1. 引言
伴随着中国经济和金融行业的快速发展,互联网技术被广泛应用到金融领域中,互联网金融成为了金融业的重要组成部分,信贷就是一项重要的创新成果。由于其灵活、便捷的融资方式,信贷 [1] 成为了越来越多人选择的融资渠道,但同时信用风险问题也一直制约着信贷平台的发展,较高的违约率带来了极大的负面影响。因此做好贷款违约预测有助于银行相关业务的顺利展开,通过数据挖掘技术对数据库中的全体借贷人以及信贷申请人的相关信息数据进行挖掘分析和分类,能够预测申请人是否会违约,从而决定是否放贷。
近年来,许多基于机器学习的方法被广泛应用于信用风险预测模型中,其中包括逻辑回归 [2] 、神经网络 [3] 和支持向量机 [4] [5] 等方法。国内外众多学者对这些方法的可行性进行了验证,但是在研究信用风险评估模型的实际问题中,因为逾期用户数量相对于正常还款用户的数量很少而造成了正负样本比例极不平衡。利用不平衡的数据集进行模型训练,将严重影响模型的分类性能,得到较差的预测效果。对于解决不平衡数据集的分类问题,一般有数据不平衡处理方法和分类器两方面内容。
1.1. 数据不平衡处理方法
比较常见的处理数据集不平衡的方法有欠采样和过采样方法 [6] [7] ,通过随机移除多数类样本或者复制少数类样本达到平衡类别分布的目的。陈启伟 [8] 等利用欠采样方法平衡数据集并与引入参数扰动的集成学习方法相结合建立信用评分模型。但是该方法对于正负样本比例失衡比较严重的数据集来说,分类效果仍有待提高。Niu [9] 等利用SMOTE方法处理不平衡数据集,验证了该方法在信用风险评估模型中的有效性。但是SMOTE方法在生成新样本的过程中没有对少数类样本进行区别选择,并且容易出现样本重叠的问题。对此Han [10] 等提出了边界合成少数类过采样Borderline-SMOTE算法,改善了样本重叠的问题,但该方法只对处于边界的少数类样本进行过采样,容易造成正负类边界模糊的问题。
1.2. 分类器
传统分类算法包括朴素贝叶斯算法 [11] 、支持向量机算法和决策树算法 [12] 等。朴素贝叶斯算法是基于条件独立性假设的一种算法,当条件独立性假设成立时,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。支持向量机算法是建立在统计学习理论基础上的机器学习方法,SVM可以自动寻找出对分类有较好区分能力的支持向量,由此构造出的分类器可以最大化类与类的间隔,因而有较好的适应能力和较高的分准率。决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。
但由于传统分类算法在解决不平衡数据的分类问题时存在局限性,为此可以在传统分类算法上做出改进,主要方法有代价敏感学习 [13] 和集成学习方法 [8] [14] [15] 。代价敏感学习通过优化目标函数使分类模型更关注少数类样本的分类准确率解,从而增加少数类样本错分的惩罚代价来解决数据不平衡的问题。集成学习算法是一种组合算法,它通过组合多个基分类器输出最终分类效果较好的强分类器。经典的集成学习算法包括Boosting算法 [12] ,随机森林算法 [16] 和Bagging算法 [17] [18] 。Bagging中典型的一种算法是AdaBoost算法 [14] [19] [20] [21] ,该算法以每一次迭代训练出的基分类器为基础,对错分样本加大权重,之后再进行迭代训练。在不平衡的数据集中,少数类样本相对而言被错分的代价较大,可以在很大程度上增强少数类样本的影响程度而有效的提高少数类样本的分类效果,从而训练出更加偏向于少数类分类正确率的模型。
根据上述分析,本文提出一种基于SMOTE (Synthetic Minority Oversampling Technique)的改进算法SMOTE-Tomek算法和AdaBoost分类算法相结合的信用风险预测模型来改善数据不平衡问题对分类效果的影响。该模型从数据不平衡处理方法和分类器两个方面进行改进,来解决信用风险预测中数据不平衡的问题。对于数据不平衡处理方法,利用改进的过采样方法生成新样本来平衡数据集;在分类器方面,利用AdaBoost分类算法训练新的数据集得到最终的预测模型。
2. 不平衡数据处理方法
2.1. SMOTE算法
SMOTE的全称是“合成少数类过采样技术”,非直接对少数类进行重采样,而是设计算法来人工合成一些新的少数样本。通过创造合成的少数类样本来实现对少数类的过采样的方法是对随机过采样技术的改进,可以在一定程度上避免随机过采样模型过度拟合的问题。但是SMOTE算法在生成新的少数类样本时,只是单一地在同类近邻样本间插值,并没有考虑到少数类样本附近的多数类样本分布情况。若新生成的少数类样本周围有多数类样本,则很容易发生重叠的现象,使样本分类时发生错误。
2.2. SMOTE-Tomek
SMOTE-Tomek算法使用SMOTE对样本中少数类样本进行上采样,然后使用Tomek Links方法对多数类样本进行下采样。SMOTE-Tomek方法可以一定程度上缓解SMOTE方法容易产生样本重叠的问题,Tomek Links流程如下:
1) 将不平衡数据集分为多类样本数据集
和少数类样本数据集
。
2) 对多类样本数据集
中的每一个多类样本求其最近的少数类样本,对少数类样本数据集
中的每一个少数类样本求其最近的多数类样本。
3) 比较其最近距离,并判断样本是否相同,若相同则为Tomek Links对。
4) 将Tomek Links对中的多数类删除,从而得到新的数据集,然后选择分类算法对其学习。
3. AdaBoost分类器
AdaBoost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(基分类器),然后把这些基分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。AdaBoost能对不平衡数据集获得更好的通用性能,AdaBoost的提升机制更专注于被误分的少样本,以提高少类样本的分类精度。
关于AdaBoost的基分类器,目前有多种选择,如以径向基核支持向量机(RBFSVM)和决策树为基分类器。本文使用决策树模型作为基分类器,以决策树为基函数的提升方法称为提升树,在分类问题中此决策树为二分类决策树。
以决策树为基分类器的AdaBoost算法流程如下:
1) 初始化训练数据(每个样本)的权值分布。每一个训练样本,初始化时赋予同样的权值
,N为样本总数。
表示第一次迭代每个样本的权值。
表示第1次迭代时的第一个样本的权值。
2) 进行多次迭代,
,m表示迭代次数。
a) 模型采用前向分布算法,首先确定初始提升树
。
b) 使用具有权值分布
的训练样本集进行学习,得到基分类器:
,该式子表示第m次迭代时的基分类器,将样本x要么分类成−1,要么分类成1。其中
表示决策树,
表示决策树参数,M为树的个数。
c) 计算基分类器
的训练误差。
d) 计算基分类器
的话语权,话语权
表示
在最终分类器中的重要程度。
该式是随
减小而增大,即误差率小的分类器,在最终分类器的重要程度大。
e) 通过经验风险极小化确定下一颗决策树参数
:
f) 更新训练样本集的权值分布用于下一轮迭代,其中被误分的样本的权值会增大,被正确分的权值减小。
是用于下次迭代时样本的权值,
是下一次迭代时第i个样本的权值。其中
代表第i个样本对应的类别(1或−1),
表示基分类器对样本
的分类(1或−1)。若分类正确,
的值为1,反之为−1。其中
是归一化因子,使得所有样本对应的权值之和为1。
3) 迭代完成后,组合基分类器,形成强分类器。
4. 模型性能评估指标
为了正确评估是否有效分类样本,引入模型性能评估指标。本文所构建的为二分类模型,采用的评估指标有混淆矩阵、精确度、召回率、F1-score以及ROC曲线和AUC值。
4.1. 混淆矩阵
在本文二分类的情况下,表1混淆矩阵中定义了四个类别:真阴性(TN)代表借款人实际未违约,预测结果也未违约;伪阳性(FP)代表借款人实际未违约,预测却违约了;真阳性(TP)代表借款人实际违约,预测结果也违约;伪阴性(FN)代表借款人实际违约,但预测结果却为未违约。
4.2. 精确度、召回率、F1-Score
精确度是指真阳性(TP)的数量在模型所预测的观测值为阳性的样本中(TP + FP)所占的比例。公式定义为:
混淆矩阵中的借款人违约的人数中所占的比例。公式定义为:
F-measure也称为F-score,是召回率R和精度P的加权调和平均值,是为调和召回率的增减和精度之间的矛盾。该综合评价指标F引入一个系数α,进行召回率和精度的加权调和,其表达式如下:
最常用的F1指标是上述式中的系数α为1的情况,即:
F1的最大值为1,最小值为0。
4.3. ROC曲线及AUC值
ROC曲线全称为受试者工作特征曲线(Receiver Operating Characteristic Curve),它是根据一系列不同的二分类方式(分界值或决定阈),它是以假正率FPR为横坐标,真正率TPR为纵坐标而得出的ROC曲线图。
AUC就是ROC曲线下面积,在比较不同的分类模型时,可以将每个模型的ROC曲线都画出来,比较曲线下面积做为模型优劣的指标。
5. 数据介绍与模型建立
5.1. 数据介绍
银行等金融机出于客户隐私和信息安全等方面的考虑,公开提供的贷款违约或信用评分有关的数据集非常少,较大规模的数据集就更少了。本文使用的贷款违约数据集来自Kaggle网站发布的2007~2010年贷款违约竞赛数据,竞赛组织者要求参赛者对借款人是否全额偿还贷款进行分类和预测。
因此本文仅使用Kaggle网站提供的训练集中9578个样本作为本文的数据集(以下简称Kaggle数据集),用于训练本文所提及算法模型并测试该模型的预测性能。Kaggle数据集包括了借款人的借款目的、贷款利率、自我报告年收入、借款人FICO信用评分数等12个变量,表2列出了变量名及各变量描述:

Table 2. The Kaggle dataset variable case
表2. Kaggle数据集变量情况
根据对上表中变量的可视化分析可知以下几个规律:
一是信用评分特别低和特别高的人占比都较少,大多数信用评分中等,大体呈现为右偏态的正态分布,并且信用评分分值越高,违约率越低,如图1。这是信用评分的核心价值所在,可以根据信用评分的高低进行诸如是否发放、贷款额度、是否需要抵押等重要决策。
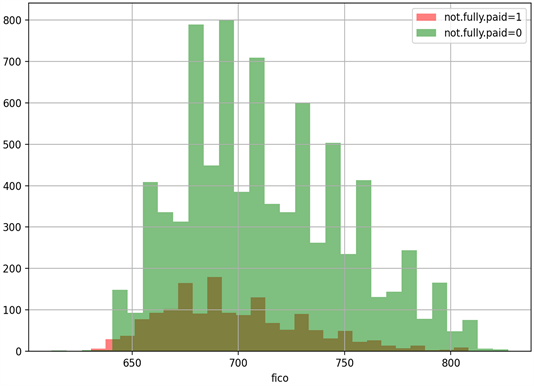
Figure 1. Histograms of loan repayment in full under different FICO scores
图1. 不同FICO分数下是否全额偿还贷款分布直方图
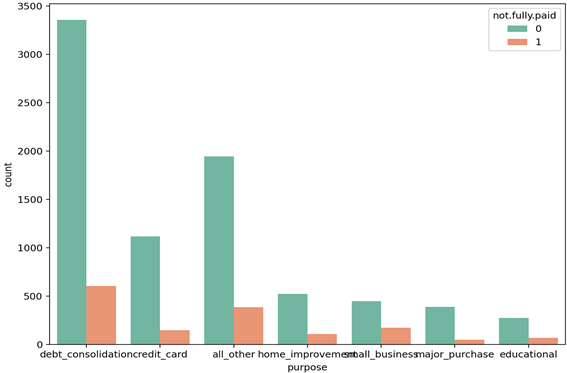
Figure 2. The histogram of the distribution of whether or not to repay loans in full for different purposes
图2. 不同贷款目的时是否全额偿还贷款分布直方图
二是用户未能全额偿还贷款的原因有众多,其中债务合并贷款在众多贷款目的中占主要因素,如图2。债务合并贷款(Debt Consolidation Loans)是为那些被众多债务纠缠而找不到解决办法的人准备的,它可以将债务人多项债捆绑起来负,组合为一笔新贷款统一偿还。
三是根据图3所示,not.fully.pay和credit.policy的趋势基本一致,无论是否能够全额偿还贷款,客户不符合LendingClub.com信用承保标准的贷款利率基本高于符合LendingClub.com信用承保标准的客户贷款利率,且不符合信用承保标准客户的FICO得分低于符合标准的客户的得分。
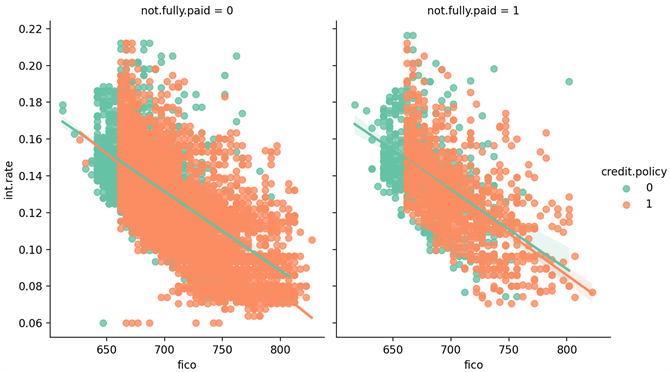
Figure 3. Trend charts not.fully.pay and credit. Policy
图3. not.fully.pay和credit.policy的趋势图
5.2. 模型建立
本文建立模型首先对数据进行预处理,建立训练集与测试集,然后通过SMOTE及其改进方法平衡原训练集,再利用改进的AdaBoost分类算法在新的训练集上根据筛选得到的变量特征进行训练。建模流程如图4所示,具体实现过程如下:
1) 本文首先对数据进行预处理,查看数据集中是否存在异常值与缺失值,并对“purpose”这一变量进行One-hot编码,将此变量变成稀疏变量,不仅仅解决了分类器对属性数据不好处理的问题,也在一定程度上起到了扩充特征的作用。将稀疏之后的“purpose”变量和“int.rate”“installment”“log.annual.inc”“dti”“fico”等变量作为特征变量。
2) 对数据进行训练集与测试集的划分,并对选择的特征变量中数据进行标准化与归一化。
3) 对处理过后的训练集进行SMOTE及其改进方法采样,生成新的平衡训练集。
4) 利用AdaBoost分类算法在新的训练集上根据选择的特征进行训练,最终建立分类模型,其中AdaBoost算法中的基分类器限制为二分类决策树。
5) 用测试集数据进行测试,验证模型分类效果。
6. 结果分析
本部分主要分析SMOTE改进算法与AdaBoost算法相结合模型的分类性能。使用上述数据,将SMOTE改进算法与支持向量机分类器、决策树分类器以及朴素贝叶斯分类器和以决策树为基分类器的AdaBoost分类器分别相结合,并对性能评估指标进行对比,结果如表3所示。
Table 3. Evaluation mechanism and performance comparison
表3. 评估机制与性能比较
由图5可知,以决策树为基分类器的AdaBoost分类器相比于支持向量机分类器、决策树分类器和朴素贝叶斯分类器的分类效果更好,并且由图6可知在模型参数一致的前提下,AdaBoost与SMOTE-Tomek数据处理方法相结合的模型分类效果优于与数据处理方法相结合的模型分类效果。因此对于上述实例数据,本文采用AdaBoost分类器与SMOTE-Tomek数据处理方法来进行分类判断。
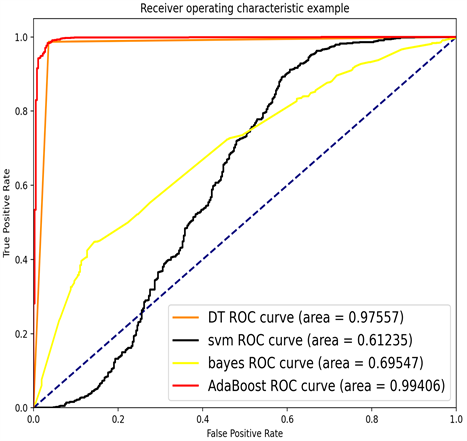
Figure 5. Roc curves of different classifiers
图5. 不同分类器的ROC曲线图
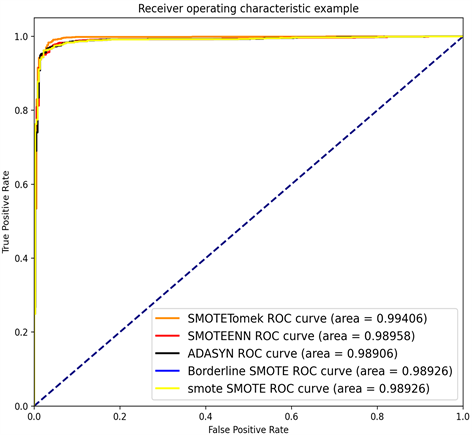
Figure 6. Different sampling methods combined ROC curves
图6. 不同数据处理方法与AdaBoost结合ROC曲线图
对于以决策树为基分类器的AdaBoost模型中,基分类器的个数(即基分类器的最大迭代次数)对于模型的最终分类效果有重要影响,如果迭代次数太大,容易过拟合;迭代次数太小,容易欠拟合。根据对模型中迭代次数的参数调整,在本文中当基分类器的迭代次数达到400时,分类效果最好,而当次数达到500时会出现过拟合的情况,如图7。
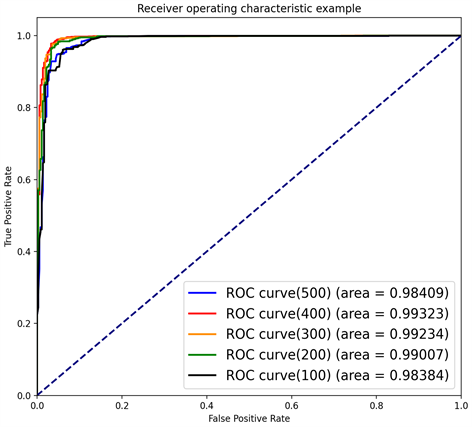
Figure 7. The base classifier has different iterations
图7. 基分类器不同迭代次数
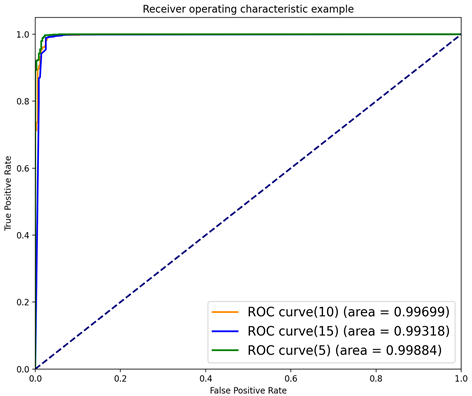
Figure 8. Different decision tree depths
图8. 不同决策树深度
为了探索决策树的大小和模型分类效果之间的影响和联系,方便起见,调用sklearn中的决策树分类工具包,设置决策树最大深度这一参数(max_depth)分别为5,10,15进行实验,其他参数相同。由图8可知决策树最大深度为5时,其AUC值可达0.99884,此时模型结果达到最优,随着决策树增大而效果变差,可能是出现了对训练集过拟合的情况。
7. 结论
信用风险问题一直制约着信贷平台的发展,一个有效的信用风险预测模型是研究的重点。在实际的研究中数据集不平衡问题严重影响着模型分类效果,为此本文从不平衡数据处理方法和分类器算法两个方面提出改进方法。在不平衡数据处理方面,通过SMOTE过采样及其改进方法平衡数据集;在分类器方面,利用决策树为基分类器,提出AdaBoost分类算法。通过与其他方法的对比实验,证实了SMOTE-Tomek与AdaBoost相结合的分类模型在信用风险预测中具有更好的预测效果。但是本文提出的模型仍然需要进一步改进,在未来可尝试寻找其他不平衡数据处理方法和分类器的结合,期望进一步提高分类效果。
基金项目
中国石油大学(北京)油气资源与探测国家实验室课题资助(PRP/DX-2208)。