1. 引言
数字经济 [1] 是人类通过大数据的处理,实现资源的快速优化配置与再生、实现经济高质量发展的经济形态。近年来,随着数字经济在全球经济发展中的地位不断提升,数字经济的发展水平和规模预测等问题受到国际组织、政府机构和国内外学术界的高度关注。国际上主要形成了美国BEA数字经济统计测算、经合组织(OECD)数字经济统计指标、欧盟数字经济与社会指数(DESI)等测量指标和方法。我国目前最主流的数字经济增加值测算方式为中国信通院数字经济核算方法。还有余丽等 [2] 给出了区域数字经济发展水平影响因素及定性评价模型,对构建数字经济规模预测模型影响指标选取具有参考价值;李栋等 [3] 综合运用相关性分析、主成分分析等多种统计方法对收集数据进行处理,并构建了中国数字经济规模预测模型;李英杰等 [4] 从数字基础设施等方面构建了数字经济发展水平量化指标体系,分别基于测度法和灰色预测模型对2019~2028数字经济发展走向进行预测;鲜祖德 [5] 根据《数据经济及其核心产业统计分类(2021)》构造了数字经济测算框架,测算并预测了我国数字经济核心产业规模。
以上研究在围绕数字经济规模测算时主要集中于生产法、支出法、回归模型和增长核算框架四大类,目前国际上对数字经济的概念认知和测度宏观层面仍缺乏统一标准。在指标体系构建上,由于没有一致的规定,不利于测算数字经济规模和增速,多集中于定性研究,定量研究较少,难以准确量化评估数字经济发展水平;在测算方法上,各个国家和区域来源于对数字经济概念及核算范围理解的偏差,对数字经济总量的测算存在或多或少的高估或低估。根据数字经济发展水平和数字经济规模呈正相关 [6] ,本研究参考和梳理了数字经济规模的影响因素 [7] ,选取具有代表性的相关指标并完成数据收集,对样本缺失数据采用线性回归进行月份多重插补扩充,同时进行多重共线性诊断以降低数据扩充的影响,对筛选后的影响指标进行主成分分析以实现数据降维 [8] ,同时构建基于数据处理的机器学习预测模型及对比模型;利用BP神经网络对2018~2022年江西数字经济规模预测进行实证分析 [9] ,以期预判江西未来数字经济发展趋势,对客观且全面地认识江西数字经济发展的现状及发展前景具有重要的现实意义 [10] [11] [12] 。
2. 研究方法
2.1. 相关性分析
在数字经济规模预测前,需要先确定数字经济的影响因素,这种影响因素(自变量)与数字经济规模(因变量)的关联度判断可以用相关性分析方法。假设从众多影响因素中随机抽取一个为自变量X与因变量Y组成变量组,这组变量之间的相关性可用Pearson相关系数表示:
其中,
是Pearson相关系数,cov表示X与Y之间的协方差,
、
分别表示X、Y的标准差,E表示数学期望。
是反映两个变量X与Y的相关性强弱,介于−1到1之间,
越接近于1表明相关性就越强;反之,
越接近于0则表明相关性就越弱。
2.2. 主成分分析
通过相关性分析对筛选后的影响因素有时需要数据降维处理。主成分分析(Principal Component Analysis, PCA)就是在“信息量”损失较少情况下,将高维数据转换为低维数据,降低预测模型的复杂度。主成分分析的原理是将原来变量通过线性组合重新组合成一组新的、相互无关的几个综合变量,这些新的综合变量就是成分,再根据成分的方差从大到小进行排序,按实际需要从中取出几个成分尽可能多地反映原来变量信息构成主成分,预测模型的构建可依据主成分作为模型的输入。主成分分析基本步骤如下:
① 原始数据的标准化。确定P个数字经济规模影响指标,构成P维随机向量
,其中n个不同年份样本数据可表示为
,
,
,构造样本矩阵
;对样本数据进行标准化变换得到标准化矩阵Z,并计算得到相关系数矩阵R。
② 确定主成分个数。求解样本相关系数矩阵R的特征方程得到P个特征值。按累计贡献率大于85%确定m值,即
。其中
为第i个主成分的方差贡献率;根据主成分总方差解释结果,选取涵盖影响指标绝大部分信息的主成分。
2.3. BP神经网络
以降维后的数据作为机器学习预测模型的输入层,可构建BP神经网络(Back Propagation Neural Network, BPNN)预测模型来预测数字经济规模。BP算法利用损失函数,每次向损失函数负梯度方向移动,直到损失函数取得最小值。反向传播算法是根据损失函数求出损失函数关于每一层的权值及偏置项的偏导数,用该值更新初始的权值和偏置项,一直更新到损失函数取得最小值或是设置的迭代次数完成为止。以此来计算神经网络中的最佳的参数。
以典型三层BP神经网络为例分为输入层、隐含层、输出层,具有如下结构:
如图1所示,
是网络层的输入向量,隐含层第K个节点和输入层之间的权向量为
。隐含层的输入为
,输出层的输入为
,
为隐含层到第j个节点的权值向量,
为输出层的输入,网络的输出向量为
。期望输出向量为
。损失函数的期望值
。
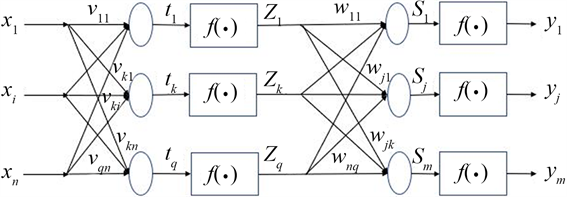
Figure 1. Schematic diagram of a three-layer neural network
图1. 三层神经网络示意图
2.4. 基于数据处理的数字经济规模预测模型
基于上述研究方法构建了数字经济规模预测模型,并与其它预测模型作对比分析,进行模型评价。数据处理及模型构建流程如图2所示。

Figure 2. Data processing flowchart of the digital economy scale prediction model
图2. 数字经济规模预测模型的数据处理流程图
3. 实证分析
3.1. 数据来源
数据收集
数字经济发展水平和数字经济规模呈正相关,通过查阅相关文献并进行分析总结数字经济发展水平的影响因素,论文从基础设施、数字金融产业、数字交易以及知识产权四个维度选取江西省数字经济规模的影响指标,见表1。
本文收集了2011~2020年共计10组数据,其中数据主要来源于《中国统计年鉴》《中国第三产业统计年鉴》《中国信息产业年鉴》《江西省统计年鉴》、北京大学数学普惠金融指数、国家统计局等。
考虑到收集数据部分指标存在部分年份缺失的情况,对缺失数据采用线性回归方法进行月份多重插补扩充,将影响指标的2011~2020年10组数据扩充到月份的108组数据。

Table 1. Impact Indicators of digital economy scale in Jiangxi Province
表1. 江西省数字经济规模影响指标
3.2. 数据处理
3.2.1. 相关性分析
采用SPSS(26.0)对上述指标扩充后的108组数据进行相关性分析,各指标与数字经济规模间的相关性热图见图3,其中x22表示数字经济规模。
由图3第一行数据可知,各指标与数字经济规模的相关系数最小值为0.847,最大值达0.991,说明各指标均与数字经济规模的相关性极强。从相关性热图颜色辨识,各影响指标间存在多重共线性关系。用容差和方差膨胀因子进行多重共线性诊断分析,选取所有指标中的一个指标xi为因变量,其他指标为自变量得到的线性回归模型的决定系数
,计算容差
,容差的倒数为指标的方差膨胀因子VIF,对于容差小于0.1或者VIF大于0,则表明有共线性存在。用SPSS(26.0)得到排除影响指标的诊断结果,见表2。
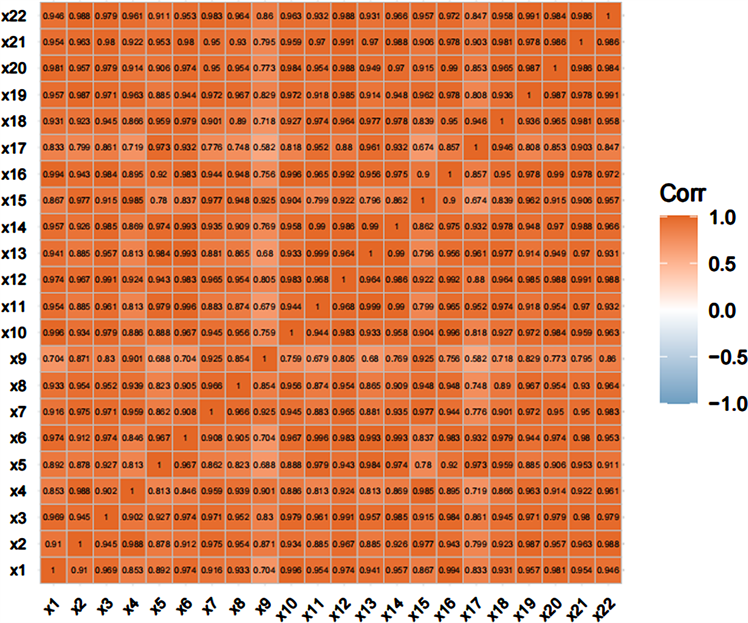
Figure 3. Correlation analysis heat map
图3. 相关性分析热图
Table 2. Collinearity diagnosis results of excluded variables
表2. 排除变量共线性诊断结果
通过多重共线性分析排除以上9个指标,选取光缆长度、互联网宽带接入端口数、互联网域名数、数字金融覆盖广度、数字金融使用深度、数字金融数字化程度、规模以上工业企业R&D人员折合全时当量、规模以上工业企业R&D项目(课题)数、网上移动支付水平、电信业务量、技术合同成交总额、专利申请授权数等12个指标表征江西省数字经济规模。
3.2.2. 主成分分析
对排除后的12个指标进行主成分分析,KMO统计量值为0.745,大于0.7,可看出变量间的相关程度无太大差异;巴特利特球形检验的结果小于0.05,球形假设被拒绝,原始变量之间存在相关性,结果均表明上述数据适合进行主成分分析,得到样本数据主成分总方差解释,见表3。
Table 3. Interpretation of principal component total variance
表3. 主成分总方差解释
根据主成分总方差解释,前四个主成分的累计方差贡献率超过99%,这样提取前四个主成分(分别记作F1、F2、F3、F4)可以涵盖选取12个指标的绝大部分信息,构建预测模型对数字经济规模进行预测。
3.2.3. 预测结果及分析
基于主成分分析提取的四个主成分F1、F2、F3、F4分别构建BP神经网络预测模型以及对比模型进行分析。设定滞后期数为12,即用前12个月份的值对当前月份的数字经济规模进行预测,同时划分前7年的第1~84组数据为训练集训练神经网络,第8年的第85~96组数据为测试集评估神经网络训练效果,取主成分最后12组数据作为BP神经网络的输入得到输出即为预测结果。其中BP神经网络按照“4-9-1”的网络拓扑结构完成训练及预测,其中4为输入层神经元个数,9为隐藏层神经元个数,1为输出层神经元个数,网络结构如图4所示。
根据建立的基于数据处理的BP神经网络预测模型,对江西省2011年12月至2020年12月数字经济规模进行实证分析,为了进一步检验模型预测效果以及验证主成分分析实现数据降维的有效性,本文将基于主成分分析构建PCA-BP神经网络模型与PCA-ARIMA模型、PCA-MLP模型、ARIMA模型、MLP模型、BP神经网络模型做比较,其中MLP模型按照“4-9-1”的网络拓扑结构完成训练及预测,ARIMA模型、MLP模型、BP神经网络模型使用的是经过数据填充以及多重共线性诊断筛选,但未经主成分分析进行数据降维的影响指标数据,对2021年度江西省数字经济规模进行预测,得到各模型预测结果(见图5)。
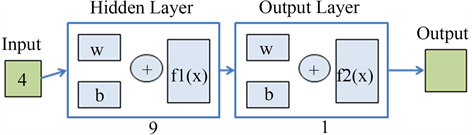
Figure 4. Topological structure of BP neural network
图4. BP神经网络拓扑结构
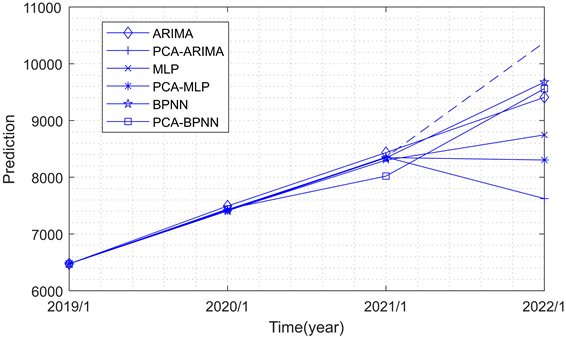
Figure 5. Comparison of prediction results of various models
图5. 各模型预测结果对比
从图5中可以看出,2018~2020年间除BPNN模型外其余模型预测结果与对应年份实际变化趋势基本吻合,2020~2021年间不同模型预测结果与实际值变化趋势出现较大偏差,综合比较来说,PCA-BPNN模型与实际值变化趋势基本吻合。同时通过计算得到各模型预测结果误差(见表4)。
Table 4. Prediction results error of each model
表4. 各模型预测结果误差
结合表4实验结果,分别比较ARIMA模型和PCA-ARIMA模型、MLP模型和PCA-MLP模型、BPNN模型和PCA-BPNN模型可知,经过主成分分析提取主成分构建的预测模型预测效果远优于未经数据降维构建的预测模型的预测效果,相较于ARIMA、MLP、PCA-MLP模型MAE、MAPE均提高了50%以上,表明了主成分分析实现数据降维的有效性。综合比较来说,PCA-BPNN预测效果最佳,进一步论证了PCA-BPNN预测模型的准确性及可行性。
4. 结论
① 相关性分析通过对主观选取因子的定量化分析,确定研究对象的影响指标。主成分分析是设法将多影响因素构成的原始变量重新组合成一组新的、相互无关的几个综合变量,同时根据实际需要从中可以取出几个较少的总和变量尽可能多地反映原始变量的信息。本文初始选取21个数字经济规模的影响指标,通过筛选变为12个影响指标,再通过主成分分析提取出4个主成分,再分别构建基于数据处理的机器学习预测模型以及对比模型进行实证分析,验证了模型预测的准确性。
② 实证分析表明,当构建机器学习预测模型而样本数据过少时,可对相邻年份进行数据填充以实现数据扩充,变为大样本数据进行分析。同时对扩充数据进行多重共线性诊断以降低线性填充的影响,筛选得到12个影响指标并进行主成分分析以实现数据降维。在上述数据处理的基础上,本文分别构建了典型机器学习模型MLP模型、BPNN模型以及传统预测模型ARIMA模型,实验结果表明,当样本数据足够多时,机器学习模型预测效果远优于传统预测模型,且文中给定机器学习模型中,基于数据处理的PCA-BPNN神经网络预测效果更佳。
③ 本研究在参考和梳理数字经济规模的影响因素,选取具有代表性的相关指标,对样本缺失数据进行月份多重插补扩充,同时进行多重共线性诊断以降低数据扩充的影响,对筛选后的影响指标进行数据降维,同时构建基于数据处理的BPNN预测模型,对定量测算数字经济规模和增速具有参考价值。
基金项目
国家自然科学基金项目(71961001)。