摘要: 吸烟有害健康,为优化办公环境以及保证办公室人员身心健康。随着深度学习中卷积神经网络(Convolutional Neural Network, CNN)在目标检测领域上的发展,其目标检测方法有:单阶段检测(YOLO、SSD、RetinaNet等)、双阶段检测(Fast RCNN、Faster RCNN、Cascade RCNN等)。相比于传统的手工设计特征算法,基于深度学习的方法通过学习大量标注数据来自行进行特征的学习和提取,并预测或识别出结果,基于深度神经网络的目标检测方法具有更好的特征提取能力和分类识别效果。本文设计了采用YOLO深度学习算法的办公室吸烟行为检测方法。通过网络公开数据集收集的吸烟数据集,经过对数据集的整合与调整形成最终进行实验的吸烟行为检测数据集。用吸烟行为检测数据集分别训练YOLOv5,YOLOv6,YOLOv7,YOLOx四个模型,通过对比训练产生的结果得到办公室吸烟行为检测的最佳训练模型。实验结果表明,在办公室吸烟行为检测实验中,YOLOv5为检测效果最优异的模型,其精确度均值(mAP):76.6%,平均推理时间:17.1 ms。
Abstract:
Smoking is harmful to health, in order to optimize the office environment and ensure the physical and mental health of office staff. With the development of Convolutional Neural Network (CNN) in the field of target detection, the methods of Convolutional Neural Network detection include one-stage detection (Yolo, SSD, RetinaNet, etc.) and two-stage detection (Fast RCNN, Faster RCNN, Cascade RCNN, etc.). Compared with the traditional hand-designed feature algorithm, the method based on deep learning can learn and extract feature by learning a lot of labeled data, and predict or recognize the result, the object detection method based on deep neural network has better feature extraction ability and classification recognition effect. In this paper, Yolo deep learning algorithm is used to detect office smoking behavior. The smoking data set collected through the web-based open data set was integrated and adjusted to form the smoking behavior detection data set for the final experiment. Four models, Yolov5, YOLOV6, Yolov7 and Yolox, were trained with smoking behavior detection data set. The best training model of office smoking behavior detection was obtained by comparing the results of training. The results showed that YOLOV5 was the best model in the detection of office smoking behavior. The mean accuracy (mAP) was 76.6% and the mean reasoning time was 17.1 ms.
1. 引言
办公室是公共场所,根据卫生部《公共场所卫生管理条例实施细则》第十八条:室内公共场所禁止吸烟。所以在办公室禁止吸烟不仅是国家的明令要求,也是创建文明、和谐、健康社会与生活的必然要求。但就目前公司禁烟情况来看,还任重道远。
国内外还未将深度学习应用于办公室吸烟行为检测场景,本文首次作出尝试,将深度学习中的卷积神经网络用于办公室吸烟行为检测。
通过对学者们在多场景下的吸烟行为检测研究的科研课题的学习,本文归类出吸烟检测方法主要包括烟雾检测 [1] [2] [3] 、手势动作检测 [4] [5] 和香烟目标检测 [6] ,其中,由于香烟烟雾形态复杂、透明度高,关键检测因素采集难度大导致检测精确度低;由于吸烟时手势动作与喝水吃饭等动作相似,靠手势动作判断吸烟的误检率高。因此本文采用香烟目标检测的方法进行吸烟行为识别,将办公室图像信息输入吸烟检测算法中,对香烟目标进行检测。
基于深度学习的目标检测方式,对光线、形变等不确定变量的鲁棒性强,且当今基于深度学习的目标检测,检测的精度和效率得到了很大提升,目标检测的YOLO系列算法已经迭代多代。故本文采用基于YOLO [7] [8] [9] [10] 模型的目标检测方法,用吸烟行为检测数据集分别训练YOLOv5,YOLOv6,YOLOv7,YOLOx四个模型,通过对比训练产生的结果得到办公室吸烟行为检测的最佳训练模型。
2. 模型检测原理
本文实验所用四种模型均为单阶段目标检测模型,即对目标直接分出类别,并对边框进行回归,检测原理如图1所示,相比于双阶段目标检测 [11] [12] 模型,单阶段目标检测模型省去了区域提名(Regionproposal)。
YOLOv5、YOLOv6、YOLOv7和YOLOx四个模型出自于不同的团队,网络结构各有不同。如图2所示,为YOLOv5的网络模型。YOLOv5的骨干网络为CSPDarknet53 (含SPPF),Neck为FPN + PAN结构。YOLOv6、YOLOx和YOLOv7的检测思路和YOLOv5相似。其中YOLOX的主要改进是引入了Decoupled head解耦头的结构,如图3所示。YOLOv6骨干网络由YOLOv5的CSPDarknet换为了EfficientRep,neck基于Rep和PAN构建了Rep-PAN。YOLOv7在backbone加入E-ELAN,E-ELAN对基数(Cardinality)做了扩展(Expand)、乱序(Shuffle)、合并(Merge Cardinality),能在不破坏原始梯度路径的情况下,提高网络的学习能力。

Figure 2. Structure diagram of YOLOv5
图2. YOLOv5网络结构图
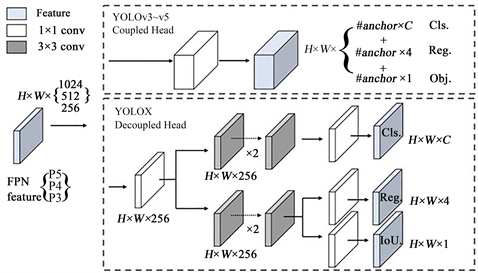
Figure 3. The structure of the YOLOX decoupled head
图3. YOLOx解耦头的结构
3. 数据集与实验配置
3.1. 数据集采集及制作
通过网络公开数据集收集吸烟检测数据集,数据集中包含图片信息与标签信息。由于收集的数据集中有部分数据损坏或不满足办公室吸烟检测条件,所以对收集到的数据集进行重新整合与修改,并添加自己通过Label Img制作的数据,最终形成本文实验所用包含4857张图片的办公室吸烟检测数据集。由于不同模型训练的数据集格式不同,所以,该数据集被制作为YOLO格式和VOC格式两种格式进行实验。
3.2. 配置
本次实验在AMD Ryzen 5 5600H with Radeon Graphics处理器,主频为3.30 GHz,内存为16 Gi B,显卡型号为NVIDIA GeForce RTX 3050的PC机上进行,在CUDA11.8环境下利用深度学习框架Pytorch对四个模型进行训练与测试,具体实验配置见表1。训练模型的参数设置如表2所示,模型的训练次数Epoch设为100;批次大小Batch size是指训练时一次性输入网络的图片数目,与显卡大小和模型大小有关,所以,将YOLOv5,YOLOv6,YOLOv7三个模型的Batch size设置为4,将YOLOx模型的Batchsize设置为2;输入分辨率均采用模型原始初始值640,四个模型均加载官方预训练权重进行训练。

Table 1. Experiment environment configuration
表1. 实验环境配置
Table 2. Training parameter setting
表2. 训练参数设置
4. 结果与分析
4.1. 模型性能对比
由于YOLOv5,YOLOv6,YOLOv7,YOLOx四种预训练模型的网络有所差异,所以在不同的数据集上表现出来的效果都有所不同。为了得到更适用于办公室吸烟检测数据集所对应的权重数据,用数据集分别对这四种模型进行训练。然后用测试模型加载训练数据集得出的权重,用含300张图片的测试集对四种模型进行性能对比。通过计算四种模型在测试集上的精确率P均值(mAP)以及召回率R来评价模型的性能,如公式(1)所示为精确率的计算,如公式(2)所示为召回率的计算。
(1)
(2)
公式(1)和公式(2)中,TP表示将正类别预测为正确类别的个数;FP表示将负类别预测为正确类别的个数;FN表示将正类别预测为负类别的个数。YOLOv5,YOLOV6,YOLOv7,YOLOx四种预训练模型测试的结果如表3所示。
Table 3. Performance comparison of different models
表3. 不同模型性能对比
由表3可知,YOLOv5模型的mAP值最高,相对于YOLOv6模型,YOLOx模型,和YOLOv7模型分别高出0.6,3.5,和16.9个百分点。YOLOx模型的召回率最高为85.8%,其次是YOLOv5模型,为80.1%,相比于YOLOv6和YOLOv7模型分别高出15.7和22.5个百分比。YOLOv5的平均检测时间最快,为17.1ms。四个模型对吸烟行为检测样例如图4所示。
从图4的检测对比可以看出,YOLOv5的预测精确度较高为0.87,优于其他三种检测模型。
4.2. YOLOv5模型训练过程分析

Figure 5. Loss and accuracy of YOLOv5 network
图5. YOLOv5实验损失和精度值
综合上述四种模型的测试性能以及测试效果,本文选用YOLOv5模型训练得到的最佳权重数据。图5描绘了模型训练时的精确度均值(mAP)和训练损失随迭代次数的变化值。从训练次数Epochs的值为0开始,mAP从0开始快速上升,训练损失值由0.10开始迅速下降,标志着网络模型开始对图片特征进行学习。当训练次数Epochs为40附近时,精度升至0.74,曲线趋于稳定,波动减少;损失值降至0.04,下降速度减缓。当训练次数Epochs为80附近时,精确率曲线趋向为0.766的稳定值,训练损失曲线趋向为0.028的稳定值。由此,YOLOv5模型训练过程稳定,性能优良。
5. 总结与展望
本文首先对收集的数据进行预处理,得出更符合办公室吸烟行为检测的数据集,通过对比YOLOv5,YOLOv6,YOLOv7,YOLOx四种预训练模型所得的性能结果和检测效果,得到最优权重数据。试验结果表明,相较于其他三种模型,使用YOLOv5模型检测办公室吸烟行为的方法可以快速、精确地识别出吸烟行为,为办公室禁烟提供了一定保障。
作为国内外基于深度学习的办公室场景下的吸烟行为检测的首次尝试,YOLOv5的表现并不俗,我后续将对YOLOv5网络模型做出进一步调整,期待更好的检测结果。