1. 引言
人们通过眼睛获取信息,大脑对信息进行处理从而得出结论。与人类处理数据的方式类似,计算机模拟生物视觉,通过大量的图像或者视频来学习包含在图像或者视频里的信息从而能够感知环境,来解决相应的问题。计算机视觉有图像的分类 [1] 、检测 [2] 、分割 [3] 这三大任务。小目标的检测一直是目标检测问题中一个难以解决的困难点,该技术的目的是准确地检测出图像中可视化特征信息非常少的小目标,通常指32*32像素以下的目标。与常规尺寸的目标物体相比,小目标在目标检测任务中常常存在几个困难,比如小目标可利用特征少、对定位精度要求高、数据集中小目标物体少、目标检测网络未针对小目标物体优化等问题。2012年卷积神经网络开始兴起,目标检测任务进入快速发展期。基于卷积神经网络的目标检测算法主要有两条发展方向既:无锚框和基于锚框的方法,其中基于锚框的方法又包含了One-stage (一阶段检测算法)和Two-stage (二阶段检测算法)。两阶段算法的开端是由Girshick提出的R-CNN [4] 算法,它的主要思想是使用卷积神经网络(CNN)来提取图像中的特征,然后使用选择性搜索算法来提取图像中的候选区域,最后使用CNN来分类和定位这些候选区域。此后在R-CNN的基础上Girshick又提出Fast-RCNN [5] 算法。Fast-RCNN只需要在原始图像上提取一次特征,从而大大缩短了训练和推理时间,降低了计算量。一阶段算法的提出则彻底解决了两阶段算法很难解决实时性这个问题从而真正的实现了端到端检测的目的。一阶段算法目前主要包括YOLO (You Only Look Once) [6] 算法和SSD (Single Shot Multibox Detector) [7] 算法,此后的算法大部分是在这两个算法的基础上衍生出来的。随着生成对抗网络(Generative Adversarial Network, GAN) [8] 的兴起,使用GAN对特征图进行上采样,扩大特征图中小目标的尺寸,以此来提升检测网络对小目标母体的检测精度成为研究热点。Bai [9] 与Rabbi [10] 等人分别提出了SOD-MTGAN模型和在遥感小目标检测领域使用超分辨率重建技术,针对小目标的边缘进行增强。此后,越来越多的学者投入到使用超分辨率重建技术来提升小目标检的研究中。
本文在上述问题的基础上,提出了使用基于生成对抗网络的超分辨率算法以及SPD-Conv模块来改进YOLOv5目标检测模型。实验表明,在VisDrone2019数据集上对比原始YOLOv5网络mAP@0.5提升了3.73个百分点。最后经过消融实验证明本文提出的两个模块对小目标检测效果均有一定提升。
2. 改进ESRGAN超分辨率模型
2.1. 改进RRDB基本块
为获得更好的感知质量和主观判断更好的超分图像,Wang等人在2018提出了ESRGAN [11] 。算法。ESRGAN算法使用RRDB作为基本块,如图1所示,它结合了多级残差网络和密集连接,与SRGAN [12] 。超分辨率模型相比,RRDB的基本块具有更深的结构和更复杂的残差连接方式。此外,ESRGAN在残差值添加到主路径之前乘以一个[0,1]的常数来缩小残差值,以防止不稳定。通过观察发现,当初始参数方差变小时,残差结构会变得更加容易训练。然而在处理极低分辨率的小图像时ESRGAN网络会出现模糊现象,同时ESRGAN算法也存在平滑图像细节丢失的问题,在处理复杂场景图片,诸如具有复杂色彩和复杂边缘信息的图像时会出现纹理细节丢失的现象。为此本文提出了一种新的网络架构,用一个新的基本块来代替ESRGAN使用的基本块,此外,向生成器网络中引入高斯噪声,利用随机变化来产生纹理细节更加真实的图像。
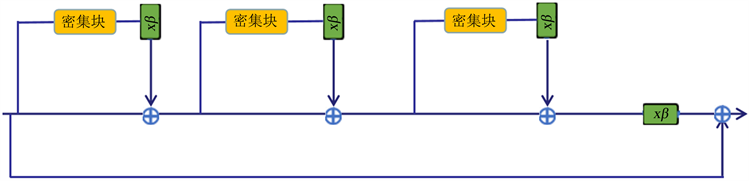
Figure 1. RRDB basic block structure diagram
图1. RRDB基本块结构图
原密集块RRDB结构如图2(a)所示RRDB块融合了多级残差网络的思想也融合了密集连接的思想。在图2(a)提供的密集块基础上添加额外的残差学习层,在不增加复杂性的同时增加模型的理解力,以达到更好的鲁棒性,然后在每个密集块的每两层中再添加一个残差。使用改进RRDB块的新模块生成的图像,在视觉质量方面要比原密集块的视觉质量高很多。在Chen [13] 等人提出的论文中也正印证了这样的观点:残差网络可以重复使用特征,密集网络可以找到新的特征。因此这种改进架构可以充分利用和探索特征,从而产生主观视觉质量更高的图像,改进后的网络结构如图2(b)所示。
 (a) RRDB基本块
(a) RRDB基本块 (b) 改进RRDB基本块
(b) 改进RRDB基本块
Figure 2. Improved RRDB basic block structure diagram
图2. 改进后RRDB基本块结构图
2.2. 引入高斯噪声
往生成器中加入噪声常被应用于生成人脸的网络中,可见加入噪声对图像纹理细节的提升有很大的帮助。为了产生纹理更加真实的图像,将高斯噪声添加到每个密集残差块的输出中,其网络结构如图3所示。
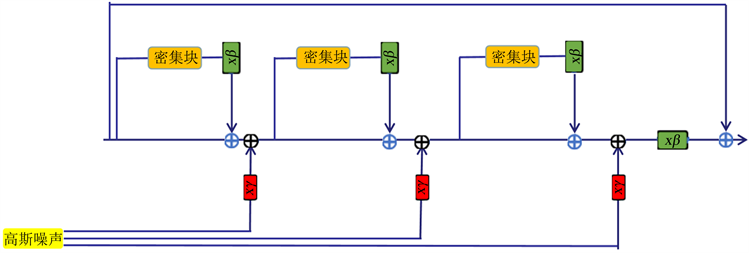
Figure 3. Network structure after adding Gaussian noise
图3. 添加高斯噪声后的网络结构
2.3. 损失函数设计
本文判别器的设计使用相对判别的方法,判别器需要同时输入一组图像,其任务变成了相对其中一张图像另一张图像为真实的概率。相对判别器的输入是两张图像,公式表示为:
(1)
其中
。
表示的是判别器未做sigmoid前的输出。
表示的是某一分布在判别器输出的期望。
则生成器的对抗损失为:
(2)
由生成器损失可知,真实图像和生成图像都能够为生成器贡献损失,因此生成器可以从两者中获益。采用此方法可以训练生成器,生成纹理细节更丰富的图像。
使用感知损失的目的是在特征空间中,约束生成的图像尽可能和真实图像保持一致,这样得到的结果不像像素空间那么模糊。在SRGAN中使用VGG特征层激活函数后的特征图做约束。ESRGAN指出激活后的特征是很稀疏的,监督能力很小。以VGG19网络为例,在第5个池化层前的第4个卷积层(VGG19-54)后激活函数后的信息仅有11.17%,以该结果做监督,监督力度很弱,这致使网络效果不佳。因此本文采用ESRGAN中的方法,使用激活函数前的特征计算损失,依次训练网络,这样监督信息不是稀疏的,监督力度更强。VGG损失的定义为,生成图像
的特征与参考图像
特征之间的欧氏距离:
(3)
式中,
,
为VGG网络中各个特征映射的维度。
综上,生成器的总损失为:
(4)
其中
为生成图像与参考图像之间的
损失。
2.4. 优化器设置与实验环境.
本文选用Adam优化器,其中
设置为0.9,
设置为0.999。在网络收敛前,交替训练生成器G和判别器D,以此来更新两个网络的参数。本文实验在阿里云平台进行,实验的深度学习环境和使用的框架如表1所示。
2.5. 实验结果分析
本文将优化的最终模型在BSDS [14] 数据集上与当前流行的超分模型(包括SRGAN和ESRGAN)进行对比,来证明本文提出的改进ESRGAN中RRDB模块的残差连接以及引入相对判别器对超分辨率重建任务是相当有益的。为了展示本文所提出的网络的超分辨率细节纹理的生成能力。本文从BSDS数据集的原图中裁剪出一块96 × 96的子图像,利用双三次插值法对子图像进行4倍下采样处理得到低分辨率图像。本文从生成结果中选取了几组具有代表性的结果进行展示。图4(a)是测试数据集上的原始图像,图4(b)的第一列是从测试集的原始图像中裁剪出的96 × 96的子图像,第二列是使用双三次插值法对子图像进行4倍下采样处理得到低分辨率图像。第三列是使用ESRGAN算法对低分辨率图像超分后的结果。第四列是使用本文所提出的算法对低分辨率图像超分后的结果。从本次的实验结果中可以看出,本文提出的改进ESRGAN算法比原始的ESRGAN算法生成的图像更加清晰,生成边缘和纹理细节更加丰富,从而可以证明加入密集残差块和引入对抗损失对超分辨率重建任务是相当有益的。



(a) 数据集中的三张原始图片


 HR LR ESRGAN 改进ESRGAN(b) 实验生成效果对比
HR LR ESRGAN 改进ESRGAN(b) 实验生成效果对比
Figure 4. Comparison between the improved ESRGAN algorithm and the original ESRGAN algorithm
图4. ESRGAN的改进算法与原始ESRGAN算法效果对比图
3. 基于超分辨率重建的YOLOv5改进算法
3.1. SPD-Conv
YOLO系列目标检测模型对原图进行了缩放,检测网络需要由特征层使用分类和回归操作进行下采样,下采样后小目标特征的感受野需要映射回原图,然而经过上述操作后,映射到原图上的小目标在原图中的尺寸可能小于原本的尺寸,造成检测效果变差。小目标往往更依赖浅层特征,因为浅层特征有更高的分辨率,其次对于深度卷积网络,在深度的特征图提取过程中小目标信息可能已经丢失。在常见的目标检测模型中需要使用主干网络对目标图像进行下采样处理,这种下采样处理会使面积较小的目标在特征图上的映射只有几个像素点的大小,因此分类器很难对目标进行分类。受大目标影响,检测网络会将重心转移到对大目标的检测上导致网络对小目标的检测效果变差。
深度卷积体系结构中有一个对于小目标来说的设计缺陷,既CNN架构中常采用跨步卷积或池化层,这导致了细粒度信息的丢失和较低效率的特征表示的学习。为此在2022年8月7日来自于Missouri大学的Raja Sunkara and Tie Luo提出了一种新的CNN模块,称为SPD-Conv [15] 。SPD-Conv完全替代(从而消除)卷积步长和池化层。SPD-conv是一个空间到深度层,后面跟着一个无步长卷积层对特征映射X进行下采样,但保留了通道维度中的所有信息,因此没有信息丢失。
3.2. 空间到深度
如图5,SPD-conv由一个空间到深度层和一个非跨步卷积层组成。考虑任何大小为
的中间特征图X,切出一系列子图为:
(5)
(6)
(7)
(8)
(9)
(10)
一般来说,给定任何(原始)特征映射X,子映射
由所有特征映射组成的特征图
,
和
可以按比例因子对X进行下采样。如图5给出了比例因为为2时的例子,得到4个子图
每个都具有形状
并将X下采样2倍。接下来,沿着通道维度连接这些子特征图,从而获得一个特征图
,它的空间维度减少了一个比例因子,通道维度增加了一个比例因子。换句话说,SPD将特征图
转换为中间特征图
。
3.3. 将SPD模块嵌入到YOLOv5中
基于SPD-Conv的特性和YOLOv5目标检测的网络结构,只需要用SPD-Conv结构替换YOLOv5中随同stride-2的卷积层。在YOLOv5的主干网络中,使用了五个步长为2的卷积层来将特征图缩小32倍。YOLOv5目标检测的网络在颈部使用了2个stride-2的卷积层。综上将SPD-Conv模块应用到YOLOv5中需要替换7处,分别为主干网络5处,颈部2处。YOLOv5颈部的每个跨步卷积之后都有一个连接层,卷积层将得到保留,全连接层将保持在SPD和Conv之间。改进后的SPD-YOLOv5主干网络架构如图6(a)所示,颈部网络如图6(b)所示。
 (a)
(a)  (b)
(b)
Figure 6. SPD Structure diagram of SPD embedded in YOLOv5
图6. SPD嵌入到YOLOv5中的结构图
3.4. 基于超分辨率重建的目标检测模型
本文将改进版ESRGAN超分辨率网络嵌入到SPD-YOLOv5中对图像进行上采样,丰富特征信息,以提高小目标检测任务的精确度。在本文中,为了减少模型的计算量,只对YOLOv5主干网络提取的特征图进行超分辨率重建。其基本网络结构如图7所示。
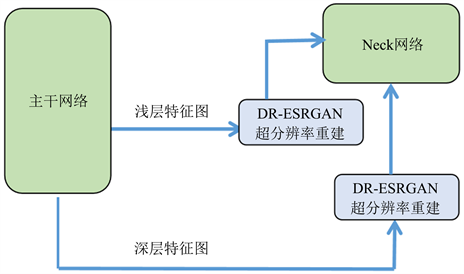
Figure 7. Improved version of ESRGAN + SPD-YOLOv5 simple diagram
图7. 改进版ESRGAN + SPD-YOLOv5简易图
4. 实验分析
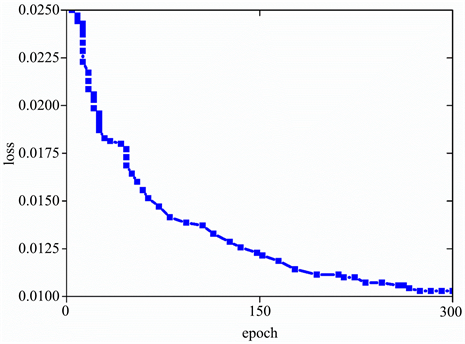
本文将训练的batchsize设置为16,使用SGD随机梯度下降法作为本网络的优化器。为了获得本网络最优的超参数,本文采用基于遗传算法的超参数进化算法来对网络的超参数进行优化。为了减少训练时间,本文挑选1000张图片作为进化过程中的数据集,evolve设置为50,epoch设置为100,最终在第30代之后训练精度收敛于最大值,从而选择这组超参数作为本文网络的超参数。超参数具体设置如下:初始学习率设置为0.01392,学习率动量设置为0.96783,权重衰减系数何止为0.002,图像Mosaic的概率设置为1.0。最终三中损失函数收敛情况如图8所示。
 (a) Lossobj
(a) Lossobj (b) Lossbox
(b) Lossbox  (c) Losscls
(c) Losscls
Figure 8. Loss of function convergence
图8. 损失函数收敛情况
预测精度mAP随epoch的变化如图9所示。
4.1. VisDrone数据集实验分析
为了让本文的实验更加周密和方便对比,本文借鉴了文献 [16] 所做的实验设置,验证YOLOv3、YOLOv5和本文所提出的模型在VisDrone2019数据集上的实验结果,与此同时也将BetterFPN和RRNet加入实验对比,最终结果如表2所示。由表2可以看出,本文所提出的模型 评价指标均高于YOLOv3、RRNet、BettrtFPN等模型。比原始YOLOv5模型提高了3.73个百分点。实验也表明本文提出的模型在小目标数据集上效果优秀以及在不同的数据集上也具有较强的鲁棒性。本文模型在VisDrone2019数据集上训练出的混淆矩阵如图10所示。

Table 2. VisDrone dataset experimental results
表2. VisDrone数据集实验结果
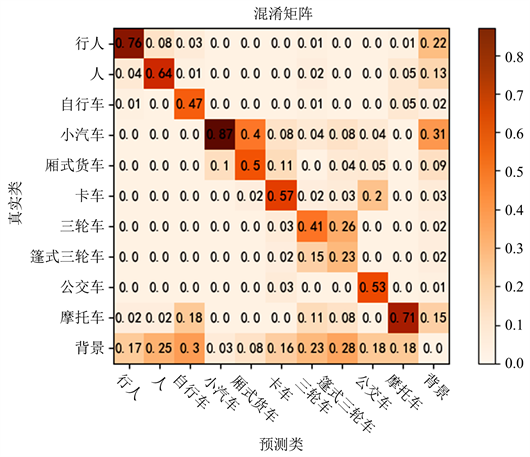
Figure 10. VisDrone dataset experimental confusion matrix
图10. VisDrone数据集实验混淆矩阵
4.2. 消融实验
为了探究本文提出或改进模块对于整个模型的提升效果,本节使用VisDrone2019数据集进行验证,并进行消融实验,在原始YOLOv5的基础是逐一增加各模块,并比较实验结果以评估每个模块的贡献。表3列出了消融实验的结果。
Table 3. Results of ablation experiment
表3. 消融实验结果
由表3可知,增加超分辨生成网络和SPD模块对于检测网络mAP的提升贡献相对较大,分别提升了1.92个百分点和1.08个百分点,说明对特征图进行超分辨重建和取消跨步卷积能有效的增强模型对于微小目标的检测能力。同时可以发现单独增加CA注意力模块对于检测网络mAP提升效果比较一般,但是将CA模块嵌入到DR-ESRGAN + SPD-YOLOv5中时提升较大为0.73个百分点,说明注意力模块能够结合其它提升模块能够发挥更好的效果。图11为本文模型在VisDrone数据集上的部分检测效果。
 (a)
(a) (b)
(b)
Figure 11. The partial detection effect of this model on the VisDrone dataset
图11. 本文模型在VisDrone数据集上的部分检测效果
5. 总结
本文针对YOLOv5目标检测模型对小目标检测精度较差的问题,首先对ESRGAN超分辨率网络进行改进,在RRDB基本块的基础上添加额外的残差学习层,并且在每个密集块的每两层中再添加一个残差。在不增加复杂性的同时增加模型的理解力,以达到更好的鲁棒性,同时引入高斯噪声,在生成图像的某些局部方面随机化生成,能够使模型在更高级的层面提供更细致的纹理细节。接着引入SPD-Conv模块来取消跨步卷积,提升目标检测网络对微小物体的特征感知能力。最后对融合超分辨率重建、SPD-Conv模块的YOLOv5目标检测网络进行实验分析,实验证明本文提出的网络对小目标物体的检测性能优越,对比原始YOLOv5模型mAP (%)提高了3.73个百分点。最后进行消融实验,目的是验证本文提出的各种模块对小目标检测性能的贡献。