1. 引言
颗粒物的无组织排放源主要由自然和人为活动产生,它严重影响了空气质量和周围地区的人体健康 [1] 。与从可定义或固定点源有组织排放的颗粒物不同,无组织排放颗粒物在空间、时间和强度上都有着较强的不确定性,导致现场监测的工作量大、样品不具有代表性,操作难度高 [2] 等。目前,常用的颗粒物浓度测量方法主要有β射线吸收法、压电晶体差频法、微量振荡天平法、光散射法 [3] 等。其中,光散射法因其测量仪器结构简单、响应快而被广泛应用在大气气溶胶浓度的测量 [4] 中,但其在无组织排放颗粒物上应用较少。汪文涛 [5] 等提出了基于后向散射的无组织排放颗粒物浓度远程测量方法,为开放场地的无组织排放颗粒物浓度监测提供了一种新思路。这种方法是通过校准后向散射光强和颗粒物浓度之间的对应关系来实现的。由于在此浓度计算过程中,需要先已知颗粒物的粒径分布,所以对于颗粒粒径分布的测量十分关键。
近年来,很多反演算法在颗粒物粒径分布的研究上得到了广泛应用,可分为非独立模式和独立模式。独立模式又称自由分布法,各分档粒径下对应的体积频度并不服从某种规律,反演是求取各档粒径的频度的严格解,并无预先分布函数的假设,结果需给出各档粒径下体积或重量频度的具体值,常见的有Phillips-Twomey-NNLS算法 [6] 、Chahine迭代算法 [7] 、最小均方算法 [8] 等。非独立模式又称分布函数限定法,需先假定颗粒系的粒径分布服从某一函数,反演只需要求取函数的特征参数即可限定好颗粒系的粒径分布,如人工蜂群算法 [9] [10] 、人工鱼群算法 [11] 、遗传算法 [12] 等。
受上述研究的启发,本文假设无组织排放颗粒物粒径分布服从Rosin-Rammler分布 [13] ,根据多波长后向散射粒径测量原理提出基于BP神经网络和粒子群算法(PSO)反演非独立模式下的粒径分布的预测方法。首先建立两种算法模型,根据Mie散射理论生成仿真数据分别应用于两种预测模型验证了准确性并进行对比;然后通过聚苯乙烯浓度标定实验得到系统修正系数,将其用于实验提取的四波长激光的灰度值比值修正后进行预测模型的粒径分布测量。
2. 基本原理
2.1. 多波长后向散射粒径测量原理
如图1所示,被测颗粒系被不同波长激光束照亮时,会向四周散射不同强度的入射光。成像系统(包括镜头和相机)用于获取被照射颗粒的图像,相机接收颗粒系的某个立体角的光能量并经过镜头的汇聚在图像传感器上显现清晰明亮的光斑,图像传感器平面与激光束垂直,从激光束到图像传感器的距离用L表示。
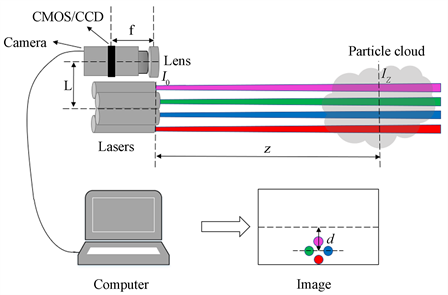
Figure 1. Multi-wavelength backscatter schematic diagram
图1. 多波长后向散射原理图
根据入射光强度
、颗粒的粒径分布和颗粒系相对于周围介质的折射率,图像灰度值G和颗粒物浓度C之间的关系可以用下式表达 [5] :
(1)
式中:
为散射光观察点与颗粒系的距离;
为相机的曝光时间;
为测量区域的厚度;
为单位曝光时间内相机的光强响应系数;
是一个仪器常数,可以通过实验标定获得;
是与颗粒系粒径分布有关的散射光强系数。
对于Rosin-Rammler分布,一般需要求解体积频率分布函数中的尺寸参数
和分布参数k两个未知数。本文采用四种波长的激光对同一颗粒系进行测量,即采取B (450 nm),G (532 nm),R (658 nm)和IR (780 nm)四种波长的激光入射在同一颗粒系,由于波长不同,在其他条件相同的情况下,后向散射的光强不同 [14] 。根据公式(1),可以得到四种波长下后向散射图像灰度值与颗粒物浓度的关系式:
(2)
根据公式(1)可知,颗粒物的后向散射图像的灰度值与测量距离、相机曝光时间以及颗粒物浓度等均有关系,为了消除因这些变量所带来的误差,可以利用不同波长下后向散射光强的比值进行颗粒粒径分布的反演计算 [14] ,即可得到关系式:
(3)
由于实验中测量得到的灰度值G与模拟的散射光强E之间的差别主要在于不同波长激光的入射光强
以及相机对不同波长的散射光的响应系数
,因此只要通过实验标定得到
的相对值,即可以对模拟得到的散射光强进行修正。
利用该标定结果,对于采集得到未知颗粒粒径分布的图像中的散射光斑的灰度值G就可以反算得到
中的未知颗粒粒径分布。
2.2. BP神经网络模型
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络 [15] ,其算法称为BP算法,它的基本思想是梯度下降法,利用梯度搜索技术,使网络的实际输出值和期望输出值的误差和均方差为最小。
本文主要简单介绍三层的BP网络,即输入层,隐含层和输出层,其中输入层和输出层节点数按实际情况选取,而隐含层节点数根据以下经验公式 [16] 计算:
(4)
上式中l为神经网络中隐含层节点数;m为输入层节点数。同时选用双曲正切S型函数tansig作为输入层到隐含层的激活函数,隐含层到输出层之间的激活函数为线性传递函数purelin [17] 。BP神经网络的核心训练算法采用L-M (Levenberg-Marquardt)算法,该算法是高斯牛顿算法和梯度下降法的结合,具有鲁棒性好,收敛速度快的优点 [18] ,适用于中等规模的前馈型网络模型。
BP神经网络算法的基本步骤如下:
1) 首先初始化权值和阈值,在训练神经网络时会自动将其设置成较小的随机数;
2) 输入数据库的训练样本,包括输入向量和输出向量;
3) 分别计算隐含层以及输出层的输出值的误差;
4) 根据误差对权值和阈值进行调整;
5) 计算网络的误差均方和;
6) 不断循环第二步到第五步,直到误差均方和满足设置的精度要求。
2.3. 粒子群算法模型
在研究了人工神经网络理论之后,针对BP神经网络存在容易早熟收敛、局部最优等缺点,结合神经网络自身特性设计出一种新型智能算法——粒子群算法(PSO)。该方法已应用于各个领域。与BP神经网络相比PSO有着精度高的独特优点,且全局探索能力较强、鲁棒性能好,但也存在收敛速度慢等不足 [19] 。
PSO的每个优化问题的解都是搜索空间中的一只鸟,称之为“粒子”,粒子通过更新自身的速度和位置来实现寻优 [20] 。每个粒子在飞行过程经历的最好位置,就是粒子本身找到的最优解,叫做个体极值
。而整个群体所经历过的最好位置,就是整个群体所有粒子发现的最优解,叫做全局极值
。实际过程中每个粒子都有一个由优化目标函数所决定的适应度值(fitness value)。每个粒子的位置可表示为
,N表示种群粒子的总个数),它所经历过的最好位置记为
,它的速度用
表示。每个粒子就是根据以下公式 [21] 不断更新自己的速度和位置,从而产生新一代群体:
(5)
(6)
其中
、
为常数,称为权重因子,通常
;rand是[0, 1]之间的随机数,w为惯性权重函数。公式分为三个部分,第一部分是记忆项,表明粒子先前的速度;第二部分是自身认知项,表明粒子的动作,是粒子从当前点指向粒子本身最好点的一个矢量;第三部分为群体认知项,是粒子从当前点指向种群最好点的矢量,体现了粒子间的知识共享。
粒子群算法的基本步骤如下:
1) 初始化每个粒子的速度和位置,设置最大速度、种群规模和迭代次数;
2) 根据目标函数,计算每个粒子的适应度值;
3) 对每个粒子,将当前位置的适应度值与个体极值
对应的适应度值比较,如果当前位置的适应度值更高,则用当前位置更新历史最佳位置;
4) 对每个粒子,将当前位置的适应度值与全局极值
对应的适应度值比较,如果当前位置的适应度值更高,则用当前位置更新全局最佳位置;
5) 根据公式(5)和(6)分别更新每个粒子的速度与位置;
6) 当满足迭代次数后算法结束,全局最佳位置
即全局最优解。
3. 实验结果与讨论
3.1. 相关系数的标定
根据多波长粒径分布测量原理,在进行粒径反演之前,为了保证仿真值和实测值之间的一致性,需要对实验测量系统内部的参数
和
进行标定。
本文采用体积平均粒径为10 μm的聚苯乙烯颗粒作为标定颗粒,在透明的玻璃容器中加入一定量的纯净水,配置质量浓度50~300 mg∙m−3的样品溶液。使用便携式无组织排放测量装置 [5] 对透明玻璃容器中的聚苯乙烯颗粒物进行测量,为减少环境中杂散光的干扰,实验在黑暗的环境下进行,如图2所示。在实验中,固定装置中相机镜头到玻璃水槽的距离为1 m,玻璃水槽的长宽均为0.2 m,即为测量区域的厚度。调整焦距和对焦面,使测量区域清晰的成像在相机的靶面上。同时调整相机曝光时间,确保图像的灰度值未饱和,设置相机曝光时间
为20 ms,帧率为15帧/s,对每一种质量浓度溶液拍摄60张散射图像,采集图片时间为4 s。
经过图像处理得到四种波长下颗粒物的质量浓度与散射光强灰度值之间的关系曲线,如图3所示。
采用最小二乘法对数据进行拟合得到线性关系式,得到四个波长下的拟合系数分别为
,
,
,
。根据质量浓度测量原理可得:
(7)
由于已知标定颗粒的平均粒径为10 μm,根据公式分别计算出
,
,
,
,根据公式(3),可以得到四种波长下相机的响应系数
以及入射光强
间的比值:
(8)
在实际测量中,相机的响应系数
以及入射光强
与颗粒的粒径无关,因此可以作为定值。

Figure 2. Multi-wavelength backscatter imaging experimental measurement system
图2. 多波长后向散射成像法实验测量系统

Figure 3. Fitting curve between particle concentration and image gray level
图3. 颗粒物浓度与图像灰度拟合曲线
3.2. BP神经网络模型的训练与预测
基于BP神经网络的基本原理,对服从Rosin-Rammler分布的粒径分布函数的尺寸参数
和分布参数k进行模拟,本文确定输入层节点数为3,输出层节点数为2,因此可以确定隐含层节点个数为7。根据常规无组织排放颗粒物的粒径分布 [13] ,分别模拟粒径分布参数中尺寸参数
范围为1.0~40.0,分布参数k的范围为6~15,其中粒径分布函数的上下限分别为50 μm和1 μm随机产生了不同的粒径分布参数下四种波长的颗粒的后向散射光强比值,其中训练集占90%,测试集占10%。经过BP神经网络的训练,得到输入测试集对应的输出数据。
同时,利用模拟数据随机得到的双参数粒径分布的测试集为模拟值,将两者进行对比分析。分别进行十次和百次重复性仿真后取平均,对比结果如图所示。从图4可知,十次预测后粒径分布函数中的尺寸参数
的最大相对误差为107.31%,平均相对误差为16.98%;分布参数k的最大相对误差为42.89%,平均相对误差为16.26%。百次预测的尺寸参数
最大相对误差为55.62%,平均相对误差为14.26%;分布参数k的最大相对误差为85.11%,平均相对误差为16.83%。可见经过BP神经网络预测的结果与设定的模拟值大部分较为接近,但有时会出现收敛度不高,精度较低,个别误差很大,造成整体平均误差偏大。同时可见十次和百次预测的结果的平均误差比较接近,因此取十次预测平均结果即可。
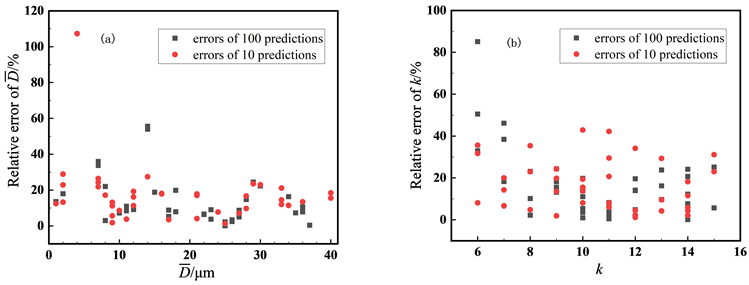
Figure 4. Comparison of the relative errors of the particle size distribution of ten times and a hundred times. (a) Dimension parameter
; (b) distributed parameter k
图4. 十次百次粒径分布相对误差对比。(a) 尺寸参数
;(b) 分布参数k
3.3. 粒子群算法的训练与预测
由粒径分布测量原理可知通过实测四种波长灰度值G的比值求解方程组(3)就可求得被测粒子的粒径分布。本文对其求解使用粒子群算法反演非独立模式下的粒径分布。
对于Rosin-Rammler分布,反演计算的适应度函数定义为:
(9)
式中,下标mea表示为测量值;cal表示每次迭代的反演值;
,M表示入射激光的波长个数,本文为4波长。算法反演的粒径分布函数的主要参数取值如表1所示。

Table 1. Particle swarm optimization parameter settings
表1. 粒子群算法参数设置
为验证粒子群算法的准确性,分别采用粒径分布为R (1, 10) (代表R-R分布,
= 1 μm和k = 10)、R (3, 6)、R (6, 12)、R (10, 8)、R (16, 14)、R (22, 9)、R (26, 7)、R (31, 13)、R (35, 11)和R (40, 15)的聚苯乙烯颗粒进行仿真分析,符合上文BP神经网络仿真的
在1~40 μm,k在6~15范围内。当经过10次迭代后,目标函数数值基本达到稳定值,表明结果达到了最优化,且进行十次重复性仿真结果基本一致。将此结果与BP神经网络十次均值结果对比,结果如表2:
Table 2. Simulation results of particle size distribution parameters
表2. 粒径分布参数模拟结果
图5显示了PSO算法和BP神经网络的粒径仿真结果和误差图。从图可知,BP神经网络预测的尺寸参数
的最大相对误差为52.54%,平均相对误差为12.41%;分布参数k的最大相对误差为10.70%,平均相对误差为5.99%。而PSO算法预测的尺寸参数
的最大相对误差为7.15%,平均相对误差为1.95%;分布参数k的最大相对误差为6.55%,平均相对误差为3.22%,明显优于BP神经网络预测的结果。但在预测耗时方面,PSO算法十次预测总耗时95 s,远大于BP神经网络十次预测总耗时6 s。此结论符合两种算法的特点,也表明了基于BP神经网络和PSO算法对颗粒粒径分布进行预测的方法是可行的。
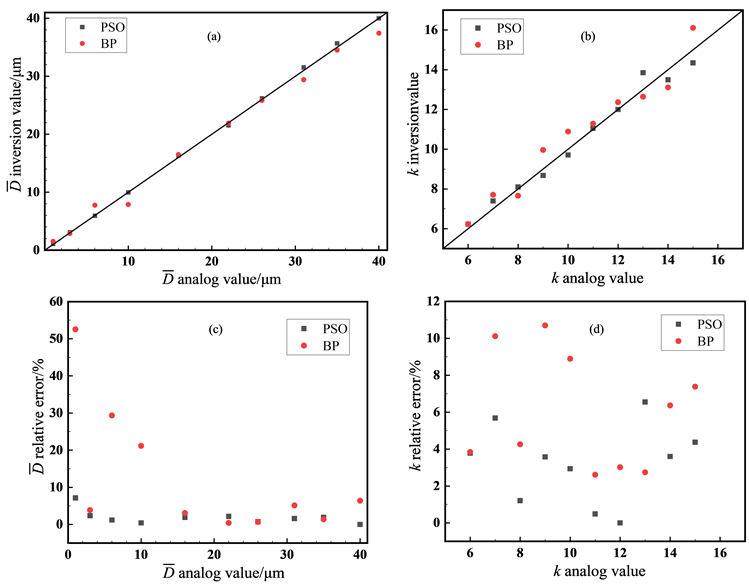
Figure 5. Comparison of simulation results of particle size distribution parameters. (a) Inversion results of distribution parameter
; (b) Inversion results of distribution parameter k ; (c) Relative error of dimension parameter
; (d) Relative error of distribution parameter k
图5. 粒径分布参数仿真结果对比。(a) 尺寸参数
反演结果;(b) 分布参数k反演结果;(c) 尺寸参数
相对误差;(d) 分布参数k相对误差
3.4. 粒径分布实验测量
前面通过仿真验证了基于BP神经网络和粒子群算法对颗粒粒径分布测量方法的可行性。为探究两种模型对实际颗粒粒径测量计算的效果,进一步验证该粒径测量方法的准确性,本节采用体积平均粒径为10 μm的窄分布的聚苯乙烯标准颗粒均匀悬浮于水中进行测量实验。利用便携式无组织排放测量装置对透明玻璃容器中的悬浮颗粒进行测量,采集得到聚苯乙烯后向散射光斑的图像。通过图像处理得到不同浓度的后向散射光斑中四种波长下灰度值的比值,分别利用BP神经网络模型和粒子群算法模型进行反演,得到不同浓度下粒径分布参数预测结果如图6所示。
从图6的结果来看,平均粒径为10 μm的颗粒通过PSO算法反演出来的尺寸参数
的值始终在10.0左右,分布参数k的值在8.1上下波动。而BP神经网络预测出来的粒径分布函数中的尺寸参数
的值在10.3上下波动,分布参数k的值始在8.8上下波动,但波动幅度都不大,总体趋势在误差允许的范围内。总体来看PSO算法的反演结果明显好于BP神经网络的预测结果,而在预测耗时方面,PSO算法十次预测总耗时59 s,BP神经网络十次预测总耗时4 s,BP神经网络优于PSO算法。
Figure 6. Comparison of measured results of particle size distribution parameters. (a) Inversion results of distribution parameter
; (b) Inversion results of distribution parameter k
图6. 粒径分布参数实测结果对比。(a) 尺寸参数
反演结果;(b) 分布参数k反演结果
4. 结论
本文根据多波长后向散射粒径测量原理,将BP神经网络和粒子群算法(PSO)模型分别用于颗粒物粒径测量。
首先根据Mie散射理论生成四种波长不同粒径分布下的后向散射光强比值,用仿真数据分别验证了两种预测模型的准确性并进行对比预测结果显示PSO预测的相对误差分布在±2%,±4%以内,明显优于BP神经网络预测的±13%和±6%,但在预测耗时方面,PSO算法十次预测总耗时95 s,远不如BP神经网络十次预测总耗时6 s。进一步通过10 μm的聚苯乙烯颗粒在水悬浮液中的标定实验提取了四波长激光的灰度值比值,通过测量系统相关系数
修正以后用于两种预测模型粒径预测,PSO的反演结果仍明显好于BP神经网络的预测结果,而在预测耗时上,PSO十次预测总耗时59 s,BP神经网络十次预测总耗时4 s,BP神经网络优于PSO算法。
上述研究表明,BP神经网络和PSO均能应用于粒径反演。其中BP神经网络预测耗时较短,但容易出现收敛精度不高等问题,有时不能得到较为准确的预测结果,由于多波长后向散射光强可能会引入不同波长下的误差,误差的叠加使得算法预测的准确性降低,从而使得反演结果的多值性也比较严重,造成整体平均误差变大。而PSO预测精度较高,但耗时稍长,前几次反演偶尔会陷入全局最优值和局部最优解问题,但只要反演参数设置合理(如调节惯性权重等),还是可以得到比较准确的结果,反演结果均符合两种算法的特点。