1. 引言
粗糙集理论是用于处理不精确、不一致、不完备信息和知识的有效工具 [1] [2] 。如今,学者们对粗糙集理论已经进行了深入探索,相应的属性约简 [3] [4] [5] [6] 方法也较为完善。Kryszkiewicz [7] 在不完备决策系统下引入广义决策保持约简,介绍了相关决策规则的提取,并提出了基于差别矩阵的广义决策保持约简方法。差别矩阵方法虽然可以求出所有约简结果,但其效率相对于启发式算法较低。2002年王国胤等 [8] 从信息论观点出发,将条件信息熵作为启发式信息,设计了启发式属性约简算法;2018年,Gao [9] 提出了最大决策熵的启发式属性约简算法。2019年Zhang等 [10] 等提出了启发式的广义决策属性约简。
现阶段,对于大规模数据集,有关属性约简的快速算法研究已取得许多成果。2006年,徐章艳等 [11] 提出了基于基数排序的快速属性约简算法;2010年,Qian等 [12] 提出了正域加速属性约简算法,2018年,Du等 [13] 在序决策系统下提出了快速属性约简算法。另外,增量式属性约简算法 [14] [15] [16] [17] 利用已有的信息进行增量更新,不需要重新计算,从而实现算法效率的提高。本文从对象和属性的角度考虑研究,通过理论分析和实验结果均表明了该算法的有效性。
2. 基本概念
定义1 [1] 信息系统是由四元组
组成,其中U表示论域,是非空有限对象组成的集合;AT表示非空有限属性集合;
表示属性
的值域,有
;f是一个映射函数,
为论域U中的每一个对象在
上都有一个值。若
,其中C表示非空有限的条件属性集合,D表示非空有限的决策属性集合,且
,则四元组记为
称为决策信息系统。
定义2 [1] 四元组
为一个决策信息系统,对任意非空属性集合
,有
P在U上的不可区分关系定义为:
(1)
不可区分关系
是一个满足自反性、对称性和传递性的等价关系。由不可区分关
导出对论域U的划分为
,通常简写为U/P,其中
表示包含x的等价类,易得
。
定义3 [1] 决策信息系统的四元组
,由决策属性D导出U的划分为
,对
,决策类U/D关于条件属性集P的下近似和上近似的定义为:
(2)
(3)
决策类U/D关于条件属性集P的正域和边界域的定义:
(4)
(5)
定义4 [9] 决策信息系统
,U在C以及D上的划分分别为
,
,其中
,
。对于任意一个等价类
,
该等价类的最大包含度以及最大决策分别定义为:
(6)
(7)
定义5 [9] 决策信息系统
,U在C以及D上的划分分别为
,
,其中
,
。C相对于D的最大包含度的概
率分布定义为:
(8)
定义6 [9] 决策信息系统
,若
,Q相对于D的最大包含度的概率分布定义为
,那么对于任意一个等价类
的最大决策熵以及B相对于D的最大决策熵分别定义为:
(9)
(10)
3. 基于最大决策熵的启发式约简
定义7 [9] 决策信息系统
,若
,
,q的内部属性重要度定义为:
(11)
定义8 [9] 决策信息系统
,若
,
,q的外部属性重要度定义为:
(12)
定义9 [9] 决策信息系统
,
,
,若
,则q为核属性;若
,则q为冗余属性。
定义10 [9] 决策信息系统
,若
是C的一个约简,当且仅当满足以下两个
条件:
1)
;
2) 对
,有
。

Table 1. Fast reduction algorithm based on maximum decision entropy (ACC_HA_MDE)
表1. 基于最大决策熵的快速约简算法
4. 基于最大决策熵的加速算法
定理1决策信息系统
,
,若
,其中,
,
,
,并且
,则
。
证明:若
,
,其中
。因此对每个等价类
,存在决策类Y,使
。用
表示在U上的最大
决策熵。
由于
,所以
,又因为
,其中
,
,
,故
。同理可得
。因此
,所以
。因此,若
,则
。
通过表1所示的ACC_HA_MDE算法,可以快速计算基于最大决策熵的属性约简。其中ACC_HA_MDE
在步骤5的时间复杂度为
;而在表2所示的HA_MDE算法在步骤4的时间复杂度为
。因此,ACC_HA_MDE的效率更高。
Table 2. Attribute reduction algorithm based on maximum decision entropy (HA_MDE) [9]
表2. 基于最大决策熵的属性约简算法 [9]
5. 实验分析
实验环境采用Intel Corei3-9100 (3.6 GHz)处理器、8 GB内存和Windows10操作系统。算法使用Python语言进行编写,在开发工具PyCharm2020上编译运行。
为了验证提出算法的有效性,本实验选取了8组UCI数据集,为了更好验证所提出算法的有效性,需要对数据集进行预处理。首先将数据集使用WEKA3.8.5进行等频离散化,并将数据集中名词性数据转化为整数表示。对于缺失数据,利用对应属性下占最多比例的属性值进行替换。表3展示了每个数据集的相关信息。在实验过程中,将各数据集按对象数目分成10份(每份为
),或将各数据集的属性每份分成
。
约简效率对比
本节对HA_MDE与ACC_HA_MDE两种算法的约简效率进行比较分析,通过8组UCI数据集进行实验展示。表4展示了HA_MDE与ACC_HA_MDE两种算法的时间以及约简长度。可以看到7个数据集的ACC_HA_MDE算法的时间比HA_MDE算法的消耗的时间少。例如Audit-risk数据集,本文提出的算法ACC_HA_MDE耗时0.32 s,而启发式算法HA_MDE运行时间为2.01 s,HA_MDE运行时间约为ACC_HA_MDE运行时间的6.281倍。而Hill数据集,本文提出的算法ACC_HA_MDE相对于HA_MDE耗时较多,由于该数据集在迭代中删除的正域与属性不够多,使消耗时间增多。由于删除的是冗余属性和对象,所以两种算法的约简长度相同。
Table 4. Comparison of time and reduction length of HA_MDE and ACC_HA_MDE algorithms
表4. HA_MDE和ACC_HA_MDE两种算法的时间与约简长度比较
图1中用实心六边形折线表示HA_MDE、用实心倒三角形折线表示ACC_HA_MDE,展示了两种算法在8组数据集上随论域大小变化的时间消耗曲线,横坐标表示论域大小,纵坐标表示算法运行时间。从图1中可以看到除了Hill数据集外,其余7个数据集在本文提出的算法ACC_HA_MDE运行时间相对于HA_MDE运行时间较短。因此,本文提出的ACC_HA_MDE算法相对于启发式HA_MDE算法提高了算法效率。
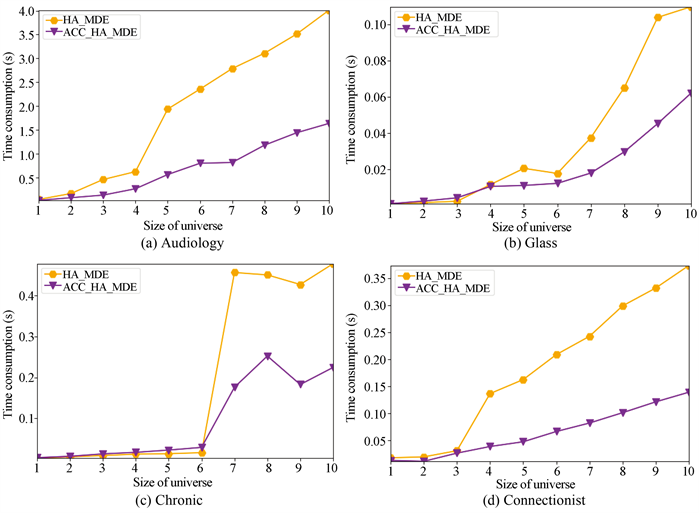

Figure 1. Comparison of algorithm reduction efficiency with object increase
图1. 随着对象增加算法约简效率的比较
6. 总结
本文针对基于最大决策熵的约简目标提出了在完备决策信息系统下的快速属性约简算法。在每轮迭代中首先删除一部分正域,使数据集中对象数目减少,以提高算法的效率;其次删除冗余属性,可以进一步提高算法的效率。实验选取8组UCI数据集对提出的算法进行有效性验证,实验结果表明:本文提出算法的效率优于经典算法的效率,实现了对经典算法的优化。
基金项目
本文受烟台市科技计划项目(编号:2022XDRH016)的资助。