1. 引言
在电力行业中,大部分工作场合需要工作人员持有特种作业操作证才能上岗,特别是在一些安全性要求比较高的场所,如发电站、变电站等,要求每一名工作人员必须佩戴有效的电工作业、带电作业或高空作业证件才能进入,防止不相关人员进入工作场所产生安全风险。过往的证件检查方式采用人工识别方式,需要配置一名工作人员在岗亭或门卫处检测每一位进出工作场所人员是否佩戴有效证件。随着人员数量增加,传统的人工检查方式难以满足实际需求,因此需要采用一种自动智能识别证件的方式,本文提出采用计算机视觉技术进行工作人员的证件识别。首先,采用计算机视觉技术进行证件识别可以提高识别准确率和效率,同时减少工作量和人力成本。其次,通过计算机视觉技术识别的电力业务证件信息,电网公司可以进一步分析数据,统计不同类型证件的使用频率,为证件管理和业务流程优化提供依据。最后,采用计算机视觉等前沿技术手段,可以让电力企业在技术和管理水平上实现现代化,这也是智慧电网建设的一部分。总之,计算机视觉技术为电力企业数字化转型提供了技术支撑,其应用于电力业务证件识别可以带来安全性、效率、精确性等诸多方面的提高,有利于电力企业实现现代化发展。因此,这一技术应用具有非常重要的意义。
目前,国内外已有许多计算机视觉技术在电力领域上的应用研究,并取得了一些优秀的成果。首先,在电力设施定期巡检的应用上有基于视觉技术的输电线路巡检 [1] ,具体的有机器人巡检 [2] 、直升机巡检 [3] 、无人机巡检 [4] [5] 以及遥感卫星巡检 [6] 等。其中无人机巡检已发展为我国输电线路巡检的主要运维方式 [7] [8] 。为提高输电线路自动化巡检水平,众多学者致力于无人机图像中电力设备的识别与缺陷检测研究 [9] [10] 。在电力设备图像特征提取方面,主要集中在深度学习方法 [11] 上。如采用目标检测算法的高压线关键部件检测方法 [12] 、采用FastCNN的高压线缺陷检测 [13] 、基于视觉的变压器缺陷检测 [14] 等。因电力设施及其工作环境特殊性,如天气变化,光线变化等,对于视觉技术的检测算法有较大的困难,在弱光环境下识别率低的情况比较严重。
在电力行业特别是对于电力业务证件的识别场景中,由于背景图像复杂以及光线不足等情况容易造成识别率低的问题,因此,本文提出一种基于CBAM注意力机制 [15] 的YOLOv5检测算法,通过引入CBAM注意力机制可有效提高背景复杂及光线不足的情况下检测精度。通过实验数据分析验证了改进YOLOv5检测算法相对原有算法在检测精度提升9.33%。
2. 目标检测技术
2.1. 目标检测技术基本原理
目标检测(Object Detection)是计算机视觉的一个重要任务,其的目的是在指定图像中检测所需要的目标物体,并识别每个目标的类别和确切位置。目标检测主要包括两个子任务:1) 分类(Classification):识别图像中目标的类别,如人、车、动物等。2) 定位(Localization):确定每个目标的空间位置,一般用边界框表示。
目标检测技术的原理主要包括:1) 图像分割:将输入图像分割成多个区域,然后判断每个区域是否包含目标。典型的方法有滑动窗口和区域检测等。2) 特征提取:从输入图像中提取特征,通常使用深度学习网络来自动学习特征。这些特征包含用于分类和定位目标的语义信息。3) 分类器:使用机器学习算法训练一个分类器,可以判断输入特征是否包含目标。常用的方法有SVM、Softmax等。4) 边界框回归:训练一个回归模型来预测目标的边界框,一般直接在特征图上进行回归预测。5) 锚框:使用预定义的锚框来预测目标的位置和尺寸。典型算法如YOLO会在特征图上的每个单元预测锚框与目标的偏移,从而定位目标。6) 非极大值抑制:当多个锚框预测同一个目标时,会选取评分最大的框作为预测,其它框会被抑制从而过滤重复检测。7) 置信度预测:预测每个锚框属于目标的概率值,以区分目标和背景。通常使用Sigmoid激活函数将预测值压缩到0~1之间。
2.2. 目标检测技术研究现状
计算机目标检测算法的发展历程主要有三个阶段:1) 传统机器学习时代:这一阶段主要使用手工提取的特征,结合SVM、AdaBoost等机器学习算法进行检测。优点是计算简单,缺点是特征提取依赖人工,泛化能力较差。2) 深度学习时代:这一阶段开始使用CNN自动学习特征,然后采用分类器进行检测。代表方法有OverFeat、RCNN系列等。优点是特征表达能力强,缺点是计算复杂,速度较慢。3) 单阶段检测时代:此阶段的检测算法可预测目标的类别和位置,无需区域提议等中间步骤。代表方法有YOLO、SSD等。优点是速度快、精度高、效率好,已成为主流方法。目前,目标检测技术正处于第三阶段,单阶段检测器时代。这一阶段的算法花费较少,速度快,精度也较高,并且数据集和计算资源也越来越丰富,所以这一阶段的算法表现也在迅速提高,具有更广泛的应用。
2.3. YOLOv5
YOLOv5是YOLO (You Only Look Once)系列模型的稳定版本,由Ultralytics公司研发。相比其前几个版本,YOLOv5在速度、精度和轻量级方面都有很大提升。
YOLOv5的技术原理是基于one-stage目标检测器,并采用了自注意力机制和跨阶段连接等技术。具体来说,模型首先输入一张图片,并通过特征提取网络(backbone)提取出图像的特征图。然后,采用多层感知机(MLP)对特征图进行回归和分类,以预测出目标的位置、类别以及置信度分数等信息。
在网络结构方面,YOLOv5采用CSP (Cross Stage Partial Network)模块来替代传统的ResNeXt模块,提高网络的性能以便加快训练速度。同时,为了进一步提高检测效果,YoloV5还引入了自注意力机制,以便更好地捕捉图像中的上下文信息,并在跨尺度特征融合时提高特征重要性。此外,YOLOv5还采用了PANet (Path Aggregation Network)和SPP (Spatial Pyramid Pooling)等技术,以进一步改进特征融合和特征提取的效果,从而提高整体检测性能。YOLOv5的网络模型如图1所示。

Figure 1. The network model of YOLOv5
图1. YOLOv5网络模型
3. CBAM注意力机制
CBAM (Convolutional Block Attention Module)是结合空间和通道的注意力机制,它可增加神经网络提取图像特征的能力。CBAM引入了两个不同的注意力机制模块,具体为通道注意力机制及空间注意力机制,来增强输入特征图中的相关信息。通道注意力机制主要用于学习通道之间的相关性,帮助模型更好地理解特征图中的语义信息。空间注意力机制主要用于学习空间上不同目标的相关性,可提高模型对图像中结构信息的理解能力。CBAM将这两种注意力机制结合在一起,以获得更精确的特征表示,从而提高神经网络的性能。
3.1. CBAM注意力机制原理
CBAM可用于各种常用的卷积神经网络中,如ResNet、VGG、DenseNet等。在实际应用中,CBAM通过添加注意力模块的方式来改进网络架构,它由两个子模块组成:
1) 通道注意力机制(Channel Attention Module)通过全局平均池化和最大池化对通道维度的特征图进行聚集,获得通道描述符,然后利用两个并行的共用1 × 1卷积层对这两个描述符学习Adaptive Weights,通过Sigmoid激活函数获得注意力的权重,最后通过通道乘积获得加权的特征图。通道注意力机制模型如图2所示。
为了汇聚空间特征,采用全局平均池化和最大池化两种方式来分别表示不同的信息。
(1)
其中
表示Sigmoid函数,
,
。输入
是的特征F,先分别进行空间全局平均池化和最大池化得到两个
的通道数据。接下来,再将它们分别输入到一个两层的神经网络,第一层神经元个数为C/r,激活函数为Relu,第二层神经元个数则为C。这个两层的神经网络是互相结合的。然后,将得到的两个特征向量相加后经过一个Sigmoid激活函数得到一个权重系数
。最后,用权重系数与原特征F相乘便可得到缩放后的新特征向量。
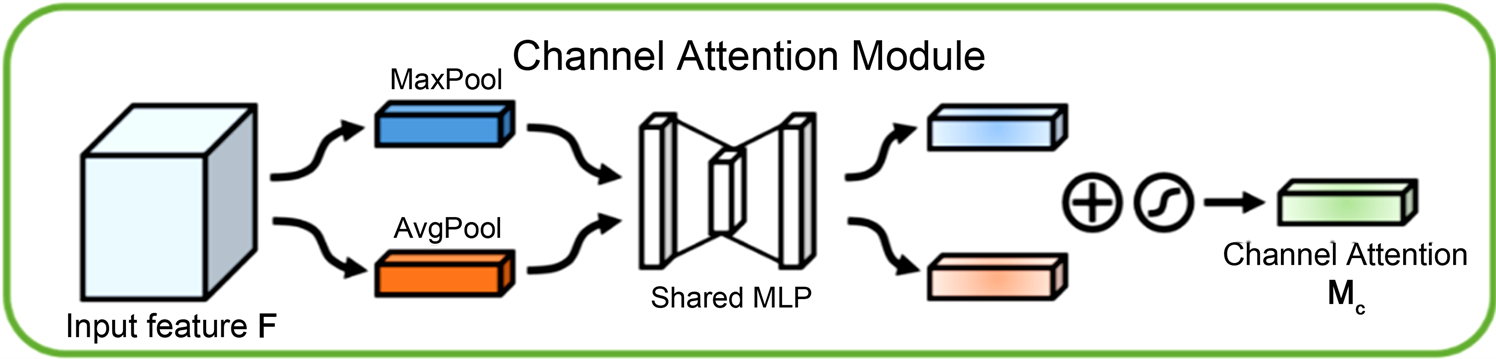
Figure 2. Model structure of channel attention mechanisms
图2. 通道注意力机制的模型结构
2) 空间注意力机制(Spatial Attention Module)对输入特征图的每一个通道进行最大池化和平均池化,获得空间描述符,然后通过两个1 × 1卷积层和Sigmoid激活函数来学习空间的注意力权重,最后通过点乘获得加权的特征图。空间注意力机制模型如图3所示。
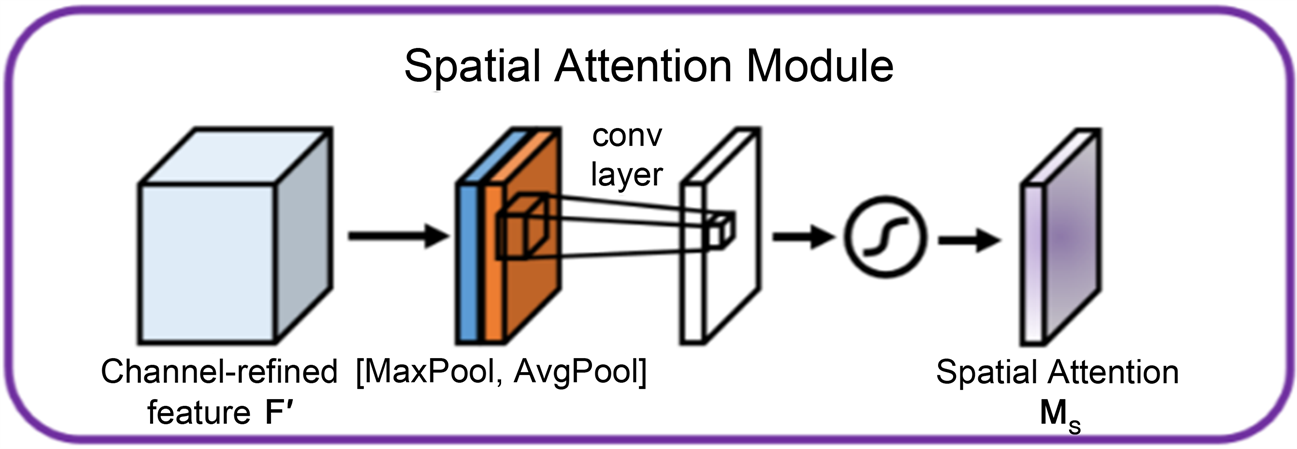
Figure 3. Model structure of spatial attention mechanism
图3. 空间注意力机制模型结构
引入空间注意力模块主要用于关注哪些特征是有意义的。
(2)
与通道注意力相似,给定一个
的特征
,先分别进行一个通道维度上的平均池化和最大池化,得到两个
的通道信息,并将这两个信息按照通道拼接在一起。然后,经过一个激活函数为Sigmoid的7 × 7卷积层,得到权重系数
。最后,用权重系数与特征
相乘便可得到缩放后的新特征向量。
3) 残差连接:CBAM模块最后将输入特征图和两个注意力模块的输出特征图进行相加作为最终输出,这种残差连接可以避免信息的损失。CBAM模型结构如图4所示。
3.2. 使用CBAM注意力机制改进YOLOv5目标检测算法
基于CBAM注意力机制的YOLOv5目标检测算法是本文对YOLOv5算法的一种改进,通过引入CBAM模块来增强特征表示能力。在该算法中,首先使用YOLOv5模型提取原始图像的特征图,然后在特征图上添加CBAM模块来进行特征增强。CBAM利用结合通道注意力机制和空间注意力机制来提升神经网络对特征的提取能力,从而实现更精确的目标检测。
具体来说,基于CBAM注意力机制的YOLOv5算法的主要流程包括以下步骤:首先使用预训练的YOLOv5模型对原始图像进行特征提取,得到一个高维度的特征图。接着,在每个残差模块之后加入一个CBAM模块,采用通道注意力机制与空间注意力机制进行图像特征的增强。加入CBAM模块后,再利用回归器对特征图进行处理,得到目标检测的结果。具体来说,回归器会对每个网格预测包含的物体的边界框坐标、置信度得分以及类别信息,从而实现多目标检测。基于CBAM的YOLOv5模型结构如图5所示。
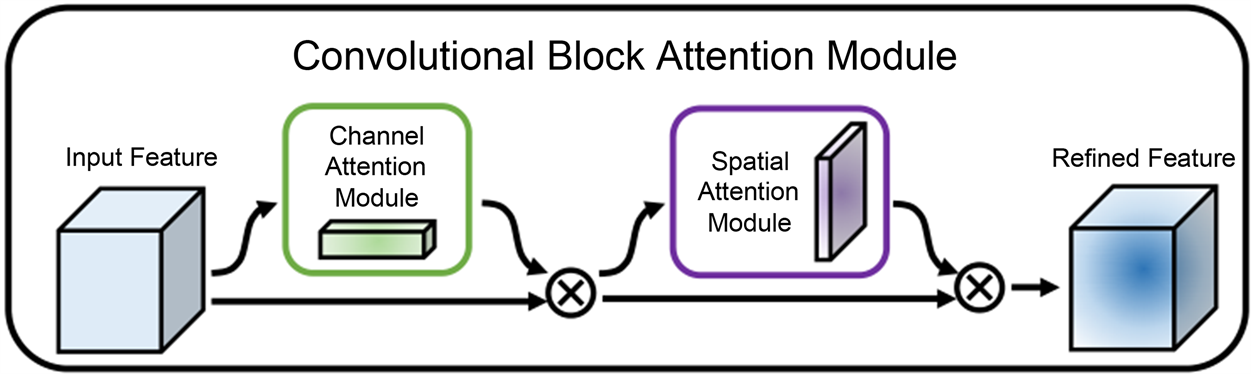
Figure 4. CBAM attention mechanism model
图4. CBAM注意力机制模型
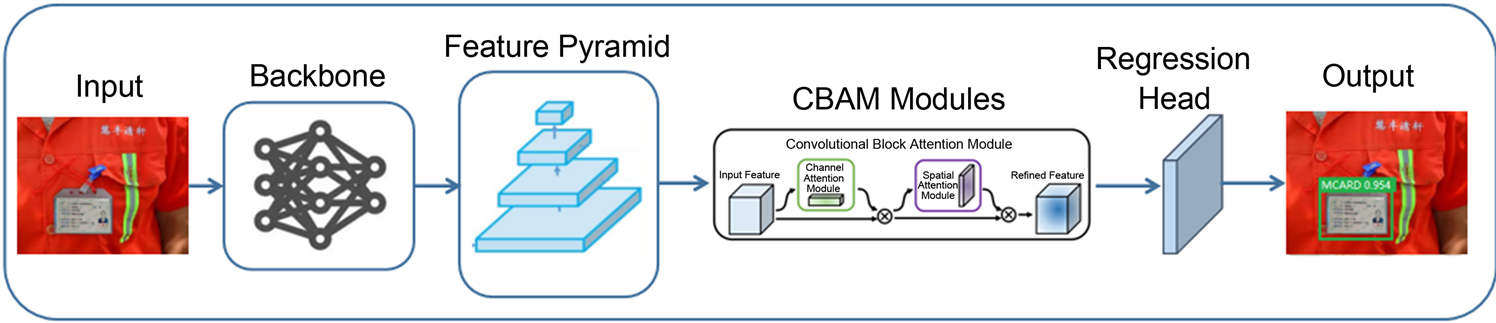
Figure 5. The YOLOv5 model based on CBAM
图5. 基于CBAM的YOLOv5模型
4. 数据与模型
4.1. 数据集制作
本文数据集主要来源于实验室制作的图像样本和在网络中收集的部分证件图像,数据集涵盖了身份证、工作证、特种作业操作证、电工证书等常用的电力系统工作人员证件,并且制作了在不同工作环境下的证件佩戴样本,使样本多样和广泛。训练和检测的对象主要针对工作人员在特定场景下的设备操作、业务办理等情况进行。数据集如图6所示。
4.2. 数据处理
本次从现场及网络原始收集到图片3000张,经挑选去除重复和失真样本得到2000张有效样本图片。因样本数量较少容易产生过拟合,本文对数据集进行了增强,采取的样本增强方法有旋转、翻转、调色等,因此共得到2000 × 5 = 10,000张数据集样本图片,如图7所示。每个数据集都包含原始收集的数据集。
鉴于YOLOv5实际不需要太高分辨率原始图像,故统一将所构建的数据集照片尺寸压缩到640 × 640大小,然后对数据集样本进行标签制作,将外围框坐标位置进行记录,给定类别标签,将制作好的数据集随机分割。其中70%用作训练,20%用作验证,10%用作测试集。数据集样本数量如表1所示。

Table 1. The sample size of the dataset
表1. 数据集样本数量
4.3. 模型训练
本文使用Pytorch框架搭建算法开发环境,采用YOLOv5实现网络模型的初步训练,然后引入CBAM注意机机制改进YOLOv5算法,再对样本进行二次训练,得到2个不同算法的模型。使用4.2节中的数据集作为训练样本。实验系统配置参数如表2所示,训练配置参数如表3所示。
Table 2. System configuration parameters
表2. 系统配置参数
Table 3. The training configuration parameters
表3. 训练配置参数
对深度学习模型的评价有多种不同的指标,因此会产生不同的评价结果,需要结合实际应用场景,选择有针对的指标进行评估才能得到更优的检测效果。本文选取准确率、召回率和平均准确率均值进行评估。
1) 准确率:
预测结果中准确识别出目标与所测试的图片数量的比值。预测结果中两种情形为:记正确预测的样本数量为CP,错误预测的样本数量为FP。则准确率P如式(3)所示。
(3)
2) 召回率:
预测结果中未识别出目标与所测试的图片数量的比值。预测结果中两种情形为:记正确预测的样本数量为CP,未预测的样本数量为NP。则召回率R如式(4)所示。
(4)
3) 平均准确率均值:
首先计算某一类别的平均准确率AP如式(5)所示。
(5)
在平滑PR曲线上,其中
,即是召回率R在不同点位上的平均准确率。
平均准确率均值mAP则是对所有AP 求平均值,如式(6)所示。
(6)
其中,APi为第i个类别的平均准确率,n为类别的数量。
5. 实验结果与分析
电力证件检测模型的训练需要进行网络参数的微调与优化。在训练阶段,使用7000张随机选择的图像进行模型训练,迭代次数为1000。改进前后随迭代变化的损失曲线如图8所示。
由图8可看出,损失函数随着迭代次数的增加而降低,在达到一个数值后便趋于稳定。其中,YOLOv5模型的损失在训练过程中波动相对较大。本文提出的基于CBAM注意力机制改进的YOLOv5模型的损耗比改进前低,波动较小。大约300次迭代后收敛,最终稳定在约0.56。
为了检测改进后模型的优越性,结合所选择的评价指标,在测试集中将本文方法与YOLOv5、SSD、Faster R-CNN等常用的目标检测算法进行对比。不同模型在所选的指标上的测试结果如表4所示。
Table 4. Comparison of the results of several commonly used object detection algorithms
表4. 几种常用目标检测算法结果对比
从表4可以看出,Faster R-CNN的检测时间最长,达到0.109 s。YOLOv5对每个图像的检测时间最短,但检测精度不高。与YOLOv5、SSD和Faster R-CNN相比,本文的基于CBAM改进的YOLOv5检测模型在检测准确率与平均准确率均值指标上达到最好效果。算法检测时间为0.056 s,比改进前的0.043 s有一定的增加,这个结果也足够在电力系统业务上使用要求。图9为不同场景下检测模型的检测结果。

Figure 9. Comparison of the detection results of four detection algorithms in different lighting scenes
图9. 4种检测算法在不同光照场景的检测结果对比
从图9可以看出,SSD、Faster R-CNN、YOLOv5在多种光线场景下(光照充足、光照较暗)总体检测精度相对较低,特别是在光照较暗时有低于0.7的情况。而本文方法在多种光线下的检测精度都优于YOLOv5算法,检测精度最大有0.162的提高,可以应用于多种光线较暗的场景下的电力系统证件识别。
6. 结束语
本文提出了一种用于电力系统中业务工作证件识别的改进YOLOv5模型,通过引入CBAM注意力机制提高了特征提取的准确率。在数据集制作与处理过程中采用了多种变换方式对数据集进行了扩充增强,解决数据集太小容易出现训练过拟合问题。实验结果表明,相对于原有的YOLOv5算法与常用的目标检测算法,本文算法可明显提高证件识别的平均准确率,平均准确度均值为95.40%,检测时间为0.056 s。本研究仍然存在一些不足,如并对证件进行部分遮挡的识别进行研究,后期将增加更多数据集,对证件进行不同部位进行遮挡,进一步研究本算法对遮挡证件的识别性能。
基金项目
本文由“南网高层次人才特殊支持计划”项目资助。
NOTES
*通讯作者。