1. 引言
2D人体姿态估计主要关注人体关节在二维平面上的位置和连线关系,而3D人体姿态估计则是在三维空间中确定人体关节的位置和姿态。目前2D人体姿态估计相关研究已趋向成熟,其自底而上的多人姿态实时检测在精确性、实时性和鲁棒性上都达到非常高的水准。相比之下3D人体姿态估计面临着更多的挑战,因为单帧图像仅仅是三维物体的二维投影,自身缺乏深度信息。相关研究 [1] 总结提出了2D姿态预测3D姿态任务存在的两个最大的问题:
(1) 不适定问题(Ill-Posed Problem),即一个二维姿态可能对应不同的三维姿态。
(2) 病态问题(Ill-Conditioned Problem),即对异常检测点敏感,一个错误的二维检测点会极大影响三维检测准确度。
另一方面,深度学习算法依赖于大量的训练数据,而现有的3D姿态数据集非常少,且大都是依靠适合室内环境的动作捕捉(MOCAP) 系统构建的,系统需要带有多个传感器和紧身衣裤的复杂装置,在室外环境使用是非常不方便的,因此目前的主流数据集基本都是在实验室环境下采集的,这势必会影响到算法在户外数据上的泛化性能。
为了解决不适定问题,本文引入扩张时序卷积模块来拟合时间信息。扩张时序卷积可以通过对输入2D姿态信息的跨步、距离、范围、关联等方面考虑,提高对姿态信息的抽取和重构能力,从而提高模型对不同三维姿态的区分能力。
为了解决病态问题,本文设计了一个嵌入连接矩阵和对称矩阵的图卷积注意力机制模块来拟合空间信息。该模块利用人体骨骼点之间的连接和对称关系构建邻接矩阵,图卷积网络通过局部聚合操作,将每个节点的邻居节点的信息进行聚合,并利用这些节点之间的关系进行信息的传递,以增加人体结构信息,减少误差累积。
基于以上两个模块,本文构建了一种基于深度学习的三维人体姿态估计算法:图注意力时空卷积网络(GA-TCN),该算法灵活地结合了时空信息,相较其他解决方案有着更好的性能表现。
2. 相关工作
目前三维人体姿态估计的主要研究方向有两种:
(1) 基于回归的三维人体姿态估计:
Newell [2] 提出了一个全新网络结构,称为“Stacked Hourglass Networks”。该网络由多个hourglass模块组成,每个hourglass模块由多个卷积层和池化层交替组成,以捕捉不同尺度的特征。此外,该方法还使用了一种自适应权重回归策略,可以有效地缓解姿态重心点偏移的问题。Chen [3] 等人提出了一种基于层次分解的人体姿态估计方法。该方法通过分解人体姿态为不同部位的姿态,将整个姿态估计问题转化为一系列局部姿态回归问题。
直接回归方法的训练过程是直接将2D图像转换为3D关节坐标,这导致了其对噪声和非常规姿态的鲁棒性较差。即使输入的2D图像相同,由于镜头的距离、光照和人体形变等因素的影响,得到的3D姿态也会有所不同,且模型通用性较差 [4] :对于不同的人体形态和姿态,直接回归方法不具有很好的通用性。因为人体形态和姿态变化非常大,而该方法在训练时通常只学习到了一些特定的形态和姿态,因此在新的测试数据上可能表现不佳。
(2) 基于2D-to-3D提升的人体姿态:
由于目前2D人体姿态估计准确度非常高,从2D人体姿态出发推断3D人体姿态已成为一种流行的3D人体姿态估计解决方案。在第一阶段,使用现成的2D人体姿态估计模型来估计2D姿势。然后在第二阶段通过2D到3D提升获得3D姿态。
此外,Chen [5] 等人提出了一种无监督提升网络,该网络基于提升–再投影–提升过程的闭包性和不变性提升特性,具有几何自一致性损失。闭合意味着一个经过提升得到的三维骨架,经过随机旋转和重投影后,得到的二维骨架将位于有效二维姿态的分布范围内。不变性是指以不同的角度投影三维骨架得到的二维姿态,经过重新提升后的三维骨架应该是相同的。这种方法可以在没有标记数据的情况下提高三维人体姿态估计的准确性。
随着序列方法(RNN、LSTM、Transformer等)研究的成熟,有研究者尝试输入视频序列来预测3D姿态。Hossain和Little [6] 提出了一种使用具有快捷连接的长短期记忆(LSTM)单元的循环神经网络,以利用人体姿势序列中的时间信息。他们的方法利用序列到序列网络中的过去事件来预测时间一致的3D姿态。但是之前的工作通常忽略了空间约束和时间相关性之间的互补性质,基于此Pavllo [7] 等人提出了一种可扩张时序卷积网络,用于从连续的2D序列中估计2D关键点上的3D姿态。
鉴于人体姿势可以表示为一个图,其中关节是节点,骨骼是边缘,图卷积网络(GCNs) [8] 已被应用于2D~3D姿势提升问题,并显示出良好的性能。Ci [9] 等提出了一种局部连通网络(Local Connected Network, LCN),它利用全连通网络和GCN来编码局部联合邻域之间的关系。LCN可以克服GCN权值共享方案对姿态估计模型表示能力的限制,以及结构矩阵缺乏支持自定义节点依赖的灵活性。Zhao [10] 等人也解决了GCN中所有节点的卷积滤波器共享权矩阵的局限性。为了研究语义信息及其关系,提出了一种语义GCN算法,语义图卷积(SemGConv)操作用于学习边缘的通道权重。由于SemGConv和非局部层是交错的,因此可以捕获节点之间的局部关系和全局关系。
3. 模型框架

Figure 1. Framework for 3D pose recognition algorithm
图1. 3D姿态识别算法框架
本文提出的3D姿态检测算法的总体框架如图1所示,图中的箭头基于数据流动方向示意给出了算法流程。首先如图1左上方所示,它采用现有算法对视频图像进行2D姿态估计,获得人体二维骨骼坐标序列作为下一步3D姿态估计的输入;然后如图1中虚框中部所示,它采用本文提出的图注意力扩张时序卷积网络(GA-TCN)将2D姿态提升为3D姿态,输出人体三维骨骼坐标点。在训练阶段,如图1右上方所示,它以真实三维人体位姿作为监督计算损失,通过反向传播完成GA-TCN网络的参数训练。GA-TCN网络的详细结构和原理见下节讨论。
4. 图注意力时序卷积网络
4.1. 图卷积网络与图注意力机制
对图2(a)所示二维周期网格,例如图像像素,采用传统卷积神经网络就可对其进行特征提取等各种处理。但是对图2(b)所示非规则网格,必须采用图卷积网络(Graph Convolutional Network, GCN)。在GCN中网格节点的拓扑关系复杂多变,需要通过连接矩阵进行定义。
 (a)
(a)  (b)
(b)
Figure 2. Periodical 2D grids and non-periodical 3D grids
图2. 二维周期网格与非规则三维网格
在图卷积神经网络中,邻接矩阵能够提取节点之间的拓扑结构信息。它描述了每个节点与其他节点之间的连接关系,包括基于位置、图像特征等的表示方法。通过邻接矩阵,网络能够识别节点之间的依赖关系、拓扑结构及节点的位置信息等信息,从而更好地理解图像特征之间的关系,并捕捉人体关键点之间的空间和结构信息。
 (a)
(a)  (b)
(b)
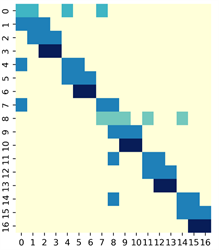
Figure 3. (a) Representation of the adjacency matrix
as a heatmap; (b) Representation of the symmetric matrix
as a heatmap
图3. (a) 邻接矩阵
热图表示;(b) 对称矩阵
热图表示
图3(a)为邻接矩阵的热图表示,其中边缘节点(3, 6, 10, 13, 16)分别为头、双脚、双手,这些节点在热图由深蓝色块标记,可以很清楚的看到相比其他节点,边缘节点仅有一条连接边。而在一般的图卷积任务中仅仅使用一阶邻域表示,这种表示在模拟以躯干为中心的人体时通常表现很差,因为这忽略了人体的对称性结构和人体四肢的运动学约束。一阶邻域表达将关节约束仅限于相邻的一个关节,这对于运动链末端的边缘关节缺乏约束,因此它们在空间中的位置不能被有效地定位。这也是重建误差的最大来源。因此本文引入人体结构相关知识,加入了基于人体骨骼对称结构的图卷积核邻接矩阵
。
对于来自视频的2D姿态预测序列的输入,本论文将二维关键点视为代表人类骨骼的关节,用一个无向图表示骨架,其中关节是节点,关节之间的链接是边。本论文基于Zhao [10] 提出的SemGCN构造给定单帧的二位关键点骨架图,将骨骼2D姿态定义为
,其中V是N个节点和E条边的集合。设
是包含C个特征的节点的集合,在本文中C = 2,即一个节点由其二维平面中的坐标值
表示。图的结构可以用一阶邻接矩阵
表示节点之间存在的连接,用单位矩阵I表示自连接,
表示在邻接矩阵中添加自连接信息。给定第l层的节点特征,通过以下卷积得到后续层的输出特征如下所示:
(1)
其中
是一个通过反向传播学习的矩阵,用于转换输出通道,
是一个可学习的掩码矩阵,
是元素乘运算,
是一个Softmax非线性激活函数,它将一个节点的特征归一化到图中相应的相邻节点。
通过对输出节点特征的通道引入一组掩码矩阵
,可将上式推广为:
(2)
其中
表示通道级联,
是矩阵
的第c行。

Figure 4. Graph attention mechanism module
图4. 图注意力机制模块
用分别表示人体节点连接和对称关系的邻接矩阵和对称矩阵分别组成图卷积网络,再将两者相结合即构成图注意力机制模块,如图4所示,其中C为通道数,T为接收域(即同时输入的视频帧数),N为关节数量(17个关节)。输入分别经过对称图卷积块和邻接图卷积块,然后将输出在通道维度上连接,最后通过一个一维卷积降维保持通道维度和输入维度一致。
经过图注意力机制对输入序列的每一帧数据进行处理后,添加了人体骨架连接信息和人体对称信息,后续进一步传输给扩张时序卷积层在时间维度上建模。
4.2. 扩张时序卷积
人体姿态是连续变化的,人体姿态的某一关节点在某一时刻可能无法准确提取,例如被遮挡,但是在下一时刻遮挡可能消失。换句话说,进一步利用视频动作的时间相关性,可以有效增加人体姿态估计的准确性和鲁棒性。为此本文引入了一个完全由卷积构成的具有残差连接的扩张时序卷积网络,它以图注意力机制处理后的2D姿势序列作为输入,最终重建出3D人体姿态序列。扩张时序卷积网络具有许多优点,例如可以克服RNN [7] 无法在时间上进行并行化处理的缺点;再如其输出和输入之间的梯度路径具有固定长度,不受序列长度影响,可以有效缓解影响RNN [11] 的消失和爆炸梯度问题;同时还提供了对于时域接收域精确控制,这在3D姿态估计任务中非常有效。

Figure 5. Graph Attention Mechanism Module
图5. 扩张时序卷积网络核心结构
扩张时序卷积网络的核心结构如图5所示。根据其中的网络连接关系,给定一个第l层的长为T有M维特征的输入序列
,以及卷积核,卷积运算F定义如下
(3)
其中d是扩张因子,k是卷积核大小,s − d∙i表示过去的方向。扩张操作相当于在卷积核内部引入固定步长。当d = 1时,扩张卷积退化为常规卷积。使用更大的扩张使得顶层的输出能够代表更大范围的输入,从而有效地扩展卷积层的接收域,有利于提取更长时间间隔的时间相关性。
5. 实验结果与分析
5.1. 数据集准备与评估指标
本文实验采用目前使用最广泛的室内人体姿态数据集Human3.6M [12] 。该数据集涉及从4个不同视角拍摄的11名专业演员(6男5女)在室内进行的17项活动(例如吸烟、拍照、打电话),共包含360万个3D人体姿势,以及由基于标记的准确MoCap系统捕获的3D地面实况注释,可同时获取24个身体部位的实时三维坐标。本文使用其中的S1、S5、S6和S7的图像进行训练,使用S9和S11的图像进行测试。实验对GA-TCN算法中的图注意力模块和扩张时序模块分别进行了消融实验,训练过程中使用PyTorch 框架实现本论文的方法并进行训练与测试。对于Human3.6M,使用批量大小b = 128的Amsgrad进行优化,并训练50个epoch。学习率从0.001开始,然后在每个epoch中应用学习收缩因子α = 0.95。每个dropout层均设置为0.05。
本文采用平均关节点位置误差 [13] (Mean Per Joint Position Error, MPJPE)和标准化平均关节位置误差 [14] (Normalized Mean Per Joint Position Error, NMPJPE)作为模型的评价指标来评估其效果。其中MPJPE的计算公式如下:
(4)
式中N表示输入视频帧数,J表示关节数,Xi,j表示第i个样本中第j个关节的真实三维坐标点,
表示第i个样本中第j个关节的预测三维坐标点。
NMPJPE通过计算预测关节位置与真实关节位置之间的欧氏距离来衡量算法的准确性,并对结果进行标准化以考虑不同人体模型的缩放和旋转。具体计算公式如下:
(5)
其中S是一个标准化因子,通常是参考关节的长度或者整个人体模型的对角线长度。
5.2. 实验结果与讨论
在实验中本文采用的硬件设备和软件环境配置分别如表1和表2所示。

Table 1. Hardware equipment configuration
表1. 硬件设备配置
Table 2. Software equipment configuration
表2. 软件设备配置
本文首先比较了图注意力模块对模型的提升效果。在实验评估中本文以VideoPose3D提出的预测模型为基底,同时为了降低时域因素的干扰,将时序卷积的接收域统一规定为27帧。两个模型在训练过程中验证集的误差如图4所示,蓝色线段表示未引入图注意力机制的模型,橙色线段表示引入图注意力机制的模型。从图4中可以明显看出在引入图注意力后模型效果的提升。

Figure 6. (top) Changes in loss during the training process; (middle) comparison of MPJPE; (bottom) comparison of NMPJPE
图6. (上) 训练过程中损失变化;(中) MPJPE对比;(下) NMPJPE对比
图6说明本文提出的模型分别在时序卷积逐层增加的情况下,损失函数曲线出现明显的下降。在时序卷积扩展因子设定为[3, 3, 3, 3]的情况下,平均MPJPE为25.11 mm,相比于三层扩展因子[3, 3, 3]的28.30 mm降低了12.7%,相比于两层扩展因子[3, 3]的36.46 mm降低了31.1%。这证明在卷积步长不变的基础上,加深时序卷积的叠加层数能有效地提升模型性能。


Figure 7. The decreasing curve of the loss function on the training set, validation set, and test set under different expansion factors
图7 不同扩展因子下训练集、验证集和测试集的损失函数的下降曲线
图7进一步给出了引入图注意力机制后模型在各个动作上的误差表现(表中GA-TCN,T = 27,without GA那一行为不引入图注意力机制,接收域为27帧的模型,而后续各行为引入图注意力机制,但接收域不同)。从表3中可以看出,与其他3D姿态模型相比(表中前10行),本文提出的模型在各种动作上的估算误差均有所下降。
Table 3. Comparison of MPJPE among different models on various action validation sets
表3. 各模型在不同动作验证集中的MPJPE对比
通过实验结果的对比分析可以发现,在引入图注意力机制之后,模型在测试集上的平均测量误差为49.6 mm,较改进前降低5.8%。在扩展因子固定为三层的情况下,增加每次时序卷积的步幅,损失函数曲线略微下降。其中[5, 5, 5]和[3, 5, 7]的接收域分别为125帧和105帧,相比于[3, 3, 3]的27帧有较大的扩展。其结果也反映到模型性能上,在接收域扩展将近3倍的情况下,平均MPJPE仅仅降低了2.7%。这表明相较于加深时序卷积的深度,在单个时序卷积上加大步幅对模型的性能提升较小。
表3给出了在不同模型在各动作上的误差对比,数据表明在不存在自遮挡的动作中(如问候、等待、行走等),本模型较其他模型平均误差降低8.9%;在存在自遮挡的动作中(如坐着、抽烟、电话等),本模型较其他模型平均误差降低11.5%验证了图注意力机制的有效性。实验证明本文构建的人体三维姿态估计模型具有较好的预测准确性,并在各项存在自遮挡的动作上提升较为显著。
图6给出了本文的一组3D人体姿态估计实验测试结果。其中在图8(a)的视频图像中,标出了所检测到的人体2D姿态骨骼关节点,这些骨骼关节点对应的三维坐标如图8(b)所示。在表1和表2所示配置下,文本所提出的3D人体姿态估计算法可以达到约每秒14帧的准实时检测速度。
 (a) (b)
(a) (b)
Figure 8. Model detection results
图8. 模型检测结果
6. 结论
本文提出了一种基于深度学习的三维人体姿态估计算法,该算法充分利用人体骨骼节点的连接关系和对称关系构建了一种图注意力时间卷积网络,该网络可以充分利用单目视频中的时空信息,解读人体姿态随时间的变化,从而相较传统方法表现出更好的准确性和鲁棒性。该算法可以达到准实时检测速度,可以广泛应用于老人安保监测、VR、虚拟数字人和元宇宙等领域。