1. 引言
在当今这个时代,经济与需求都在快速发展,汽车已经成为社会生活和工作的必需品。尽管近几年电动汽车正在飞速发展,但是不可否认传统的内燃机汽车仍然是汽车行业的主流。这就导致给城市甚至世界环保带来很大压力。国家在不断加强对汽车行业的管控的同时对汽车尾气排放标准也在不断提高。影响汽车尾气排放因素有发动机、进气系统等,但其中一个相当重要的因素则是汽油。
汽油是当今世界上用量最大、用途最广的轻质石油产品之一,主要用于各类交通工具的动力燃料。汽油是通过重油分解出来的,大部分使用的是重油轻质化工技术。国家需要的成品汽油则需要再次进行精制处理。汽油标号代表的是汽油的抗爆性,在工程中则是指辛烷值。辛烷值越高,就代表汽油抗爆值越高。我国为了减少尾气中硫等有害气体的排放,大部分使用的是催化裂化技术来脱硫,但是会使汽油辛烷值的降低,从而导致经济效益大大减少。
命题宗旨是:利用数据挖掘技术 [1] 来建立降低辛烷值损失模型和辛烷值损失预测模型。所建立的模型区别于通过数据关联或机理建模的方法所建立的化工模型,充分利用到了其中大量的操作变量,实现对过程优化的及时响应。通过对主要操作变量的优化,实现减少硫含量的同时保证汽油辛烷值降低幅度最小,同时实现效益的增长。
国内研究者主要集中在辛烷值损失模型的建模方面 [2] ,研究了基于统计学、机器学习和深度学习等技术的辛烷值损失模型。近年来,随着中国石化企业实验室信息管理系统的建成,积累了大量的实验数据。因此,以现有数据库中的汽油理化指标数据集为基础,开始探索和采用一些非线性的建模方法,进行辛烷值的定量计算,如秦玉翠利用误差反向传播人工神经网络(back propagation neural network,BP神经网络),对近红外光谱仪测定数据进行处理分析,如光谱吸光度与汽油辛烷值,结果证明了ANN方法的可行性。另外也有研究以向量机回归法为基础,以分子结构为依据,构建基于烷烃马达法的辛烷值计算模型,最后采用留一法验证模型,验证了数据的鲁棒性。这些研究工作说明了采用非线性的建模方法有利于进一步精确对辛烷值进行定量计算,进而精确对辛烷值的损失定量计算,有利于提高汽油清洁化的效率。
2. 寻找建立辛烷值损失预测模型的主要变量
2.1. 数据预处理
给定的原始样本数据采集于霍尼韦尔PHD (中石化高桥石化的实时数据库)以及LIMS实验数据库,原始数据中大部分位点的变量数据正常,但每套装置采集的数据均有相当部分点位存在问题 [3] ,因为数据在采集和传输这个过程中会存在着数据误传、漏传等一些误差现象,因此需要对原始样本数据进行预处理后才可进行后续分析使用。由于辛烷值的测定数据相对于操作变量数据而言相对较少,而且辛烷值的测定往往滞后,所以以辛烷值数据测定的时间点为基准时间,取其前2个小时的操作变量数据来进行数据预处理。
不良数据处理
1) 异常值处理
a) 根据拉依达准则(3σ准则)去除异常值
b) 通过变量操作范围(最大最小值的限幅方法)剔除异常值
2) 部分残缺及全部空值处理
a) 根据80%法则对缺失值进行删除处理
b) 部分数据为空值的位点用平均值进行插值
数据处理流程图见图1:
2.2. 寻找建模主要变量
2.2.1. 问题分析
为了简化实际的生产问题。需要针对已经处理325个样本数据,将367个操作变量通过降维的操作筛选出建模主要变量,使其尽可能具有典型性,并拥有各自的独立性,方便应用于化工生产中。为了实现降低辛烷值损失的目标,就必须先通过数据降维,来减少不必要因素的影响。能实现数据降维的有以下方法:缺失值比率、低方差滤波、高相关滤波、随机森林/组合树以及主成分分析法。本文使用主成分分析法(PCA)是一种常用于减少大数据集维数的降维方法。利用SPSS软件,使用主成分分析法实现变量的降维处理 [4] 。
2.2.2. 主成分分析法(PCA)
主成分分析法(PCA) [5] 能够把大变量集转换为仍包含大变量集中大部分信息的较小变量集将相关性较高的特征变为相互独立且不相关的特征。优点是在减少数据集的变量数量的同时保留尽可能多的信息。
2.2.3. 主成分分析求解过程
1) 计算标准化样本的协方差矩阵,是反映标准化后的数据之间相关关系密切程度的统计指标,值越大,说明有必要对数据进行主成分分析 [6] 。
(1)
其中
。
2) 得出样本矩阵的样本关系系数矩阵
(2)
3) 检验
进行KMO检验及Barlett球形检验,其中KMO [7] 检验是取样的适当性检验,主要是检验所选择的变量是否包含导致相关的根本性变量;Barlett球形检验是判读相关系数矩阵与单位阵是否有显著差异。如果相关系数矩阵近似为单位矩阵,则变量之间彼此正交,进行主成分分析没有意义,说明两者之间有显著的差异,可以开展主成分分析。
4) 根据协方差矩阵,计算R的特征值和特征向量
特征值:
(R是半正定矩阵,且
)
特征向量:
5) 计算主成分贡献率以及累计贡献率,根据选取的主成分个数的原则,来确定主成分个数。
一般取累计贡献率超过80%的特征值对应的第一、第二、……、第m (m ≤ p)个主成分,第i个主成分:
。
6) 计算主成分载荷
(3)
7) 通过主成分分析,可以得到主成分得分矩阵
2.3. PCA编码实现与结果
变量筛选原则:控制变量对产品性质具有明显的响应关系,变量间相互独立、不存在重复信息;能够全面反映成品汽油的不同特征属性。利用主成分因子方法(PCA)分别对各个操作变量进行分析,根据提取主成分个数累计方差超过80%的原则,通过最大方差旋转法,经因子载荷矩阵旋转后选择载荷值大于0.8的指标作为下一步待筛选指标适用性分析,利用SPSS软件对操作变量进行因子分析。
通过观察表1各个主成分的特征值,可以看出特征值的变化规律,特征值的大小代表了主成分的方差贡献率大小和重要性程度。累计贡献率是因子分析中抽取出的因子特征值之和的比值,取出的因子相较总体变量更具有代表性。

Table 1. Interpretation of total variance
表1. 总方差解释
根据表1和表2的总方差和成分矩阵,就可以计算指标权重,根据要求解释的总方差需要超过80%,同时为了避免在之后的权重计算中出现负值,就需要依靠SPSS对数据进行标准化。
指挥权重计算流程
Step 1:输入数据主成分的特征根和成分。
Step 2:计算线性组合中的系数。
Step 3:计算综合得分模型中的系数。
Step 4:权重计算。
Step 5:对指标权重按高到低排列,选出其中由高到低的22个操作变量作为建模的主要变量。如下表3。
Table 3. Main variables of modeling
表3. 建模主要变量表
3. 建立辛烷值损失预测模型
3.1. 问题分析
需要建立汽油辛烷值(ROM)损失预测模型。采用上文得到的建模主要操作变量,利用数据挖掘技术来建立辛烷值(ROM)损失预测模型,并进行模型验证。根据所得建模主要操作变量的数据分析,需要使用BP神经网络来建立预测模型,利用Matlab软件编写程序,实现对辛烷值(ROM)损失的预测,通过模型验证,来分析误差。
3.2. BP神经网络的基本原理
神经网络又称为连接模型,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法模型。模仿生物神经网络大量神经节点之间相互连接的关系,实现处理信息的目的。
BP神经网络 [8] 具有不断学习的功能,就是在模拟的过程中,通过不断的循环来收集系统所产生的误差,并且通过反馈到输出层,再通过输出层传递信号,最重要的是可以使用这些误差来调整神经元的权重,这样就生成一个可以模拟出原始问题并且能够很好地解决人工神经网络系统。本文就是基于BP神经网络对辛烷值损失的预测来建立模型 [9] 。
3.3. 模型建立
主要因素的确定:由上面的主成分分析分析计算可知,影响辛烷值损失(ROM)的主要因素是22个变量。
BP神经网络的训练过程及流程图见图2:
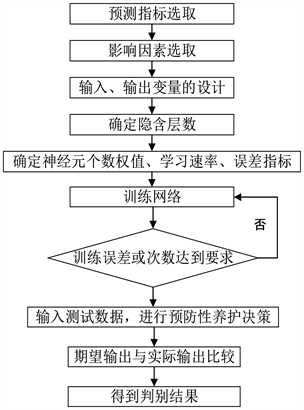
Figure 2. BP neural network flow chart
图2. BP神经网络流程图
1) 计算个层神经元的输入和输出:
2) 计算误差函数对输出层的个神经元的偏导数。
3) 计算误差函数对隐含层各神经元的偏导数。
4) 修正连接权值。
5) 计算全局误差。
6) 判断网络误差是否满足要求。
然后,我们选择辛烷值(ROM)损失相关数据为研究对象,利用Matlab软件进行预测分析,可以得到如图3所示结果。
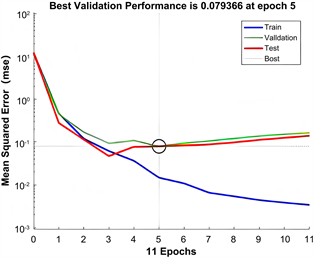
Figure 3. Relationship between gradient and mean square error of variables
图3. 变量的梯度和均方误差之间的关系图
一般来说,MSE的值越小,R值越接近1,模型拟合的越好。通过分析图4可以知道,训练效果比较好。
将拟合值对真实值回归,拟合优度越高,说明拟合的效果越好。由上图拟合数据可知,使用的神经网络预测模型误差很小,说明该模型符合要求。
4. 优化主要变量操作方案
4.1. 问题分析
问题四要求在保证产品硫含量不大于5 μg/g的前提下,求得辛烷值(RON)损失减少的各主要变量的优化条件。即求得使得辛烷值损失最少的,且满足硫含量不大于5 μg/g的各个主要变量的值。也就是求解最优解的问题:辛烷值损失值的最小为目标,22个变量的取值范围以及硫的含量范围作为约束条件,求解最优条件。
其中辛烷值损失量的预测模型在上一章已经求出,此预测模型也即为辛烷值损失量与各个主要变量的关系式。而硫含量与筛选出的主要变量的变化相关,即随着主要变量的变化而变化,因此根据神经网络算法对硫含量再进行一次预测,可以得出硫含量与主要变量的表达式。
4.2. 解决方案
先用BP神经网络算法求出硫含量关于22个主变量的预测模型,然后选定辛烷值损失值的最小为目标,22个变量的取值范围以及硫的含量范围作为约束条件,用粒子群算法对优化问题进行求解。
4.2.1. 粒子群算法求解最优化问题
是一种基于群体智能理论的并行算法,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解 [10] 。它是通过适应度来评价解的品质,但它比遗传算法规则更为简单,它没有遗传算法的“交叉”和“变异”操作,它通过追随当前搜索到的最有值来寻找全局最优 [11] 。
假设
是微粒i的当前位置,
是微粒i的当前飞行速度,那么,基本粒子群优化算法 [12] 的进化方程如下:
(4)
(5)
(6)
(7)
式中,t表示迭代代数;
表示微粒i迄今为止经历过的历史最好位置;
是当前粒子群搜索到的最好位置(全局最好位置);
C1、C2分别为认知学习因子和社会学系因子。
4.2.2. PSO的基本算法流程
Step 1:在允许的范围内,初始化搜索点的位置及其速度;
Step 2:计算粒子的适应度值,即目标函数值;
Step 3:根据以上公式,对每一个粒子的速度和位置进行更新;
Step 4:检验是否符合结束条件,若当前的迭代次数达到了预先设定的最大次数(或达到最小错误要求等),则停止迭代,输出最优解,否则转到Step 2。算法流程见图5。

Figure 5. Particle swarm algorithm process
图5. 粒子群算法流程
4.3. 粒子群算法的初始值设定与结果展示
4.3.1. 粒子群算法的初始参数设定
根据经验对粒子群算法初始值进行设定,如表4所示:
4.3.2. 粒子群算法结果
经过粒子群算法计算后,可得到一组比较理想的使得辛烷值损失取得最小值的最优解,则优化结果见表5。
根据最优化结果可知,硫含量满足要求,且辛烷值损失值的结果为0.2个单位,远小于该厂辛烷值损失值平均值1.37的30%,符合优化要求。
5. 模型可视化
要求以图形展示其主要操作变量优化调整过程中对应的汽油辛烷值和硫含量的变化轨迹。而由于主要操作变量只能逐步调到位,故需要使一个操作变量进行单独的有步长的变化,其他操作变量不变,展现汽油辛烷值和硫含量的变化情况。
5.1. 变量筛选
部分变量的可调整幅度值大于操作变量最优值与133号样本的差值,表示这些变量已经在进行人工操作后,也无法降低辛烷值损失量,故将其剔除。
如表6所示,操作变量D101原料缓冲罐压力不符合上述条件,进行剔除,不予考虑。
5.2. 可视化分析
绘制图,以某操作变量的值为横坐标,以辛烷值与硫含量的值为纵坐标。操作变量以相应可调整幅度值进行递增或递减,解出的最优值133号样本的值进行逼近。辛烷值与硫含量的值由上文的预测模型和操作变量值进行确定。在筛选出的主要变量中,以D-123凝结水入口流量作为典型例子,进行绘图分析。
由图6可见,D-123凝结水入口流量的值从2000个单位到0时,也即从133样本的值到最优解时,辛烷值损失值逐渐减小,且硫的含量满足要求。

Figure 6. Relation among sulfur content, octane number loss value and D-123 condensate inlet flow
图6. 硫含量、辛烷值损失值关于D-123凝结水入口流量关系图
6. 结论
本文首先基于对辛烷值损失影响的大小,利用主成分分析筛选主要影响变量,得到22个主要变量:然后通过得到的主要操作变量利用BP神经网络建立辛烷值损失预测模型,模型验证后误差很小,说明构建了可靠的计算模型:为了优化变量,满足辛烷值和硫含量的要求,使用高精度的粒子群算法,使实现的损失值远小于优化目标。