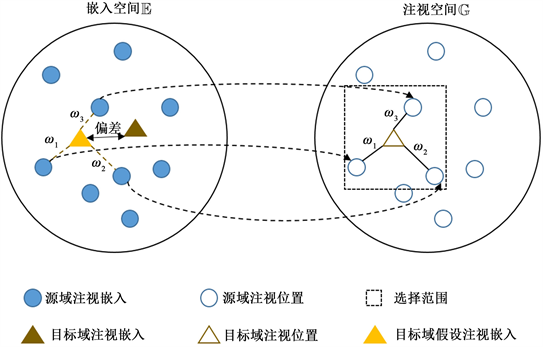
Figure 2. Embedding with prediction consistency
图2. 预测一致性嵌入
一致性嵌入:将注视特征所在的空间描述为嵌入空间
,注视位置所在的标签描述为注视空间
。我们提出了一种域注视的局部线性表示方法(LR),对于目标域,利用源于注视位置线性表示目标域注视位置。对于目标域中的每一个样本,注视目标检测模块预测得到的注视位置为假设标签。我们在注视空间组合K个源域注视位置标签来描述它。
我们首先在注视空间中定义每一个目标域预测注视位置的领域,只有当源域注视位置标签
与目标域预测注视位置
差异小于
时,
被视为目标域预测注视位置
的邻居。我们用
来描述
的所有邻居集合,定义为:
(6)
在拥有K个以上的领域,每一个目标域预测注视位置
随机抽取K个生成
,用于表示
。我们定义权重
表示第i个源域注视位置对第j个目标域预测注视位置
重构的贡献,我们的目的时为每一个
找到最合适的解。
对于与2D注视位置,邻域数量越大,意味着在训练过程中很难找到一个合适的解来最小化重构损失
。我们引入L2正则化确保唯一解。重构损失
表示为:
(7)
其中
,可以写成矩阵形式:
(8)
其中
,
,
为局部协方差矩阵,定义为:
(9)
由拉格朗日乘子法得到使重构损失
最小的解
为:
(10)
当最优权重
时,LR的形式表示为:
(11)
我们将注视空间
中的线性关系转移到嵌入空间
中,生成目标域假设注视嵌入。对于目标域注视嵌入
,对应的假设嵌入表示为:
(12)
如图2所示,注视空间
中的LR权值被继承到嵌入空间
。对于嵌入空间 中的目标域注视嵌入,我们通过公式生成其对应的假设嵌入
。目标域的假设嵌入和源域嵌入之间的线性关系与目标域预测注视位置和源域注视位置之间的线性关系相同。
3.3. 损失函数
我们首先使用源域训练我们的注视目标检测模块,注视目标检测模块的总损失是注视热图上的均方差损失
和注视目标是否在帧内的二进制交叉熵损失
的加权和。
(13)
其中
和
为其权重参数。
对于注视热图损失,我们在标签中给出的注视位置周围放置高斯权重,作为注视热图标签。并使用均方差计算注视热图损失。给定训练过程中的Bt大小批次的源样本,损失函数如下:
(14)
其中
是该批次中第i个样本,
为其对应标签,MSE表示均方差损失函数。
我们通过交叉熵损失函数计算注视目标落在帧内还是帧外的损失,损失函数如下:
(15)
为了实现源域和目标域之间的域自适应,我们提出了两个DA损失,其中预测一致性损失
计算源域和目标域之间的偏差,它确保相源域和目标域相同注视位置的样本具有相同的嵌入特征。同时我们以对抗损失
缓解域偏移,使得目标域嵌入更接近源域嵌入。
对抗损失函数
如下:
(16)
预测一致性损失函数
如下:
(17)
其中函数d为L1距离。
测量目标域假设嵌入与预测嵌入之间的距离。此外由于目标域假设嵌入是源域嵌入的线性组合,
还评估了源域和目标域之间的偏差。在训练过程中,随着目标域假设嵌入与预测嵌入越来越近,域之间的偏移逐渐消除。
因为有些数据集没有InOut标签,所以我们在进行带有域自适应的注视目标检测任务的时候去除了
损失。应用我们域自适应模块的总损失为
、
和
三个损失。域自适应注视目标检测总损失函数如下:
(18)
其中
、
和
为其权重参数。
4. 实验
4.1. 数据集、实现细节、评价指标
数据集:GazeFollow [10] 数据集包含122,143张图片,包含130,339个头部位置和相应的注视点标签,测试集包含4782个标签,其余用于训练集。因为GazeFollow数据集是静态图片,并且不包含注视点落在帧内还是帧外的标签。VideoAttentionTarget [5] 数据集由来自Youtube上各种来源的1331个视频剪辑组成。VideoAttentionTarget的注释包括164,541个帧级头部边界框,109,574个帧内凝视目标,54,967个帧外凝视。测试集包含31,978个标签,其余用于训练集。GOO [35] 数据集是包含24类杂货的货架图像集合。在每张图片中,一个人在看着货架上的一件物品,GOO数据集是注视目标检测任务中第一个同时使用真实图片和合成图片的数据集。在本文中,我们只使用了真实图片,没有使用合成图片。训练集包含9552张图片,测试集包含2156张图片。
实现细节:我们在PyTorch中实现我们的模型。场景图片、头部图片和深度图片都被标准化并调整为224 × 224场景模块、头部模块和深度模块主干基于ResNet-50。场景主干在Place数据集 [36] 上进行预训练,头部主干在Eyediap数据集 [37] 上进行预训练,深度主干也在Place数据集 [36] 上进行预训练。
由于注视目标检测模块决定中的邻域和线性注视表示,因此需要一个训练好的模型来生成可靠的目标域预测注视位置。我们首先使用源域数据集对注视目标检测模块进行70期的预训练,批次大小为16,学习率为2.5 × 10−4。
对于带域自适应的注视目标检测任务,我们要同时优化
、
和
,进行了70次迭代,批次大小为16,学习率为0.0001。我们首先更新源域和目标域的注视嵌入
,
。并通过域分类器DF计算对抗损失
。然后更新目标域预测注视位置
,同时预测源域的预测注视位置。对于目标域预测注视位置
,我们构造
并计算
。我们使用源域标签进行LR操作,以获得更高的精度。通过反向传播对网络参数进行跟新,使得
、
和
最小。
对于不带域自适应的注视目标检测任务,我们要同时优化
和
。该模块在GazeFollow数据集上从头开始训练70期,批次大小为16,学习率为2.5 × 10−4。拟合之后,我们在VideoAttentionTarget数据集上对模型进行微调。此外,我们在GOO数据集上从头开始训练我们的注视目标检测模块,训练70期,批次大小为16,学习率为2.5 × 10−4。
评价指标:我们采用以下的指标来评估模型的性能。AUC↑:我们使用 [38] 提出的曲线下面积(AUC)标准来评估预测热图的置信度。↑表示AUC值越大精度越高。Dist↓:我们评估热图中最大值像素给出的预测值与真实注视点标签之间的距离,↓表示距离越小注视点估计结果更准确。
4.2. 实验分析
4.2.1. 注视目标检测

Table 1. Evaluation on benchmark datasets.
表1. 对基准数据集的评估
我们将我们的注视目标检测模块与表1中的以往方法进行比较。这些比较包括标准注视分析基线,1) 随机,2) 中心偏差,3) 固定偏差,其结果取自 [10] 。随机,表示通过从高斯分布中采样值来生成每一个像素的热图。中心偏差,预测结果总在图像的中心,固定偏差,预测是由训练集中与测试集中头部图像相似位置的头部位置的平均值。
我们的方法获得了同类方法中最好的结果。它甚至超过了GazeFollow和VideoAttentionTarget数据集中的人类表现,分别增加了0.4%和2.2%。在VideoAttentiontarget和GOO数据集上分别性能提升最显著,AUC分别提升了3.8%~11.3%和2.0%~12.4%。在Dist方面我们的方法落后Fang [1] 和Jin [11] ,但性能优于其他方法。因为Fang方法与我们的模型相比,通过添加1) 提取头部姿势,2) 检测眼睛,3) 提取眼睛特征的组件,呈现出更复杂的模型,这在显示应用中可能无法正确执行。另一方面,对于Jin [11] ,我们认为他们模型中的提取3D注视方向和生成深度图像的辅助网络有助于提高Dist,而该方法在AUC方面比我们和其他的方法表现差。
此外,可以观察到,即使是空间模型,我们的方法优于Chong [5] ,其中包括CONV-LSTM网络。因此我们得出结论,与依赖RGB的视频相比,集成由RGB图像生成的深度图像可以获得更好的注视目标检测性能。
4.2.2. 跨数据集注视目标检测
本节研究了图像中注视目标检测任务的域自适应问题。为此我们在一个数据集上训练Chong [5] 的模型和提出的方法,而在一个完全不同的数据集上去测试训练的模型,相应的结果如表2所示。可以看出,我们的方法在所有跨域分析中都优于Chong [5] 。因此我们认为,我们添加的域自适应模块是有效的。
Table 2. Evaluation of gaze target detection performance across datasets.
表2. 跨数据集注视目标检测评估
4.2.3. 消融实验
为了更好的研究我们模型不同组成部分的贡献,我们训练了注视目标检测模块的以下变体。1) 仅包含场景模块:我们去除了头部模块和深度模块。头部特征没有和场景特征关联,仅仅通过头部位置掩码生成头部调节特征。2) 场景模块和头部模块:我们去除深度模块,场景模块和头部模块得到保留。场景模块的输入是场景图像和头部位置掩码的拼接。3) 头部模块和深度模块:我们去除场景模块,头部模块和深度模块得到保留,深度模块的输入是深度图像和头部位置掩码的拼接。4) 我们将深度模块移除,将场景模块的输入换为场景图像和深度图像的拼接。5) 我们将深度模块移除,将场景模块的输入换为场景图像、深度图像和头部位置掩码的拼接。6) 我们将公式4中提出的求和操作替换为拼接操作,拼接特征应用于解码器。相应的结果如表3所示。
结果表明,我们的注视目标检测模块的所有组成部分对于实现最佳性能都很重要。实验1、2、3和4让我们分别了解头部、场景和深度模块的贡献。其中最重要的是头部模块(将AUC提高了16.9),它提供了场景中人的头部方向信息,使得场景模块和深度模块更多的关注头部朝向的区域。贡献第二大的是场景模块(与GazeFollow数据集上的实验3相比,将AUC提高了3.5, Dist降低了0.035).。使用没有深度模块的模型仍然无法处理不同深度的目标。我们提出的方法相比于实验2,AUC提高了0.4,Dist减少了0.09。在VideoAttentionTarget数据集上的性能提升更高,AUC提高了2.5,Dist减少了0.01。
Table 3. Gaze target detection module ablation experiment
表3. 注视目标检测模块消融实验
我们对于添加的域自适应模块也进行了消融实验。我们分别在不包含域自适应模块、仅包含LD损失、仅包含LEPC损失和我们完整的模型上进行实验。
Table 4. Ablation experiment of domain adaptation methods for gaze target detection
表4. 注视目标检测域自适应方法消融实验
表4展示了消融实验结果。实验结果表明我们的域自适应模块每一个损失函数都是重要的,同时使用它们可以获得最佳的性能。其中预测一致性嵌入对性能提升最大。
5. 可视化结果
图3展示了在GazeFollow数据集上的结果,其中我们展示了我们的注视目标检测模块(即没有域自适应)和Chong [5] 的结果以及标签。我们可以看到我们的模型可以有效地处理场景深度对注视目标检测任务的影响。在图4中我们展示了模型有和没有域自适应的可视化结果。源数据集为GazeFollow,目标数据集为GOO时。从图3中可以观察到我们的域自适应方法和没有域自适应方法相比,显著提高了注视目标检测结果。

Figure 3. Visual results of gaze target detection module
图3. 注视目标检测模块可视化结果

Figure 4. Visual results of domain adaptive module
图4. 域自适应模块可视化结果
6. 结束语
我们提出了一种新颖的包含深度信息的注视目标检测模型,在第三人称的视角检测图像中的人在看哪里。我们的模型由三路径组成,1) 头部图像,2) 场景图像,3) 深度图像。场景图像和深度图像提供场景信息和深度信息。它与现有技术不同,因为它不依赖于注视角度的监督,不需要明确的头部方向信息或被检测目标的眼睛位置。大量的评估表明,所提出的方法优于现有方法。
本文还研究了用于注视目标检测的域自适应方法。为此我们想前面所描述的注视目标检测模块添加了域自适应模块。域分类器确保了学习到的特征尽可能不区分源域和目标域,一致性嵌入使得源域和目标域的注视特征对齐。我们的方法增强了目标数据集上的性能。在本文中我们没有从注视目标在帧内还是帧外的精度方面评估我们的方法。这是由于在多个数据集中缺乏相应的标签。
基金项目
安徽省重点研究与开发计划(202004d07020004),安徽省自然科学基金项目(2108085MF203),中央高校基本科研业务费专项资金(PA2021GDSK0072, JZ2021HGQA0219)。
参考文献