1. 引言
近年来,深度学习和自动驾驶的兴起导致了3D检测的快速发展。目前的3D检测方法主要基于LiDAR点云 [1] [2] [3] [4] [5] ,而点云的稀疏性极大地限制了它们的性能。尤其是在包含遮挡、背景干扰、噪声等的复杂场景中实现对感兴趣目标的检测识别与分割中,大部分融合机制是通过将点云映射到图像中进行融合,然而点云匹配上的像素点较少不能完全利用好图像特征,稀疏的LiDAR点云在远处和遮挡区域提供的信息较差,从而难以生成精确的3D边界框。许多多传感器融合方法提出了解决这个问题的方案。MV3D [6] 引入了一种RoI融合策略,在第二阶段融合图像和点云的特征。AVOD [7] 提出从图像特征图和BEV特征图中融合全分辨率的特征作物,以实现高召回率。MMF [8] 利用2D检测、地面估计和深度完成来辅助3D检测。在MMF中,伪点云用于骨干特征融合,深度完成特征图用于ROI特征融合。尽管他们取得了巨大的成功,但是其融合是统一转换为2D后再进行检测的,缺乏自顶向下的框架搭建,且精度方面仍然处于粗融合层次,以及点云会在3D~2D的时候产生较大的损失。
针对以上问题,本文提出如下解决方案:
• 提出了适应新技术要求的融合层级,分析对比不同融合方法之间的性能,并针对车辆前方环境的特点,自顶向下设计了基于特征级融合方案,使得框架与应用环境更契合。
• 受LSTM机制启发,拓展设计中晚期门控循环融合,有效降低了多传感器之间的对齐偏差,提高融合检测精度。
• 设计一种新的高维度表示,且匹配了专门维度编码器3D-T,专为数据融合设计,有效降低了跨模态数据融合过程中的信息损失。
• 为更好地在三维空间中提取伪点云的特征,提出了CP卷积方法。
• 通过使用数据集进行训练与验证,证明了本文方法的有效性。
2. 相关工作
2.1. 多源异构传感器融合层级
传感器融合是一个十分流行的课题,从其诞生以来的几十年来一直活跃在研究领域。多源异构传感器的数据融合传统包括三个主要步骤:时空标定、数据的对齐、异构数据之间的关联融合,然后就是具体任务步骤,如状态估计、车道线检测和语义分割等 [9] 。首先传感器融合的划分目前没有明确的定义标准来分类,大部分研究者根据融合的时期不同可以分为:前融合、中间融合和后融合,也可以称为数据级融合、特征级融合以及决策级融合。前融合指的是融合未经过处理的传感器数据;中间融合指的是各类传感器数据先经过特征提取或其他处理后再进行融合,接着再通过别的算法进行运算;后融合指的是各类传感器数据根据不同的处理算法得到处理结果,再通过加权融合得到最终决策的融合。但是,随着现价段模型复杂度的增加,从位置上越来越多的融合被划分为中间融合,这样就不能很好地区分融合层级。因此,本文提出了一个新的划分方法,通过融合后的结果在整个算法网络中充当的作用来划分。这样不仅能更有区分度,还能更好地反应融合对模型算法的作用,具体定义如图1所示。
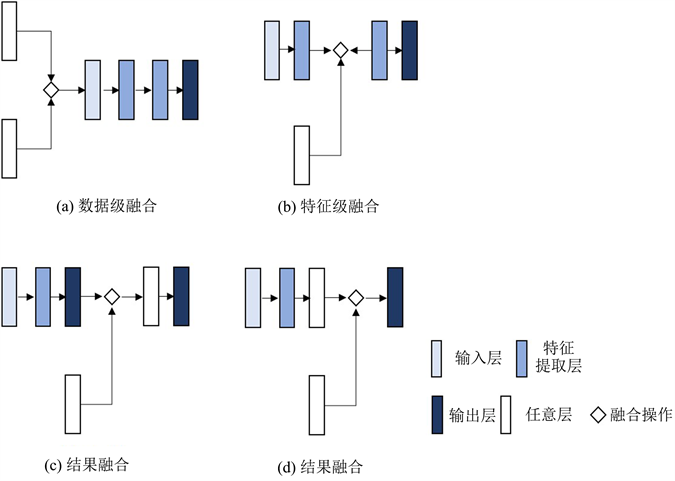
Figure 1. Examples of different fusion levels
图1. 不同融合层次示例
2.2. 循环神经网络及其变体
循环神经网络(RNN)经常在有时间序列的数据中使用,这样可以更好地处理不同时间序列之间数据的关系。通过简单的循环网络结构如图2所示,可以知道网络记忆中上一步的数据信息并且通过该信息影响输出结果。其中UVW都是权重矩阵,分别代表输层出到隐藏层、隐藏层到输出层、上一次隐藏层结果到这一次隐藏层的权重;XSO均是向量值,分别代表输入值、隐藏值和输出值。
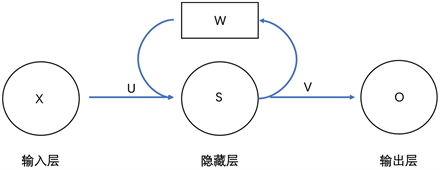
Figure 2. Simple recurrent network structure
图2. 简单循环网络结构
而在处理时序过长数据时,循环神经网络容易产生梯度爆炸和梯度消失的问题。为了解决这一问题,设计了更复杂的LSTM网络。LSTM首先在1997年由Hochreiter & Schmidhuber提出,2012年后随着深度学习在的兴起,LSTM又在若干学者(Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo, and Alex Gloves)的努力下更新迭代,由此便形成了比较完善的LSTM框架,并且在很多领域得到了广泛的应用。其相对循环神经网络更复杂,尤其是针对于记忆的长短、以及应该遗忘何种信息?记住何种信息?的问题通过:遗忘门、输入门、输出门等结构来较为完美地解决。LSTM单元如图3所示,整体来看还是一个循环神经网络架构,只是在隐藏层部分增加了复杂度,多了遗忘门、输入门和输出门三个门控单元,以及隐藏和候选单元状态(ht、ct)。单元状态表示当前t时刻的状态内容(记忆内容),而隐藏状态是模型在时间t时的输出。
两个隐藏状态执行重要的功能,即:慢速状态Ct,用于对抗梯度消失问题;快速状态ht,允许LSTM在短时间内做出复杂的决定。每个门控状态都执行独立的任务,调节单元状态和隐藏状态的记忆长短与结合程度。
2.3. 数据融合计算方法
在目标检测的融合方法中,出现过多种多样的融合计算方法,主要可以归为连接法、合并法、相加法和子网络法4种。
连接法:这种方法是最直接的方法,通过将不同模态的数据直接相连,最普遍的表现形式就是数据在维度上的增加。而直接法中又分为两种,① 把第二个传感器的数据拼接到第一个传感器的数据上,总体的层数是不变的只是每层的尺寸变大,被称为concatenate;② 在第一个传感器数据通道的基础上将第二个传感器数据平行扩展为新的通道,使得通过拓展通道来融合数据,被称为extended channel。
合并法:该方法适用于多源异构传感器数据对共同目标输出的融合,首先各个分支数据通过特征提取后产生各自的候选元素,然后通过该法进行候选框融合 [10] [11] ,具体的操作通常是加权求和。例如相机和Lidar分别获得RGB和点云信息,分别通过各自的特征提取网络获得候选框,最后再通过加权求和获得最终的结果。
相加法:通常在特征图融合和ROI处理中出现,前者通常是直接将特征图进行合并,后者又分为两种其一是将ROI进行合并 [6] 其二是将ROI叠加预设成特征检测的约束条件 [12] 。
子网络法:这种方法是近年来学者为了提升决策融合的效果提出的,通常是在现有检测网络的结果基础上再设计一个子网络对其进行特征提取,称该子网络为网中网(Network in Network, NiN)。例如对两个分支的结果预测框进行融合,此类融合输出与决策级高层特征融合的方法非常相似。
2.4. 深度补全
深度补全的目的是在彩色图像的引导下,从一个稀疏的深度图中预测产生得到一个密集的深度图。最近,人们提出了许多高效的深度补全方法。文献 [13] 利用双分支骨干网络实现了一个精确高效的深度补全网络。文献 [14] 提出了一种多假设的深度表示方法,可以在前景和背景之间锐化深度边界。尽管深度补全任务的主要目的是为下游任务服务,但在三维检测中真正使用深度补全的方法很少。在基于图像的三维物体检测中,有一些工作如文献 [15] [16] 中使用深度估计来生成伪点云。然而,由于缺乏准确或足够的原始LiDAR点云,它们的性能受到很大限制。
3. 跨模态融合方法
本文设计了一个实现智能车辆敏感环境感知的融合网络——MS3D-Net,整体分为三个部分——激光雷达点云流、伪点云流和密集高精融合头,如图4所示,其中:① 激光雷达流,仅根据原始点云数据并用RPN来生成3D ROI特征;② 伪点云流,利用所提出的CP卷积提取点特征,并利用稀疏卷积提取体素特征,再经过RPN操作得到3D ROI特征;③ 密集高精融合头,以网格化的方式融合原始点云和伪点云的3D ROI特征并生成粗预测框,且在LGRF最小单元之前通过该预测框来修正原始点云和伪点云的3D ROI特征,具体是经过裁剪和高维拼接粗预测框,然后经过LGRF单元融合,最后将输出结果传输至下一步对应的检测头。具体内容本节将分为六小节来阐述该网络的设计与搭建过程,第一小节通过控制变量方法确定了融合层级,第二小节改良了具体的融合计算方法,第三小节设计了融合框架的主体最小计算单元,第四小节对同步增强操作进行了具体阐述,第五小节具化了CP卷积,第六小节匹配了具体的损失函数。

Figure 4. MS3D-Net algorithm diagram
图4. MS3D-Net算法图
3.1. 确定融合层级
首先,为了设计出能在各种不同天气中实现良好融合效果的网络模型,本文按照不同融合时期的鲁棒性、实现效果等性能评价指标,分析对比了几种主要的融合层级,来选出最合适的融合层级。本着控制变量准则,先通过开源库KITTI收集并制作相同的数据集,接着通过基于统一方法的物体目标检测器,使用相同的训练条件和相同的输入特征,对不同的融合方法进行了定性比较。从融合效果分析、数据冗余性分析两个角度分析融合的合理性,选择最好的融合时期。
目前,有很多检测器,而这些检测器大多是三种源架构之一的变化或修改得来的,即Faster-RCNN [17] 、R-FCN [18] (基于区域的全卷积网络)和SSD [19] (单步多目标检测器)。Huang等人 [20] 分析了关于这三种源架构的利弊的更多细节,他们在准确性、速度和内存使用方面对它们进行了比较。基于这种比较,本文中选择了Faster-RCNN,因为它在准确性方面优于其他元架构,而在速度和内存使用方面没有太多的损失。
收集制作的KITTI数据集由7481张训练图像和7518张测试图像组成,相应的激光雷达数据由Velodyne的64线激光雷达采集得到。总的来说,标注的数据集包含6个不同类别(汽车、卡车、电车、行人、自行车、货车)的大约8万个标记的物体。数据集被分成训练集、验证集和测试集,测试集由数据集中前500张图像组成,训练集由接下来的6500张图像组成,验证集由剩余的图像组成。
为了通过神经网络融合照相机和激光雷达数据,必须将传感器数据转换为合适的格式,以便将数据送入神经网络。对于RGB图片数据,通过reshape操作调整为神经网络的预定输入尺寸,同时保持其长宽比不变如图5中(a)所示。对于激光雷达数据,为了降低计算损耗先相机视场外的点云数据通过ROI操作去除,再将三维激光雷达点投射到图像平面上(如式(1)~(2)),形成一个稀疏的深度图(如式(3)~(8)),最后通过邻域均值法进行插值得到稠密的深度图(如式(9)),如图5所示。

Figure 5. Data types in preprocessing
图5. 预处理中的数据类型
(1)
(2)
其中关于激光雷达图像的位置(c, r),
和
是激光雷达传感器的平均垂直和水平角度分辨率,当RGB中存在一个相应的激光雷达映射点是时候,每个激光雷达图像像素(c, r)分配相应的深度值
,不存在时深度值d会设置为无穷大。激光雷达图像B如图5中(b)所示。
(3)
(4)
(5)
(6)
(7)
(8)
式中是使用具有镜头畸变的针孔相机模型来进行矩阵变换的。其中,
和
是分别是沿x轴和y轴的焦距,
是相机的光学中心,
是其偏斜参数,
为畸变参数。与激光雷达图像类似,每个投影点
被赋予深度值
,将其他无映射点的点深度设置为无穷大。该稀疏深度图像C的示例如图5(c)所示。
(9)
该式表示以p为中心取小邻域N内的激光雷达点的平均深度的值,通过插值来填充没有深度信息的像素。该稠密深度图像D的示例如图5(d)所示。
最后,基于Faster-RCNN目标检测器搭建四种不同层次的融合网络,并通过目标检测任务进行评估各个层级网络的性能。为了模拟各种不同天气中网络的性能,在训练过程种人工加入了恶劣天气的干扰、增加噪声,检测结果如图6所示。
如图中,白色区域被随机拟合到相机和深度图像中。这是因为在耀眼的阳光下,相机图像中含有白点,而激光雷达传感器也会因为激光束的反射和吸收而在雨雪中提供较少的点。另外,当将另一个输入流设置为无穷大时,仅使用相机或激光雷达数据模拟传感器故障。
具体各个层级融合网络的检测性能如表1所示:
结果表明,传感器数据融合越靠近特征融合,目标检测器的检测率就越高,同时在部分数据失效时(通过增加噪声验证,验证结果如图6)鲁棒也更好。综上所诉,确定了最符合本文要求的融合层级——特征融合。

Figure 6. Detection results at different noise levels
图6. 不同噪声下的检测结果

Table 1. Performance test results for converged networks at all levels
表1. 各层级融合网络性能测试结果
3.2. 高维表示
针对特征利用率低这一问题,本文提出新的高维表示,使得特征保留尽可能多。高维表示为
且是一个时间序列,
,其中每个子集包含
七维数据。本文模型的目标是共同学习最佳传感器融合频率和模式组合,以正确预测期望的分类/回归目标。首先对输入数据进行预处理,使用适当的编码器3D-T在时间融合之前将信号数据变换到相同的维度。图像数据经过深度补全,转化到伪云特征图像表示,三维点云经过3D ROI操作变换到点云特征图像表示,两个支路的数据均通过ROI操作和特征提取器后,先通过裁剪和拼接操作得到新的高维表示后再通过下文的级联单元LGRF将RGB特征与点云融合得到高维深度图像,如图7高维流程图所示。

Figure 7. High-dimensional representation algorithm diagram
图7. 高维表示算法图
通过单目摄像头获取得的数据,首先经过高斯处理去除噪声。由上文中得到的稠密深度图像D,通过空间关系矩阵映射变换如式子(10)~(13),可以得到一帧伪云P。映射得到像素点对应的空间坐标后,再通过拼接法(concatenate)得到高维表示
。
(10)
(11)
(12)
(13)
式中x和y分别表示RGB图像中的像素点坐标,坐标转换矩阵是的空间关系转换的逆矩阵,其他函数定义与上文中一致。
通过64线激光雷达获取到点云数据后,为了降低计算损耗先相机视场外的点云数据通过ROI操作去除。其中,ROI是根据VoxelNet中的rpn来进行操作的,如图8。经过操作后得到点云特征图,且数据维度与前文的伪点云一致。
由于图像和点云之间的维度差距,先前的工作直接将从BEV LiDAR特征图中裁剪的2D LiDAR ROI特征和从前视场角图像特征图中剪裁的2D图像ROI特征连接起来,这是一种粗糙的ROI融合策略。在本文的方法中,通过将2D图像转换为3D伪云,这样可以以更精细的方式融合图像和点云的ROI特征,如图9所示。本文的3D-T由3D融合、网格融合和注意力融合组成。
1) 3D融合:本文使用3D ROI来裁剪3D原始云和3D伪云,其仅包括3D ROI中的LiDAR特征和图像伪云特征,如图9(b)所示。以前的方法使用2D ROI裁剪图像特征,这将涉及来自其他对象或背景的特征,如图9(a)所示,这会导致大量干扰,尤其是对于被遮挡的对象。
2) 网格融合:在以前的ROI融合方法中,图像RoI网格和LiDAR ROI网格之间没有对应关系,所以他们直接将图像ROI特征和LiDAR ROI特征连接起来。而在本文的方法中,由于原始ROI特征和伪ROI特征的表示方法相同,可以分别融合每一网格的一对特征。这就意味着能够用相应的伪网格特征准确地增强目标物体的每个体素的特征。
3) 注意力融合:为了自适应地融合来自原始ROI和伪ROI的每对网格特征,本文利用了文献 [21] 中激励的简单注意力模块。通常,通过预测每对网格的一对权重,并用权重对这对网格特征进行加权,以获得融合后的网格特征。
在此,接下来对本文的3D-T进行了详细的描述。令b表示一个单一的三维ROI。接着用
和
分别表示b中的原始云ROI特征和伪云ROI特征。这里(默认为6 × 6 × 6,遵循的基础模型是Voxel-RCNN [22] 的模型)是三维ROI中网格的总数,C是网格特征通道。
和
的第i个ROI网格特征分别表示为
和
。随机选定一对ROI网格特征(
,
),接着再将
和
拼接起来。然后将结果传输到全连接层和激活函数层,产生一对网格特征的权重(
,
),其中
和
都是标量。最后,用(
,
)对(
,
)加权,得到融合后的网格特征
。其中,
的具体公式表达如下所示:
(14)
(15)
实际实践中,一个bath中的所有ROI网格特征对都可以并行处理,因此本文的3D-T非常有效。
3.3. 中晚期门控递归融合(Late Gated Recurrent State Fusion, LGRF)最小计算单元
为了解决部分传感器子集被遮挡时融合效果下降和传感器之间时间相关性丢失这两大问题,受LSTM机制的启发,本文试提出了同时学习融合加权和时间加权的门控递归融合单元(Gated Recurrent Fusion Units, GRFU),基于此修改设计出了本文的fusion中的基本单元——LGRF (Late Gated Recurrent Fusion)最小计算单元。能够做到:1) 延迟融合,并通过M个LSTM单元并行传递每个传感器数据,允许每个传感器编码器单独决定他们各自的历史与当前传感器输入的利用程度(本文称此为晚期递归融合(Late Recurrent Summation, LRS)),同时能够根据时间维度对齐传感器数据从而减少对齐偏差;2) 为每个传感器定义门,以确定每个传感器编码对融合单元和输出状态的贡献(称之为早期门控递归融合(Early Gated Recurrent Fusion, EGRF))。有了延迟融合,时间相关性就解决了。有了门定义,在部分传感器被遮挡或者失效时就可以实时调整每个传感器的贡献度。该单元整体融合时期偏中后期,鲁棒性能更好。
在下文中,本文首先分别定义了这两个修改模块,最后将两者结合起来定义本文的主模型LGRF模型。上文中预处理后的伪点云和点云特征分别接入该模型的
和
接口,再经过LGRF融合单元融合。
在这个模型中,总共使用了2个不同的LSTM单元(每个传感器一个)。对于每个模态,分别计算遗忘、输入、输出和单元状态。模型原理图和公式分别显示在图10和公式(16)~(18)。
(16)
(17)
(18)
其中,每个门的输入空间转换权重
、
和偏置
都是与每种模态数据匹配不变的,但在不同是时间步长内是共享的。每个LSTM单元从过去时间步骤的状态(
,
)和当前时间步骤的输入
中接收信息。另外,各个传感器的每个LSTM单元没有单独的状态,而是所有的单元都接收来自前一个时间步长的相同的细胞状态(
,
)。通过这种建模选择,可以在时间上传播融合后的表征。通过在所有传感器之间共享前一个时间步长的细胞状态(
),该模型可以单独决定是否保留每种模态的信息。最后,所有的隐藏状态(
)和细胞状态(
)被添加到一起,产生一个综合的表示
和
,并将其传输到下一个时间步长。
晚期融合为模型提供了一些灵活性,可以分别控制各个传感器的记忆信息,但即使在这里,最后的求和也会融合所有的传感器数据(通过假设它们具有相同的权重)。但是,如果能从数据中了解每个传感器对最终融合状态的贡献程度就更有利于融合效果。受LSTM [23] [24] 和GRU [25] 中使用的门控机制的启发,本文在传感器融合模块中也提出了一个类似的曝光控制。对于M个传感器,定义了M − 1个门(
)来控制传感器编码(
)在最终状态
中的曝光。与 [25] 类似,本文将最后一个传感器的门控定义为
。这使得融合结果表示成为单个传感器编码的线性内插。模型示意图和方程式分别如图11和公式(19)~(23)所示。首先,使用非线性运算将传感器的嵌入数据转换为相同的维度,如公式(19)。然后,如公式(20)所示,计算M − 1门。如公式(21)所示,最后的融合是在每个门与相应的传感器编码相乘并相加后形成联合后进行的。如公式(22)~(23)所示,以at为输入进行时间建模。
(19)
(20)
(21)
(22)
(23)
门控函数对于得出见解和解释模型内发生的融合的性质很有价值。一旦学会,用户可以通过门控值解释每个传感器的贡献度,并验证它们是否符合人类对数据集中一些任意样本的见解。这种可解释性特征对于涉及安全关键任务的场景至关重要。
最后,本文使用的中晚期门控递归融合模型,它结合了晚期递归融合(独立控制每个传感器的记忆)和早期门控递归融合(学习如何融合)的最佳方面,以提高时空融合模型的学习性能。
(24)
(25)
(26)
(27)
(28)
(29)
该模型示意图见图12。与早期的门控递归融合模型类似,本文把融合门
作为所有传感器编码e * t的函数来计算,但并不是对所有传感器输入进行线性插值以得到联合输入状态at,而是使用门控来控制每个编码传递到传感器特定LSTM单元的曝光量。最终的联合单元和隐藏状态是由所有最终单元状态和隐藏状态的输出各自相加计算出来的。
3.4. CP卷积
每帧伪云定义:对于每一帧伪云p,将图像中每个像素的RGB
和坐标
拼接到其对应的伪点。因此,第i个伪点
可以表示为
。
提取伪云特征的一种简单方法是先直接对伪云进行体素化,然后对其执行三维稀疏卷积操作,而实际上它并没有充分发掘伪云中丰富的语义信息和结构信息。PointNet++是提取点的特征的一个很好的例子,但它并不适合伪云。首先,由于伪云的数量庞大,PointNet++中的球查询操作将带来大量的计算。其次,PointNet++不能提取二维特征,因为球查询操作没有考虑二维邻域关系。考虑在内。有鉴于此,需要一个特征提取器可以有效地提取2D语义特征和3D结构特征。
基于上述分析,本文提出了CP卷积,它在图像域上展开近邻搜索,灵感来自体素查询 [22] 和网格搜索 [26] 。通过这种方式,可以克服PointNet++的不足之处。首先,一个伪点可以在恒定的时间内搜索它的邻近点,这使得它比球查询操作快得多。其次,图像域上的邻域关系使得提取2D语义特征成为可能。
然而,不能将所有的伪点投射到当前帧的图像空间进行邻居搜索,因为在gt采样的情况下,来自其他帧的伪点可能会导致视场角闭塞遮挡。为此,本文提出了一种ROI感知近邻搜索。具体来说,就是根据伪点携带的
属性,将每个三维ROI中的伪点分别投射到其原始图像空间,如图13底部所示。这样一来,相互遮挡的伪点就不会成为彼此的邻近点,所以即使它们之间在视场角上存在严重的遮挡,它们的特征也不会相互干扰。
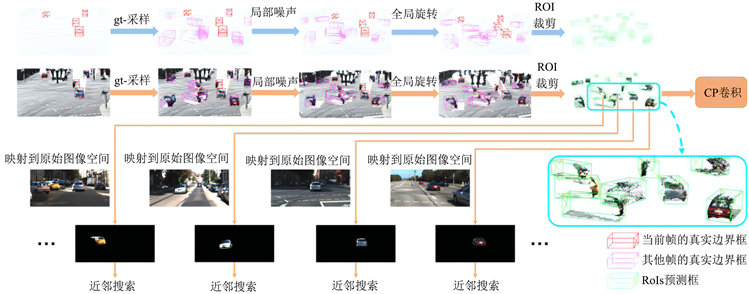
Figure 13. CP convolutional feature extraction schematic
图13. CP卷积特征提取示意图
对于第1个伪点
,本文将
的特征表示为
,它包括三维几何特征
和二维语义特征
。正如文献 [22] 中的激励函数,在进行近邻搜索之前,特意在伪点特征上应用了一个全连接层,以降低复杂性。在经过全连接层之后,特征通道被提升至到
,如图14所示。

Figure 14. CP convolutional element illustration
图14. CP卷积元图解
本文利用
与其邻近点的三维和二维位置残差,使
的特征能够知道到三维和二维空间的局部关系,这对于提取
的三维结构特征和二维语义特征尤为重要。对于
的第k个近邻点
,
和
之间的位置残差表示见式(30)。
(30)
其中
。
对于
的K个邻居,首先收集它们的位置并计算位置残差。然后,再在位置残差上应用一个全连接层,将其通道提升到
以与伪点特征对齐。给定一组相邻特征
和一组相邻位置残差
,接着用相应的
对每个
进行加权赋值。加权相邻特征被级联而不是最大池化,以获得最大的信息保真度。最后,应用一个全连接层将聚合后的特征通道映射回
。
本文将三个CP卷积堆叠起来以提取伪云的更深层特征。考虑到高层级特征提供了更大的感受野和更丰富的语义信息,而低层级特征可以提供更精细的结构信息,所以将每个CP卷积的输出拼接起来,以获得伪云的更全面和更有鉴别力的表示。
4. 实验与分析
本次实验是基于tensorflow深度学习框架,通过python 3.7编程语言采用逻辑回归方式训练MS3D-Net模型,实验硬件设备是英伟达公司的RTX 3080显卡,显存16 G,设置batch为32,学习率为0.001。
实验的具体流程如图15所示,首先基于开源库KITTI获取本文所需的车辆环境信息数据。接着制作数据集,总共收集了14,936个有效样本数据(每个样本包含图像数据和雷达点云数据),包含6个不同类别(汽车、卡车、电车、行人、自行车、货车)的大约8万个标记物体,最后按照7:2:1的比例划分训练集、测试集和验证集。
然后进行模型训练,将包含14,936个样本的数据集送入本文搭建的模型中进行多次迁移训练,并且与几种模型进行比较得到验证的P-R曲线如下图16所示。
由上图可知,MS3D-Net的方法对比其他几种方法无论是在精度(precision)还是召回率(recall)上都更高一些。根据表2,可以看出,不管是各项的精度还是平均精度(mAP) MS3D-Net都有着更出色的表现,并且检测速率与LRS相近地出色。
Table 2. Table of comparative experimental results by method
表2. 各方法对比实验结果表
最后,基于tensorflow框架部署在实验室路端智能设备项目,并且使用了TensorRT高性能推理器进行模型加速。主要由服务端模型和客户端软件构成,构建合适的服务端模型来处理客户端的请求;利用Triton-Client与OpenCV编写客户端脚本,请求服务端模型推理服务,再利用PyQt5编写了GUI,满足相应的功能需求。
安装好cuda、tensorrt、opencv、docker、NVIDIA容器、triton这些所需环境,再将脚本文件打包成可执行文件即完成软件部署。实际部署后,检测结果如图17所示。

Figure 17. MS3D-Net deployment detection results graph
图17. MS3D-Net部署检测结果图
5. 结论
本文首先对比分析了不同类型融合层对融合性能指标的影响,并且结合车辆敏感环境特点为本文确定了融合框架的层级。然后专门为数据融合设计了新的高维表示,并且提出了与之对应的融合方法3D-T,有效降低了跨模态数据融合过程中的信息损失。受LSTM机制启发,拓展设计了中晚期门控循环状态融合,有效降低了多传感器之间的对齐偏差,减少了部分传感器数据丢失或错误的影响,提升低时间相关性时的融合表现。为了提高图像特征的提取,从图像支流获得更多维度的信息,提出了CP卷积方法进行提取。最后通过使用KITTI数据集进行训练与验证,分析结果发现本文方法在提高检测精度(融合性能)的同时又保证了检测速度。该方法有效提高复杂场景中的融合效率,为进一步的检测与跟踪提供更准确与鲁棒的信息。
NOTES
*通讯作者。