1. 引言
近年来,随着网络的快速发展,在丰富了广大人民生活的同时也使他们的生活得到了改变。人们更容易通过互联网获取信息,然而在互联网爆炸式发展的今天,网络上的文本有着数量庞大、内容复杂、类别繁多等特性,人们需要用大量的时间来过滤真正有意义的信息,从各式各样的文本数据中提取出需要的信息,渐渐成为人们日常生活的必然需求。
文本分类作为自然语言处理(NLP)中一个十分经典的应用,已经诞生几十年了,发展十分迅速,从传统的文本分类模型包括朴素贝叶斯、支持向量机、K 近邻、决策树、逻辑回归等,到深度学习下的文本分类包括CNN模型、RNN模型、BERT模型、Attention机制的诞生,可以更好的利用词序的特征。随着样本和网络深度的增加,模型分类的精度越来越高,基于深度学习的方法已经在各项文本分类任务上,超越了传统的基于机器学习的方法,成为当前文本分类的主流方法。为了提高人们的用户体验,文本分类模型应该尽可能具有高的分类精度,同时文本分类模型的推理时间也必须满足响应速度快的要求。为了令分类模型在满足系统响应速度要求的前提下具有尽可能高的准确率,一种有效的方式是采用知识蒸馏(KD)来完成分类模型的训练,知识蒸馏的核心思想为:利用具有较强特征提取能力的大型深度学习模型对数据集中的深度知识进行学习,然后将这些深度知识转移到小型深度学习模型中,这样即使是小型深度学习模型也能获得接近教师网络的评价指标。
最近的一些变体尝试利用多个教师的知识来指导学生,鉴于多教师蒸馏多用来处理图像且给每个教师分配平均或者固定的权重 [1] [2] [3] ,而在文本分类方面的研究较少,本文提出基于交叉熵的多教师蒸馏的中文文本分类模型,并分成同构和异构两种,分别提出了不同的蒸馏策略。本文设置教师模型分别为预训练后的BERT 模型和BERT-CNN模型,学生模型为TextCNN模型。实验结果表明,本文提出的方法比平均反映的多教师蒸馏的学生模型表现效果更好,同时比基于置信的多教师蒸馏(CA-MKD) [4] 等一些方法效果好,比单独训练教师模型减少了参数量,说明其具有很好的压缩意义。
2. 相关研究
随着深度学习的发展,在自然语言处理(NLP)中更新换代了许多模型,对NLP任务的精度得到了提高。经典模型卷积神经网络(CNN)在深度学习中一般是用来解决计算机视觉和图像处理之类的问题,而Yoon Kim针对CNN做了一些变形,提出了一种更简单的模型,即TextCNN模型 [5] 。其中TextCNN模型只有一层卷积层和最大池化层。在TextCNN之后又提出了可以解决时序问题循环神经网络(RNN) [6] ,但由于RNN模型在梯度下降时容易出现梯度消失或梯度爆炸问题。于是针对梯度消失和梯度爆炸问题提出了长短期记忆网络(LSTM) [7] ,LSTM模型是在RNN的基础上增加了门控单元,在一定程度上提高了模型的性能。在LSTM提出后,Devlin 等人通过堆叠Transformers的编码部分提出了BERT模型 [8] ,引入了基于注意力机制 [9] 的多头注意力(Multi-Headed Attention)机制,同时考虑了当前词的前后单词对当前词的影响,从而能够生成更加准确的文本表征,进而提升文本分类准确率。同时,由于BERT模型能够并行地处理文本,使得其拥有更高的训练效率。
随着NLP任务在深度学习的发展和性能指标的改善,使NLP任务的产业化成为可能。然而昂贵的计算成本,使模型在移动设备上的部署变得困难。为了压缩模型以减少模型在计算上的时间和空间消耗。近年来模型压缩的主流方法有剪枝(Pruning) [10] [11] [12] 、量化(Quantization) [13] [14] [15] 、权重共享(Weight Sharing) [16] 及知识蒸馏(Knowledge Distillation) [17] [18] [19] 。近年来知识蒸馏备受关注,其在分类和预测任务中是非常有效的。Xinyin Ma等人 [20] 提出了一种新的两级无数据蒸馏方法,用12层BERT模型作为教师网络用8层和4层BERT模型作为学生模型;廖胜兰等人 [21] 通过生成对抗网络得到的大量无标签数据,将教师模型的知识迁移到学生模型的一种知识蒸馏意图分类方法;Nityasya M.N.等人 [22] 用BERT模型或者混合BERT模型去指导Bi-LSTM模型和CNN模型在未标记数据集上实验。
不同于以上工作,本文认为多教师蒸馏也是具有研究意义的,提出了基于交叉熵的多教师知识蒸馏的中文文本分类模型,并分成同构和异构两种情况,对应的提出了不同的蒸馏策略,并取得了满意的实验结果。
3. 基础知识
3.1. 数据预处理
在进行模型训练之前,电脑需要把每个字都转换成向量。首先要对每句话进行分词操作,然后BERT模型和TextCNN模型有一份自己字典,其中样式为每个字前面都有一个索引,词嵌入层会把每个字用索引替代,然后从训练好的词向量中根据索引提取词向量,最终每个字都被转换为词向量。两种编码大致如下图1所示。
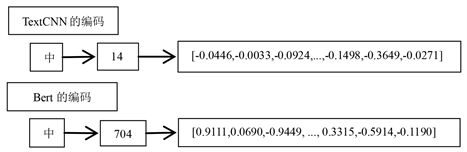
Figure 1. Partial word vector conversion of TextCNN and BERT
图1. TextCNN和BERT的部分词向量转换
其中TextCNN的词向量维度为300维,BERT的词向量维度为768维。本文设置文本长度为32,对于句子没达到长度时会默认填充[PAD]符号使得每句话有相同的长度。其中BERT编码的第一个代表[CLS]符号,预训练后的BERT模型通过微调生成词向量,而TextCNN模型本文选择用搜狗预训练词向量。
3.2. 教师模型
教师模型通常为复杂的、鲁棒性强的模型教师模型,简单来说就是一个大而深的高精度模型,本文选用预训练后的BERT模型和BERT-CNN模型作为教师模型。
BERT模型是把多个Transformer多个编码层堆叠起来,以便更好的特征提取。一般BERT模型有12层Transformer编码层,即12个块(block)。经过BERT编码过后可以作为词嵌入,后接入全连接层做分类器,如图2左边分叉所示。
BERT在文本分类的应用:BERT模型在每文本前会插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图2所示。也就是说[CLS]符号最后对应的输出包含了文本的全部信息,可以很好的做好分类任务。

Figure 2. Network architecture of BERT and BERT-CNN models
图2. BERT和BERT-CNN模型的网络架构
其中右边分叉为BERT-CNN模型,即BERT作词嵌入后接入TextCNN模型做分类器。
3.3. 学生模型
教师模型会有好的表现,但模型一般都比较大,在训练过程中会用大量的内存和计算资源,就会使得模型运行对计算机内存和配置要求较高。这就需要一个简单快捷的网络来接受教师的知识。
本文选择TextCNN模型为学生模型。TextCNN只有两层分别是卷积层和最大池化层。众所周知,卷积网络是在矩阵上进行滑动的,而NLP任务的输入是以矩阵表示的句子。与图像处理不同,卷积核的宽和每个词向量宽度一样,即每次读取都是一个字符,如下图3所示。
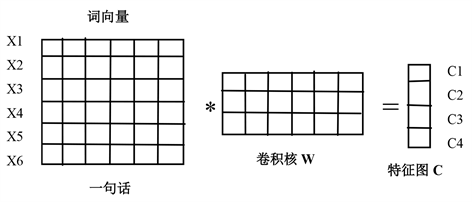
Figure 3. Calculation process of convolution
图3. 卷积的计算过程
其计算公式如下,其中♁是按行拼接,f为非线性激活函数:
(1)
(2)
(3)
其中x是每个文字所对应的TextCNN的编码。卷积核的“宽度”就是输入矩阵的宽度(词向量维度),“高度”可能会变,但一般是每次扫过2~5个单词,是整行进行的。一般来说,在大的词表中计算3元语言模型就会很吃力,所以本文按照2,3,4这样来取值。
4. 多教师知识蒸馏的文本分类
4.1. 多教师蒸馏模型
不同的教师体系结构可以为学生网络提供各自的有用知识。在培养学生网络的过程中,可以将多个教师网络单独或整体地用于蒸馏。在典型的师生框架中,教师通常有一个大模型或多个大模型的集合。要从多个教师那里转移知识,最简单的方法是使用所有教师的平均反应作为监督信号(Hinton et al., 2015) [17] 。通常情况下,多教师知识蒸馏可以提供丰富的知识,并根据不同教师知识的不同,定制出一个全能的学生模型。
然而,如何有效整合多名教师的不同类型的知识。在日常学习中知道:同样的知识每个老师教学的结果是不同的,而权重是一个很好的参数,可以充分发挥每个参数的用处,本文认为在每个教师传递知识前乘上各自的权重,学生也会得到更好更全面的指导。
首先如何构造每个教师的权值,即每个老师对学生的指导力度,最期望的情况是教师越接近真值其指导效果越好,本文认为用教师和真值标签的交叉熵损失来判断各个教师的指导力度,教师与真值的损失公式为:
(4)
(5)
其中
是第k个教师网络的Logits输出,y是标签,k表示第k个教师,N表示数据中类别个数。
(6)
其中得到
就是本文要的权重,可以看出在教师与真值的损失
越小教师的指导力度
就越大,反之教师表现(
)的越差指导力度(
)越小,则师生的蒸馏损失定义为:
(7)
其中
是学生网络的Logits输出,根据上面的公式可以看出教师表现的越好,其前面的权重就越大;反之权重就越低。相比于平均获取教师的知识,这样的构造学生就可以更好更全面的获取教师的知识。
教师的知识并不是什么都可以用来指导学生的,其中主要的知识有中间层特征知识传递和最后标签知识传递,而在师生网络不相似时本文认为中间层特征的提取转换不如加强最后标签知识传递方便。所以本文考虑了两种情况下的多教师蒸馏分别为:同构多教师蒸馏和异构多教师蒸馏。
其中同构蒸馏是指教师和学生的模型架构相似或属于同一系列;异构蒸馏是指教师和学生的模型网络结构不完全相同、难以实现层间特征图匹配的情况。对于用BERT深度模型去指导TextCNN简单模型的本文认为是异构多教师蒸馏,即不选择用中间层特征做知识传递,选择加强最后标签知识传递;而对于用BERT-CNN深度模型去指导TextCNN简单模型的本文认为用同构多教师蒸馏,即选择用中间层特征和最后标签知识做知识传递。
4.1.1. 同构多教师蒸馏

Figure 4. Isomorphic distillation network architecture
图4. 同构蒸馏网络架构
如上图4所示是模型同构多教师蒸馏的网络构建,在确定师生蒸馏损失
和学生损失
后,认为模型中间特征也是有指导意义的,考虑到TextCNN模型的简单性,本文采用教师和学生模型经过卷积池化后输出的特征作为中间层特征。在求得每个教师的权重之后,把其加入到教师对学生训练过程中进行中间层特征指导,本文选用光滑L1范数求得蒸馏误差:
(8)
其中
分别是第k个教师和学生网络的中间特征。光滑L1损失相比L1损失改进了零点不平滑问题。相比于L2损失,在x较大的时候不像L2对异常值敏感,是一个缓慢变化的损失。最后得出总的损失函数为:
(9)
(10)
其中
是学生的训练损失;其中
是超参数,可以平衡蒸馏损失和中间特征损失以使得模型有更好的表现。
4.1.2. 异构多教师蒸馏

Figure 5. Heterogeneous distillation network architecture
图5. 异构蒸馏网络架构
如上图5所示是模型异构多教师蒸馏时的网络构建,本文认为模型异构多教师蒸馏时,中间层特征的提取转换不如加强最后标签知识传递方便,所以本文考虑加强最后标签知识的指导意义。这里选择用L2损失函数来拉近学生和教师的Logits输出,同样也用之前得出的权重,最终得出以下公式:
(11)
其中
和
分别是第k个教师网络和学生网络的Logits输出,最后得出总的损失函数为:
(12)
(13)
其中
是超参数,可以平衡蒸馏损失和标签知识损失以使得模型有更好的表现。
4.2. 实验与结果分析
4.2.1. 实验数据
在本节中,对THUCNews数据集进行实验,验证本文提出的多教师知识蒸馏的有效性。基于流行的神经网络架构,本文采用了预训练后的BERT模型、BERT-CNN模型和TextCNN模型师生组合。
THUCNews数据集在14个类别中抽取10个类别,每个类别抽取10,000条新闻标题,共100,000条,文本长度在20到30之间。类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。分别定义为0到9。数据集划分如下表1所示。
4.2.2. 评估方法
评估方法选取文本分类常用的指标:准确率(Acc)和F1得分作为模型效果的最终评价,公式为:
(14)
(15)
准确率表示预测正确的样本数占样本总数的比例,其中n为评估模型所使用的样本总数;
为指
示函数,当输入的文本类别与预测的结果一致时,则指示函数的结果为1,否则为0;P为查准率,R为查全率。为了更好地体现模型压缩的有效性,在原有的评价体系上增加单位迭代次数所需要的时间(s)以及模型参数量两个评价维度。
4.2.3. 实验细节
本文的实验需要如下表2的配置。
对于BERT和BERT-CNN模型均采用BERTAdam优化器,学习率设置为0.00005,Warmup设置为0.05,中间隐藏层单元为768,dropout层为0.1,epoch设置为3;在TextCNN模型采用随机梯度下降法,动量设置为0.9,权值衰减为0.0001,学习率设置为0.001,卷积核分别用2,3,4,卷积核数量为256,dropout层为0.5。批大小均设置为128。为了公平起见,在所有方法中,温度T设置为5,而α设置为3,epoch设置为5。在整个实验过程中,同构和异构分别将β设置为10和1,随机数种子为12。
4.2.4. 实验结果
通过在THUCNews数据集上实验,本文设计了一个表现好的教师和一个表现差的教师,以体现基于交叉熵的多教师蒸馏对比于平均接受每个教师的知识的好处,本文分别在同构和异构蒸馏的情况下做实验,得到如下表3和表4的结果。

Table 3. Experimental results of isomorphic distillation
表3. 同构蒸馏实验结果
其中Avg Weight是代表平均每个教师的指导力度,CA-MKD是基于置信的多教师蒸馏,KD1表示教师一进行单教师蒸馏,KD2表示教师二进行单教师蒸馏,AEKD表示基于梯度空间的自适应多教师蒸馏,EBKD表示基于熵的多教师蒸馏。通过表3的实验结果可以看到,对于同构多教师蒸馏,Avg Weight 比学生模型TextCNN的精度提升了2.51%;而CA-MKD、AEKD和EBKD精度分别提升了1.95%、3.08%和2.57%;但本文的方法对比与学生模型TextCNN精度提升了3.26%,对比于AEKD和CA-MKD分别提升了0.18%和1.31%,说明本文采用交叉熵损失作为每个教师的指导力度和采用光滑L1范数来处理中间层知识传递的方法更优;并且可计算出本文方法蒸馏后相比于表现好的教师的性能损失(教师模型–蒸馏模型)/教师模型为0.79%;通过与单教师蒸馏对比本文的方法在精度和性能损失方面也有所提高。
Table 4. Experimental results of isomerization distillation
表4. 异构蒸馏实验结果
而对于异构多教师蒸馏,从表4的结果可以看出,Avg Weight比学生模型TextCNN的精度提升了2.30%;同时CA-MKD、AEKD和EBKD使精度分别提升了2.00%、2.04%和2.46%;但本文的方法对比与学生模型TextCNN精度提升了3.30%,比EBKD和CA-MKD分别提升了0.84%和1.30%,说明本文对于异构师生网络的蒸馏方法,即强化Logits输出做知识指导和提取中间特征的做知识指导效果更好,这样也避免了师生网络差别大时中间层的提取转换。同样也可计算出异构时本文方法蒸馏后相比于表现好的教师的性能损失为0.78%,相对于单教师蒸馏本文在精度和性能损失方面也有所提高。
本文也对每个模型的参数量和训练后保存的模型大小进行了统计,得到如下表5结果。
Table 5. Comparison of the number of model parameters and the size of the training saved mode
表5. 模型参数量和训练保存模型的大小比较
从上表5可以看出相比于教师网络的BERT-CNN模型和BERT模型,学生TextCNN模型的总参数量和保存模型偏小。教师模型总参数量是学生模型的48.85和48.01倍,是训练出来模型的69.15和68.55倍。而本文的模型在总参数量上和学生模型一样的,同样只是教师模型的2.05%和2.08%,但训练出的模型却只是教师模型的0.72%和0.73%,即缩小了138.22和137.01倍,而且对比学生TextCNN模型压缩了2倍,认为本文的模型起到了很好的模型压缩效果。
同样本文也记录了模型的一次epoch时间,得到如下表6所示,可见本文的方法只用了原来21.05%的时间,同时相比于其他方法也更快。
Table 6. Comparison of model training once epoch time
表6. 模型训练一次epoch时间的比较
4.2.5. 消融实验
其中w/o表示没有。从上表7实验结果可知在师生同构时,w/o Lhint在没有提取中间层特征时,精度和F1得分会降低,说明中间层包含了蒸馏的有用信息。在师生异构时,w/o Lout在没有加强Logits输出特征的情况下,精度和F1得分也降低了,说明Logits输出和软目标一样包含了蒸馏的有用信息。
5. 结论
基于文本分类的问题,本文采用了多教师–学生的知识蒸馏模型,采用了预训练后的BERT模型和BERT-CNN模型作为教师模型,经典模型TextCNN作为学生模型,用以做多教师蒸馏。本文针对每个教师的指导力度采用了交叉熵的方式计算出的权重作为指导力度,同时把模型分成同构和异构两种情况并分别提出了用光滑L1范数来衡量师生中间层特征的距离和加强Logits输出的知识指导的蒸馏策略。在THUCNews数据集上进行实验,结果表明,本文在同构和异构的情况下即使部分教师表现较差,也使得学生模型分类效果分别提升3.26%和3.30%,且相比于表现好的教师性能损失分别为0.79%和0.78%,说明接近教师的分类表现,同时参数量只是教师模型的2.05%和2.08%;训练出的模型是教师模型的0.72%和0.73%,而且对比学生TextCNN模型也缩小了2倍,认为起到了很好的模型压缩效果。对于THUCNews数据集本文采用的是搜狗预训练词向量模型,这始终有所局限,下一步研究可以用更好的方法去提取文本中的特征作为词嵌入,以使模型精度再次得到提高。
基金项目
国家自然科学基金(11961039)。
NOTES
*第一作者。
#通讯作者。