1. 引言
人类主要是通过面部表情这一途径来传达自身情感信息的。早在上世纪70年代就出现了表情编码系统的概念,人脸表情被分为惊讶、生气、高兴、厌恶、悲伤、害怕6类。部分表情识别算法已能够实现较为准确的表情分类,如Zhang H等 [1] 提出的弱监督局部全局关系网络,Marrero等 [2] 提出的带有Attention机制的基于CNN的网络架构FERAtt,Li等 [3] 提出的基于注意力机制的卷积神经网络ACNN,Fard等 [4] 提出了一种自适应相关损失,以指导网络生成类内样本相关性高、类间样本相关性较低的嵌入式特征向量,改善嵌入式特征向量之间对类类别的区分。张海峰 [5] 等提出的基于多特征融合的人脸表情识别模型。这些模型的底层依赖AlexNet [6] 、VGGNet [7] 、GoogleNet [8] 、ResNet [9] 等网络。
学生群体课堂学习情况分析是一种特殊场景,此时的面部表情是个体听课专注度的反映,但信息的准确获取所受影响因素较多,如头部姿态、背景信息、面部遮挡等。
为了消除复杂背景影响,Lee等 [10] 设计了两个支路模型,各支路分别用于正常提取人脸面部特征和聚焦面部表情之外的背景信息,最后进行融合。Liu等 [11] 提出双分支多特征学习网络,有效地区分局部面部特征的细微差异。Acharya等 [12] 使用流形网络结构进行协方差合并,再使用二阶统计量捕捉面部特征扭曲,以更好地捕获部分变形的区域面部特征。Zhou等 [13] 利用Attention机制和双线性池化进行多模态的表情特征融合,以使模型专注于面部的重要部位,提升面部表情识别的准确性。Wang等 [14] 运用对抗学习思想消除身体姿态变化干扰,得到单纯的人脸表情特征,提高了表情识别的鲁棒性。Zhong等 [15] 利用图结构的人脸表情表示和双向循环神经网络进行特征提取,有效去除了冗余信息,减少了干扰和训练开销。
与普通的人群密集型场景不同,学生课堂听课时的面部遮挡主要集中在左脸、嘴巴、右脸等下半张脸。为此,本文采取了如下的解决方法:
1) 引入自注意力机制学习局部特征并与整体特征融合,使模型更关注表情有效区域,过滤无效信息,获取表情细节特征。
2) 限制遮挡支路权重始终小于眼部支路权重,并通过阈值限定眼部区域权重在合理区间从而进一步弥补课堂场景下面部遮挡带来的信息损失,提高模型准确率。
2. 基于自注意力机制与特征融合的表情识别模型
模型共分为提取人脸表情特征、自注意力权重分配、特征融合和表情分类4部分,如图1所示。
在提取人脸表情特征模块,先对课堂教学视频帧中的原人脸图像进行裁剪和遮挡,将裁剪和遮挡后的人脸图像与原人脸图像分成五路,每路都通过Resnet残差网络提取局部特征。
在自注意力权重分配模块分别对从每个支路学习到的学生人脸表情特征分配权重,自注意力机制会为从各支路学习到的表情特征分配权重,然后再通过约束性损失函数约束分配到的权重使得眼部特征分配到最大权重。
在特征融合模块将从注意力分配特征权重模块得到的各支路权重和学生人脸表情特征进行融合得到学生人脸表情的全局特征,学生人脸表情全局特征由各个支路加权注意力特征之和得到。
最后在表情分类模块将得到的数据使用SoftMax分类器分类学生人脸表情。
3. 表情特征学习
3.1. 特征提取
在人脸图像中,嘴部、眼部和鼻子为识别提供了局部特征,可供于融合成全脸图。因此,图1设计了5条支路,分别提取整体特征、眼部特征、嘴部特征、鼻子部位特征和下半张脸遮挡特征。特别地,将下半张脸随机遮挡作为特征有利于解决因课堂脸部遮挡问题而产生的表情识别准确率低问题。
模型先根据人脸检测得到的人脸关键点坐标信息裁剪各支路图像,并使用数据增强方法进行下半张脸随机遮挡。因为裁剪得到的不同部位图像尺寸不同,需将各支路图像缩放为相同尺寸,并对下半张脸中包含的鼻子和嘴部进行像素值归一化处理,最后送进支路网络。
各支路网络由相同的ResNet残差网络组成,其后端连接全连接层并使用激活函数来获取各支路提取到的特征所占权重,同时引用约束性损失函数约束遮挡支路的特征权重,使其小于眼部特征权重最后融合整体人脸表情特征和局部人脸表情特征得到表情特征图。具体模型图参见图2。
3.2. 自注意力权重分配
公图像输入部分输入学生人脸图像得到人脸复制图X0。部位细分部分由X0输出X1~X4,分别对应眼部、鼻子、嘴部和随机遮挡的下半张脸。对应地,在特征提取部分得到输出F0~F4,而注意力权重分配部分依据式(1)计算F0~F4的权重
。
(1)
其中,W1和W2为全连接层权重,R为ReLU激活函数,f为Sigmoid激活函数。由各支路ResNet残差网络学习到的学生人脸表情特征Fi与注意力权重
的加权和构成了式(2)所示的全局人脸表情特征Fm。
(2)

Figure 2. Student expression feature learning model diagram
图2. 学生表情特征学习模型图
3.3. 约束性损失与分类损失函数
由于课堂场景下遮挡区域主要集中在下半张脸,应使模型减少对遮挡区域的关注。因此,采用式(3)所示的约束性损失函数,以限制遮挡支路权重小于眼部支路权重。
(3)
其中,
为遮挡支路权重值,
为眼部支路权重,margin为阈值初始值设为0.03。当眼部支路的权重值与遮挡支路的权重值之间的差距超过了阈值margin时,就会产生损失,目的是让模型更加关注眼部支路的特征。具体来说当眼部支路的权重值
大于遮挡支路的权重值
的加上margin时,损失函数的值为0,说明网络更加关注眼部特征,对于眼部的识别和定位更加准确,不会对网络进行惩罚。当眼部支路的权重值
小于遮挡支路的权重值的加上margin时,损失函数的值会大于0,说明网络更加关注遮挡区域特征,这是会对网络进行惩罚,从而引导网络更加关注眼部特征。
函数L1鼓励模型对每个样本预测其真实标签的概率尽可能大,并对预测概率和其他概率之间的差距进行限制。
分类损失采用式(4)所示的交叉熵函数。
(4)
其中,y为真实人脸表情标签,
为预测人脸表情标签。
最后,将约束性损失与分类损失求和作为总损失函数,参见式(5)。
(5)
4. 实验与结果分析
4.1. 数据集与参数设置
本文使用公开数据集FERplus [13] 进行验证,它是谷歌搜索引擎收集的大规模真实人脸表情数据集,包括28,709张训练图像,3589张验证图像和3589张测试图像。
残差网络采用ResNet50;训练数据集学习率初始化为0.01;Epoch迭代周期为30,学习率每迭代一个周期更新为当前的0.1倍。
4.2. 对比分析
表1显示了本文模型与PLD (Probabilistic Label Drawing) [16] 、Deep-emotions [17] 和Efficient-Net [18] 在测试集上的准确率。

Table 1. Accuracy of facial expression recognition using several models
表1. 几种模型的表情识别准确率
在模型中,约束性损失函数的阈值margin设置为0.03。可以发现,由于融合了局部与整体表情特征,重点关注眼部这一不常被遮挡的人脸区域,本文模型更准确地获得了特殊场景下的表情特征,进而提高了表情识别的准确率。
鉴于阈值margin的重要性,图3比较了其值分别取0.01、0.03、0.05、0.07和0.1时对识别准确率的影响。
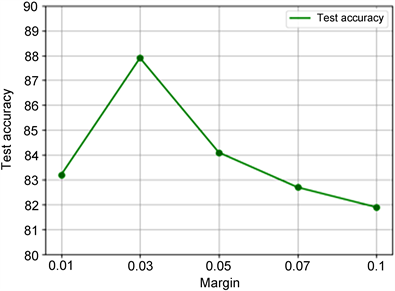
Figure 3. Student expression feature learning model diagram
图3. 学生表情特征学习模型图
当margin值过大时,模型会过于关注眼部区域,使其他区域的特征影响降低而导致识别准确率下降。当margin值过小时,模型对所有特征区域的关注程度相对均衡,无法将权重偏向于不常被遮挡的眼部区域。
5. 结论
为了解决课堂教学场景下学生人脸表情识别问题,构建了利用局部特征和整体特征的融合,并使用约束性损失函数对遮挡支路进行限制,重点关注不常被遮挡的眼部区域的识别模型在公开数据集上较现有模型得到了更高的表情识别准确率。模型表明,对于一些有明显约束的场景,通过布局和整体的特征融合及对损失函数进行约束可以有效缓解因某些信息缺失而造成的识别准确率下降问题。结合对眼部动态的判别,可以利用该模型进一步衡量学生课堂学习的专注度。