1. 引言
超分辨率(Super Resolution, SR)重建旨在从低分辨率(Low Resolution, LR)图像重建出高分辨率(High Resolution, HR)图像。本文的研究动机在于为了满足对高质量人脸图像的获取需求,专注于通过算法模型提高人脸超分辨率重建的效果,以此降低更换高像素相机的成本。
目前,深度学习方法已被广泛应用于图像处理任务。自从文献 [1] 提出了一种三层结构的超分辨率模型后,又诞生了许多优秀的方法。文献 [2] 在一个很深的残差模型中,通过调整通道的权重来让模型突出关键部分。文献 [3] 在通道注意力的基础上使用中间状态矩阵模拟像素间的空间相关性。而文献 [4] 则通过残差和密集的连接方式加强信息传递,提高模型的泛化能力。这些方法利用残差连接、密集连接和注意力机制等结构,在峰值信噪比(Peak Signal to Noise Ratio, PSNR)和结构相似性(Structural Similarity, SSIM)等评估指标上均有显著提高。但是,它们通常采用Bicubic下采样来模拟退化后的训练数据集,这种退化方式是固定且理想的,并且简化了实际的退化场景,因此很难推广到实际应用中。
在实际情况中,受相机传感器质量、拍摄条件、存储方式以及分辨率变化等多种因素影响,图像的退化方式是未知的。为了更好地适应实际应用需求,一些研究人员正试图使用更为复杂的退化模型。文献 [5] 提出了一个通用的框架与退化策略,采取模糊内核和噪声水平两个退化因素。文献 [6] 认为真实的模糊核可以通过对图像中高度重复的块进行估计获得,并使用GAN来学习这种映射关系。文献 [7] 在双三次退化的LR图像中额外加入自然图像特征,并将这些数据用于GAN模型的训练,从而大大提高重建质量。合适的退化模型可能会带来更好的重建效果,但是过度退化会导致性能下降 [8] 。
针对现实中人脸图像的常见退化场景,本文设计了一种人脸图像退化模型,该模型采用随机退化算法对输入图像进行实时退化,并将其作为训练用的图像对输入超分辨率模型,以此扩展模型的映射能力。人脸图像包含丰富的纹理细节信息,而生成对抗网络(Generative Adversial Network, GAN)被广泛应用于恢复和重建任务。鉴于这点,本文提出了一种新的超分辨率模型DSTGAN (Dense Swin Transformer Generative Adversial Network)。DSGAN的生成器不再是传统的卷积,而是采用一种Transformer结构,将GAN与Transformer进行结合。更进一步的,本文通过密集连接多个Transformer层,提出了一种新的生成器单元DST (Dense Swin Transformer),利用密集连接高效地传递各层信息。同时,鉴别器方面引入性能更强的U-Net结构,用于提高鉴别能力。
2. 相关工作
2.1. 生成对抗网络(GAN)
GAN是一种强大的生成模型,已经在图像、语音和文本等领域有许多成功的应用。其中,SRGAN (Super-Resolution Generative Adversarial Network) [9] 是首个将生成对抗网络用于超分辨率重建的方法,其生成器输入为LR图像,通过感知、对抗和内容损失函数,在与鉴别器对抗的过程中,获得高感知质量的输出。文献 [10] 提出的ESRGAN在SRGAN的基础上用残差密集块(Residual Dense Block, RDB) [4] 作为生成器的基本单元,堆叠多个RDB提取深层特征,并使用激活前的VGG网络 [11] 计算感知损失。ESRGAN不仅能够生成逼真纹理,而且避免了局部伪影,其感知质量达到了一个新的高度。
2.2. Transformer
Transformer最初是为自然语言处理 [12] 构建的,通过多头自注意力模块(MSA)以及前馈多层感知机(MLP)层来捕获单词之间的长距离相关性。Transformer采用序列表示特征,并建立了特征间的全局相关性。近期,Transformer的新成果,例如Vit [13] 、IPT [14] 和ST [15] ,已经显示出了在计算视觉领域的巨大潜力。在ST中,MSA是按窗口计算的,相对于点到点的注意力计算,复杂度是线性的。通过MSA建立的全局依赖关系可以有效地学习图像的自相似信息。由于ST具有性能强、复杂度低和兼容性好的优点,文献 [16] 将ST用于图像超分辨率中,并在性能上超越了基于卷积的方法。
2.3. 多头自注意力机制(MSA)
MSA的结构如图1所示。通过对输入进行多次不同的线性变换,然后将变换后的结果作为不同注意力头的输入。输入被划分为h个子空间,并对每个子空间计算查询向量Q、键向量K和值向量V。对于每个子空间i,注意力计算表示为:
(1)
每个注意力头都会进行权重计算,其中涉及到Q、K和V三者的权重。通过计算Q和K之间的注意力权重矩阵以及与V的乘积,得到当前头的最终注意力输出。最后把所有注意力头的结果拼接,再将其乘上权重W,以获得多头注意力的输出:
(2)
3. 本文方法
3.1. 模型结构
DSTGAN的结构如图2所示,该模型由两部分组成:生成器和鉴别器。生成器接收LR图像作为输入,输出相应的HR图像。然后,将生成的HR图像和真实HR图像分别送入鉴别器进行真假判别。生成器与鉴别器不断进行对抗,直到达到纳什均衡。
3.1.1. 生成器结构
生成器的结构如图2实线框所示,主要包含三个阶段:浅层特征提取、深层特征提取和上采样。在浅层特征提取阶段,生成器通过一个3 × 3卷积将输入的LR图像映射到一个更高维的特征空间。
深层特征提取阶段是生成器的主要阶段。DST是生成器基本单元,其结构如图3所示,由6个ST和3个卷积层组成。ST引入了文献 [15] 的一种Transformer结构,包含多头自注意力(MSA)和多层感知机(MLP)。在进行MSA和MLP之前,分别进行一次层归一化(Layer Normalization),用于将每个输入的均值和方差归一化到相同的范围内,并且以残差的形式连接两部分的输入输出。
在DST中,每两个相邻的ST作为一个整体密集连接到后续每个卷积层中。值得注意的是,DST中密集连接的信息来自Transformer结构,相比卷积层,Transformer结构能够更好地关注全局信息。每次在密集连接后,卷积层会将先前层的信息融合,利用卷积的空间不变性增强Transformer。此外,卷积层的另一个作用是通道进行归一化处理,以便将其输入到下一个ST。一个DST模块总共存在三次密集连接,假设输入的特征图的大小为C × W × H,其中C为通道,W和H分别是宽度和高度。密集连接后的特征图大小分别为2C × W × H、3C × W × H和4C × W × H,最后,这些特征图都经过卷积层归一化到C × W × H。值得一提的是,在输入和输出ST之前,分别进行一次embedding和unembedding操作,将输入数据在图像特征图和Transformer嵌入向量之间进行转换。
人脸包含了丰富的纹理信息,例如毛发、皮肤褶皱、斑点等,这些相似结构可能会在当前图像的全局范围内多次重现,这些重复的信息对重建具有鲁棒性。在深层特征提取阶段,通过堆叠多个DST模块,有助于充分提取特征和学习全局相似信息。
在生成器的上采样阶段,为了达到目标的超分辨率倍数,使用子像素卷积 [17] 的方法对特征图进行上采样。该方法将通道上的像素排列到同一空间的大矩阵上,通过缩减通道数来扩大空间尺度。相较于其它上采样方法,亚像素卷积具有参数少、效率高和学习性强等优点。最终输出生成的HR图像。
3.1.2. 鉴别器结构
关于鉴别器的选择,文献 [9] 和文献 [10] 都采用了基于VGG结构的鉴别器。虽然VGG结构在图像分类和识别方面有出色的表现,但其鉴别图像真假能力有限,无法满足本章对鉴别器性能的需求。因此,本文使用了最近工作中常用的U-Net [18] ,其结构如图2虚线框所示。U-Net结构具有对边缘的敏感性,可以通过真假图像的细微边缘差异来更加准确地识别出真假图像。
在起始阶段,输入特征图经过4个卷积层的处理,通道数逐渐从3增加到512。这些卷积层使用两倍步长的卷积核,每次特征图通道增加时,分辨率都会缩减到原来的四分之一。当通道数达到512后,每次进行卷积操作之前都会将特征图上采样(Bicubic插值)两倍,然后通过卷积操作逐渐将通道数压缩到1,这个过程正好与起始阶段相反。在U-Net的第5、6、7层的特征图分别与3、2、1层的对应尺度的特征图进行跨层连接,这种残差连接可以有效地融合浅层信息,有助于得到更精确的结果。为了增强训练的稳定性,避免出现过度的尖锐和伪影,每次卷积操作之后都会进行一次LeakyRelu激活和谱归一化。
3.1.3. 损失函数
DSTGAN的损失函数包括内容损失、对抗损失和感知损失三部分。下面以x表示输入LR图像,G(x)表示生成器生成的HR图像,y表示真实HR图像。
内容损失:L1损失广泛地使用在超分辨率任务中,它是一种一阶运算,对异常值的敏感度相对较低,另外计算简单、收敛速度快。L1损失通过绝对差值平均和的方式,计算了两个图像间像素级别的差异,内容损失Lcontent表示如下:
(3)
其中N是特征图的像素数量,(i, j)为G(x)和y中对应的坐标。
对抗损失:对抗损失的主要目的是让鉴别器无法区分G(x)与y,文献 [10] 中提到这种损失有助于学习更清晰的边缘和更精细的纹理。鉴别器和生成器各自的对抗损失分别表示为式4和式5,这里计算的是一种相对概率。对于鉴别器来说,它的目标是最大化G(x)与y的概率差异。而对于生成器,它的目标是最小化这个差异。
(4)
(5)
其中
,EG(x)和Ey分别计算了G(x)和y所在mini-batch的平均值。
感知损失:感知损失可以帮助生成器学到更真实、语义性和结构性的特征。为此,引入了训练好的未激活的VGG-19模型,用于计算生成图像和真实图像之间的感知损失,其定义为两者的欧式距离:
(6)
其中N是特征图像素总数,
是特征提取函数。通过比较生成图像和真实图像之间的差异,促使它们向全局内容和结构相似的方向逐渐收敛。
DSTGAN的生成器使用上面三种损失的加权和作为整体损失,表示为:
(7)
其中α,β,λ是权重系数。鉴别器的损失是对抗损失中的
,在训练中,为了避免污染生成器的参数,鉴别器的反向传播与生成器的相互独立。
3.2. 人脸图像退化模型
在图4中,HR和Bicubic两张图像视觉上差异较小,如果只使用Bicubic下采样建立HR/LR图像对,这样训练出的模型仅能学习有限的退化信息,无法充分发挥深度学习模型强大的预测能力。为此,可以进一步退化图像,以建立一个更广阔的从低质量到高质量的映射空间,从而让模型找寻更优的重建结果。
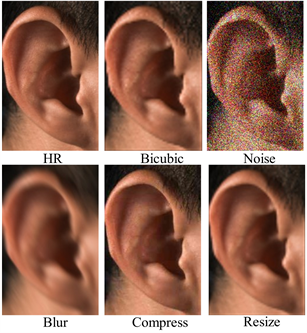
Figure 4. Effect of various degradations
图4. 各种退化的效果
本文的退化模型有4种退化方式,分别是噪声、模糊、压缩和放缩。不同退化方式的效果也列在图4中,噪声为泊松噪声和高斯噪声,模糊是高斯滤波器,压缩是JPEG压缩,放缩通过多次尺度改变来实现。退化模型的退化策略是由本文提出的随机退化算法(详见算法1)决定的,该算法主要考虑以下几个因素:1) 一张图像很难同时包含所有的退化情况,比较常见的退化有压缩和放缩,因此压缩和放缩的阈值k2和k3需要适当放大。而噪声的情况相对较少,因此噪声的阈值k0被设置得比较小;2) 同一张图片在不同的退化顺序下得到的结果是不同的,因此随机退化算法一开始就设置一个随机序列来决定退化的顺序;3) 由于实际中退化的强度通常是正态分布的,因此对每种退化方式都设置了一个强度系数,且该系数是正态分布随机数。通过该随机退化算法,本文的退化模型可以生成理论上无限多的LR和HR的图像配对,这大大扩展了数据集。
4. 实验部分
4.1. 数据集和评估指标
目前开源的高质量人脸图像数据集FFHQ [19] (图5上层)。尽管图5是筛选出的高质量图像,但在细节方面仍有不足。经过退化处理后,图像细节进一步减少,这会影响模型对纹理细节的学习。因此,在本文工作中拍摄了大量超高分辨人脸图像用于训练超分辨率模型。在拍摄过程中,搭设了光场、幕布等设备,可以调节多种色温及亮度。使用海康威视MV-CE200-10GM工业摄像头拍摄了100张2000 w像素的超高分辨率的人脸图像,并使用康成800 RYS-800WAF拍摄了分辨率相对较低的5张800 w像素的图像用于图像测试。图5下层是截取的自摄图像,相比FFHQ数据集,人脸的纹理明显更加清晰了。此外,还使用了公开数据集:DIV2K、Set5、Set14、B100以及Urban100,表1给出了具体的数据集组成。
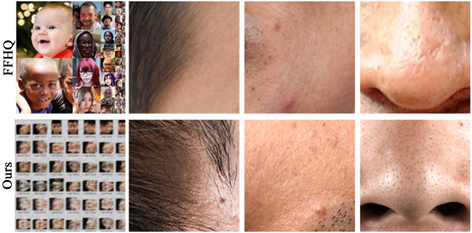
Figure 5. Comparison of FFHQ dataset and this paper’s dataset
图5. FFHQ数据集和本文数据集对比
4.2. 实施细节
在训练过程中,Batch Size设置为32,超分辨率的倍数固定为4。输入的HR图像是随机裁剪的64 × 64大小的块,经过所提出的退化模型生成LR图像。DST的窗口大小为8。生成器总共包含6个DST模块,其损失函数的权重分别为
。随机退化算法的参数为
,
,
,
。使用ADAM优化器,其中β_1 = 0.9,β_2 = 0.999,生成器和鉴别器的学习率均为5e−3,并且每迭代5000轮衰减一半,总共训练30,000轮。
本文方法均使用Pytorch框架实现,并在操作系统为Ubuntu v18.04的服务器上训练,其中CPU为Intel Xeon Gold 6140,内存为64 GB,显卡为6块显存容量为11264MB的NVIDIA GTX1080Ti。
4.3. 实验结果分析
图6给出了DSTGAN与其他模型的重建结果对比,包括RDN [4] 、ESRGAN [10] 和SwinIR [16] 。从图中可以看出,RDN、ESRGAN和SwinIR的表现差异不大。然而,这些模型在重建头发、睫毛等高频纹理方面存在困难,并且会出现明显的锯齿感,从而导致整体效果不够自然和真实。这些问题主要原因是LR图像中存在较多的缺失像素,导致线条的过渡不够光滑。仔细观察RDN和ESRGAN的结果,会发现图像上存在一些不自然的亮点和噪声,而SwinIR相对较少。这是因为SwinIR中采用基于全局的自注意力机制,考虑了自身的相似信息,避免了这部分的不自然,这也是本文选用ST结构的原因。
图6最后一列对应DSTGAN的重建结果。DSTGAN对LR图像中无法辨认的模糊区域进行了光滑处理,并消除了模糊感,从而使毛发的边界更加清晰,视觉上更加流畅和连贯。在处理皮肤的纹理时,通过突出皮肤的褶皱来增强其视觉效果。综合来看,DSTGAN在纹理和细节方面的恢复效果更精细,其重建质量和视觉观感优于其他模型。
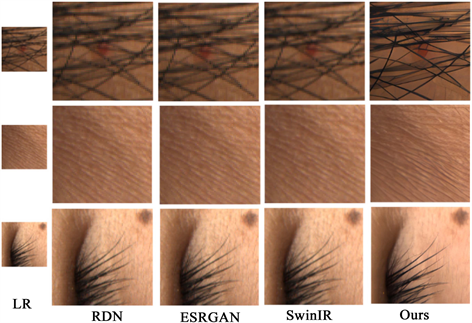
Figure 6. Partial comparison between the results of this model and other models
图6. 本文模型和其他模型的结果局部对比
4.4. 消融实验
4.4.1
. 退化模型有效性分析
为了验证所提图像随机退化模型的有效性,进行了多项消融实验,针对不同退化强度进行了比较。实验结果如图7所示,其中,通用的Bicubic下采样方法作为弱退化模型,强度系数减半的图像随机退化模型作为等半退化模型,以及实际的随机退化模型。从图中可以看出,弱退化模型视觉效果与上一节的RDN和ESRGAN类似,整体上具有较强的模糊感,边缘细节不够清晰。等半退化模型的效果有所改善,但仍存在一定的朦胧感。相比之下,本文实际的退化模型表现相对更好,进一步提升了头发和皮肤纹理的重建质量,在保留细节的同时带来更具有鉴别性的效果。
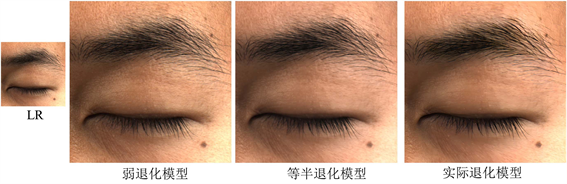
Figure 7. Degradation model validity ablation experiment
图7. 退化模型有效性消融实验
4.4.2. DST有效性分析
为了验证DST结构的有效性,比较了RDB、ST以及DST三种生成器基本单元的性能,使用PSNR和SSIM这两个指标来定量评估性能,其中PSNR和SSIM数值均越大性能越好。为了减少退化模型的随机性带来的影响,采用Bicubic方法进行下采样,即作为一个通用的模块来验证效果,结果如表2所示。将生成器的基本单元从RDB更换为ST后,PSNR提升了0.36 dB。相比文献 [10] 中使用的RDB,ST建立了全局上下文依赖关系,因此表现更佳。表中最后一行是DST的评估结果,该结构在ST的基础上进一步提高了性能,证明DST中的密集连接是有效的。

Table 2. Comparison experiments of different generator basic units
表2. 不同生成器基本单元对比实验
4.4.3
. DSTGAN整体有效性分析
为了进一步评估DSTGAN模型的整体有效性,在基准数据集Set5、Set14、B100和Urban100上将DSTGAN与目前流行的其他几个生成对抗网络模型进行了× 4超分辨率的定量比较,包括SRGAN [9] 、ESRGAN [10] 和NatSRGAN [20] 。由于退化模型对PSNR及SSIM指标的影响较大,为了公平起见,DSTGAN使用与其他几种模型相同的退化方式,即Bicubic下采样,实验结果如表3所示。DSTGAN在所有测试集上都取得了最好成绩。与次好性能的NatSRGAN相比,DSTGAN在所有数据集上的PSNR分别提升了0.16 dB、0.36 dB、0.23 dB及0.27 dB,在SSIM指标上分别提升了0.0049、0.0142、0.0127及0.0104。此外,相比第一个生成对抗网络方法SRGAN,DSTGAN性能的提升较大,特别是在Urban100数据集上相比SRGAN在PSNR和SSIM指标上分别提升了2.19 dB和0.0794。实验结果表明,DSTGAN作为一个普通的生成对抗网络超分辨率模型依旧有着出色的性能。
Table 3. Quantitative comparison of DSTGAN and other models (PSNR/SSIM)
表3. DSTGAN和其他模型的定量比较(PSNR/SSIM)
5. 结束语
在本文中,结合生成对抗网络和Transformer模型,构建了一种用于人脸图像超分辨率重建模型DSTGAN。使用DST模块作为生成器的基本单元,以提升模型对深层特征的提取能力。此外,提出了一种图像退化模型,用于实时生成训练的图像对,从而让模型学习更广泛的映射关系。通过主观视觉评价,所提模型在视觉感知方面表现最佳,并通过多项消融实验验证了模型的有效性。
综上所述,所提模型可用于生成具有良好视觉感知的人脸图像,并可用于实际场景的图像优化。但是,目前该模型对算力和存储资源的要求较高,限制了其应用场景。因此,在未来的工作中,将致力于构建一个可移植性强的模型,并且提高对其他图像类别的适用性。