1. 引言
图像超分辨目的在于将一张LR (low-resolution)图像重建到HR (high-resolution)版本,从而改善图像质量。图像超分辨作为重要的底层视觉任务,其在医疗、遥感等领域有着重要作用,因此受到越来越多的学者的广泛关注。
传统的图像超分辨方法有很多,包含基于预测的方法,基于边缘的方法,基于统计的方法以及基于稀疏表示的方法等。近些年,随着深度学习技术的快速发展,出现很多基于深度学习的图像超分辨方法,并且这些方法在多样的基准上取得了很好的重建性能。Dong等 [1] 开创性地提出了第一个基于CNN (convolutional neural network)的图像超分辨网络SRCNN。该网络仅用简易的三个卷积层将LR图像映射到HR图像。随后,研究学者们发现更深更复杂的网络有利于图像特征信息的提取以及重建,因此在SRCNN的基础上,很多更深更复杂的方法 [2] - [9] 陆续被提出。这些方法利用密集连接残差块的不同变体作为网络的重建模块,一方面可以避免网络模型在训练过程可能出现的梯度消失问题;另一方面利用深层网络强大的特征提取传递能力,保证网络输入的图像特征信息在网络的传输过程中得以保持,从而重建出质量更高的图像。然而,需要指出的是,上述提到的方法大多基于L1或者L2损失去优化SR (super-resolution)图像与真实HR图像之间的距离。尽管这种方法可以在图像定量指标(如PSNR、SSIM)取得最优的结果,但重建出的图像往往过于模糊或平滑。主要原因是人类对视觉相似性的感知与这种像素级的误差的关联性不大。因此,研究者们逐渐关注于如何重建出视觉感知质量好的图像。Johnson等 [10] 通过设计新的感知损失从特征空间而非像素空间来缩小两张图像之间的距离,使得训练出的超分辨网络可以重建出视觉感知更好的图像。Ledig等 [11] 提出基于生成对抗网络(GAN)的模型SRGAN,利用GAN强大的生成能力,使得超分辨出的图像具有更真实的细节。随后Wang等 [12] 提出的ESRGAN在SRGAN的基础上加以改进,取得了当时最优的超分辨性能。随后研究学者利用注意力机制来进一步提高网络模型的性能。其中最具代表性的方法当属最近流行的transformer模型。其一开始应用于自然语言处理任务,主要利用Self-Attention (自注意力)结构来取代传统的循环神经网络结构,最大的特点是可以实现并行计算。后来,在研究学者的尝试努力下,将其运用到计算机视觉领域。如基于transformer机制的图像超分辨方法 [13] [14] 进一步提高了图像的恢复质量。
值得注意的是,上述提到的方法虽然在常用的基于合成的图像数据集上能够取得优良的超分辨效果,但是在真实场景图像上的重建效果不佳。其主要原因是通过这些模型合成的图像与真实场景下的图像之间存在域距离,这种域距离主要反映在图像退化的复杂度上。通常来说,通过上述方法合成的低分辨图像的退化样式单一,例如双三次插值。然而,在现实场景中采集到的真实图像由于传感器噪声、相机抖动等因素的影响,往往存在多样未知且复杂的退化(噪声、模糊、压缩等因素的结合)。
因此,近年来,研究者着力于真实场景图像超分辨的研究。一些工作 [15] [16] 通过调整相机焦距来获得真实图像成对的数据集,进而以监督的方式训练网络。然而,这些数据集的收集依赖于复杂的硬件设备并且对于不同相机均需要采集新数据,采集的难度较大且成本较高。一些方法则利用测试图像调整模型。Shocher等 [17] 设计出轻量级的CNN模型ZSSR,仅用测试数据训练该模型,使得该模型关注于图像具体细节。然而,通过直接利用测试图像训练网络模型的方式存在很大的问题。因为现实生活中的图像种类以及数量非常庞大,要想模型对某一类图像数据的重建效果好,就要使用这类数据重新训练模型,这大大提高了训练的时间及成本。另有一些工作提出盲超分算法 [18] [19] ,假定低分辨图像是由高分辨图像经过某种退化而来,这些盲超分方法比基于合成数据训练的模型有着更好的泛化性。然而,这种固定退化估计并不能有效作用于拥有复杂且未知退化的图像上。随后出现了一些基于域适应的方法来缓解这一问题。
域适应是指源任务与目标任务相同,但源域数据与目标数据的分布不同。并且,源域有许多标签样本,而目标域没有或者有很少的标签样本。需要注意的是这里所说的数据分布的不同指的是物体相同而来源不同。比如,对于自行车图像数据集,有些来自相机采集,有些来自互联网。近年来域适应广泛应用于计算机视觉任务,例如分类 [20] [21] [22] ,目标分割 [23] [24] 。因为这些任务所处理的图像虽然来源不同(通常是背景存在差异),但是图像中的主体内容相同,因此这类域适应任务较易实现。然而,在真实场景图像超分辨任务中,一般能获取到的HR-LR图像对是不配对的,即源域图像与目标域图像的主体与背景均不相同,因此很难去训练出一个鲁棒性好的模型去适应具有多样域的图像。
Yuan等 [25] 提出循环对抗网络(CinCGAN),主要的做法是利用GAN网络去将具有复杂退化样式的输入图像映射到干净的图像域(双三次插值域),然后再送入超分辨网络进行重建。其运用两个循环一致性去限制域之间的映射。不同于CinCGAN,在基于频率分离的真实场景图像超分辨方法 [26] (FSSR)中,作者利用图像的高频信息去合成与目标域图像相似的LR图像,随后以合成的HR-LR图像对去训练重建网络,使得训练出的模型可以适应真实场景下的图像。然而,上述的两种方法虽然采用生成对抗技术以及高频信息逼近来缩小源域图像与目标域图像间的域距离,但由于源域图像与目标域图像的内容不同,这种利用图像中具体信息的方式进行域逼近会在一定程度上会使得源图像丢失信息,从而导致重建出的SR图像丢失细节并且存在伪影。
基于上述研究,本文探索了一种更合理的缩小源域图像与目标域图像之间域距离的方式,提出了一种基于域适应的真实场景图像超分辨网络模型。模型主要由两部分组成:退化网络以及重建网络。第一阶段利用非配对的HR-LR图像,经过退化网络合成与真实LR图像分布相近的LR图像。第二阶段则利用第一阶段合成的图像对训练超分辨网络,重建得到SR图像。本文通过设计退化网络以及重建网络,并引入域适应损失来缩小域距离,以提高源域图像与目标域图像分布的相似性,从而改善重建效果。
综上,本方法在构建一个高效的图像超分辨网络的基础上,引入域适应损失函数。在第一阶段合成LR图像的过程中,通过域适应损失函数去优化退化网络,从而约束生成空间。在第二阶段利用合成的HR-LR图像对去训练重建网络。在重建网络训练完成后,输入测试集中的具有复杂退化样式的真实LR图像,能够重建出清晰的高分辨率图像。通过定量与定性实验,与其他常见方法进行对比,实验结果表明,本文的方法取得了更好的重建效果。此外,本文还对引入的域适应损失进行了消融实验,以验证所提出方法的有效性。
2. 模型介绍
本文所提出的网络模型分为两部分:退化网络以及重建网络。退化网络的输入是HR图像,经过退化网络合成与其配对的LR图像。并通过引入域适应损失来缩小合成的LR图像与真实LR图像之间的域距离,获得HR-LR图像对。随后,将合成的LR图像作为输入送入重建网络,利用与其对应的HR标签进行监督训练,从而使得训练出的重建网络可以适应真实场景下的图像,超分辨重建出高质量的SR图像。
2.1. 退化网络
本节将介绍所提出的退化网络的具体细节。如图1所示,退化网络主要由卷积层与激活层构成。首先对输入的高分辨率图像(HR)进行预处理,随机裁剪成256 × 256大小的图像块。然后经过第一对卷积层与激活层(退化网络中所用的激活层均为PReLU),将特征图维度从初始的3通道变换到56通道。得到的高维度特征图经过第二个卷积层,对应的参数为k5s4p2 (卷积核大小为5,步长为4,填充为2),因此可以得到原尺寸四分之一大小,即64 × 64的特征图。然后再经过激活层以及第三对卷积激活层,最后经过一层卷积,将特征图维度变回3通道,从而得到退化后的低分辨率图像(LR)。
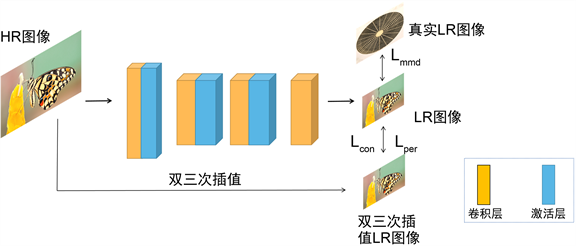
Figure 1. The structure of degradation network
图1. 退化网络结构图
退化网络通过多种损失函数进行优化,这里采用的损失包含内容损失,感知损失以及域适应损失。内容损失采用常用的L1损失,来计算HR图像经过退化网络合成的LR图像LRd与HR图像经过双三次插值生成的LR图像LRb间的距离,从而使得合成的LR图像与原HR图像保持内容一致。内容损失Lcon的计算公式如下:
(1)
其中,H,W分别代表LR图像的高和宽。
代表输入的HR图像经退化网络生成的LR图像,
代表HR图像经双三次插值生成的LR图像。对于感知损失Lper,采用通用的计算方法,即采用大规模图像识别的深度卷积网络VGG19网络中的中间卷积层来提取特征进行损失计算。其由19层网络层组成,包含5个卷积块,每个卷积块由多个卷积层组成,输入输出的通道数不同,共16层卷积层。每个卷积块后面跟随一个最大池化层。最后的3层是全连接层。卷积块中统一采用3 × 3的卷积核,卷积层的步长均为1,池化层窗口大小统一采用2 × 2,步长为2。VGG19凭借较深的网络层数可以很好的提取图像信息的局部特征。本文具体采用的是conv5_3层,即第五个卷积块的第三层卷积层。感知损失Lper的计算公式如下所示:
(2)
其中,
表示VGG19特征提取器。
除了上述提到的两种损失以外,还新提出了域适应损失。考虑到由上述构建的退化网络合成的低分辨率图像LRd与真实世界中的LR图像LRr存在较大的域分布差异,因此,本文新提出一种域适应损失,来使得生成的LR图像更逼近真实场景下LR图像的分布。具体来说,利用最大均值差异(MMD)来衡量两个数据的分布差异。最大均值差异的主要思想是如果两个随机变量的任意阶矩都相同的话,那么这两个随机变量的分布一致。若两个随机变量的分布不相同,那么使得两个分布之间差距最大的那个矩被用来作为度量两个随机变量距离的标准。其在先前的工作里主要用在迁移学习中。如风格迁移任务。本文创新性地将其应用到超分辨任务中。主要做法是:寻找一个映射函数,此映射函数可以将变量映射到高维空间,随后求两个变量在高维空间的分布距离,通过减小该距离使得合成的图像更符合真实分布。具体的域适应损失函数Lmmd如下:
(3)
其中,
代表高维空间转换函数,这里具体将源域数据与目标域数据转化为高维核空间。n,m分别表示源域图像LRd以及目标域图像LRr的维度,这里n = m。
退化网络的总损失为上述列举损失的加权求和:
(4)
其中,
用于控制域适应损失的权重。
2.2. 重建网络
经过退化网络合成的LR图像,将送入重建网络进行超分辨重建。本节将介绍重建网络的具体细节。考虑到较深的网络有着更好的特征提取以及重建能力,因此,本文采用残差密集块(RRDB)作为重建网络的主要部分。如图2所示,重建网络由卷积层,RRDB (残差密集块)以及上采样块组成。输入的LR图像首先经过一层卷积层,将特征图的维度从3 (RGB)变换到64。然后将得到的高维特征图送入23个残差密集块进行特征提取,每一个残差密集块由多个卷积层和激活层组成。然后将残差密集块输出的特征图送入上采样模块进行尺度变换。本文用的上采样方式是最近邻插值,经过两次尺度因子为2的最近邻插值,得到的特征图大小是原输入的4倍。最后经过两层卷积层,将特征图维度降为3,得到最终的重建结果。
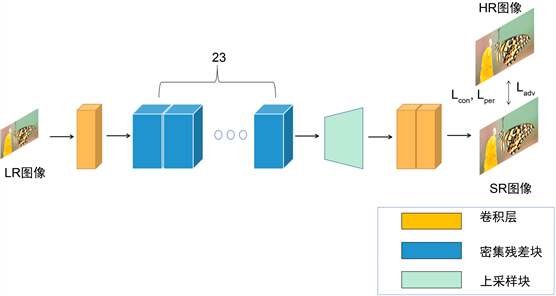
Figure 2. The structure of reconstruction network
图2. 重建网络结构图
与退化网络类似,训练重建网络的损失包含内容损失、感知损失。内容损失的计算公式如下:
(5)
其中,HR表示源高分辨图像,SR代表重建网络重建出的高分辨图像。感知损失的计算公式如下:
(6)
经过实验发现,如果仅使用上述两种损失来优化重建网络,重建出的图像效果不是很理想,在一定程度上有细节的丢失。因此,为了使得重建出的SR图像具有更丰富的细节信息,除了上述提到的两种损失外,还引入了频域对抗损失。具体来说,提取HR图像以及SR图像的高频信息,送入判别器D,让重建出的SR图像具有与HR图像相近的细节。通过利用线性滤波器来分离出图像中的低频与高频信息。为此,首先定义一个低频滤波器WL,用于提取SR图像中的低频信息。然后将源图像与提取到的低频信息进行差值操作,从而得到该图像所包含的高频信息。对标签HR图像进行相同的滤波高频提取,然后将二者的高频信息送入判别器D。其中,将输入判别器的HR高频信息作为真样本,将SR中的高频信息作为假样本,通过频域对抗损失来让SR中的高频信息逼近HR。具体的频域对抗损失如下:
(7)
其中,E代表取一个批大小的均值。WL代表低通滤波器,这里具体采用的是高斯低通滤波器。因此,重建网络的总损失为:
(8)
其中,
,
是用于控制感知损失和对抗损失的权重。
3. 实验验证与仿真分析
3.1. 数据集
由于本研究是针对真实场景下的图像超分辨率重建,因此采用的数据集并非常用的基于合成的数据集,而是已有的利用相机在真实场景中采集的图像数据,具有多样的图像类型,如建筑,动物等。具体用于模型训练的是RealSR数据集。RealSR数据集中包含真实的LR-HR图像对,是作者在不同的场景下通过调整相机焦距获得,其中包含由佳能和尼康相机采集的595对LR-HR图像对。本文采用的训练集包含DIV2K中800张高分辨图像作为HR图像,以及RealSR尼康子集下的200张低分辨图像作为LR图像,验证集包含50对图像对。实验的评估标准包含定量指标(PSNR、SSIM)以及定性的视觉质量对比。
3.2. 训练细节
本实验在NVIDIA 1080TI GPU图形显卡平台下开展。使用Adam优化器更新退化网络以及重建网络。其中对主要的参数
,
分别进行设置。在退化网络中
设为0.5,在重建网络中设为0.9,
均设为0.999。对于退化网络,输入的HR图像裁剪为256 × 256,批大小设为6;对于重建网络,输入的LR图像裁剪为128 × 128,批大小设为6。超参数
,
,
分别设置为0.005,0.01,0.005。退化网络训练300轮,学习率初始为0.0002,150轮后逐渐减少至0。重建网络训练迭代50,000次,学习率分别在5 k,10 k,30 k迭代后减半。
3.3. 对比实验
本文主要与现有的基于频率分离的真实图像超分辨方法FSSR,以及基于监督训练的模型ESRGAN进行对比实验。需要说明的是上述两种方法的预训练模型没有在RealSR数据集上进行训练,因此为了公平比较,将上述模型在RealSR的Nikon子数据集下进行重新训练。训练完成后,在验证集上进行模型性能测试,从定量与定性两个方面进行比较。表1展示的是图像超分辨结果的定量比较,衡量的指标为PSNR,SSIM。越高的PNSR以及SSIM指标代表超分辨出的图像越不失真。从表中可以看出,本文所提出的方法取得了最优的PSNR以及SSIM。除了定量的比较外,为了验证提出方法重建图像的视觉效果,与其他方法进行定性实验比较,定性的图像视觉质量的比较如图3所示。第一列为FSSR的结果,第二列为ESRGAN的结果,第三列为本文所提出方法得到的结果,最后一列为原图。
从图3中可以看出,FSSR以及ESRGAN重建出的图像具有明显的伪影,导致视觉效果不理想。本文所提出的方法可以有效减少伪影的生成,重建出的图像清晰且拥有更丰富的细节。如图中第一行的建筑图,与其他方法相比,本文的方法更能保留建筑的边缘以及轮廓信息;对于下面的字母和文字图像,前面两种方法重建出的效果有伪影且失真,所提出的方法在保持图像不失真的情况下,更多的恢复出图像细节。
3.4. 消融实验
为验证所提出的域适应损失的有效性,对新加入的域适应损失进行了消融实验,实验结果如表2所示。其中第一行的w/o Lmmd代表的是在没有引入域适应损失的情况下,模型取得的结果。第二行的w Lmmd则表示加入域适应损失后的结果。从表中结果可以看出,在加入域适应损失后,重建出的图像具有更高的PSNR以及SSIM。图4是视觉效果的对比,可以看出,加入域适应损失后,重建的图像更清晰并且能更好保持原图中的颜色等信息,从而证实了所加入的域适应损失提升了模型的重建性能。

Figure 3. The vision comparison with other methods
图3. 其他方法的视觉对比图

Figure 4. The comparison results of ablation experiments
图4. 消融实验结果对比图
4. 结论与展望
本文在分析出现有的图像超分辨方法不能很好适应真实场景中图像的原因后,在已有方法的基础上,以缩小图像间域距离为出发点,提出了基于域适应的真实世界图像超分辨方法。设计的网络结构由两部分组成:退化网络以及重建网络。网络的训练分为两阶段。第一阶段,先设计退化网络,在训练退化网络的过程中加入域适应损失,使得HR图像经过退化网络合成的LR图像与真实场景中的LR图像拥有相似的分布。第二阶段,利用第一阶段已合成的HR-LR图像对训练重建网络,使得训练出的重建网络可以适应真实场景中的图像。实验结果证明了所提出方法的可靠性和可行性。
需要指出的是,本文通过域适应损失来缩小源域图像与目标域图像之间二者的域距离,使得模型对真实世界图像有很好的泛化性,取得了令人满意的超分辨重建效果,但这样可能会导致源域图像丢失一些信息。因此,寻找一种更适合的指标去度量不同域图像间的距离,这是下一步研究的主要内容。
基金项目
安徽省自然科学基金资助(2008085MF190);安徽省高校协同创新项目(GXXT-2022-044)。