1. 引言
糖尿病DM (Diabetes Mellitus)是由于胰岛素分泌不足或胰岛素抵抗导致血糖水平或血糖偏高而引起的慢性代谢性疾病。如果不尽早介入治疗,糖尿病会严重影响个人的健康问题,如乳酸性酸中毒、肾衰竭、低血糖昏迷、重度感染等。国际糖尿病联盟IDF (International Diabetes Federation)于2021年12月6日正式发布全球糖尿病地图(IDF Diabetes Atlas)第10版 [1] ,根据最新报告显示,2021年全球约有5.37亿成人(20~79岁)患有糖尿病,占全球该年龄段人口的10.5%,其中约90%是II型糖尿病患者。糖尿病的患病率仍在上升,预计2045年将增加到7.83亿,患病率为12.2%。中国有1.41亿人的成年糖尿病患者居世界首位,患病率也比世界水平略高,约为13% [2] 。
糖尿病已经成为全世界威胁人类健康的重大慢性疾病之一,预防和控制糖尿病发生已经成为全世界致力解决且迫在眉睫的问题。医疗大数据的增加和机器学习算法的发展,为检测及诊断糖尿病提供了新的途径和方法。近年来,许多的研究工作者基于数据驱动的方法对糖尿病分类预测进行了研究。目前,基于数据驱动的糖尿病分类研究主要包括基于传统机器学习和基于深度学习的分类预测研究。Malviya等人使用随机森林RF (Random Forest)、AdaBoost、支持向量机SVM (Support Vector Machine)、极限树(ExtraTree)等传统机器学习模型对糖尿病数据进行分类预测,研究结果表明ExtraTree效果优于其他分类模型 [3] 。Tigga等人基于收集的数据和PIMA数据集,采用logistic回归、朴素贝叶斯、随机森林等机器学习算法来预测糖尿病并对比分析实验结果,得出随机森林分类效果最好的结论 [4] 。随着机器学习的发展和在医疗数据中的广泛使用,研究者通过嵌入优化算法和集成多个单分类器等手段提高模型的预测精度。张春富等提出的基于遗传算法的Xgboost (GA-Xgboost)模型,使用GA的强全局搜索能力优化Xgboost,提高其收敛速度,使得GA-Xgboost模型在糖尿病风险预测任务中性能优于线性回归、DT、SVM及NN等模型 [5] 。Ali等使用KNN、朴素贝叶斯NB (Nave Bayes)、线性判别分析、决策树作为基本分类器,随机森林作为元分类器,构建堆叠的集成分类器进行了糖尿病风险研究 [6] ,也有研究者采用其他的模型集成方法基于各种机器学习方法构建糖尿病分类模型,发现集成的分类器性能比单个分类器显著 [7] [8] 。尽管基于传统机器学习的糖尿病预测已取得了相当好的准确率,支持向量机具有严格的理论基础和数学基础,可避免局部最小问题,且小样本学习具有较强的泛化能力。然而,支持向量机的分类性能对参数选择比较敏感,实际应用中存在依靠经验或试算方法确定参数的局限性。这在一定程度上限制了模型的泛化能力。传统的机器学习模型架构简单、参数有限,适合比较简单的分类预测场景,不能挖掘大数据中深层的、隐含的时空相关性,故对复杂数据的分类预测能力有限。相对来说,深度学习通过监督学习或者无监督学习自动学习复杂数据中的模式并提取数据特征,其强大的分层特征学习能力在各种机器学习任务中取得了巨大的成功 [9] [10] 。
深度学习是实现人工智能的重要技术之一。近年来,深度学习被广泛应用于计算机视觉、机器翻译与语音识别、信息检索和医学诊断等领域。深度学习模型是通过卷积神经网络结构提取数据深层次特征,实现网络端到端的训练,通过不断优化网络参数使得模型具有更好预测能力。Joseph等开发了一个基于贝叶斯优化、引入注意力机制的可解释的TabNet模型进行糖尿病的预测分类 [11] 。TabNet架构可进行特征重要性分析,用于确定对糖尿病分类最重要的特征,该模型结合贝叶斯优化和TabNet的优点,对有关诊断提供有贡献的潜在因素的见解,以确保医生和患者理解模型预测的原因。该模型的缺点是训练时间长且仅适用于表格数据。Liu等人针对糖尿病分类预测,提出一种支持图卷积神经网络的双流学习架构,通过临床数据证明了所提方法的有效性 [12] 。Bala等采用极限树和随机森林模型对糖尿病的特征进行筛选,然后构建基于深度神经网络的分类预测模型,以PIMA糖尿病数据集为基础验证了模型的有效性,并与多种基线模型进行比较,结果表明所提模型分类效果显著 [13] 。Kannadasan等使用堆叠的自动编码器训练网络层,提取数据中的隐藏特征,然后加入softmax层对数据集进行分类,最后利用训练数据集的监督反向传播方式对网络进行微调,构建了一个基于深度神经网络的糖尿病风险预测模型 [14] ,此模型最大程度集成了自动编码器和softmax的优点,从而实现良好的分类性能。
虽然深度学习模型对复杂数据具有良好的分类性能,但是,在实践中也存在一些挑战,比如模型优化算法、网络结构、超参数、激活函数等设置对深度学习模型的性能和效果会产生不同的影响。神经网络的训练中所遇到的问题对深度学习模型优化的挑战更大,科研人员也做了很多研究工作,提出了多种优化算法。张鑫等人选择SVM作为分类模型,通过粒子群优化算法PSO (Particle Swarm Optimization)对SVM的参数误差惩罚因子和核函数进行优化,输出最佳参数组合,用于构建糖尿病性视网膜病变和神经病变的并发症分类预测模型 [15] 。Karegowda等人采用决策树和相关性Genetic特征选择方法进行特征筛选,并建立了基于GA-BP神经网络的糖尿病分类模型,混合GA-BP可以得到最优的网络参数和权值 [16] 。Aljarah等使用鲸鱼优化算法WOA (Whale Optimization Algorithm)优化多层神经网络的权重和偏置,建立了基于多层神经网络的糖尿病分类模型 [17] 。Si等以15个医学数据集为基础,研究了不同优化算法在人工神经网络分类中的效果 [18] 。尽管近年来基于深度学习的糖尿病分类研究取得了长足的进步,但神经网络在参数训练过程中容易陷入局部最优,影响网络模型的预测性能,因此,针对神经网络优化方法的研究仍亟待深入展开。群智能优化算法及其应用是当前优化领域的重要分支和研究热点,也是交叉学科的前沿性研究方向之一。本文提出基于改进狮群算法优化神经网络的糖尿病风险预测模型。首先,采用合成少数类过采样SMOTE (Synthetic Minority Oversampling Technique)技术消除数据集不平衡性问题,采用递归特征消除RFE (Recursive Feature Elimination)方法进行特征选择,然后,引入非线性扰动因子改进狮群算法LSO收敛因子,得到一种改进狮群算法ILSO,采用ILSO对BP神经网络的网络参数进行优化。最后,利用优化后BP模型对真实糖尿病数据进行分类预测。
2. 改进的狮群优化算法
2.1. 狮群优化算法
狮群优化算法(Lion Swarm Optimization, LSO)是刘生建等人于2018年提出的新的群智能优化算法 [19] 。相比PSO、人工蜂群算法ABC (Artificial Bee Colony)、引力搜索算法GSA (Gravitational Search Algorithm)等,LSO算法收敛速度最快,最容易跳出局部最优值,可以更好地解决全局最优问题。
2.2. 改进狮群算法
在LSO算法中,狮王的最佳位置受到参数
、
、
的影响,其中
在迭代过程中线性递减,但是狮群算法在实际搜索过程是非线性变化的。为了更好地平衡算法的全局搜索与局部寻优,我们引入了非线性扰动因子对
进行改进,得到改进LSO (ILSO)算法。
的改进公式为:
(1)
扰动因子
在改进前后的变化趋势见图1。改进后的扰动因子
在迭代初期变化速率较慢,保证充分的全局搜索能力,在迭代后期,衰减速率较快,这不仅增强了局部搜索能力,同时提高寻优速度,使得算法快速收敛。整体而言,改进后的
能更好的权衡全局优化与局部优化之间的关系,提高算法优化能力和收敛速度。
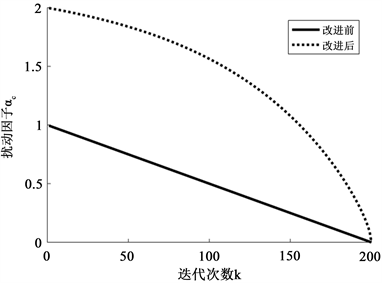
Figure 1. The variation trend of disturbance factor before and after improvement
图1. 改进前后扰动因子的变化趋势
2.3. ILSO-BP预测模型
BP神经网络既有着自学习、自组织等优势,也存在容易陷入局部最优、收敛速度缓慢、训练精度不高等缺点。为了改进这些缺点,本文将改进的狮群优化算法ILSO引入BP神经网络的参数寻优过程,用ILSO优化算法取代传统梯度下降法优化BP神经网络的权重和偏置,并构建基于ILSO-BPNN的糖尿病分类预测模型。
基于ILSO-BP的糖尿病分类预测模型的算法流程见图2,主要步骤包括:
1) 原始糖尿病数据PIMA属于非平衡数据,使用合成少数类过采样技术SMOTE (Synthetic Minority Oversampling Technique) [20] 消除不平衡性;为避免特征冗余,使用递归特征消除RFE (Recursive Feature Elimination) [21] 方法进行特征选择。
2) 确定预测BP神经网络结构。根据预处理数据集的特征,确定BP神经网络结构,包括输入层神经元个数
、输出层神经元个数
、隐藏层神经元个数
等。
3) 种群初始化。设置种群数量N,寻优空间的维度
,最大迭代次数
,种群初始位置
,成年狮数量
。其中寻优空间的维度
由BP神经网络结构决定
。
4) 确定适应度函数。使用训练数据的预测值
与真实值
之间的交叉熵函数
作为适应度函数。设BP神经网络的第
层第
个节点的输入为:
(2)
激活函数为
,第
层第
个节点的输出为:
(3)
则适应度函数为:
(4)
其中,
为第
层第
个神经元与第
层第
个神经元之间的连接权重,
表示第
层第
个神经元的偏置。
5) 分配狮王、母狮、幼狮位置。狮群个体位置代表待寻优的BP神经网络的初始权重和偏置。
6) 狮群位置更新。依据(5) (6) (7)式更新狮王、母狮、幼狮的位置进行全局搜索,计算适应度值并排序。
(5)
(6)
(7)
其中
,
为第
个狮子在第
代的历史最优位置,
为第
代群体最优位
置,
是服从正态分布
的随机数,
为第
代母狮在群体中随机挑选的捕食伙伴的最优位置,
为扰动因子,
和
分别表示狮子活动范围空间各维度的最小值均值和最大值均值,
为幼狮位置移动范围扰动因子,
为幼狮跟随母狮的第
代的最佳位置,
为第
个幼狮在捕猎范围内被驱赶的位置,
,
为概率因子,
服从均匀分布
。
7) 判断是否达到优化条件。若迭代次数未到达
,且相邻两次训练结果的误差未小于阈值ε,则返回步骤6);否则,输出最优的狮群位置向量,并转步骤8)。
8) 获得BP神经网络最优参数。狮群算法寻优产生的最优值解码得到BP神经网络的最优权值和偏置。
9) 建立基于BP神经网络的糖尿病预测模型并进行分类预测。将相关数据输入到ILSO-BP网络模型,输出结果即为分类预测值。
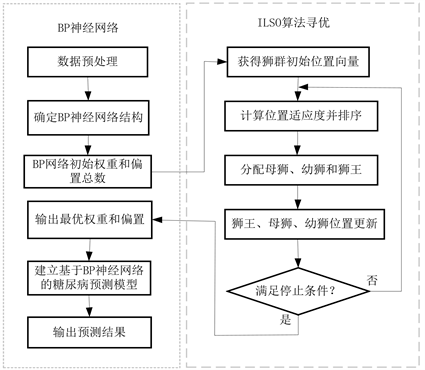
Figure 2. Flowchart based on ILSO-BP diabetes prediction model
图2. 基于 ILSO-BP糖尿病预测模型流程图
3. 实验结果与分析
3.1. 数据预处理
本文所选择的数据集是PIMA糖尿病数据集,来源于美国国家糖尿病和消化肾脏疾病研究所 [22] 。表1为数据集的基本特征。数据集共768行9列,8个特征1个类别,其中阴性样本500条,阳性样本268条,数据类别不平衡。为了提高模型分类精度,对数据做预处理,包括过采样和特征选择。我们选择70%训练数据做SMOTE过采样处理来增加阳性样本数,减少噪声对阳性样本分类效果的影响。过采样的数据有686条,阳性样本和阴性样本各343条。使用递归特征消除法RFE消除特征之间的冗余,选取最优特征组合,降低特征维数。通过实验发现PIMA数据中的8个特征不存在冗余。
3.2. 模型性能评价指标
本文选择准确率
、精确率
、召回率
、
和AUC作为评价指标。其中
、
、
和
由公式(8)~(11)计算得到:
(8)
(9)
(10)
(11)
其中,
指将正类预测为正类的数目,
指将正类预测为负类的数目,
指将负类预测为正类的数目,
将负类预测为负类的数目。
AUC (Area under the ROC Curve)值是指ROC (Receiver Operating Characteristic Curve)曲线下的面积,其中ROC曲线以假正类率为横坐标,真正类率为纵坐标的绘制的曲线。AUC越接近1,预测精度越高,当AUC为0.5时,预测无意义。

Table 1. Basic characteristics of PIMA dataset
表1. PIMA数据集基本特征
Table 2. Forecast performance comparison
表2. 预测性能比较
3.3. ILSO-BP模型参数设置
BP神经网络输入层节点为8,2个隐含层,每层神经元数为50,输出层节点为1,最大迭代次数为5000,学习率0.1,激活函数tanh,损失函数为交叉熵损失函数。狮群数量30,
为0.2,最大迭代次数500,l和h的初值分别为−0.1和0.1。实验环境采用英特尔第十代酷睿i5-10210U处理器,显卡型号2500U。算法模型采用python3.9编程,绘图工具采用matplotlib绘图模块。
3.4. 实验结果分析
3.4.1. ILSO-BP与基线模型的性能比较
本文选择的基线模型包括基于网格搜索优化超参数的K近邻(KNN)、支持向量机(SVM)、随机森林(RF)方法和朴素贝叶斯(NB)、决策树(DT)方法。ILSO-BP模型和所有基线模型的评价指标见表2。由表2可知,我们所提出的ILSO-BP模型分类准确率达到87.50%,优于基线模型。不论是标签为0的样本还是标签为1的样本,其精确率、召回率、F1值都明显大于其他基线模型的各个指标。实验结果证明本文所提出的ILSO-BP模型对糖尿病分类具有较高的预测精度。
图3是各分类器的ROC曲线图。ROC曲线图下的面积是AUC,AUC越接近1,模型检测效果越好。由图3对AUC排序:ILSO-BP > DT > RF > KNN > NB > SVM,且ILSO-BP的值为0.8673,明显大于其基线模型的AUC值。依据AUC的一般判断标准说明我们所提的ILSO-BP模型对PIMA数据的分类效果很好,可用于糖尿病风险预测。
3.4.2. ILSO-BP与其他糖尿病预测模型性能比较
表3给出本文所提出的预测模型与其他已有预测糖尿病预测模型的比较。所有文献都采用公共数据集PIMA。文献 [23] [24] 和 [25] 分别采用了粒子群优化、多目标优化及粗糙集与蝙蝠优化的模糊理论分类预测模型,他们的准确率分别为82.32%、81.50%和85.33%。Aljarah等提出基于WOA、PSO优化BP的模型分类准确率分别为77.86%、79.77% [17] 。文献 [16] 提出的基于GA优化BP模型的准确率为84.71%。使用本文提交的预测模型的准确率是87.50%,该模型在预测糖尿病方面有较高的准确率。
3.4.3. 消融实验
通过消融实验检验基于ILSO-BP模型中的每个组件对预测效果的影响,实验结果见表4。BP模型的准确率分别为85.33%,增加了狮群优化算法的LSO-BP的准确率提高到86.41%,基于改进狮群优化算法的ILSO-BP的准确率达到了87.50%,与BP和LSO-BP相比较,ILSO-BP的准确率分别提高了2.17%和1.09%。精确率、召回率和F1等指标的值也说明了改进的预测模型ILSO-BP具有良好的预测性能。所提的ILSO-BP模型和LSO-BP、BP模型的实验耗时分别为129 s,126 s和154 s,这一事实说明引入狮群算法确实提高了神经网络的参数寻优效率。
3.4.4. 数据预处理方法对模型性能的影响
正确合理的数据预处理对模型的预测性能也有较大影响。数据预处理阶段不仅采用SMOTE过采样技术消除样本不平衡问题,而且使用递归特征消除法RFE消除特征之间的冗余。通过实验发现PIMA数据中的8个特征不存在冗余,故在模型训练和预测中仍保持8个特征。表5为不同数据预处理时模型性能,表中ASRIB代表了(SMOTE) + (RFE) + (ILSO-BP)模型的准确率,ARIB代表了(RFE) + (ILSO-BP)模型的准确率。如果选择其中4个特征进行建模预测,准确率ARIB和ASRIB分别为68.83%和64.13%,我们发现过采样SMOTE降低了预测性能。5个特征预测也有类似结果。当选取特征数为6和7时,过采样技术对模型预测性能几乎没有影响。当SMOTE与RFE相结合后,准确率ARIB和ASRIB分别为83.12%和87.50%,预测性能有显著提高。
Table 3. Performance comparison of ILSO-BP with other diabetes prediction models
表3. ILSO-BP与其他糖尿病预测模型性能比较
Table 5. Impact of data preprocessing on ILSO-BP
表5. 数据预处理对ILSO-BP的影响
4. 结语
研究证明,越早了解糖尿病患病风险并进行早期干预可降低糖尿病致死率。本文提出一种基于改进狮群算法优化神经网络的糖尿病风险预测模型。首先,引入非线性扰动因子改进初始狮群算法收敛因子,在初始阶段,非线性扰动因子递减缓慢,提升算法跳出局部搜索的能力,从而避免算法陷入局部最优,最终达到增强全局优化能力,在后期阶段,扰动因子快速递减,这样可增强算法局部搜索能力,提高算法的收敛速度。利用改进狮群算法(ILSO)的寻优能力优化神经网络参数,提高神经网络的精度与收敛速度。构建基于ILSO-BP神经网络的预测模型。同时,采用过采样技术SMOTE和递归特征消除方法RFE对糖尿病数据进行预处理,提升模型预测能力。以皮马印第安人糖尿病数据集PIMA为基础进行了广泛实验,实验结果表明,经过改进狮群算法优化BP神经网络预测模型对糖尿病风险具有良好预测能力,为糖尿病的辅助诊断提供支持。下一步将在更多数据集上验证模型的有效性,同时尝试其他优化算法或数据预处理方法,以提高模型的预测精度。
基金项目
国家自然科学基金/National Natural Science Foundation of China (71761031)。