1. 引言
随着现代计算机技术的不断发展,计算机系统规模逐渐扩大,但同时,系统异常的概率也在上升。例如,当前的分布式系统规模庞大且运行逻辑复杂,容易导致系统出现异常。此外,系统上运行的各种软件服务也给系统运行带来挑战。随着软件服务的增加,系统故障的风险也随之上升。因此,需要相应的异常检测手段来确保系统的正常运行。
日志详细记录了系统运行状况和各种事件,因此基于日志的异常检测方法具有重要的实际意义,并成为众多学者和专家的研究方向 [1] 。早期的日志异常检测主要依赖人工分析。例如,在系统出现异常时,运维人员通过查看日志并搜索关键词,如“fail”和“error”,以找到可能与异常状态相关的信息。然而,随着系统规模的扩大,日志规模也相应增加,人工分析日志的成本和效率变得不尽如人意。因此,设计针对日志信息的异常检测算法具有重要实际价值。随着机器学习技术的发展,许多专家将其应用于日志异常检测领域,并提出了众多方法。这些方法利用机器学习的能力,以提高异常检测的效率和准确性,为系统运行提供更强大的保障。
Xu等人 [2] 首次将主成分分析(PCA)方法应用于日志异常检测领域。他们首先结合源代码分析和信息检索来解析日志,随后将每个日志序列转换为日志计数向量,并应用PCA进行异常检测。最后,结果以决策树形式可视化。Lou等人 [3] 通过应用不变量挖掘方法来寻找日志中的异常。程序不变量指的是在系统运行过程中始终存在的线性关系。通过不变量挖掘,可以表示系统运行时的正常执行线性关系。如果被检测的日志序列破坏了这种关系,则将该日志序列判断为异常。例如,用户的登录和登出是对应的,如果登录和登出表示的日志数量不相等,则说明出现了异常。文献 [4] 首次将决策树应用于WEB请求日志的故障检测,基于日志计数向量及其标签构建决策树,并通过遍历决策树来判断新实例的状态。Liang等人 [5] 使用支持向量机算法(SVM)进行故障检测,同样基于日志计数向量及其标签进行训练。
早期基于传统机器学习的日志异常检测方法主要利用日志计数向量进行异常检测,但此类检测方式具有局限性。一旦日志解析出错,将产生新的日志模板,从而影响模型检测。随着深度学习技术的发展,该领域取得了显著成果,因此许多学者将深度学习技术应用于日志异常检测领域。
Lu等人 [6] 将卷积神经网络(CNN)应用于大数据系统日志的异常检测。该方法首先通过日志解析将日志转换为日志键,接着利用日志键生成日志序列,然后将日志序列向量化,最后输入到CNN模型中进行异常检测。Du等人 [7] 基于LSTM网络提出了一种新的日志异常检测模型DeepLog,将系统日志视为自然语言建模。异常检测分为执行路径异常检测和参数异常检测。通过结合这两种不同的检测,以达到更好的检测效果。并采用在线方式增量地更新DeepLog模型,以便模型能够适应新的日志。Zhang等人 [8] 提出了一种基于双向长短时记忆网络(Bi-LSTM)的日志路径异常检测模型,可以有效进行日志路径异常检测。文献 [9] 提出了一种并行GRU模型,该方法利用日志解析生成的日志模板,进而得到相应的日志模板序列和对应的日志模板频度向量。然后将两者分别输入到两个GRU模型中,接着将两个GRU模型的输出进行拼接,最后通过softmax函数得到输出。
尽管现有的基于深度学习的日志异常检测方法取得了一定的成绩,但仍存在以下不足:大多数基于深度学习的日志异常检测方法采用日志解析来处理日志,但研究表明日志解析可能带来噪声影响,从而影响模型检测性能 [10] [11] [12] 。此外,日志格式的多样性进一步影响日志解析器对日志的解析。某些解析器可能在某个数据集上表现良好,但在其他数据集上表现较差。目前尚无通用的日志解析器能完美解决这些问题。另外,现有的日志序列异常检测方法大多基于日志模板索引编码进行日志序列化,这容易导致日志语义丢失,从而影响模型的检测性能。
针对以上不足,本文提出了一种基于GRU和TextCNN的日志序列异常检测方法。该方法基于日志语义信息,通过SBERT将日志转换为句向量,然后利用滑动窗口提取日志序列向量,最后利用本文提出的日志序列异常检测模型GTCLog对日志序列进行异常检测。GRU能够有效捕获序列中的依赖关系,而TextCNN能够对GRU捕获的依赖关系进行进一步的特征提取。GTCLog通过结合GRU和TextCNN的优势,从而能够有效地检测出日志序列异常。
2. 理论基础
2.1. 向量表示
尽管日志是非结构化文本,但从语义角度来看,可以将日志视为具有特殊意义的语句。通过将日志语句向量化,可以计算向量之间的距离来表示其相似性,从而加以区分。
在文本向量化技术中,有许多优秀的词嵌入模型,如Word2Vec [13] ,Glove [14] ,和ELMo [15] 等。尽管这些模型能够有效地将词表示为词向量,但对于句子向量化而言,仍存在一定的不足。简单地对词向量进行加权求和会导致上下文语义的缺失。为了更好地保留日志语义信息,本文采用SBERT [16] 模型来对日志进行句向量化处理。
SBERT模型是近年来较为优秀的句子嵌入模型。通过SBERT,可以快速地将句子转换成句向量,并且保留丰富的语义信息。SBERT基于BERT模型,并进行了一定修改:使用Siamese和triplet网络结构来获得具有语义的句子向量。模型结构如图1所示。
训练过程如下:句子A和句子B通过BERT模型之后,经过池化得到向量u和v。接着,将u、v和两者差的绝对值
进行拼接,并乘以一个可训练的权重W,输入softmax函数得到预测结果。计算公式如下:
(1)
2.2. GRU神经网络
GRU [18] 是LSTM的一种变种,相较于LSTM有三个门(遗忘门,输入门,输出门),GRU只有两个门(更新门,重置门)。此外,GRU与标准RNN相似,只有
,没有LSTM中的CELL状态。其结构如图2所示:
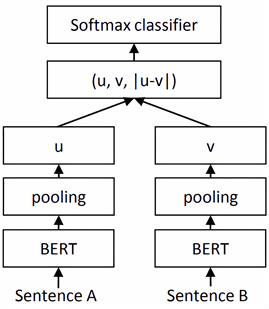
Figure 1. SBERT model structure diagram [17]
图1. SBERT模型结构图 [17]
图中
表示重置门,
表示更新门。重置门
决定
传入候选状态
的比例;
的值越小,则
的信息添加到候选状态
越少。更新门
决定前一状态的信息
和候选状态
在新状态
中的保留程度。其计算公式如下所示:
(2)
(3)
(4)
(5)
2.3. 文本卷积神经网络
除了在图像处理领域广泛应用,CNN同样在自然语言处理领域也取得了广泛的成功。TextCNN [19] (有研究称之为CNN-text)通过改变卷积方式,使得CNN模型可以有效处理文本数据。
由于模型不能直接接受文本数据,因此在模型训练之前,需要将文本数据转换为向量数据。文本由单词组成,因此通常首先将单词转换为词向量,然后基于词向量完成对文本的转换。转换完成后,便得到文本的词向量矩阵。这使得TextCNN可以像处理图像数据一样处理文本词向量矩阵。其网络结构如图3所示:

Figure 3. TextCNN model structure diagram [19]
图3. TextCNN模型结构图 [19]
在输入层,每条文本都通过词嵌入技术转换为一个二维词向量矩阵,该词向量矩阵可以视为具有相同大小的图像。在卷积层,TextCNN使用半定长卷积核提取特征,其长度通常设置为(2, 3, 4),宽度设置为词向量维度。例如,若词向量维度为d,则卷积核宽度也为d。这是因为一行词向量表示一个单词,若宽度未设定为词向量维度,词向量将被截断,从而丢失部分信息。在池化层,通过最大池化将特征压缩,然后拼接在一起。最后,通过全连接层和softmax函数得到输出。
3. 模型方法
3.1. 方法框架
本文所提出的基于GRU-TextCNN的日志序列异常检测方法,从实现角度来分,可以分为四个模块:预处理模块、日志语句向量化模块、日志序列提取模块与异常检测模块。整体框架如图4所示:
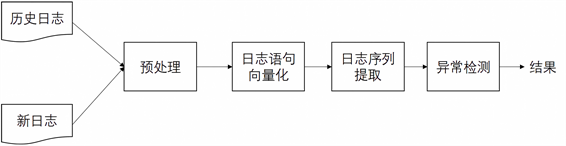
Figure 4. GTCLogmethodology framework diagram
图4. GTCLog方法框架图
3.2. 预处理
现有的日志序列异常检测方法主要采用日志解析器对日志进行预处理,通过日志解析器解析出日志模板,然后利用模板索引编码或模板语义进行日志序列异常检测。但这种预处理手段可能导致噪音产生,进而影响模型检测效果。本文提出的预处理方法将日志视为具有特殊语义的句子,并采用文本处理算法进行预处理,具体过程如算法1所示。
上述算法中,Lower函数的作用是将单词转换为小写。以日志:1117838570 2005.06.03 R02-M1-N0-C: J12-U112005-06-03-15.42.50.363779 RAS KERNEL INFO instruction cache parity error corrected为例。首先通过分词将日志处理成为一组单词集合LW。然后去除时间戳、日期等时间信息,将时间信息去除之后,接着去除空格、冒号、逗号等符号以及数字。然后将处理完成的单词集合LW,转换成字符串格式。处理完成之后,最终得到一行日志语句LS = {RAS KERNEL INFO instruction cache parity error corrected}。PLSS对应定义如下,其中LS为预处理完成的日志语句:
3.3. 日志语句向量化
尽管日志属于非结构化文本,但从语义角度来看,可以将日志视为具有特殊意义的语句。通过将日志语句向量化,可以计算向量之间的距离以表示其相似性,进而实现区分。
本文的实验基于SBERT模型将日志语句直接转换为句向量,具体过程如算法2所示。通过SBERT,每条日志语句LS都被处理成了一条日志语句向量LSV,将日志语句集合PLSS转换为日志语句向量集合LSVS。以下是LSVS的定义,其中LSV代表日志语句向量:
3.4. 日志序列提取
系统中的某个事件或状态可能需要多条日志来记录,由此产生了许多日志序列。日志序列也表明了其执行路径,因此基于日志序列的异常检测任务也被称为基于日志执行路径的异常检测任务。该任务的输入是日志向量序列。首先,通过预处理模块将原始日志集合处理成日志语句集合;接着,通过句子向量化技术将日志语句集合转换成日志语句向量集合。此时,日志语句向量集合是离散的,不包含任何执行序列。因此,需要通过日志序列提取模块提取日志序列。
现有的日志序列提取方式主要有两种:一种是根据会话提取,另一种是根据窗口提取。会话提取日志序列需要满足一定条件,即日志语句中需包含相关会话标识,例如HDFS数据中的blk信息。然后根据会话标识提取属于同一个会话的日志,从而提取出相应的会话序列。窗口提取序列根据窗口的选择又有多种形式,如固定窗口提取、滑动窗口提取等。固定窗口通过一个固定大小的窗口提取日志,例如设定固定窗口大小为5,则每次提取日志数量为5,且下一次提取是当前提取日志序列的后五条日志。滑动窗口与固定窗口类似,都是提前设置好一个固定大小的窗口。与固定窗口不同的是,滑动窗口每次的滑动步长也是通过人为设定。例如设置窗口大小为5,步长为1,有日志集合
。第一次提取的日志序列为{L1, L2, L3, L4, L5},第二次提取的日志序列为{L2, L3, L4, L5, L6},以此类推,每次滑动都只往下滑动一步。
由于本文实验所采用的数据集没有会话标识,且固定窗口的提取方式较为僵化,可能导致遗漏部分日志序列,因此本实验采用滑动窗口进行序列提取,提取方式如算法3所示:
通过滑动窗口,日志语句向量集合LSVS中的语句向量被提取出来,成为一个日志序列,然后放入日志语句序列集合LSSS中。LSSS的定义如下,其中LSS为日志语句序列:
3.5. 异常检测
为了更好地检测日志序列异常,本文提出了一种基于GRU-TextCNN的日志序列异常检测模型:GTCLog模型。日志序列为序列数据,包含一定的序列信息。实践中已证实,GRU模型能有效捕获序列中的信息,而TextCNN则能对文本特征进行有效处理。因此,本文方法通过结合两者优势,提出GTCLog模型,以实现对日志序列异常更精准的检测。模型结构如图5所示。GTCLog模型可分为四个部分:输入层、GRU层、TextCNN层和输出层。
在数据流入输入层之前,需将数据处理成相应格式。通过日志预处理模块、日志语句向量化模块和日志序列提取模块,日志集合转换成日志语句向量序列集合。输入层的输入维度为(N, l, d),其中N为样本数,l为日志序列长度等于滑动窗口大小,d为句向量维度。GRU层由GRU神经网络构成,利用GRU网络对输入的序列数据进行初步特征提取。在得到GRU层输出后,由TextCNN层进行更深入的特征挖掘。TextCNN通过设置多个不同大小的卷积核,以学习多种不同特征。卷积操作后,每个卷积核会得到一个特征向量。池化层将每个卷积核得到的特征向量进行最大池化,然后拼接起来作为池化层输出。最后,将经过TextCNN处理的特征通过全连接层进行特征映射,接着通过softmax函数得到最终概率。
4. 实验结果与分析
4.1. 实验设置
为了评估模型,实验取BGL [20] 数据集的全部数据和Thunderbird [20] 数据集前1100万条日志数据进行实验。BGL数据集来自于劳伦斯利弗莫尔国家实验室的BlueGene/L超级计算机,该数据集包含4747963条日志,其中348460条日志为异常日志。Thunderbird数据集来自位于阿尔伯克基桑迪亚国家实验室(SNL)的雷鸟超级计算机系统。BGL数据集和Thunderbird数据集均来自文献 [21] 开源的项目。
由于日志序列异常检测可以看作是一个二分类问题,因此实验采用精确率、召回率和F1值作为实验的评价指标,来评估本文模型的有效性。
1) 精确率(Precision):
(6)
2) 召回率(Recall):
(7)
3) F1值(F1-Score):
(8)
其中TP (True Positive)为模型正确检测到的异常日志序列数量。FP (假阳性)是被错误识别为异常的正常日志序列的数量。FN (False Negative)是错误地判定为正常的日志序列数量。
实验选用三个机器学习算法(朴素贝叶斯算法、决策树算法、随机森林算法)和一个深度学习算法Deeplog作为基准模型。
4.2. 异常检测效果对比实验
为了验证本文模型在日志序列检测任务上的有效性,实验分别基于BGL数据集和Thunderbird数据集与四种基准模型进行比较。实验结果分别如表1和表2所示。从两个实验的结果可见,不同的滑动窗口对模型的检测性能有影响。三种机器学习方法容易受到滑动窗口的影响,导致模型检测性能波动较大。然而,本文模型在不同滑动窗口下均能保持出色的检测性能,有效检测日志序列中的异常。接下来将对两个实验进行更深入地分析。

Table 1. Experimental results on the BGL dataset
表1. BGL数据集上的实验结果
Table 2. Experimental results on Thunderbird dataset
表2. Thunderbird数据集上的实验结果
将BGL数据集以8:2进行划分,前80%的数据当作训练集,后20%的数据当作测试集,滑动窗口大小分别取5,10,15,20,步长分别为滑动窗口大小的一半,步长值不为整数的,则向下取整,最终实验结果如表1所示。
从表1可见,模型的检测性能受到滑动窗口的影响。特别是三种机器学习方法,更容易受到滑动窗口的影响。例如,当滑动窗口为5时,NB算法精确率为0.81,但当滑动窗口大小为20时,其精确率下降到0.47。GTCLog具有良好的鲁棒性,即使滑动窗口大小改变,其检测性能仍保持在出色水平。与四个基线模型相比,本文模型在各指标上均取得了出色成绩。三种传统机器学习方法在BGL数据集上表现不理想,整体性能的F1值均未达到0.85以上。当滑动窗口为5时,GTCLog的各指标均优于四个基准模型,如图6所示。
实验结果在Thunderbird数据集上如表2所示。将Thunderbird数据集以7:3划分,前70%的数据作为训练集,后30%的数据作为测试集。滑动窗口大小分别取10,20,30,步长为滑动窗口大小的一半。从表2可见,GTCLog在Thunderbird数据集上表现出色,在三个滑动窗口的实验中,各指标均达到最优。特别是在滑动窗口大小为10的实验中,本文模型的精确率、召回率和F1值均达到了0.99,如图7所示。四个基线模型中,Deeplog表现最好,其精确率达到0.98,召回率达到0.99,F1值达到0.98。表中同样可见,三个机器学习方法更容易受到滑动窗口大小的影响。例如,DT算法的精确率波动较大,其值在三个滑动窗口下分别为0.49,0.73,0.33,而Deeplog和GTCLog能保持稳定的检测性能,指标值均能达到0.96以上。
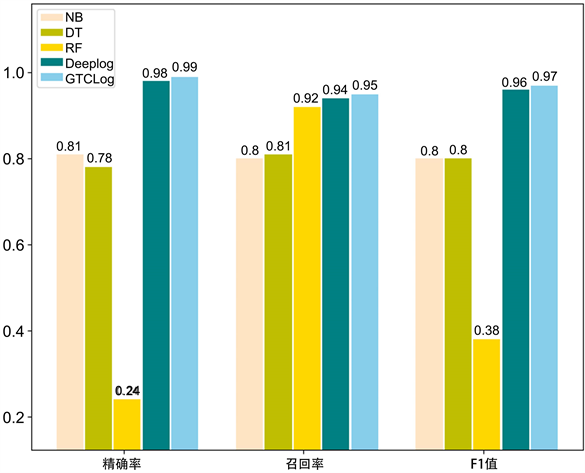
Figure 6. Experimental results for a sliding window of 5 on the BGL dataset
图6. BGL数据集上滑动窗口为5的实验结果

Figure 7. Experimental results for a sliding window of 10 on the Thunderbird dataset
图7. Thunderbird数据集上滑动窗口为10的实验结果
4.3. 消融实验
本文通过结合GRU和TextCNN提出了一种新的日志序列异常检测模型。为了验证其结合机制对模型检测性能的提升,本节通过消融实验进行实证研究。实验数据集选取BGL,同样以8:2进行划分,滑动窗口大小设为5,滑动步长设为2。实验分别选取TextCNN和GRU作为基准模型,且对应的参数与本文模型保持相同。实验结果如表3所示。
从表3可见,TextCNN在精确率方面优于GRU模型,达到了0.98。然而,在召回率方面,GRU模型优于TextCNN模型,GRU召回率达到了0.92,而TextCNN模型的召回率仅为0.86。本文模型综合了TextCNN模型和GRU模型的优势,使其性能得到提升。无论是精确率还是召回率,均实现了一定程度的提升。在BGL数据集上,准确率达到了0.99,召回率达到了0.93,F1值达到了0.96,各个指标均优于单一模型。
5. 结束语
本文首先介绍了日志序列异常检测存在的问题,然后针对这些问题提出了本文方法,并对其进行了详细阐述。本文方法将日志视为具有特殊语义的句子,通过句向量模型SBERT进行向量化,接着利用滑动窗口提取日志序列向量,最后基于本文模型GTCLog对日志序列向量进行异常检测。通过在两个公开数据集上评估本文模型,实验结果表明,本文提出的方法能够有效检测日志序列异常。
基金项目
本论文由温州市智能网络重点实验室开放课题资助。
NOTES
*通讯作者。