1. 背景介绍
1.1. 引言
居民收入向来是社会关注的热点问题,而消费为宏观经济活动中必不可少的一个环节;作为消费的前提,收入的高低水平决定着消费能力的大小,并且直接影响居民的消费信心、消费欲望和消费能力;收入作为消费的来源与基础,是影响消费的最重要因素。改革开放以来,中部地区省份的经济发展面临着一系列问题,其经济发展与东部地区差距逐渐拉大,同时,随着国家西部大开发战略发展措施的出台,西部地区与其经济发展差距也在不断缩小,中部地区面临着“中部塌陷”的危险。因此分析当前中部地区经济发展现状和问题,对促进中部地区崛起,推动全国区域协调发展,具有重要意义。
因此本文选取中部地区六个省份城镇居民人均消费性支出和人均可支配收入作为研究对象,从面板回归及时间序列分析的角度出发,研究人均消费性支出与人均可支配收入之间是否存在着长期、稳定的均衡关系,即消费与收入的长期走向是否大致相同,并进一步建立人均可支配收入的时间序列预测模型,为中部地区省份相关政策的制定与修改提供可信的依据。
1.2. 文献综述
国内学者从不同视角就居民收入与消费性支出之间的关系开展了研究。邱慧、黄解宇、李钰(2018) [1] 运用灰色关联分析模型研究山西省农村居民收入与消费结构之间的关系,得出相关结论,并提出调控现状的相关措施。胡霞(2020) [2] 从保障城乡居民收入结构合理性视角出发,采用我国28个省区市城乡居民收入和消费数据,考察了城乡居民收入结构差异与消费差异之间的关联性。该研究发现,我国东部地区居民劳动性收入对消费升级类消费的影响显著,而中部地区财产性收入差距对消费水平差异具有显著影响,劳动性收入对消费水平差异的影响效应不存在,西部地区则表现为前期居民消费倾向对消费具有惯性作用。李新朋(2019) [3] 运用ARIMA模型,对上海城镇居民人均可支配收入情况进行了预测研究。臧旭恒和张欣(2018) [4] 以资产价值变动估计了家庭收入的暂时性变动对居民边际消费倾向的影响,研究结果表明:收入的暂时性变动对低收入群体的消费影响要大于高收入家庭。
学者们的数据选取、模型设定、变量选取、指标体系构建和分析方法不同,得出的结论也不同。很多学者没有具体分析中部地区内部省份的城镇居民人均消费性支出和人均可支配收入之间的差异,而只是对中部地区的单一省份进行研究。因此本文通过构建科学的评价指标体系来探究我国中部地区城镇居民人均消费支出和人均可支配收入之间的关系。
2. 数据来源与说明
2.1. 样本选择与数据来源
选取我国中部地区六个省份(湖南省、湖北省、河南省、安徽省、江西省、山西省) 1991~2021年共31年中各年的城镇居民人均可支配收入(单位:元/人)、人均消费支出(单位:元/人)作为研究数据,数据来源于国家统计局及各省统计局,保证数据的完整性和结果的可靠性,最终得到186个样本数据。
2.2. 变量的定义与描述
2.2.1. 解释变量
从统计局中获取六个省份1991~2021年各年的城镇居民人均可支配收入的数据,通过选择城镇居民人均可支配收入可更好地反映城镇居民收入水平的变化,消除各年中因人数变化而带来的影响。对城镇居民人均可支配收入进行对数化处理,选取人均可支配收入的对数作为解释变量。
2.2.2. 被解释变量
从统计局中获取六个省份1991~2021年各年的城镇居民人均消费支出的数据,通过选择城镇居民的人均消费支出可更好地反映城镇居民消费支出水平的变化,消除各年中因人数变化而带来的影响。对城镇居民人均消费支出进行对数化处理,选取人均消费支出的对数作为被解释变量。
2.2.3. 变量定义表(见表1)
2.2.4. 描述性统计
从表2中可以看出,我国中部地区六个省份的人均消费支出的标准差是7492.560元,说明各省份人均消费支出的地区差异较大,消费水平有较大的区别。六个省份的人均可支配收入的标准差是12055.92元,说明各省份人均可支配收入的地区差异较大,可支配收入的分配不均衡。六个省份的人均消费支出和人均可支配收入的均值分别为10006.47元和14800.32元,可反映人均可支配收入中除了消费支出,还包含其他类型的支出,如:投资支出等,这是符合现实经济意义的。

Table 2. Descriptive statistics of variables
表2. 变量的描述性统计
3. 城镇居民人均可支配收入对人均消费支出影响面板回归的建模分析
3.1. 模型设计
3.1.1. 模型建立
为研究中部地区城镇居民人均可支配收入和失业率对人均消费支出的影响,以人均消费支出的对数为被解释变量,以人均可支配收入的对数为解释变量,构建如下模型:
(1)
3.1.2. 变量解释
在式(1)中,i为省份,t为年份,ln(Costi,t)为i省在t时期人均消费支出的对数值,ln(Incomei,t)为i省在t时期人均可支配收入的对数值,αi为i省的个体异质性,εi,t为随机扰动项。
3.2. 数据预处理
3.2.1. 面板数据的建立
通过对前文的数据进行整合处理,并依据建立的面板模型建立面板数据,搜集整合人均消费支出和人均可支配收入,并辅以中部地区的六个省份赋以的地区值作为虚拟变量建立面板数据。在面板数据中,每个时期在样本的个体完全一样,即为平衡面板数据。
3.2.2. 变量的平稳性检验
在面板数据中,为了避免“伪回归”的出现,确保样本数据的平稳性和估计结果的有效性,需要对数据进行平稳性检验。本文选择ADF检验对面板数据进行检验,结果如表3、表4所示,从显著值(Prob)中可以看出,在单位根检验中,5%的显著性水平下均拒绝存在单位根原假设,所有的变量均通过检验,所以该面板的数据都是平稳的。
Table 3. ADF test for ln(Cost)
表3. ln(Cost)的ADF检验
注:**表示其显著程度。
Table 4. ADF test for ln(Income)
表4. ln(Income)的ADF检验
注:**表示其显著程度。
3.2.3. 异方差和截面相关检验
本文的面板数据为长面板数据,随机扰动项εi,t可能存在异方差和截面相关。因此采用沃尔德检验进行异方差检验,采用Breusch-Pagan LM检验进行截面相关检验,检验结果表5和表6所示:在5%的显著性水平下,拒绝同方差的原假设;并在5%的显著性水平下,强烈拒绝截面相关的原假设。
Table 5. Test results of cross-sectional correlation
表5. 截面相关的检验结果
Table 6. Test results for heteroskedasticity
表6. 异方差的检验结果
3.3. 模型的选择
通过F检验来判断应当使用混合模型或固定效应模型,再进行Hausman检验来判断选择随机效应模型或固定效应模型,检验结果如表7和表8所示:
Table 8. The results of Hausman’s test
表8. Hausman检验的结果
检验结果中,F检验的P值小于0.05,因而认为应建立固定效应模型;Hausman检验中P值小于0.05,因而认为应建立固定效应模型。所以选择面板数据的固定效应模型来进行分析求解。
3.4. 模型的结果与分析
表9为直接对所有的样本使用混合回归得出的估计结果,表10为对面板数据使用固定效应模型的估计结果,结果如下所示:
Table 9. Mixed regression estimation results
表9. 混合回归估计结果
Table 10. Fixed-effect model estimation results
表10. 固定效应模型估计结果
将表9与表10进行对比我们可以知道:若将面板数据直接看成是截面数据进行混合回归,将忽略了个体间不可观测或被遗漏的异质性,而该异质性将会导致估计结果不一致,两种模型估计结果的差异证明了我们前文进行的F检验的准确性,即中部地区六个省份之间的差别不可以直接忽略不计。
总体来看,拟合结果的R2和调整后R2较大接近1,P值为0,变量显著性较好,证明模型拟合效果较好。从面板回归方程结果来看,人均可支配收入对人均消费支出的影响系数β1为正,说明人均消费支出与人均可支配收入呈正相关的关系,并且值小于1说明消费性支出不会超过可支配收入,这是符合经济学的假设的。常数项的值为正,说明居民即使没有可支配收入,为了维持生活需要购买各种生活必需品,依然会存在消费性支出的。因此,两个估计量均是符合经济学意义的。
3.5. 结论与建议
3.5.1. 结论
由上述模型的建立与分析,我们最终得到中部地区六个省份城镇居民人均可支配收入与人均消费性支出之间的面板回归方程。可以根据该面板回归方程进行预测,如当城镇居民人均可支配收入达到某一数值时,人均消费性支出将为多少。从面板回归方程的结果中,我们可以看到中部地区内部省份之间的消费水平是存在差异的,湖北省的人均消费支出相对而言是最高的,江西省的人均消费支出相对而言是最低的。
3.5.2. 建议
人均可支配收入是影响人均消费性支出的主要因素,其作用是十分明显的。因此我们应当大力发展中部地区六个省份的经济,完善社会保障制度,增加就业,提高居民的工资水平,增加居民的可支配收入,从而更大程度地提高居民的消费支出水平,实现中部地区共同发展的愿景,并且消费水平的提高也会反过来刺激经济的发展,此为一个相互促进的过程。
影响人均消费性支出的因素还有很多,如价格水平、利率等,因此在重视居民可支配收入增长的同时,还需重视其他因素对居民消费的影响,从而更进一步促进居民消费,提高消费和收入水平。
4. 城镇居民人均可支配收入对人均消费支出影响时间序列的建模分析
4.1. 样本选择说明
选择湖南省1991~2021年城镇居民人均可支配收入作为研究数据开展时间序列的建模分析,并最后理论分析城镇居民人均可支配收入在时间层面上对城镇居民人均消费支出的影响。
4.2. 平稳性检验
这里初步选择湖南省城镇居民人均可支配收入的时间序列数据建立模型,选择ACF自相关系数、PACF偏自相关系数检验以及单位根检验对时间序列的平稳性进行检验,利用Eviews作为工具,对数据进行初步分析。
4.2.1. 数据预分析
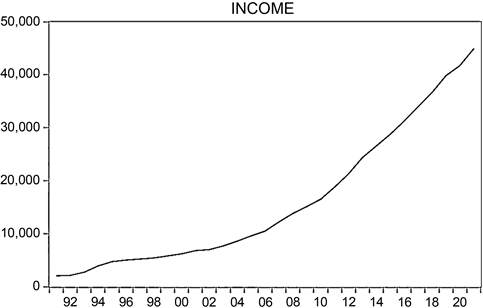
如图1所示为湖南省城镇居民人均可支配收入随时间变化的图像,我们可以初步观察到人均可支配收入随时间变化有一定趋势及规律,并不是随机变化,同时结合经济学现实意义,数据选择较为正确,可以进行下一步分析。但同时也发现人均可支配收入的时间序列图像呈上升趋势,时间序列不平稳,应当对时间序列进行平稳性处理。
 注:横坐标的单位为年份,纵坐标单位为元。
注:横坐标的单位为年份,纵坐标单位为元。
Figure 1. Per capita disposable income raw data time series changes
图1. 人均可支配收入原始数据时间序列变化
4.2.2. ACF自相关系数
从图2中,我们发现序列的自相关系数递减到零的速度相当缓慢,在很长的延迟时期里,自相关系数一直为正,而后一直为负,在自相关图上显示出明显的三角对称性,这是具有单调趋势的非平稳序列的一种典型的自相关图形式。因而对时间序列数据进行差分处理,并再次进行ACF自相关系数检验,希望得到平稳序列。
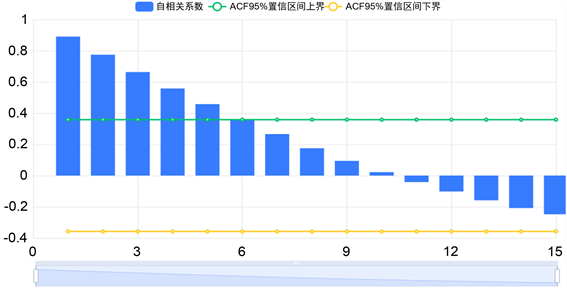
Figure 2. ACF charts of raw data of per capita disposable income
图2. 人均可支配收入原始数据的ACF图
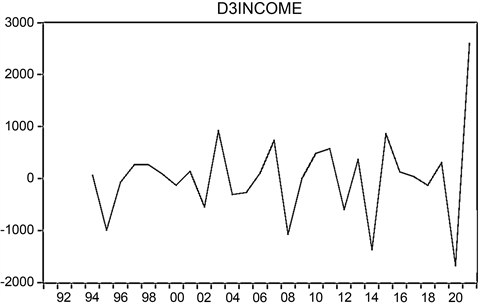
如图3所示,三阶差分后人均可支配收入数据大体平稳。如图4所示,经过三阶差分后,人均可支配收入的ACF图以及PACF图的波动较小,不存在明显的变化趋势,出现一定的截尾及拖尾现象,可以认为时间序列稳定,通过ACF、PACF检验。
4.2.3. 单位根检验
对序列进行单位根检验,直观地从数据上确定序列的平稳性。从表11中得知处理后序列的P值等于0.0006,即在0.05的显著性水平下,序列不存在单位根,说明经过上述处理后序列平稳,可以继续建模。
 注:横坐标的单位为年份,纵坐标的单位为元。
注:横坐标的单位为年份,纵坐标的单位为元。
Figure 3. Time series changes of third-order differential data of per capita disposable income
图3. 人均可支配收入三阶差分数据时间序列变化
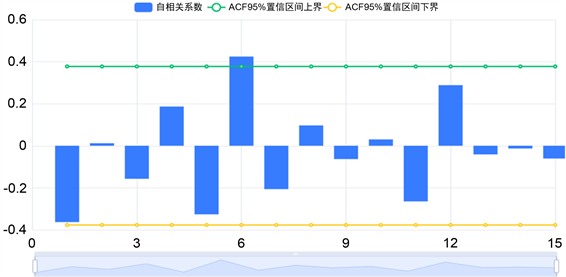
Figure 4. ACF charts of third-order differential data of per capita disposable income
图4. 人均可支配收入三阶差分数据的ACF图
注:*表示其显著程度。
4.3. 白噪声检验
如表12所示,对三阶差分过后的人均可支配收入时间序列数据运用Ljung-Box方法进行白噪声检验。可以发现12阶滞后项的LB检验P值均小于0.05,拒绝原假设,即认为所检验时间序列不是白噪声序列,通过白噪声检验,具有研究价值,可以进行进一步分析。
Table 12. LB test results of third-order difference per capita disposable income time series data
表12. 三阶差分人均可支配收入时间序列数据LB检验结果
4.4. 模型识别
从三阶差分后的自相关图可以看出,人均可支配收入时间序列数据呈现出ACF值迅速跌入置信区间,没有收敛趋势,显示出拖尾性。所以考虑选用ARMA模型来拟合时间序列,考虑到是三阶差分后的时间序列,因此对原始序列使用ARIMA模型。
4.5. 参数选择
通过相关系数检验,三阶差分后人均可支配收入时间序列数据ACF在1阶后衰减趋于零,PACF在1阶后衰减趋于零,差分阶数为3,因此q = 1,p = 1,n = 3,考虑到参数选择的偏误,也可选择ACF在4阶后衰减趋于零即q = 4,故分别建立ARIMA(1,3,1)和ARIMA(1,3,4)模型。同时,使用Eviews自动计算ARIMA模型参数功能,得到类似结果,最终建立人均可支配收入原始时间序列数据的ARIMA模型。
4.6. 模型检验
4.6.1. 模型的拟合度检验
首先绘制模型拟合图,如图5所示,从图中可以看出,残差无规则地在拟合曲线附近波动,表明残值大致上是符合随机分布的,满足残差独立性的检验;并且从图中我们还可以看出红色曲线与绿色曲线的重合度较高,因此我们认为真实值与估计值之间的差别是较小的,从侧面反映了模型的拟合程度是较高的。
绘制残差正态图,如图6所示,P值大于0.05,则接受原假设,样本残差服从正态分布,符合模型对残差服从均值为零的正态分布的基本要求。
模型的显著性检验为检验模型的有效性,一个模型是否显著有效主要看它提取的信息是否充分,一个好的拟合模型应该能够提取观察值序列中几乎所有的样本相关信息,换言之,拟合残差项将不再蕴涵任何相关信息,即残差序列应该为白噪声序列,模型的显著性检验包括残差序列的白噪声检验。
通过对Eviews输入相关命令得到残差序列,其自偏相关值见表13,对残差序列的自偏相关值进行分析,可知Q统计量的P值远大于0.05的显著性水平,为白噪声序列,所以残差序列不存在自相关,即拟合残差项几乎不存在有效信息,所以模型有效。
Table 13. A self-biased correlation of residual sequences
表13. 残差序列的自偏相关值
4.6.2. 模型的显著性检验
湖南省城镇居民人均可支配收入时间序列建立的ARIMA模型整体的拟合效果是较好的,R2和调整后的R2都较大,并通过了F检验。
4.7. 模型结果分析
4.7.1. 人均可支配收入原始时间序列建立ARIMA模型结果
ARIMA模型的原始模型为:
Table 14. Results of ARIMA model estimation
表14. ARIMA模型估计结果
结合表14的拟合结果建立如下模型:
上述模型各估计值标准差较小,具有良好的拟合程度,再次证明模型建立的正确性。具体观察结果,通过数理分析并结合相关理论可以知道城镇居民人均可支配收入确实具有时间相关性,过去的数据会影响当期数据,这说明人均可支配收入的影响具有一定的时间滞后性。同时往期数据的影响系数为正,说明往期的人均可支配收入对当期人均可支配收入产生正向影响,人均可支配收入直接作用于人均消费支出,使人均消费支出总额增加。不仅是本期的人均可支配收入,上期的人均可支配收入对本期的消费支出仍有着间接影响,上期的人均可支配收入让人们对未来有一个较好的预期,这直接促进了本期居民消费支出的增加。
4.7.2. 模型预测
对模型进行预测并绘制出相应的预测图形,如图7所示,湖南省城镇居民人均可支配收入将进一步提升,这源于多年来经济的迅速发展,人均可支配收入将随着时间继续不断地增长。
4.8. 结论和建议
4.8.1. 结论
本文采用三次差分的方法来处理不平稳的序列使其变得平稳。对于平稳的时间序列而言,ARIMA模型的预测会比较精准;而对于不平稳的时间序列而言,由于经过差分的处理,本身微小的误差在数据还原过后会导致原序列的预测误差较大。因此,针对不平稳序列的建模还有待进一步研究。
4.8.2. 建议
由上述模型以及预测结果可知:自改革开放以后,湖南省城镇居民的人均可支配收入迅速增长,表明人们的生活水平得到快速提高。近年来湖南省对小微企业的扶持政策有利于民营经济的发展,也促使居民的人均可支配收入快速提高,中部地区的其余省份可以学习这种做法,加大对小微企业的扶持,提高居民的可支配收入,从而促进居民的消费支出。
 注:横坐标的单位为年份,纵坐标单位为十元。
注:横坐标的单位为年份,纵坐标单位为十元。
Figure 7. Time series forecast of per capita disposable income
图7. 人均可支配收入时间序列预测
中部地区欠发达县(市、区)继续比照实施西部大开发有关政策,老工业基地城市继续比照实施振兴东北地区等老工业基地有关政策,并结合实际调整优化实施范围和有关政策内容;对重要改革开放平台建设用地实行计划指标倾斜,按照国家统筹、地方分担原则,优先保障先进制造业、跨区域基础设施等重大项目新增建设用地指标;不断地发展地区经济,提高居民的可支配收入,从而促进居民的消费支出,实现中部地区的共同富裕。