1. 引言
音频场景识别是环境声音的感知和理解领域中的一个重要研究方向,该任务通过对外界输入的音频进行处理,通过解析音频序列内部的特征关系,来判断机器处在何种场景下,从而帮助机器针对不同场景做出不同的应对措施。
早期对于音频场景识别的研究一般是基于传统机器学习算法实现的,如混合高斯模型 [1] [2] 、支持向量机 [3] 等。但是随着深度学习的发展和大量的较大规模音频公开数据集的出现,尤其是声音事件检测比赛DCASE (Detection and Classification of Acoustic Scenes and Events) [4] 的举办,使得传统机器学习算法的大规模数据拟合能力显现出了不足。许多学者开始使用神经网络进行音频场景识别的研究,用以代替传统的分类器实现音频场景分类,并取得更好的效果 [5] [6] 。伴随着卷积神经网络的快速发展以及近年来注意力机制在图像分类分割 [7] [8] 等多种任务上的出色表现,这些方法同样被引入了音频识别的研究中 [9] [10] 。
由于将场景识别算法部署到实际设备中需要进一步提升推理速度并降低模型大小,本文提出的网络模型结构(SFAC)从三个方面进行用于场景识别的神经网络模型的设计:1) 采用时–频分离的思想设计轻量化卷积模块,增大重新设计的网络对频域信息的提取能力。2) 使用深度分离卷积替换原始的卷积,降低网络的整体参数量。3) 采用改进后的注意力机制,同时提取特征图内部和通道间注意力关系,弥补轻量化卷积设计引发的精度下降问题,提升整体精度。
2. SFAC网络
2.1. 卷积神经网络
卷积神经网络(CNN)是一种在神经网络模型中应用广泛的网络结构,其主要功能结构由卷积层、池化层和映射层组成。卷积层通过一个各通道之间共享权重的卷积核在特征图上的滑动运算操作达到特征提取的效果,卷积核的大小约束了该层卷积的关注野的大小。池化层可以看作一个下采样操作,通过池化可以在减小特征图尺寸的同时,等效增大下一级卷积层的关注野大小。映射层一般由一层或多层的全连接网络组成,用于将卷积后的特征映射到目标维数进行输出。在训练时,通过神经网络中经典的梯度反向传播方法进行各层参数的迭代更新优化。
CNN网络一般会通过多层堆叠卷积层和池化层进行深度特征的提取操作,相当于将输入的特征编码成更高维度的融合特征,可以更充分利用输入特征中的各种模式组合。在卷积堆叠的过程中,特征图尺寸会逐级下降,最终形成一个金字塔形的特征变化结构,这样的卷积结构称为特征金字塔。
2.2. SFAC结构
浅层的特征金字塔结构通常会面临特征特征提取能力不足的问题,而加深的特征金字塔结构会增加网络复杂度换取更优的特征提取效果。本文在保持一定的特征金字塔深度的前提下,根据语音特征的特点进行了网络结构的轻量化设计,提出了SFAC (SequenceFrequency Attention CNN)网络,能够更充分地提取特征。如图1所示,SFAC网络整体依旧以低层数的低复杂度卷积神经网络构成,网络主要分成时频复合层(Sequence)、频域解析层(Frequency)、注意力映射层(Attention)三部分。

Figure 1. The diagrammatic sketch of structure of SFAC
图1. SFAC结构示意图
Conv5表示该层使用的卷积核尺寸为5,每个时频复合卷积层和频域卷积层都由一组卷积层和池化层组成,每层卷积后都会接入批归一化层(Batch Normalization),让卷积层能更好的训练,进一步提升网络的收敛速度和泛化性能。本文参考文献 [11] 中提出的远端补偿方法,使用残差连接让第一个时频复合卷积层的带有底层时域卷积特征的特征图与经过频域卷积层后的特征图相加,用以弥补特征金字塔多次卷积后的低层时域特征信息丢失问题。
注意力映射层中包含了注意力实现模块和全连接模块,分别负责注意力权重计算和特征映射,在全连接模块中加入Dropout,在训练时按照设定的概率选取神经元失活,防止网络过拟合。
3. 时频分离轻量卷积
3.1. 深度分离卷积
在图像领域的相关工作中,深度分离卷积 [12] (Depthwise Separable Convolution)在Xception [13] 和MobileNet [14] 中的应用受到了广泛的关注。
如图2所示,深度分离卷积主要将原始卷积拆分成了两个独立的部分,即逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。逐通道卷积将每一个输入特征通道对应一个单独的卷积核,所有通道的卷积结果最终重组为相同通道数的输出特征图组,逐点卷积采用尺寸为
的普通卷积核,用于轻量化的改变特征的通道数同时进行通道间的特征融合。逐通道卷积过程中并不会改变通道数,通道数的改变在逐点卷积中实现。
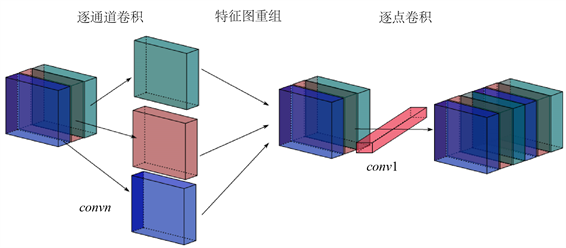
Figure 2. The diagrammatic sketch of the depth wise separable convolution
图2. 深度分离卷积流程图
使用深度分离卷积替代普通卷积,可以提升卷积运算的速度,同时降低模型的参数量。但是同时有可能会伴随而来一系列的轻微性能下降,需要设计另外的增强方法以弥补这一缺陷。
3.2. 异形卷积与时频分离卷积
与图像领域的输入不同,语音任务中常使用的频谱图特征在不同的方向上表示的特征信息并不相同,在时域方向上的卷积和在频域方向上的卷积提取的特征对最终的分类的贡献度也有所不同。而卷积核大小为
的异形卷积相比标准卷积,可以在卷积时只考虑与卷积方向相同的维度的特征表示,从而单独将频域特征或时域特征进行突出表达。

Figure 3. The diagrammatic sketch of time-frequency convolution
图3. 时频卷积复合层示意图
本文选取了2层卷积堆叠的模型结构,将标准卷积分别换为时域方向和频域方向的异形卷积进行了对比,发现网络在收敛以后,单纯频域方向的卷积网络的识别准确率较高,故说明在音频场景识别的任务下,频域特征相比而言具有更高的特征提取价值。
故本文在SFAC中利用时频方向不同的特征特性,设计了时频分离卷积的结构。如图3所示,本文将前两层卷积设计为一组频域方向和一组时域方向的异形卷积组合而成的时频复合卷积层。在后两层较高维度上设计为仅对频域方向上进行采样的频域卷积层。在卷积的实现形式上均采用深度分离卷积,同时这样将
的卷积核拆成一组卷积核
和
的方法可以将卷积核存储的参数量从
降低到
。而频域卷积层相比原始的网络减少了时域方向上的卷积运算,该层的参数量和计算量都可以收缩到n。
4. 卷积注意力
4.1. 注意力池化
传统的池化机制主要是平均池化和最大池化,其一般与卷积层配合使用,将卷积后的特征图尺度降低,从而达到抽象更高维度的特征和降低内存使用量的作用。为了在保持池化作用的前提下,引入注意力机制充分利用特征图中的不同特征模式,文献 [15] 提出了注意力池化机制,其大致描述如下:
(1)
(2)

Figure 4. The diagrammatic sketch of the attention based pooling layer
图4. 注意力池化层示意图
如图4所示,注意力池化输入的特征图
将通过两个
的普通卷积进行分流,同时将特征图通道数降低,卷积结果分别通过Softmax激活函数和Sigmoid激活函数生成注意力矩阵
和分类矩阵
。而矩阵
通过概率模型计算得概率矩阵
,
内部的每一个元素对应
矩阵中对应元素的重要性。最后通过分类矩阵和概率矩阵逐元素相乘得到注意力池化模型的输出,从而可以根据实例的贡献为实例赋予权重,从而获得更优化的预测结果。
经过时频分离卷积后的特征应当包含了更高维度的频域特征组合,本文考虑音频分类场景下频率方向上的特征的有效性一般更高,如图5所示,将映射方法从逐元素求和改进为先对时间维度进行平均化,再对频域维度进行最大化求值,得到一个长度为批量大小的1维张量。故改进后的注意力层先统一对输入特征降维为50维度,再进行注意力系数计算。最后
计算出的结果通过一个最大平均化的操作代替原始的逐元素求和,最后经过线性变换层映射到目标维数。
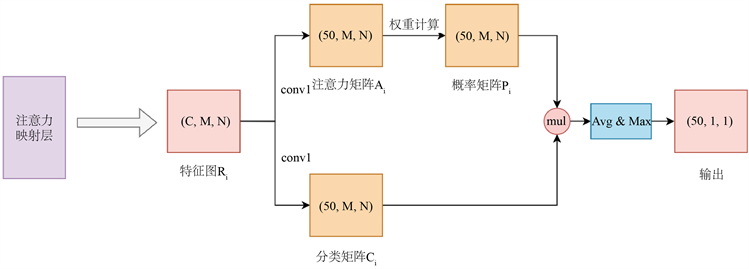
Figure 5. The diagrammatic sketch of the attention reflect layer of SFAC
图5. SFAC注意力映射层示意图
4.2. 通道注意力
区别于常规注意力机制主要作用于特征图内部关联,文献 [16] 提出了一种对特征图通道间关联权重的建模方法,称为SE Block (Squeeze and Excitation Block)。如图6所示,该方法将卷积后的多通道特征先通过压缩(Squeeze)过程,在特征图层面使用全局平均池化(Global Pooling),将特征图压缩到尺寸为1。在特征通道层面按照设定的压缩比例(Reduction)使用全连接层将通道数压缩,随后再使用全连接层将通道数恢复为输入的大小,经过sigmod激活函数后,得到每个通道的注意力权重。
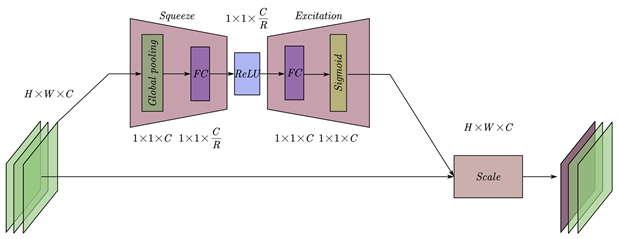
Figure 6. The diagrammatic sketch of the SE Block
图6. SE Block示意图
本文在网络的实现中,在时频复合卷积层之后和频域卷积层之后都部署了基于SE Block的通道注意力机制,与注意力池化层共同作,同时提取特征图中通道间和特征图上的非线性关系,可以在付出少量的计算量和网络复杂度的增加的代价下,实现更充分的特征提取效果。最终参照ResNet [17] 中提出的残差连接结构,将浅层时域信息与深层注意力频域信息进行融合。
5. 实验与结果
5.1. 数据集
本文提出的改进音频场景分类模型在以下数据集上进行了实验和评估:
UrbanSound8K分类数据集包含一组8732条来自10种不同的城市场景的录音,总音频长度8.8小时。数据集中单段音频长度小于等于4秒,采样设备为麦克风,采样率为44.1 kHz或者48 kHz。
TAU Urban Acoustic Scenes 2020 Mobile [18] 数据集(TUT2020)包含来自多个个欧洲城市使用4种不同设备的10个不同声学场景中的录音。录音设备为双耳麦克风、三星Galaxy S7、iPhone SE和运动相机gopro。数据集总音频片段数量为23040个,单个片段为44.1 khz采样率的10秒长度音频。
5.2. 实验方法
与DCASE基线系统一致,本文的实验使用的输入为对数梅尔频谱特征(logmel),提取出的特征大小固定为
,提取40维的梅尔带。
在网络训练过程中,采用初始学习率为0.001的Adam优化器对卷积神经网络进行优化训练。整体系统采用Pytorch 1.8进行编码实现,在Nvdia A40 GPU上进行实验,本文进行对比的低复杂度卷积网络如下表1所示,其中Conv3-64;s1表示该层卷积网络采用的卷积核大小为3,输出特征图通道为64,卷积步长为1。
5.3. 实验结果
本文从整体模型在多个数据集上的表现准确度、模型参数量和模型推理速度进行综合的评估展示。
5.3.1. UrbanSound8K
在UrbanSound8K数据集上的测试结果如表2所示,相比CNN_P基线模型,本文提出的SFAC模型总体上预测准确度有2.6%的提升,在10个子项中有9个子项的预测准确度有所提高或者持平,在枪声识别上出现一定量的下降。相比VGG-4和CNN_NP基线模型,本文提出的模型在准确度上有较大的优势,基本所有子项都有不等的提升幅度。

Table 2. Comparison of the effects of different models on UrbanSound8K dataset
表2. 不同模型在UrbanSound8K数据集上的效果对比
如图7所示的混淆矩阵可以看出,SFAC模型可能在部分嘈杂或者干扰声场较多的子项上会出现识别偏差,尤其是在音乐街道、儿童嬉闹和犬吠此三项上出现了同比较大的混淆值。
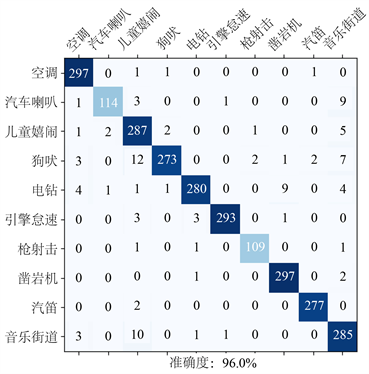
Figure 7. The confusion matrix of SFAC model (UrbanSound8K)
图7. SFAC模型混淆矩阵(UrbanSound8K)
5.3.2. TUT2020
如表3所示,可以看出TUT2020数据集中的多数据源采集以及整体更大的数据量的特点对神经网络的预测带来了更大的压力,基线系统的预测成绩相比其他规模较小的数据集(如UrbanSound8K)有了较大的下降,本文提出的网络总体上相对于表现最好的基线网络能有8%左右的准确率提升,从图8所示的混淆矩阵可见,SFAC网络在数据集中容易产生混淆的电车、巴士和地铁场景上也表现出了识别效果的稳定进步。
在这里,本文同步加入了更深的卷积网络VGG-A (8层卷积)和VGG-E (16层卷积)网络进行轻量化网络模型与更深网络模型的纵向对比,可以看出更深的VGG卷积网络在某一些子项上可以比本文提出的轻量化网络更有效,但是总体上并不一定比经过设计过后的轻量化网络的准确率更优。
Table 3. Comparison of the effects of different models on TUT2020 dataset
表3. 不同模型在TUT2020数据集上的效果对比
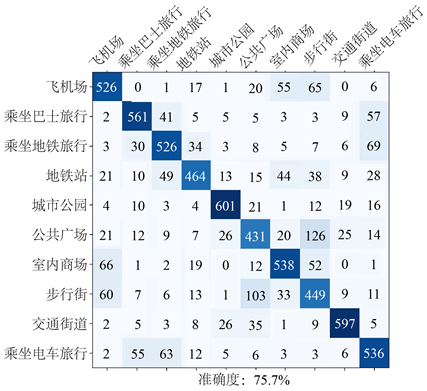
Figure 8. The confusion matrix of SFAC model (TUT2020)
图8. SFAC模型混淆矩阵(TUT2020)
5.3.3. 对比实验
为验证改进的注意力池化层与原始的注意力池化层和普通池化层的改进效果,本文在UrbanSound8K数据集上进行了对比实验,其结果如表4所示。
本文分别将时–频分离网络(SF Net)、CNN_P、CNN_NP固定为前端特征提取网络,后接入不同的池化层对比预测准确度。本文的前置网络在配合改进的双注意力的池化模块达到了最高的准确度。没有加入注意力池化只使用Flatten进行预测的SF Net的准确度相比其他金字塔网络出现了明显的下降,说明本文对频域方向改进的卷积方法确实会导致一定的预测性能下降。而在加入了注意力映射层以后,综合准确度得到了一定的提升,弥补了时频分离卷积导致的精度下降问题。本文改进的注意力池化层在三种不同前置网络下均表现出了对原始注意力池化的有效效果提升。在加入注意力池化层的同时,再加入通道注意力模块(SE Block)后,网络的预测准确度得到了进一步的提升。
Table 4. The performance of different pooling methods under different front networks
表4. 不同的池化方法在不同前置网络下的表现
5.3.4. 推理速度与参数量
本文在UrbanSound8K测试集上采用批次为1的形式,进行了14000次的完整推理并计算时间消耗,同时统计模型的总参数量和每秒浮点运算次数(FLOPs)指标,参数量越小表明模型占用的存储空间越小,FLOPs指标越小说明模型对运算量的需求越低,测试结果如表5所示。
Table 5. Comparison of the number of model parameters and inference speed
表5. 模型参数量和推理速度对比
可以看出,本文提出的两种模型在提升模型效果的前提下,在轻量化方面均有较大的提升,SFAC模型的存储量为VGG-4基线模型的3.5%,CNN_NP基线模型的5.4%,CNN_P基线模型的6.1%。模型在轻量化方面的改进效果十分明显。但是在推理速度方面,由于分组卷积对内存访问的需求较多,并且通道注意力机制在较大的通道数压缩时会增加计算量,在实际推理实验中推理耗时有所上升。
6. 结论
本文使用深度分离卷积和非对称卷积进行了轻量化网络的设计,研究并引入了两种用于轻量化卷积网络中的注意力机制,综合提取了特征图维度和特征图通道间非线性关联特性。同时,本文进行了映射方法的改良,使得模型内部使用不同维度的注意力方法与时频分离卷积结构相结合,弥补了轻量化设计导致的性能下降问题,最终提出了SFAC注意力轻量卷积网络。
实验表明,本文提出的轻量化模型在多个公开音频数据集上都表现出了稳定的准确度提升,同时可以压缩模型参数量,以降低实际部署中的存储空间开销,但是同时也存在注意力机制在通道数较多的卷积层进行运算导致的额外推理性能开销问题。