1. 引言
随着我国铁路总里程的不断增长以及智能运维智能列检需求的不断提升,对图像数据质量的要求也越来越高 [1] 。然而,轨道交通领域的数据采集不可避免地会遇到恶劣照度或者恶劣天气场景,在这些场景下采集的图像数据质量难以满足后续图像处理算法的性能要求 [2] 。比如夜间采集的图像或在列车底部等光照不强的区域采集的图像,因为照度低或者照度不均匀,存在纹理模糊、对比度低的现象;再比如在雾天或者在雨天天气采集的图像,存在雨雾遮挡的问题,导致图像清晰度低,目标物体难以辨别。这些恶劣场景下的图像在被后续图像处理算法应用时,如在目标检测、语义分割等算法应用中,算法性能被数据质量限制而难以达到令人满意的结果。因此,提升恶劣照度与恶劣天气场景下的图像数据质量,将有利于改善后续图像处理流程的性能。
在进行图像增强提升数据质量,一方面是人类视觉体验的提升,另一方面对于机器视觉的感知与理解也会有帮助,探索同时使两者受益的总体框架是一个关键问题。现有的研究大多仍以各自解决路线上的问题为目标,他们的模型不足以超越自己的目的(仅用于人类视觉或机器视觉之一) [3] 。
针对恶劣天气和恶劣照度场景下的图像增强算法层出不穷 [4] - [9] ,既有传统方法也有基于深度学习的方法,涵盖学科理论多种多样。其中涌现了一些经典算法性能令人印象深刻。比如,对于低照度图像,Tao Li等人提出了一种自适应非线性彩色增强方法 [10] ,可以在基本保持图像亮区不变的情况下对图像暗区进行亮度与对比度增强;Rahman等人提出了多尺度Retinex增强方法 [11] ,基于Retinex理论实现了低照度增强功能。对于带雾图像,何凯明等人发现了清晰图像存在暗通道的统计规律,并基于此提出了暗通道去雾算法 [12] ,开创了基于暗通道进行去雾的先河;Xu Qin等人提出了一种特征融合图像去雾算法 [13] ,通过引入通道注意与像素注意并将其融合构建了去雾网络,取得了较好的去雾效果;对于带雨图像,Wei等人提出了提出了一种简洁的视频去雨模型 [14] ,利用基于块的高斯混合模型对雨层进行编码实现去雨功能;Dongwei Ren等人提出了一种渐进递归去雨网络算法 [15] ,通过重复展开浅ResNet并引入递归层,提供了一个有效、简单的基线去雨网络。
然而,当前这些算法大部分仅针对一种场景,没有形成一个整体的框架,也不考虑增强算法与其它高级视觉任务级联的效果,无法自适应地同时应对多种恶劣场景。在轨道交通中的高级视觉任务如障碍物目标叫测与轨道语义分割,训练数据大多设计在清晰的环境中执行,图像增强对于这些任务的提升效果不在单一场景增强算法的考虑范畴。本文提出了一种轨道交通低能见度场景图像增强系统,可以自动识别图像是否是低照度这样的恶劣照度场景或者识别是否是雨天雾天这样的恶劣天气场景,识别后可以有针对性地对图像进行低照度增强或者去雨去雾处理,从而提升图像质量。将该系统运用于轨交场景下的目标检测与语义分割应用中,实验表明,该系统可以有效提高目标检测和语义分割的准确率。
2. 系统框架设计
本文所提出的轨道交通低能见度场景图像增强系统方案如图1所示,主要包括5个模块,即照度分类模块、低照度图像增强模块、天气分类模块、图像去雨模块和图像去雾模块。当系统接收到一张待处理图像时,首先通过照度分类模块判断该图像是否是恶劣照度图像,若为低照度图像则接入低照度图像增强模块进行增强,增强后的图像能够在较好地保留图像亮区特征的情况下对图像暗区进行亮度和对比度增强,恶劣照度条件下的图像质量主要受低照度影响较大,天气情况在低照度下不易观察,因此对恶劣照度图像不做进一步的天气划分;若照度分类模块判断输入图像不是低照度图像,则接入天气分类模块以判断图像是否是在恶劣天气情况下拍摄;若判定图像为雨天天气,则接入图像去雨算法对雨痕进行去除,以消除雨痕遮挡对后续图像处理应用的影响;若天气分类模块判定图像为雾天天气,则接入图像去雾算法对图像进行去雾,以削弱雾天不清晰图像对后续流程的影响;而对于其它的照度与天气均正常的清晰图像,系统则不需要对其进行增强,直接输送到后续的图像应用中。
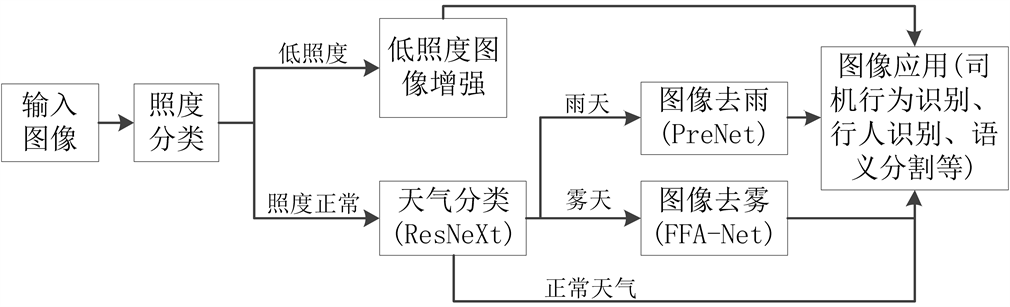
Figure 1. Image enhancement system of low visibility scene in rail transit
图1. 轨道交通低能见度场景图像增强系统
3. 恶劣照度下的图像质量提升
3.1. 基于主聚类推定的照度分类算法
为了让系统可以自适应地处理不同照度图像,需要对输入的图像进行照度分类以便区分处理。本文采用了一种基于主聚类推定的照度分类算法。
照度分类算法主要分为6个步骤:
S1获取RGB格式图像并将其转换到HSV空间,提取照度分量
。
S2对图像
进行多尺度高斯滤波:
对照度分量
进行多尺度高斯滤波,公式如下:
(1)
(2)
(3)
上述公式中,
为采集的RGB图像转换到HSV空间获取的照度V分量,是待预处理照度分量,
为第k个高斯模板函数,
表示卷积运算,
为抽取的第n个高斯尺度下的照度图像数据,
为第k个高斯模板函数的标准差,n表示总共有n个高斯滤波模板,w为尺度配比,且
,
为对照度分量
进行多尺度高斯滤波后的输出值。
S3设置迭代的初始值:
(4)
(5)
(6)
其中,M和N分别表示矩阵
的行数与列数。
S4定义迭代次数
,按照主聚类推定算法 [16] 公式更新mn和sn值。
S5满足迭代停止条件或者达到迭代次数上限k时,停止迭代,至此得到了照度分量
的主要像素照度估计值mn。
S6设置经验阈值
,若
则认为是低照度图像,否则认为是正常照度图像。
3.2. 全局局部信息相结合的图像增强算法
若照度分类模块判定输入图像为低照度图像,则需要对输入图像进行增强,本文在自适应非线性彩色增强方法 [10] 的基础上,提出了一种全局局部信息相结合的图像增强算法对图像进行增强,算法主要分为4个步骤:
步骤S1:从获取的RGB图像中提取图像照度分量并进行多尺度高斯滤波预处理;
设
,
,
为输入RGB图像三通道值,x、y分别表示图像像素横轴和纵轴坐标,则照度分量
可由如下公式计算得到:
(7)
(8)
其中
是未归一化的照度分量,max表示求最大值。
对照度分量
进行多尺度高斯滤波,公式如下:
(9)
(10)
(11)
上述公式中,
为采集的RGB图像转换到HSV空间获取的照度V分量,是待预处理照度分量,
为第k个高斯模板函数,
表示卷积运算,
为抽取的第n个高斯尺度下的照度图像数据,
为第k个高斯模板函数的标准差,n表示总共有n个高斯滤波模板,w为尺度配比,是根据图像场景设置的经验值且
,该多尺度滤波的配比可以进行调节以便获得最佳的增强效果,
为对照度分量
进行多尺度高斯滤波后的输出值,是预处理后获取的照度图像数据。
步骤S2:图像照度自适应增强,采用一种非线性的函数对所述预处理后的照度图像
进行自适应变换,公式如下:
(12)
(13)
上述公式中,
为增强后的照度图像数据,参数z与照度图像
的直方图相关。L为
的累积分布函数等于0.1时对应的照度值。
步骤S3:图像局部对比度增强。
对预处理后照度图像
使用多尺度侧窗保边滤波,通过下式进行:
(14)
(15)
上述公式中,
,该多尺度滤波的配比可以进行调节以便获得最佳的增强效果,
表示第p个基于均值滤波的侧窗保边滤波函数,
为对应的滤波输出,
为多个尺度侧窗保边滤波的加权输出值,
表示卷积运算。
对侧窗保边滤波输出进行对比度增强,通过下式进行:
(16)
(17)
(18)
上述公式中
为照度图像
的标准差,
为一极小值防止除数为0,可取
,
、
以及q为计算过程的中间值。
的求解即为所述的使用非线性函数对侧窗滤波输出进行图像对比度增强,
为对比度增强后的照度图像。
步骤S4:图像色彩恢复。
计算增益因子,定义如下:
(19)
上述公式中,
为一极小值防止除数为0,可取
,
为对比度增强后的照度图像,
为对照度分量
进行多次高斯滤波预处理后获取的照度图像数据,a为增益因子上限,可以根据不同场景设置不同的上限值,场景一般可分为夜晚场景,白天场景,或者按照照度大小分为多个等级的场景。
使用上述增益因子,由增强后的照度图像转化为三通道彩色图像,公式如下:
(20)
(21)
(22)
上述公式中,
,
,
分别表示色彩增强后的输出图像的R通道、G通道和B通道像素值,
,
,
为对应的输入彩色图像像素值。t为色彩增益因子。
使用全局局部信息相结合的图像增强算法对轨道交通场景中的车载接触网运行状态检测系统(3C系统)内弓网低照度图像进行增强,效果如图2所示,由图可见增强后图像的亮度和对比度得到提升。

Figure 2. Before and after low light image enhancement for rail scenes
图2. 轨交场景低照度图像增强前后对比
4. 恶劣天气下的图像质量提升
4.1. 天气分类算法
若照度分类模块判定输入图像为照度正常图像,则接入天气分类模块以进一步判定有无影响图像质量的恶劣天气发生。本文采用一种基于ResNext的分类算法 [17] 来对图像天气进行分类。模型网络结构如表1所示。
ResNeXt模型是ResNet网络模型 [18] 和Inception系列网络模型 [19] [20] 的结合体。ResNeXt借鉴Inception的“拆分–变换–聚合”策略,不同于Inception的是,ResNext不需要人工设计复杂的Inception结构细节,而是每一个分支都采用相同的拓扑结构。ResNeXt结构相比于ResNet,可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。
ResNeXt块结构如图3所示。

Table 1. ResNeXt network model
表1. ResNeXt网络模型

Figure 3. ResNeXt basic block structure
图3. ResNeXt基本块
将基于ResNeXt的天气分类模型运用于构建好的包含雾天、雨天、雪天以及清晰度较高的正常天气图像数据集中,分类结果混淆矩阵如图4所示,其中标号0、1、2、3分别表示正常天气、雾天、雨天及雪天,分类总体精度达到97%。
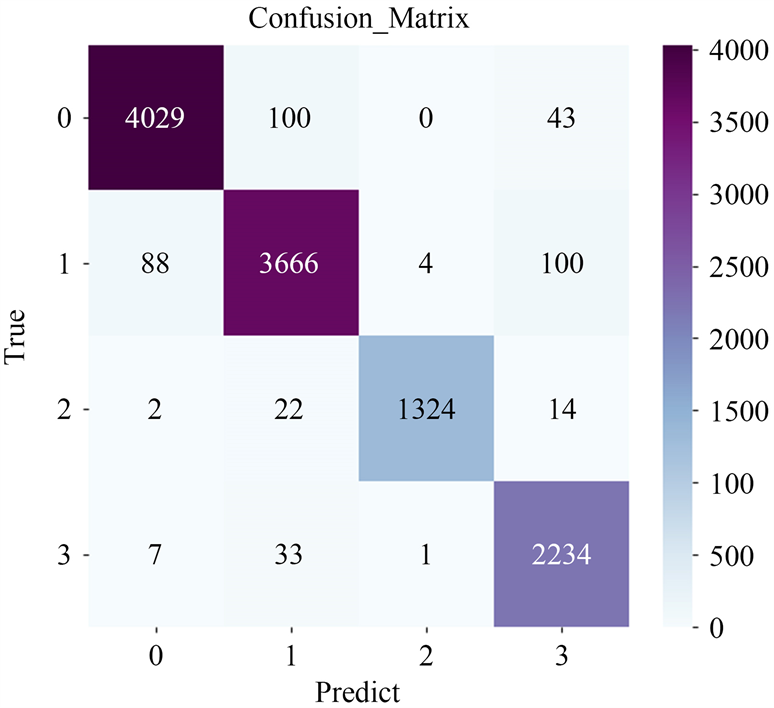
Figure 4. Confusion matrix for weather classification
图4. 天气分类混淆矩阵
4.2. 图像去雾算法
若天气分类模块判定图像时雾天图像,则接入图像去雾模块对图像进行去雾处理。本文采用FFA-Net网络模型 [13] 来实现图像去雾,FFA-Net网络模型如图所示,FFA-Net网络模型主要有3个部分组成,即包含了通道注意(Channel Attention, CA)和像素注意(Pixel Attention, PA)的特征注意模块、包含局部残差学习网络与特征注意模块的基本块结构以及特征融合结构(feature fusion attention)。FFA-Net网络模型如图5所示。
将FFA-Net去雾模型在轨交场景下的雾天图像数据集中进行测试,去雾前后对比如图6所示,从图可见去雾后图像更加清晰。

Figure 6. Comparison of rail transit scene image before and after defogging
图6. 轨交场景图像去雾前后对比
4.3. 图像去雨算法
若天气分类模块判定图像是雨天图像,则接入图像去雨模块对图像雨痕进行去除。本文采用PReNet网络模型 [15] 来实现图像去雨,PReNet通过重复展开浅ResNet,并进一步引入递归层,以利用跨阶段的深层特征的依赖性,形成最终的渐进递归网络,PRe-Net是循环迭代优化的,其网络结构如图7所示。
将训练好的PRe-Net去雨模型应用于轨交场景下的雨天图像数据集中进行测试,去雨前后对比如图8所示,从图中可见雨痕基本得以消除。

Figure 8. Comparison of rail transit scene images before and after rain removal
图8. 轨交场景图像去雨前后对比
5. 系统在轨交场景中的应用
为了更好地衡量本文所提系统的性能,评价其对目标检测、语义分割等应用准确率的影响,本文选取车载接触网运行状态检测装置(3c系统)中的低照度图像、列车前方道路的带雨和带雾图像作为实验对象,设置两组对照组,即图像经过本文所提系统处理和不经过任何处理,依次评价系统对后续处理流程的影响。
本文系统将作为插件的形式,对图像做增强预处理,并将与处理后的图像输送到后续图像处理流程中。所有实验程序均是在Ubuntu16.04系统中运行,硬件方面选用125G RAM、NVIDIA Tesla T4 GPU和2.10 GHz Intel(R) Xeon(R) Silver 4110,软件方面选用Ubuntu16.04(64位)操作系统,CUDA版本为10.0,CuDNN版本为10.0。
在实验中自适应恶劣场景图像质量提升系统所涉及的参数设置如表2所示。
5.1. 目标检测
选择单阶段检测网络YOLOv4 [21] 作为目标检测网络,采用与原始YOLOv4相同的网络架构和损失函数。本文提出的轨道交通低能见度场景图像增强系统作为插件的形式添加在模型前。原始YOLOv4模型依次在轨交场景的弓网图像数据集以及轨交场景的列车前景图像数据集上进行了训练,输入图片分辨率为640 × 640,批尺寸(batch_size)设置为8,采用均值交并比(mIOU)作为评价指标,采用目标检测框的面积交并比(IOU)阈值为0.5的平均精度均值(mean Average Precision, mAP)作为模型评价指标。
首先,对于高铁3C场景的低照度图像,在经过系统处理前与处理后依次输入训练好的基于YOLOv4的目标检测模型中,待检测的目标有接触网吊弦与受电弓两个目标,模型检测结果如表3所示,系统处理前与处理后的低照度图像目标检测效果如图9所示。
mAP@[0.5]数值越高,说明目标检测的性能越好,准确率越高。由表3可知,在经过本文所提系统处理后,对接触网吊弦与受电弓的目标检测准确率提高了1%,从图9可以明显观擦到,经过系统处理后低照度图像的整体亮度与对比度得到了增强,原图像无法检测到的接触网吊弦在增强后可以被检测到。
Table 3. Comparison of multiple target detection accuracy of different algorithms
表3. 不同算法的多目标检测准确率对比




Figure 9. Comparison of object detection results before and after low illumination image enhancement
图9. 低照度图像增强前后目标检测结果对比
其次,将带雨带雾的列车前景图像输入基于YOLOv4的多目标检测模型中,待检测的目标有行人、汽车、信号灯、障碍物、列车、站台、卡车等多个目标,同样采用目标检测框的面积交并比(IOU)阈值为0.5的平均精度均值(mAP)作为模型精度水平的衡量标准,检测结果如表3所示,系统处理前与处理后的雨天与雾天图像目标检测效果分别如图10与图11所示。
通过表3可知,在经过本文的轨道交通低能见度场景图像增强系统处理后,雾天图像和雨天图像的目标检测准确率分别体高了1.3%和6.1%,在雨天类图像数据集上提升效果显著。
从图10可以观察到,在雾天这类恶劣天气情况下采集的图像,在本文系统处理后图像清晰度得到了提升;在雾天时候会发生将行人识别为障碍物的错误情况,而图像去雾后目标检测模型可以正确地识别人与障碍物;同时,对于被雾遮挡的小目标如远端的小汽车,系统处理前有漏检的情况,处理后可以检测更多的小目标。
从图11可以观察到,在雨天这类恶劣天气情况下采集的图像,在本文系统处理后图像雨痕得以消除,图像更加清晰;雨天图像因为有雨痕遮挡,像小轿车这类小目标容易误检,而系统处理后小轿车能够被检测到;同时,因为雨痕的存在,模型容易误检出更多的障碍物,在本文系统对图像预处理后这种误检得以减少。




Figure 10. Comparison of object detection results before and after image enhancement with fog
图10. 带雾图像增强前后目标检测结果对比




Figure 11. Comparison of object detection results before and after image enhancement with rain
图11. 带雨图像增强前后目标检测结果对比
5.2. 语义分割
本文提出的轨道交通低能见度场景图像增强系统,除了应用于目标检测外,还在训练好的基于DeepLabV3+模型 [22] 的语义分割应用中进行了测试,采用与原始DeepLabV3+相同的网络架构和损失函数,模型输入图片尺寸为640 × 640,输入对比图像为系统处理前后的列车铁轨带雨带雾图像,采用均值交并比(mIOU)作为评价指标,测试结果如表4所示,系统处理前与处理后的雾天与雨天图像语义分割效果分别如图12与图13所示。
Table 4. Comparison of semantic segmentation accuracy between different algorithms
表4. 不同算法的语义分割准确率对比
mIOU值越高,语义分割准确率越高。通过表4可知,在经过本文的轨道交通低能见度场景图像增强系统处理后,雾天图像和雨天图像的语义分割准确率分别体高了1.95%和4.81%,与目标监测应用的测试效果类似,也是在雨天类图像数据集上提升效果更显著;
从图12可以观察到,在雾天天气下的语义分割试验中,有雾遮挡时远处的铁轨难以被识别,有时候甚至会将轨道边的人行道误识别为铁轨,在本文所提系统与处理后,语义分割模型可以识别更大面积的铁轨,减少误识别的现象。
从图13可以观察到,在雨天这类恶劣天气情况下采集的图像,因雨痕遮挡,模型难以识别远处以及阴影处的铁轨,而本文所提系统对图像预处理后模型可以识别更多远处及阴影处的铁轨,这提高了语义分割模型的准确率。




Figure 12. Comparison of semantic segmentation effects before and after image enhancement with fog
图12. 带雾图像增强前后语义分割效果对比




Figure 13. Comparison of semantic segmentation effects before and after image enhancement with rain
图13. 带雨图像增强前后语义分割效果对比
6. 结语
本文提出了一种轨道交通低能见度场景图像增强系统,该系统通过基于主聚类推定的照度分类算法识别图像是否在恶劣照度条件下采集,通过基于ResNeXt网络的天气分类算法识别图像是否是在雨天、雾天这样的恶劣天气条件下采集,若识别为恶劣条件下采集则系统可以自适应地根据图像情况,对图像使用全局局部信息相结合的彩色增强方法进行低照度增强,或者使用基于FFA-Net的去雾算法进行图像去雾,或者使用基于PRe-Net的去雨算法进行图像去雨,提高图像的整体质量。
本文所提系统在轨交场景中的目标检测和语义分割应用中进行了测试,系统作为插件的形式嵌入到应用中对图像进行预处理,试验表明,本文方法可以较好地对低照度、雨雾天气图像进行增强,提高图像清晰度与对比度,在轨交场景中的低照度图像、雾天图像测试集中提高目标检测及语义分割模型约1%的准确率,在两个应用中可提高雨天图像测试集4%以上的准确率。