1. 介绍
睡眠是评价人类生活质量和身体健康的标准之一,并且了解睡眠质量和结构对人类的健康至关重要。在人类的生命长河中,有1/3的时光都在休息。睡眠障碍(失眠、昼夜节律紊乱、嗜睡和阻塞性睡眠呼吸暂停)是导致人类白天嗜睡和夜间失眠、认知和情绪障碍、皮肤衰老加速和死亡率增加的危害性因素之一 [1] 。因此,对睡眠质量的准确评估是认识睡眠障碍并采取有效干预措施的关键。
迄今为止,对睡眠质量的评估主要是基于脑电信号的分析,但是标准的睡眠阶段测定需要在昂贵的和劳动密集型的多导睡眠图(PSG)中使用脑电图(EEG)信号,这就需要专用设备和实验室以及临床专家的专业知识。最近的研究人员没有依赖PSG的EEG信号,而是专注于呼吸信号,因为他们既可以显示不同的睡眠阶段,也可以在大量低成本的简化设备中捕获 [2] 。这种方法很适用于移动和物联网(IoT)医疗保健、智能家居中的睡眠健康监测 [3] 。目前,医生在诊断睡眠障碍相关疾病时的首要工作是对患者进行睡眠阶段分期 [4] [5] ,也称为睡眠评分。虽然有很多标准来划分睡眠阶段,但最常见的是四类睡眠阶段标准,它包括醒觉(Wake)、浅睡眠(Light Sleep)、深睡眠(Deep Sleep)和快速眼动(Rapid Eye Movement) [6] 对于一些更精细的测量,把睡眠阶段分成五类也是我们研究的重点。2007年,根据AASM规则(American Academy of Sleep Medicine)人们可以把一个人的生活划分成三个不同的时期:分为清醒期(Wake)、非快速眼动期(N1, N2, N3)和快速眼动期(Rapid Eye Movement) [7] [8] ,其中N1、N2和N3分别代表清醒期到睡眠阶段的过渡、浅睡和深度睡眠。为了更好地了解志愿者的睡眠状况,我们应该对他们每个睡眠阶段的多导睡眠图(PSG)进行全面的监测,其中的数据包括了,脑电图(EEG)、心电图(ECG)、眼电图(EOG)、肌电图(EMG)、呼吸信号等。在基于AASM规则下 [8] ,为PSG中的每30秒数据给出睡眠分类标签(W, N1, N2, N3, R),不同标签代表不同的睡眠状态 [9] [10] 。然而,PSG的收集和整理需志愿者到睡眠实验室并由睡眠专家分析。此外,传统的人工评分操作复杂、耗时、且评分准确性易受睡眠专家主观因素影响。
为了解决上述问题,近年来许多科研工作者致力于研发睡眠自动评分模型。研究者们利用Sleep-EDF数据库、Dreams Subjects数据库、SHHS数据库做出了睡眠自动分期模型,具体准确率如表1所示:

Table 1. Accuracy of automatic sleep staging models
表1. 睡眠自动分期模型的准确率
1998年,N.E. Huang、Z. Wu等学者首次将EMD (经验模式分解)引入美国国家宇航局,并以此为基础,开发了一种全新的、具备高度灵活性的自适应性信息时频数据处理方法,可以有效地实现对复杂的非线性、非平稳的数据分析 [11] ,经验模态分解法(EMD)是将信号分解成一些列特征时间尺度(IMF)分量,使得各IMF分量是窄带信号,简单的说就是将一个复杂信号分解成多个简单信号的过程。与小波变换不同,EMD的分解模式基于信息的实际情况,能够实现对不断变化的环境的快速响应。这种方法用于解决复杂的、不均匀、非线性的信号,特别适用于时频分析。自1998年由Huang首次提出以来,EMD(模拟数据集)一直受到广泛的重视,并且已经有所突出发现和进展。这种方法的特色在于无需依赖预先设计的函数,就能够通过对特定信息进行加工,从而产生固有模态的函数。这种方法能够解决复杂、变化快速、波形不规则等问题,并且能够提供较高的信噪比和较佳的时频聚焦能力 [12] 。
与EMD不同,EEMD拥有更强大的自我调节功能,它不仅能够捕捉到复杂的、不断发展的信息,而且还能够准确地预测和识别出复杂的、不断发展的、不断改进的信息,因此,EEMD已成为一种极为普遍的、高效的、基础的、多维的、复杂的信息处理技术。
其次,从原始呼吸信号和分解出来的6个简单信号中提取关于统计、时域和非线性等方面的9个特征。利用长短期记忆算法(LSTM)构建分类模型。经过测试我们发现,对SHHS数据库中呼吸信号进行4类和5类睡眠分期的任务中,我们的模型准确率分别达到89.22%,88.43%。我们的模型的准确度分别达到89.22%和88.43%。这种自动化的分期模型既能够克服人工分期的延迟,又能够抵抗外界环境的变化,并保持良好的分类精度。
本文工作流程如图1所示。首先,我们把SHHS数据库中的6000多个呼吸信号分为两组,第一组是训练组,也就是我们在每个睡眠阶段随机选择85%的呼吸信号特征来生成训练集,其余15%作为测试组。其次,利用四阶巴特沃斯滤波器对呼吸信号进行过滤的预处理,再用经验模态分解算法(EMD)分解出6个简单信号和9个特征。特征向量导入LSTM分类模型中进行交叉验证训练和测试。特征提取后,使用5倍交叉验证对LSTM分类器进行训练和测试。
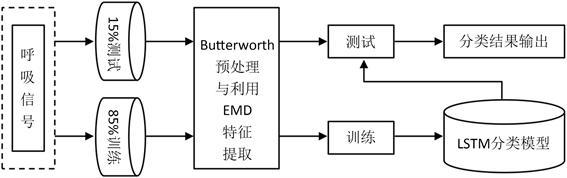
Figure 1. Workflow diagram of this paper
图1. 本文的工作流程图
2. 实验数据与方法
2.1. 实验数据
本文研究的SHHS (睡眠心脏健康研究)数据库是一个关于睡眠障碍和心血管疾病之间关系的长期研究的数据集合。该数据库包含了6000多名参与者的睡眠研究结果、病史、人口统计信息和心血管评估等信息。它是研究睡眠障碍对心血管健康影响的研究人员的宝贵资源,并为有关睡眠呼吸暂停、高血压和其他心血管疾病的研究提供了全面的数据收集。SHHS数据库对合格的研究人员是公开的。这些数据包括EEG、EOG、EMG、ECG、鼻腔气流和呼吸信号、SaO2和心率测量,以及注释的睡眠阶段、呼吸事件、EEG唤醒等。
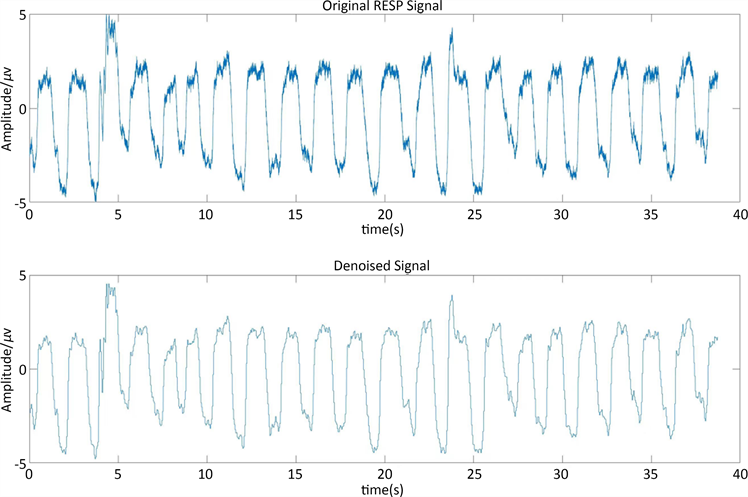
Figure 2. Raw respiratory signal and filtered respiratory signal
图2. 原始呼吸信号和滤波处理后的呼吸信号
在这项工作中,我们使用呼吸信号来划分睡眠阶段。呼吸信号是指呼吸时由呼吸肌产生的电信号。这些信号可以用放置在胸部或腹部的传感器测量,并提供有关呼吸模式和效率的宝贵信息。
呼吸信号反映了参与吸气的肌肉的活动。以及呼气活动,它反映了参与呼气的肌肉的活动。通过分析这些信号,临床医生和研究人员可以深入了解呼吸肌的力量和协调,以及呼吸系统的阻力和顺应性。
2.2. 数据预处理
首先,利用4阶巴特沃斯高通滤波器(Butterworth)对分割好的各30秒原始呼吸信号进行滤波,只允许频率范围在0.5~50 Hz的信号成分通过。其次,由于小波分析在时域和频域上具有很好的去噪性能,本文中,将巴特沃斯高通滤波后的信号经过小波变换去噪。实验表明,使用db4小波基和分解层数为6时效果比较好 [13] (图2)。
2.3. 经验模态分解算法(EMD)
经验模式分解概念通俗易懂得讲是确定适当的时间尺度来揭示信号的物理特性。换句话讲我们在试图用EMD的方法来提取某些功能即IMF (具体如下)。
经验模态分解法(EMD)是将我们的呼吸信号分解成一系列特征时间尺度(IMF)分量,使得各IMF分量都具有较低的频率范围,并且有较低的频率阈值。即IMF分量必须满足下面两个条件:在整个信号长度上,极值点和过零点的数目必须相等或者至多只相差一个;在任意时刻,由极大值点定义的上包络线和由极小值点定义的下包络线的平均值为零,即信号的上下包络线关于时间轴对称。简单的说就是将一个复杂信号分解成多个简单信号的过程。同小波变换相比,EMD方法是完全根据信号数据本身来确定需要分解出多少个IMF,因此更加的具有自适应性。
EMD的分解过程其实是如下的筛选过程,EMD方法的实现是要满足两个基本条件的过程。
1、信号至少要存在两个极值点,要找出局部最大值和最小值。
2、在两个极端点之间,时间尺度的变化会影响到他们的特征。
由于EMD的方法是自适应的,分解的基础是基于数据并从数据中得出。在EMD方法中,数据X(t) 被分解成IMFs,cj [12]
(1)
即rn代表着x(t)的残余值,在提取了n个IMF以后。而n个IMF则表示一种不同振幅、不同频率的简单震荡函数。
EMD分解步骤如下:
1、通过分析原始信号的极值点,并利用曲线拟合技术将其组合成一条上下包络线,从而将其完整地包裹起来。
2、通过上下包络线,我们可以计算出均值曲线m(t)的均值,然后再用原始信号f(t)减去m(t),最终得到H(t)即为IMF。
3、理论上讲,由于第一二步得到的IMF通常不会满足IMF的两个条件,因此必须反复执行第一二步,直至SD达到一个特定阈值,一般来说,这个阈值应该在0.2~0.3之间,当SD低于这个阈值时,才可以停止对H1(t)进行第一、第二个步骤。这样得到的第一个满足条件的是H1(t)就是IMF [14] 。
(2)
4、通过执行1、2、3步骤,直至残差r(t)达到预先设定的条件,即f(t)-H(t),
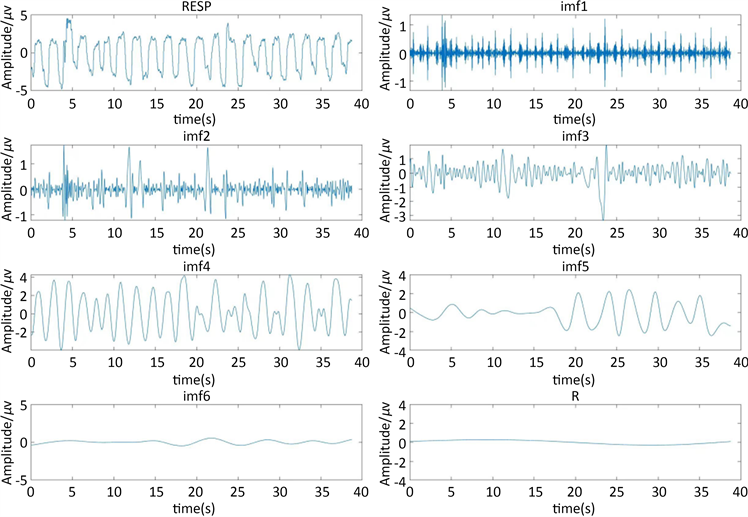
Figure 3. EMD decomposition of respiratory signals
图3. 呼吸信号的EMD分解
经过我们用EMD方法分解之后,我们可以分析得出从IMF1~IMF6频率以此降低。R为残差信号保持在0的周围,这说明EMD对呼吸信号的分解性较强(图3)。
2.4. 特征提取
在本文中,我们提取了原始呼吸信号,以及经过预处理并由经验模态分解算法分解出的6个简单信号的9个特征:均值(ME)、偏度(SK)、峰度(KU)、过零率(Zcr)、排列熵(PE)、样本熵(SE)、灵活性(HA)、复杂度(HC)和流动性(HM)。设定
为一时间序列,下面给出上述9个特征的数学定义。
2.4.1. 均值(ME)、偏度(SK)、峰度(KU)
均值(ME)和方差(
)是常用的统计量,可充分的使用数据,适应性强,但容易受到极端值的影响。偏度(SK)可以用来衡量实值变量概率分布的不对称程度,若偏度介于−0.5至0.5之间,则表明数据具有较高的对称性。峰度(KU)是对实值变量的概率分布峰态的度量 [15] 。KU可以描述数据分布形态的陡缓程度,因此可以用KU来检验数据分布的正态性。
(3)
(4)
(5)
(6)
2.4.2. 过零率(Zcr)
对于离散信号,图像单位时间内穿过时间轴的次数称为过零率(Zcr),它是信号采样点符号的变化率。这种变化响应于信号频谱的变化 [16] ,Zcr特性已被广泛使用,Zcr越大,相应的频率就越高。Zcr的计算可以用等式(7)~(8)来表示。
(7)
其中
为指标函数,定义为:
(8)
2.4.3. 样本熵(SE)
SE由Richman、Moorman等学者在2000年提出,它可以更准确地反映出时间序列的复杂性,且计算不依赖数据的长度。参数m和r的变化对样本熵的影响程度相同,因此,SE具有很好的一致性。SE被广泛应用于脑电信号和呼吸信号等时间序列的分析 [17] 。
为了计算SE,首先将输入信号S(n)向量重构为M − m + 1个m维向量
,如(9)所示。
(9)
距离
定义为向量
和
之间相应位置元素差的绝对值的最大值,公式(10)中
。
(10)
和
分别定义为m和m + 1维重构向量中距离不超过预定参数r的向量对的数量。
(11)
其中m是重构维数,本文中,r设置为标准差的0.15倍,m设置为2。
2.4.4. 排列熵(PE)
PE是一种对信号微弱变化具有放大效应的动力学突变检测方法,它可以快速和精准地对信号的突变时刻做出响应,是衡量信号复杂度的一个标准 [18] 。首先,需要将输入信号S(n)重构为K行P列的矩阵
。其次,对矩阵
的每一行向量c都按照升序排列,记录升序排列后的行向量v中元素在向量c中对应的位置序列ID,例如向量
,升序排列后
,得到位置序列为
。最后,计算出每一种位置序列出现次数与P的全排列的比值
。本文中,P被设置为4,则P的全排列为24。
(12)
2.4.5. Hjorth参数(HA, HC, HM)
Hjorth [19] 参数包括活动性(HA)、复杂性(HC)和移动性(HM)。通过直观的观察,我们可以清楚地感受到呼吸信号的波动强度、斜率以及斜率变化的幅度。
(13)
(14)
(15)
其中,
表示
和
对应位置元素的差。
是
的平均值,ME是
的平均值。同理,
表示
和
对应位置元素的差,
是
的平均值。HA实际上是输入信号的
,HM代表主导频率,HC代表信号带宽。因此,Hjorth参数既能反应输入信号在时域特征和也能反应频域特征 [18] [19] 。
2.5. 分类算法
本文中,把睡眠阶段分为5类(AWA, S1, S2, DS, REM)和4类(S1和S2合并为LS)。我们将分割好的每30秒原始呼吸和分解得到的6个简单信号分别提取9个特征,把特征组合成一行维数为63的向量,并将特征向量导入LSTM分类模型中进行交叉验证训练和测试。特征提取后,使用5倍交叉验证对LSTM分类器进行训练和测试。我们使用了两种输出方案,一种是包含AWA、S1、S2、DS和REM5个类,另一种是将S1和S2组合为LS,得到4个类。注意对于每个数据库,本文中,我们在每个睡眠阶段随机选择85%的呼吸信号特征来生成训练集,其余15%作为测试集。
长短期记忆网络LSTM
长短期记忆网络(Long Short-Term Memory networks, LSTM)是一种特殊的RNN。在人工智能领域,当我们来处理语言文字的时候,我们会经常使用循环神经网络RNN。它是一种拥有短期记忆的神经网络,常用于处理序列数据 [20] 。RNN可以用上下文搜索有用的信息,然后做出判断。但通常,RNN会出现比较严重的问题,例如:小明出生在中国,并且在那里长大,他的家乡在黄土高坡,那里的风景很美丽,所以小明说哪国语?如果用RNN的方法,RNN就要一直往前推,一直推到最开头的部分,发现小明是中国人。所以推断出他讲中文。这个现象就是“长依赖问题”。如果这个句子很长,RNN可能把有用的信息舍弃掉,从而判断失误。幸运的是科学家将RNN进行了改造升级,提出了长短期记忆网络,他们由
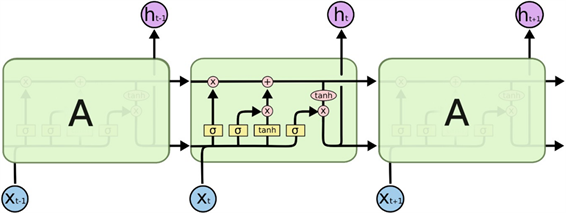
Figure 4. The repetition module in the LSTM contains four interacting layers
图4. LSTM中的重复模块包含四个相互作用的层
Hochreiter & Schmidhuber (1997)引入。LSTM提出的目的就是为了解决长期依赖问题,换句话说,它可以记住更长时间段的重要信息。与RNN结构不同,LSTM的神经网络层较为复杂。LSTM有三个门结构,分别为遗忘门,输入门和输出门 [21] (图4)。
第一步:
LSTM的第一步是决定我们要从这个过程中丢弃那些信息。这个决定是由一个“遗忘门作用层”的sigmoid层做出的,这时起到了LSTM的第一步是决定我们要从细胞状态中丢弃哪些信息。它查看前一个ht-1和当前输出xt,并为状态Ct-1中的每个数字中输出一个介于0和1之间的数字。1表示“完全保留”,而0表示“完全丢弃”这个公示表示了遗忘门的工作原理。
(16)
第二步:
LSTM的第二步是决定我们要从这个过程中储存那些新信息。tanh函数层可以从当前的向量中提取出有价值的信息,而sigmoid函数层则可以根据需要调整这些信息,使其达到最佳的状态。用一下公示来解释一下此过程。
(17)
(18)
第三步: 其实第三步是将第一步和第二步结合起来,进行一个数据和信息更新的过程。我们上一步的状态Ct-1更新为新的状态Ct。我们将上一步的状态乘以ft,忘记了我们之前决定忘记的信息。
(19)
第四步:
在LSTM的第三步中,我们需要确定我们的输出内容。为此,我们需要创建一个sigmoid层,它会根据我们的需求来确定哪些内容需要输出。接着,我们可以使用tanh函数来计算单元格的状态,并将其与sigmoid门的输出相比较,从而确定最终的输出内容。
(20)
(21)
2.6. 模型评价
LSTM分类器的性能可以通过计算分类的准确率、特异性和灵敏度来评估。准确率是混淆矩阵(Q)主对角线元素的和与样本总数(SUM)的比值。
(22)
(23)
(24)
其中,True Positive (TP),样本的真实类别是正类,分类模型将其预测为正类。False Negative (FN)为样本的真实类别是正类,分类模型将其预测为负类。False Positive (FP),样本的真实类别是负类,模型将其预测为正类。True Negative (TN),样本的真实类别是负类,分类模型将其预测为负类。kappa系数通常被用来衡量自动评分和传统手动评分之间的一致性。Landis和Koch等人认为,kappa数大于0.80的分类器具有接近完美的分类精度 [22] 。图5为SHHS数据库4分类的混淆矩阵,对角线的值表示分类器对该类别预测正确的个数,每一列纵轴表示这个类别真实的样本数,例如从第一列可以得W期样本数为2455。因此,总样本数(SUM)为混淆矩阵4列样本数之和,SUM = 4556。

Figure 5. The SHHS database 4 classification confusion matrix
图5. SHHS数据库4分类的混淆矩阵
以W期为例,从混淆矩阵第一列可得W期共有1000个样本,其中有2342个样本被分类模型预测为W期,而有82个样本被预测为LS期,4个样本被预测为N3期,27个样本被预测为R期。因此,对于W期这个类别TP = 2342 (正确预测为W期的样本数),FN = 113 (W期被预测为其它类别的样本数)。
从混淆矩阵第一行得出分类模型将一共将2363个样本预测为W期,其中预测正确的有2342个样本,而错误地将LS期、N3期和R期预测为W期的共有21个样本。因此,对于W期这个类别FP = 21 (其它类别被错误预测为W期的样本数)。TN = 总样本数 − (TP + FN + FP),对于W期这个类别TN = 2078。通过公式(21)和(22)计算出W期的specificity = 99.00%,sensitivity = 95.40%。本文中,4类和5类睡眠分期中每个类别的specificity和sensitivity计算结果在表2和表3中。
3. 结果
3.1. 分类结果分析
为了提高模型的分类准确性和防止过拟合,不仅需要对训练数据进行高效的处理,还需要调试很多的模型参数(gamma、树深度、学习率、叶子数、列样本率、子样本率、训练次数)。本文中,对SHHS数据库呼吸信号进行5类和4类睡眠阶段分类的准确性和kappa系数如表4所示。
从表4数据可以看出,4类分类器模型比5类分类器模型具有更好分类准确率。SHHS数据库对应的4分类的准确率为89.22%,kappa系数为0.8412,且kappa系数都大于0.8,睡眠专家认为kappa数大于0.80的分类器具有接近完美的分类精度。
Table 2. Sensitivity and specificity of the four classifications
表2. 四分类的灵敏度和特异性
Table 3. Sensitivity and specificity of the five classifications
表3. 五分类的灵敏度和特异性
Table 4. SHHS database sleep classification model accuracy and kappa coefficient
表4. SHHS数据库睡眠分类模型准确率和kappa系数
通过表2和表3得出,在进行4分类和5分类的实验中,分类模型对每个睡眠阶段的识别和分类都是相当精准的,且分类模型对清醒期的灵敏度和特异性较强。然而,通过表3得出分类模型对S1睡眠阶段的分类灵敏度最低,但对AWA,S2,DS睡眠阶段分类整体表现处于80%以上。因此,实验结果进一步验证了本文分类模型的普遍适用性和稳健性。
3.2. 特征重要性分析结果
特征对睡眠阶段的分类是至关重要的。因此,需要对特征的重要性进行计算和评估 [23] 。信息增益是

Figure 6. Relative information gain of Sleep-EDF database features in the LSTM
图6. LSTM中Sleep-EDF数据库特征的相对信息增益
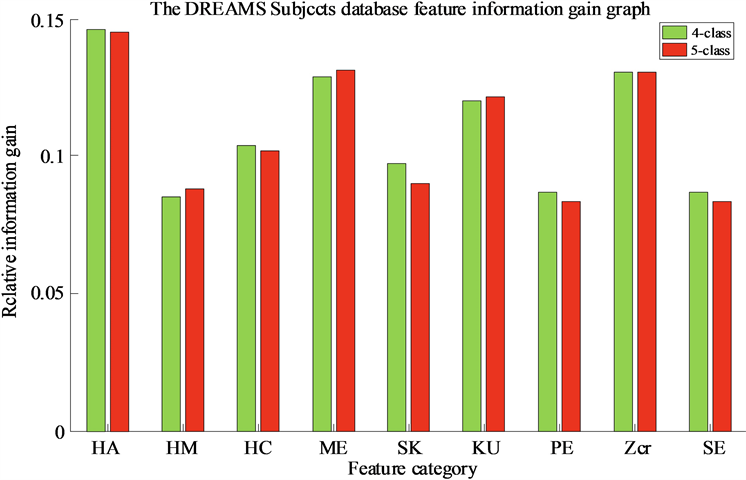
Figure 7. Relative information gain of DREAMS database features in the LSTM
图7. LSTM中DREAMS数据库特征的相对信息增益
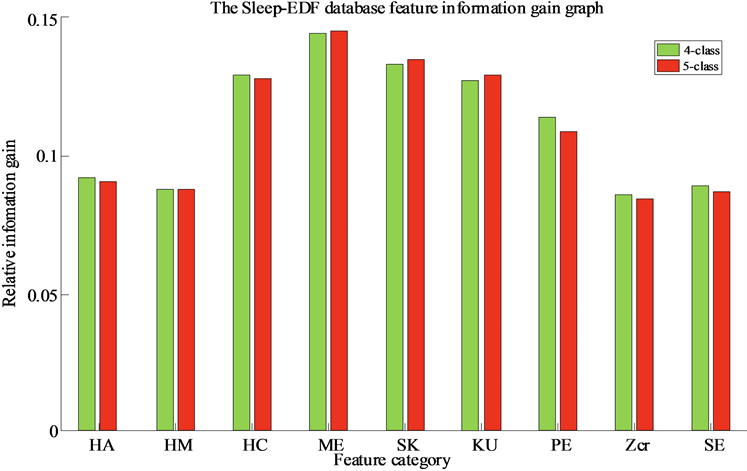
Figure 8. Relative information gain of SHHS database features in the LSTM
图8. LSTM中SHHS数据库特征的相对信息增益
评价特征重要性的最佳选择,它以相对于总信息增益的比例来衡量,比例越大,特征在分类模型中的作用就越重要。接下来,本文计算了Sleep-EDF数据库、DREAMS Subjects数据库和SHHS数据库的呼吸信号特征(HA、HM、HC、Zcr、ME、SK、KU、SE、PE)的相对信息增益,如图6~8所示。
从图6~8可以看出,特征(HC, ME, SK, KU, PE)在Sleep-EDF数据库中具有较高的相对信息增益,因此,在分类模型中更为活跃。特征(HA, ME, Zcr, KU)在DREAMS Subjects数据库的分类模型中更为活跃,而特征Zcr的相对信息增益最低,适应能力较差。特征(HC, ME, SK, KU, PE)在SHHS数据库的分类模型中更为活跃。上述分析得出在三个数据库中表现最活跃的特征是(ME, KU),其次是特性(SK, PE)。
4. 讨论
呼吸信号的分解和特征提取是获得准确睡眠评分的关键。在本文中,我们把EMD作为非线性和非平稳据的分析处理的一种选择,它是一种新的处理非平稳信号的方法。大多数研究人员在没有对呼吸进行预处理(滤波、降噪)的情况下,对DREAMS Subjects数据库中呼吸信号进行4类和5类睡眠分期的平均准确率分别为83.39%和80.06%,相比于Sleep-EDF数据库和SHHS数据库,准确率是最低的。本文采用4阶巴特沃斯高通滤波器和小波去噪技术对上述三个数据库中呼吸信号进行了预处理。我们对DREAMS Subjects数据库中呼吸信号进行4类和5类睡眠分期中,准确率分别为89.25%和84.25%。实验表明,呼吸信号的预处理至关重要。
ME和KU主要反映信号的平均值和峰度,图4~6显示ME和KU与睡眠分期高度相关。此外,SK、PE和HA对模型分类有显著贡献。在本文中,我们探索使用新组合的九个特征(KU,SK,HA,HM,HC、Zcr,SE和PE)进行分类,这在很大程度上提高了模型的评分性能。在Hassan等人之前的工作中,分类器中只使用了脑电信号的4个统计特征 [24] ,即ME、HA、SK和KU,然而分类器的分类准确率平均下降了4.24%。多数研究方法在随着数据库变化和实验数据量的增加,准确率没有升高,反而有明显降低。然而,我们的研究方法随之改变,平均准确率保持在90%左右。更加验证了本文研究方法的可靠性和普遍性。我们还了解到,利用xgboost,catboost或者cfc算法有可能对利用呼吸信号进行睡眠分类的准确率更高,希望以后在算法上更加优化。
本文中,实验的处理器为Intel(R) Core(TM) i7-8650U CPU @ 1.90 GHz 2.11 GHz CPU 16 GB,并使用了Matlab和Python两个工具来完成实验。我们对一个30秒呼吸信号的分解和分类进行了耗时计算,实验过程中NSP算法分解耗时0.101秒,睡眠阶段分类耗时0.1秒。因此,对呼吸信号分解的高计算效率和睡眠评分的高稳定性为可穿戴设备的开发带来了良好的前景。