1. 引言
在传统电力业务系统中,信息录入通常采用人工手动输入的方式进行。由于电力业务系统涉及到大量的文本信息,因此信息录入环节存在以下问题:首先是时间成本高,人工录入需要耗费大量的时间和人力成本,特别是对于一些繁琐、复杂、大量的数据录入任务,会导致效率低下,甚至会影响业务运作;其次是容易出错,人工录入容易出现错漏、重复或错误的情况,尤其是对于一些格式复杂、结构不规则的文本信息,人工录入难以保证准确性;最后是不便于数据挖掘,传统的人工录入方式难以将信息数字化,不便于后续的数据分析、挖掘和应用。基于以上问题,采用自动化的辅助录入系统 [1] ,可以有效减少人工录入的时间和错误率,提高数据的准确性和可靠性,同时也有利于后续做进一步的数据分析。
为解决在电力业务系统中信息录入带来的问题,目前已经研究出多种辅助录入方法,主要包括有:1) 光学字符识别(OCR)技术 [2] [3] [4] ,该技术可以将手写或印刷文字转化为可编辑的数字或文本格式。因此,应用OCR技术可以有效地减轻人工录入的负担,提高数据录入的效率。但是,OCR技术对于一些特殊格式、结构不规则的文本信息识别存在一定的局限性。2) 语音识别技术 [5] [6] [7] :语音识别技术可将语音输入信息转化为纯文本格式,进一步提高电力业务系统中信息录入的效率。但是,目前的语音识别技术精度还不够高,需要更多的研究和改进。3) 手写数字识别技术 [8] [9] :针对电力行业中涉及大量手写数字的情况,手写数字识别技术可以将手写数字转换为数字字符,从而提高信息录入的准确性和速度。4)基于机器学习的文本分类算法 [10] [11] [12] [13] :通过训练模型,实现对文本数据的自动分类和识别,可以减轻人工录入的负担。
以上所研究的方法都是为了减轻电力业务系统中的信息录入负担,但每种方法都有自己的局限性,只能在特定的应用系统上使用,通用性表现不佳。为解决这个问题,本文提出基于卷积神经网络(Convolutional Neural Network, CNN) [14] 的文本框识别算法,该算法可以自动识别和定位各种电力业务系统中的文本框,在不改变原有系统架构的前提下提升了自动辅助录入系统的效率与通用性。
2. 文本框识别算法综述
2.1. 卷积神经网络原理
卷积神经网络(CNN)广泛用于语音识别、图像识别、自然语言处理等领域。相比于传统神经网络,卷积神经网络在利用卷积层和池化层的结构特征上更具优势,从而在保留空间相关性、降低参数复杂度的同时,提高模型的准确率和效率。
卷积神经网络由多个卷积层、池化层和全连接层构成。其中,卷积层与池化层是卷积神经网络的核心部分,负责提取特征并降维。卷积操作可以通过卷积核对输入数据进行滑动计算,从而提取局部的空间信息。池化操作则可对卷积层输出进行降采样处理,进一步减少的计算复杂度和模型参数量,同时也有一定的避免过拟合的效果。在构建卷积神经网络时,不同的层次需要根据具体任务来进行调整,以达到更好的性能和效果。通常,卷积神经网络从低层到高层逐渐提取抽象的特征,并将其输入到全连接层进行分类或预测。卷积神经网络的基本结构如图1所示。
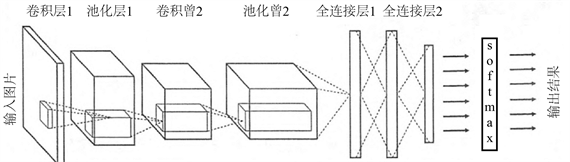
Figure 1. Basic structure of convolutional neural networks
图1. 卷积神经网络基本结构
卷积神经网络每层都包含多个神经元,相邻的层之间输入与输出关系如表达式:
(1)
其中f是非线性激活函数,w为权重矩阵,x为输入矩阵,b为偏置矩阵,y为输出矩阵。卷积神经网络采用均方差E(MSE)做损失函数,它的具体定义为:
(2)
其中
为网络的输出值,
为真实值,N为样本量。卷积神经网络通过最小化损失函数来优化网络连接权重参数:
(3)
其中
和
表示网络迭代更新前后的权重参数,
为学习速率或步长。
2.2. 文本框识别算法分类及其特点
文本框识别算法是一类针对图像中包含的文本框进行检测和识别的算法,应用广泛于自动化办公、证件识别等场景。根据其具体实现方式和特点,可以将其分为以下四种类型:
1) 基于分类器的方法:该方法最早出现且应用广泛,主要思想是通过训练分类器学习文本框的特征,如颜色、形状、纹理等,并提取出文本框的位置信息。代表算法有基于Haar特征的AdaBoost算法、基于HOG特征的SVM算法等。但是其缺点是受限于特征提取阶段的表现,结果不够准确。
2) 基于深度学习的方法:这种方法已经成为目前文本框识别的主流方法。主要是利用卷积神经网络提取特征,通过RPN (Region Proposal Network),即区域提议网络,来产生候选文本框,再利用RNN等方法进行识别。代表算法有Faster R-CNN、Mask R-CNN、EAST等。这种方法准确率更高,且能够处理各种尺寸和形状。
3) 基于联合学习的方法:这种方法主要是将文本框识别和OCR (Optical Character Recognition)结合起来,通过联合训练来提高整个系统的准确率。代表算法有CTPN (Connectionist Text Proposal Network),并且其能够直接生成识别结果。
4) 基于检索的方法:这种方法主要是先依据图像的视觉特征对文本框进行建模,再使用一些与检索相关的技术完成文本框的定位和识别。代表算法有基于SIFT特征的信息检索技术、基于DPM的物体检测方法等。
综上所述,文本框识别是一个复杂的问题,不同的算法都有其独特的优势和适用场景,需要根据具体情况选取合适的算法。而基于深度学习的方法随着人工智能技术的日益发展得到了更多人的青睐。
2.3. 基于CNN的文本框识别算法研究现状
基于卷积神经网络(CNN)的文本框识别算法已经成为了当前文本框检测和识别的主流方法之一,其准确性和鲁棒性都有了很大的提高。以下是该领域的一些研究现状:
1) Faster R-CNN:这是一个经典的基于CNN的文本框检测算法,首先通过RPN (Region Proposal Network)提出文本框候选区域,再通过ROI (Region of Interest) Pooling将候选区域缩放到固定大小,最后利用多层感知机进行分类和回归,得到文本框的位置和类别信息。
2) EAST:这是一种基于CNN的文本框检测和识别方法,其主要特点是采用了“分离–聚合”的策略,即将文本框在不同的尺度和方向上进行分离,再对其进行聚合。该方法分别采用了两个分支网络来检测文本框的位置和识别文本,能够有效地处理各种尺寸和方向的文本框。
3) TextBoxes++:这是一个基于CNN和全卷积神经网络(FCN)的文本框检测和识别算法,其主要特点是针对文本框检测和识别的两个任务分别对网络进行优化。检测阶段采用了FCN对图像进行密集的像素级预测,识别阶段则采用了一种自底向上的策略,逐层聚合文本框的特征信息。
4) CRAFT:这是一种端到端的基于CNN的文本框检测和识别算法,其主要特点是利用字符级别的信息来推测文本框的位置和方向,再通过分支网络来细化文本框的位置和形状。该方法能够处理曲线、弯曲和斜体等各种形状的文本框。
总的来说,基于CNN的文本框识别算法在近年来得到了广泛的研究和应用,其不断提升的准确性和鲁棒性为文本框识别应用提供了强有力的支持。在众多基于CNN的文本框识别算法中,Faster R-CNN凭借着其识别速度快与准确率高的特点得到了更广泛的应用。
3. 基于卷积神经网络的文本框识别算法设计与实现
3.1. 网络结构设计
3.1.1. Faster RCNN网络
基于文本框在同一个画面中可能出现多个,且样式或大小并不一致,本文采用的卷积神经网络模型是Faster RCNN [15] ,它可以自动识别图像中的物体,并在物体周围框出一个方框,相对于其他的网络模型,Faster RCNN在多目标识别精度与速度上有明显优势。在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression,classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。网络结构设计参考了python版本的VGG16模型中的faster_rcnn_test.pt的网络结构,如图2所示。
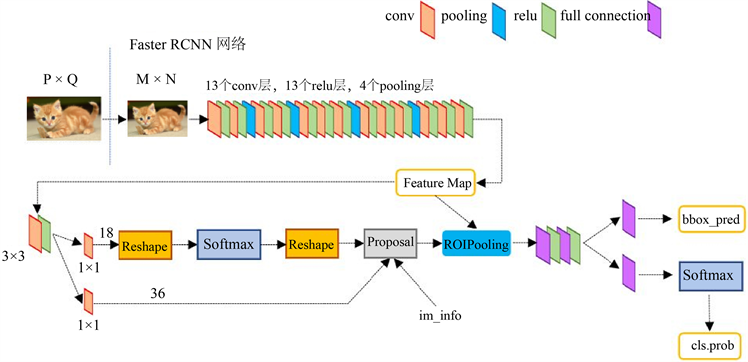
Figure 2. Faster RCNN network structure
图2. Faster RCNN 网络结构
Faster RCNN网络的基本结构主要分为4个部分:
1) 首先对尺寸为P × Q的图像缩放至M × N,然后将M × N图像送入网络;
2) Conv layers中包含了13个conv层,13个relu层,4个pooling层;
3) RPN网络首先经过3 × 3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;
4) Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification (即proposal的类型)。
3.1.2. 网络优化
因数据集数量限制,网络可能会出现过拟合情况,为降低这种情况的发生概率,需要对网络进行优化。目前一些解决方法包括参数正则化、数据增强、Dropout等技术。考虑文本框数据集样式难以使用传统的方式进行数据增加,本方采用L2正则化与Dropout [16] 技术来改善网络性能以降低过拟合的情况发生。
L2正则化是一种参数正则化方法,可以有效地限制网络模型的复杂度,从而避免过拟合现象。其主要思想是在损失函数中加入一个权重衰减项,这个项与网络参数的平方和成正比,从而对大的权重施加较大的惩罚,使得网络的参数权重变得更加均匀,避免出现小部分权重过大的情况。通过对网络参数加以限制,L2正则化能够让网络的泛化能力得到提升,从而提高网络性能。直观上就是L2正则化是对大数值的权重向量进行惩罚。鼓励参数是较小值,如果
小于1,那么
会更小。对应的损失函数为:
(4)
其中
是未加正则项的损失,
是一个超参,控制正则化项的大小。
Dropout是一种随机节点屏蔽方法,可以使得每个神经元只有一定概率参与网络训练和预测过程,从而减少参数之间的耦合关系,降低过拟合风险。其核心思想是在每次迭代中随机删除一定比例的节点,并将其激活置为0,其他节点的输出按比例进行缩放,从而保证网络具备随机性,减小网络中神经元之间的依赖关系,增强网络的泛化能力。在实际应用中,为了进一步增强Dropout方法的效果,通常还会结合L2正则化使用,以达到更好的防止过拟合和优化性能的效果。
另外,为了提升模型训练的效果,引入Adam (Adaptive Moment Estimation)优化器,它是一种基于梯度下降算法的优化方法,它结合了动量法和自适应学习率方法,能够快速且有效地优化神经网络的参数。其核心思想是利用每个时间步的梯度和梯度平方的指数加权移动平均来调整学习率,更好地适应不同参数的梯度情况,并在迭代初期更快地进行收敛。
3.2. 数据集构建
3.2.1. 数据集获取
本文框数据集主要从网上获取带有文本框的图片及网页,所收集数据样本图片包括了PC端、移动端(包括平板电脑及手机)的网页及应用图片,使样本多样和广泛。训练和检测的对象主要针对不同样式、风格、颜色、大小的文本框等情况进行。本文共收集包含文本框的正样本数据集共20000张图片,同时收集了不包含文本框的负样本数据集2000张图片。数据集示例如图3所示。
3.2.2. 数据标注
本文采用LabelImg进行数据标注,LabelImg标注工具输出的数据格式可以是XML或者CSV,其中 XML 格式是最常用的。在LabelImg中进行标注后,将标注结果保存为一个标注文件。默认情况下,会生成与图像文件名相同的XML文件,其内容包括了每个目标物体的位置和类别信息。XML格式的标注文件通常包含以下内容:
图像宽度(width)
图像高度(height)
图像深度(depth)
目标名称(name)
目标矩形框的左上角和右下角坐标值(xmin、ymin、xmax、ymax)
下面是一个使用LabelImg生成的XML标注文件的示例:
3.3. 模型训练
本文采用sklearn库的train_test_split函数对数据集进行分割,其中训练集70%,验证集20%,测试集10%。采用py-faster-rcnn框架进行模型训练与验证,训练参数设置如表1:

Table 1. The training configuration parameters
表1. 训练配置参数
模型经过1000个epochs训练,从图4中可看出,当迭代到500时,损失达到比较稳定,训练集与验证集的平均误差都小于0.005,模型训练结果较好,通过对测试集的数据进行测试识别成功率达到99%以上,对于文本框识别效果较好。
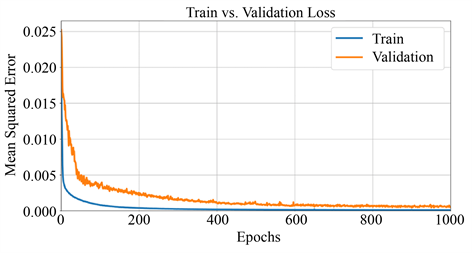
Figure 4. Training set versus validation set loss
图4. 训练集与验证集损失对比
4. 电力业务系统中的应用
4.1. 电力业务系统的特点分析
电力业务信息系统需要对各种类型的数据进行采集和录入,以获取全面的系统业务信息,同时需要保证数据质量高、速度快、可靠性强、标准化、格式化;另外为适应更广泛的用户群体,电力业务终端通常会部署多个不同系统版本的应用程序,如苹果系统APP终端、安卓系统APP终端、微信小程等。为了快速提升信息录入质量与速度,需要配套相应的辅助录入系统。辅助录入系统可以通过格式识别和校验、数据提取和转换、快捷输入、自动保存和恢复、数据智能验证等功能,辅助用户进行信息录入。其中,文本框识别算法可以准确定位信息系统中的文本输入框并自动模拟点击输入,进一步提高信息录入的速度及准确性。这些功能共同作用,旨在实现信息系统的高效运行和服务水平的提升,为电力业务的发展提供有力的支持。
4.2. 辅助录入系统设计
辅助录入系统设计原则主要包括有:首先,不改变原有电力业务系统中的系统架构及使用方法;其次,自动识别所需要录入的信息及录入位置;再次,智能提醒用户进行相关信息来源证件的拍照;最后,自动进行拍照证件的信息提取与录入。另外一个关键的考虑因素是系统具有平台通用性,可兼容苹果与安卓系统。辅助录入系统算法流程如图5所示。
4.3. 实验结果和分析
本文辅助录入系统针对某电网公司的一款用户端APP进行了辅助录入功能的测试,测试环境包含了安卓系统端及苹果系统端。主要测试用户在进行注册及完善信息时输入地址信息的辅助录入功能,所用测试数据包含地址信息的证件类别包含有身份证、户口本、居住证等。每组证件采用20人次不同的身份证件进行测试,测试次数为30次并求出平均值,人工录入的测试则以18~70岁不同年龄阶段的人员进行测试。辅助录入系统与人工录入的结果比对如表2所示。

Figure 5. The algorithm process of Auxiliary input
图5. 辅助录入算法流程
Table 2. Comparison of test results
表2. 测试结果对比
通过测试结果可知,辅助录入系统在录入时间上比人工录入方式缩短10倍以上,并且在准确率上也有4%~5%的提升。同时对不同系统终端的兼容性上,进一步表明辅助录入系统的通用性。
5. 结束语
本文将基于卷积神经网络的文本框识别算法应用到了电力业务系统中的辅助录入系统上,通过对不同证件的地址信息录入的测试,结果表明相对于人工录入在录入速度及准确率上有较明显提升,特别对于年龄大的用户来说具有重要的应用意义。基于卷积神经网络的文本框识别算法的一个主要特点是在不改变原有系统的架构前提下通过图像处理方式对文本框进行识别与定位,不需要关注具体的系统类型与应用类型,可广泛适用于电力业务中的各种信息系统,具体有较大的应用前景。
基金项目
本文由“南网高层次人才特殊支持计划”项目资助。
NOTES
*通讯作者。