1. 引言
随着互联网的发展与电子设备的普及,数据信息成几倍的速度增加。在信息爆炸的同时,信息的种类也越来越多越样。单模态数据被定义为以单一的某种格式表示的数据,比如图像、视频、3D模型,多模态数据则是多种数据结构的汇总。单模态间的检索方式逐渐发展开来,人们可以用以图搜图等一些方式来进行检索。而在多种数据类型之间的检索,也称为跨模态检索。
跨模态检索的发展需解决以下问题。首先是模态的异构性,不同模态对于同种东西的语义传达方式是有很大差异的,例如图片的特征主要表示为尺度不变特征转换特征或者局部二值模式特征。文字的特征主要表现为线性判别分析特征或者词频–逆向文件频率特征。即便描述同一个东西,不同模态的维度依旧有大幅度的不同,无法简单直接地构建传达某一东西的不同数据的桥梁。其次是语义鸿沟,计算机通过数据的潜在表示来捕获信息,接着计算不同特征的距离以判断是否相似,而人类是通过经历与学习的高级语义来判断两种东西是否相似。最后是性能,数据量大种类多,如何快速对不同模态进行检索,以及检索的精确度也是我们需要考虑的。
而基于哈希的跨模态检索方法在近年来得到很大发展。哈希方法将数据压缩成一个二进制哈希码,通过简单的异或运算,其运行速度很快适用于大数据背景。根据语义标签的嵌入情况,我们将现有的跨模态哈希方法分为三个大类:无监督、有监督以及半监督模型。
2. 相关理论
2.1. 无监督哈希方法
集体矩阵分解哈希(Collective Matrix Factorization Hashing, CMFH) [1] 设计了矩阵分解的框架来提取不同模态的共同子空间,同时把高纬度的数据压缩到低维度的特征,最后从子空间中学习到离散的二进制码。但是该方法并没有考虑样本与样本的相似性。隐藏语义稀少哈希(Latent Semantic Sparse Hashing, LSSH) [2] 联合了矩阵分解以及稀疏学习来降低原始样本的维度,并学习到不同模态的不同潜在空间,通过对不同的空间进行量化可以获取统一的哈希码,但LSSH并不是一个高效的算法,其原因在于稀疏学习的计算量相比与线性的模型来说是很大的,所以训练的成本很高。
2.2. 监督哈希方法
语义关联最大哈希(Semantic Correlation Maximization, SCM) [3] 保证同成分的样本之间的关联性尽可能地高,并且将其嵌入到哈希码的学习中。但该模型由于松弛了约束条件,因此避免不了量化误差,同时训练成本比较沉重。
2.3. 半监督哈希方法
判别半监督哈希(semisupervised cross modal hashing approach by generative adversarial network, SCH-GAN) [4] 利用了GAN技术来生成哈希码,同时采纳一些非中央样本以提升模型能力。半监督方法没有要求全部样本具有标签,并使用部分标签与模态内部的特征相结合,因此能获取高质量的哈希码。所以半监督办法在表现性能跟标注时间上取了较棒的调节。
3. 方法提出
大多数方法学习一个多种模态学习一个低维的潜在空间,尽管可以提取部分的共同语义,但会损失每种模态的独特性。其次,一些方法会先松弛离散的约束再去优化它,这样会引入较大的量化误差,从而导致精度的缺失。为了解决这些问题,提出一种新的框架叫做独特相似哈希(Unique Similar Hashing, USH)。USH是一个两步学习的哈希方法,其首先学习哈希码然后学习哈希函数。第一阶段,先使用核函数将数据非线性地投影到核空间,然后使用矩阵分解学习潜在空间。然后为不同的模态设计了各自的潜在空间以保留它们的独特性。此外,两个潜在空间被对齐通过局部相似性保留,这样可以提取不同模态的高级语义。潜在空间中学习哈希码,且不放松哈希码的离散约束来降低量化误差,并直接计算它的封闭解。在学习一个优质的哈希码之后,再学习一个哈希函数将原始样本映射到低维的汉明空间。为了平衡精度与速度,一个线性的分类器被选择作为哈希函数,USH的框架如图1所示。
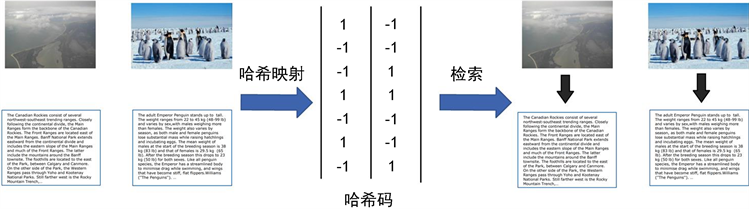
Figure 1. Schematic diagram of cross-modal hashing
图1. 跨模态哈希示意图
3.1. 符号表示
首先用X表示一个多模态数据集。第t个数据表示成
。当m为1代表了图像,当m为2代表文本,n代表样本数量。为了增加模型的非线性,使用核函数把
映射到核空间并获得
。由于这是一个监督算法,因此会使用标签信息
,其中c代表了标签的总类别。目标是产生一个离散的哈希码,将它表示成
,r代表了哈希码长度,即储存成本。最后给定一个矩阵Z,
它的Frobenius范数及迹函数被分别表示为
和
。
3.2. 哈希码学习
原始数据可能包含一定的噪声,因此需要学习一个样本的高级表示,即潜在空间。集体矩阵分解时可以去除数据的噪声,可以利用它来学习一个共同的潜在空间以储存不同模态的高级语义。但是这样是不合理的,因为每种模态的分布跟维度是相当不同的。直接设计一个共同空间将会散失每种模态的独特性。使用矩阵分解为每种模态学习一个潜在空间,其被描述如下:
(1)
其中
是一个平衡参数,
跟
为不同模态的投影矩阵,而
跟
代表不同模态的潜在空间,这四个变量都需要学习。潜在空间的维度被设置为哈希码的长度可以让哈希码的学习更加简单灵活。
在学习不同的潜在子空间之后,需要探索它们共同的高级语义。通过全局相似直接令它们对齐虽然是简单的,但是没有考虑样本与样本之间的相关性。为解决此问题,提出局部相似性保留来对齐两个潜在空间。具体而言,首先根据标签计算一个距离矩阵H,每个元素被定义如下:
(2)
根据H定义一个相似性矩阵S,如果两个样本共享同一标签,那它们相似性大的,相反,如果它们标签不相同,则没有相似性。相似性矩阵S被计算如下:
(3)
接着,考虑潜在空间之间的局部相似性。具体而言,如果两个样本是相似的,那么它们的潜在样本也应该是近似的。如果相似性很小,那么潜在样本则不要求近似,这也可以看作它们每个空间的独特性。局部相似性保留通过下面的式子实现:
(4)
其中
是一个平衡参数。通过优化公式(4)可以提取不同模态的共同高级语义并且保留它们各自的独特性。
当前目标是生成一个离散的二值哈希码
,以便于使用异或操作进行快速地检索。哈希码需要从样本的潜在空间进行学习因为潜在空间包含了高级语义。为了增加哈希码跟潜在空间的语义联系,提出下面的损失项来学习哈希码:
(5)
其中
是另一个平衡参数。
跟
是需要学习的映射矩阵。
最后,把公式(1),公式(4),公式(5)结合起来,便可以得到第一阶段的目标函数:
(6)
3.3. 优化策略
目标函数公式(6)是一个非凸的函数所以难以直接优化。但如果只优化其中一个变量而固定其他的,那么公式(6)将会变成凸的,所以把公式(6)转化为矩阵迹的形式:
(7)
1) 更新U。
在固定
之后,关于
的目标函数被简化如下:
(8)
接着计算关于
的导数,让其等于0可以得到
的封闭解,同理
也可以得到封闭解。
(9)
(10)
2) 更新V。
固定
之后,公式(7)被转化如下:
(11)
计算公式(7)对于
与
的导数令其等于0可得
与
的封闭解:
(12)
(13)
3) 更新P。
为了更新
令其他参数保持不变得到如下目标函数:
(14)
计算公式(14)的导数并且将其设置为0,将得到
的最优解,同理可得
最优解:
(15)
(16)
4) 更新B。
固定
以更新B,考虑到
是一个常数,因此简化目标函数如下:
(17)
由此可得B的最优解:
(18)
3.4. 哈希函数学
USH是一个两阶段的哈希方法,将哈希码跟哈希函数的学习分离开。所以在学习完一个优质的哈希码之后,需要设计一个哈希函数以将原始样本映射到低维的汉明空间。为了平衡速度跟精度,采用核函数加上线性分类器的方式作为哈希函数。线性分类器的描述如下:
(19)
其中
为第t个模态的分类器,而
是根据经验所得的参数。优化公式(19)之后,给定一个新的检索样本,可以使用
得到哈希码,然后通过异或操作比对不同的哈希码从而快速地实现检索。为了优化公式(19),计算其导数并令其为0可得
的最优解:
(20)
最后提供整个优化的步骤在算法1中:
Algorithm 1. Unique similarity hashing (USH)
算法1. 独特相似哈希(USH)
4. 实验论证
4.1. 数据集
Wiki [5] 收集并分类了维基百科中的数千篇文章及其附带的图片,由于有些类别非常稀少,因此只保留了10个类别的样本。Wiki提供2866个图像–文本对,它们被随机分成2173个文档作为训练集,693个文档用作测试集。此外,在该数据集中,图像被表示为128维尺度不变特征变换(SIFT)描述符,而文本是从潜在狄利克雷分配(LDA)中提取的10维频率特征。
4.2. 实验设置
将所提出的USH与其他先进方法进行对比。他们分为两种类型,首先是无监督的哈希方法包括LSSH [2] 以及CMFH [1] 。还有一些有监督的哈希方法,包括SMFH [6] ,SCM-seq [3] ,SePH [7] ,DCH [8] ,GSPH [9] ,MSL F [10] 。所有mAP结果来源于原论文,如果没有在某个数据集上验证,那使用别人复现的结果,PR曲线同理。因为USH快速收敛,所以训练迭代次数设为10。最后,实验都是在一台个人计算机上实施的,该计算机包括了16核CPU与64 GB内存。
4.3. 实验结果
实验结果分两方面,首先是mAP结果,在完成了两种任务在检索上,分别是图像检索文本以及文本检索图像。并测试不同哈希码长度下各个方法的表现。mAP的结果展示在表1中,最好的表现会被标出。绘制PR曲线,这些曲线是在哈希码长度为32位跟64位下的结果,但对于其他长度情况是近似的。展现的是PR曲线如图2所示。

Table 1. mAP results on Wiki database
表1. Wiki数据集上的mAP结果
对结果进行观察,发现在16位哈希码情况下,USH在图像检索文本上取得最佳的精度,在文本检索图像稍微落后于MSLF方法。而在32位哈希码以及64哈希码长度下,USH无论在哪种情况下都超越了其他方法。128位长度的哈希码下USH比MSLF稍低一些,但仍然比其他方法要好一些。
观察图2的PR曲线,发现无论哪种哈希码长度或者哪种任务表现上,USH的曲线都在其他曲线之上。说明USH都超越了其他方法。这都与表1的结果一致,以上评估标准都表明了USH是有效的。

Figure 2. Precision-Recall curves on the Wiki
图2. Wiki上的PR曲线
5. 总结
本文提出独特相似哈希(USH)的新框架,来快速实现多模态检索。USH是一个两阶段学习框架,它先学习哈希码再学习哈希函数。在第一阶段中,使用矩阵分解为不同模态学习一个独特的潜在空间,这可以保存不同模态的独特性。接着不同模态的潜在空间通过局部相似性保留对齐,这样可以提取共同的高级语义的同时不抛弃模态独特性,最后从潜在空间中学习哈希码。学习完一个优质的哈希码,使用一个线性的分类器作为哈希函数,其可以将新的样本映射到低维的汉明空间。为了证明USH方法是行之有效的,在Wiki数据集上进行实验对比,最后与其他方法比证明了USH的方法是有优势的。