1. 引言
随着移动宽带技术的迅猛发展和频谱资源利用率不高等问题,无线频谱资源越来越稀缺,频谱工作环境也越来越复杂。认知无线电 [1] 就被用来缓解频谱短缺问题,就是判断在主用户没有充分利用其分配的频谱资源情况下,允许未分配权限的次级用户利用该频谱资源进行通信。频谱感知技术 [2] 作为认知无线电的关键技术,就被用来实现这一过程,其主要目的是区分该频谱资源是否正在被主用户使用,并在复杂的无线环境中准确、快速地检测出空闲频谱,如果主用户未使用该频段,则该频段将被重新分配,以供未经许可的次用户(SUs)使用,但是一旦主用户开始传输,就将SUs切换到其他空闲频段,充分利用主用户不使用频谱的空闲时间,提高频谱资源利用率。传统的频谱感知算法有能量检测法 [3] 、匹配滤波检测法 [4] 、循环平稳特征检测法 [5] 等。其中能量检测受噪声不确定性影响较大,在低信噪比条件下检测性能下降;匹配滤波检测需要更多地掌握主用户的先验知识,在现实中可操作性不高;循环平稳特征检测面临复杂度高,检测效率低的问题,因此也需要一些改进。
近年来,机器学习 [6] 在频谱感知领域被广泛使用,且表现出较好的性能,机器学习技术之前已经成功地应用于认知无线电的一些方面,例如:预测、分类和切换等。机器学习在频谱感知中被用作模式分类器,将信号中提取的特征向量放入分类器中,将这些特征分为信道可用和信道不可用两类。
聚类算法作为机器学习中的无监督算法,基于聚类算法的频谱感知方案可以避免复杂且不准确的阈值计算。Sun chenhao等人 [7] 提出的基于主成分分析(PCA)和K-medoids聚类的协作频谱感知算法,Yue wenjing等人 [8] 提出的基于图像K-Means聚类分析的频谱感知算法等,这些算法的检测效率高但是低信噪比低虚警概率下的检测性能还有待提高。根据熵集中原理,最大熵聚类算法就是取熵值最大的情况对样本点做聚类,提高感知精度。
然而如果直接对原始频谱信号进行聚类频谱感知,感知准确性会降低;此外,由于数据样本分布不均,最大熵模糊聚类算法在选择初始聚类中心时可能面临所选中心点处在同一个簇中的问题,导致聚类结果不理想。Manish Kumar Giri等人 [9] 提出的基于特征值和核模糊C均值聚类的频谱感知算法就面临聚类中心重合的问题。P.Y. Dibal等人 [10] 提出的基于小波包变换和主成分分析(principle component analysis, PCA)的频谱感知算法,通过PCA减少生成数据的维度提高检测效率,但是也降低了检测准确度。因此,采用适当的方法对信号进行特征提取显得尤为关键。Li weipeng等人 [11] 提出的基于小波变换和K-中心点聚类算法在故障诊断中的应用,就充分体现出特征提取在聚类算法和故障诊断领域作出重要贡献。小波变换 [12] 是20世纪80年代后期发展起来的一种具有多分辨率特性的变换分析方法,因此利用小波变换来分析局部的细节信号就更能把握原始数据的特征信息。
综上所述,为了解决传统频谱感知算法中受噪声影响大而导致的检测性能差和复杂度高问题,本文提出将小波变换与最大熵模糊聚类相结合的方法,将其应用于频谱感知中,首先仿真分析了主用户存在与否的两个信号,利用小波变换分别提取各信号的细节因子并根据相应的细节因子重构各细节信号,得到的信号组成特征向量作为最大熵模糊聚类的训练样本,通过对无标记训练样本的学习来快速感知PU信号是否存在,提高感知准确度。
2. 信号的假设检验模型
从分类角度来看,频谱感知实际上就是把接收到的信号分为主用户信号存在与否的两类。
(1)
其中,n表示采样点,
指的是非授权用户接收到的信号,
表示当信号服从瑞利衰落时的瑞利因子,
指的是授权用户发射信号,
表示信道中存在的噪声信号。当PU信号为H0时,即授权用户信号不存在时,认知信号中仅包含噪声信号;当PU信号为H1时,即授权用户信号存在时,认知信号是主用户信号和噪声信号之和。
多天线接收技术 [13] 主要包括最大比合并、选择性合并、开关式合并、等增益合并等,选择式合并通过控制增益来实现信噪比(SNR)均值相等,但是现实中难以测量SNR;开关式合并的抗衰落性较差效率低;最大比增益产生的权重并不方便。因此本文采用结构与最大比增益类似且实现方式较为简单的等增益合并,通过对4根天线的等增益合并来实现频谱感知。
3. 基于离散小波变换和最大熵模糊聚类的频谱感知
3.1. 正交小波变换
传统的信号处理方法并不适用于这种带有非平稳信号的频谱信号,如果将仿真的频谱信号直接用于聚类算法,会降低预测准确性和检测效率,因此,需要采用适当的方法进行特征提取,使其准确快速地预测数据类型。小波变换通过选择合适的小波函数,把原始频谱信号逐次分解到各个尺度上提取相应的局部细节信号,并分析此细节信号,使其在时域和频域都能体现信号的局部特征。
小波变换主要分为连续小波变换(CWT)、离散小波变换(DWT)、离散小波包变换(DWPT)等,但DWPT的计算复杂度 [14] 为
;CWT对于小波基的选取比较困难,不同的小波基可能引起分析结果不同。因此DWT对CWT离散化处理,使得复杂度 [14] 降低为
。
离散小波变换的表达式为 [15]
(2)
式中,
和
分别为尺度函数和小波函数;J表示小波分解的层数;N表示分解的系数和总和;
和
分别表示近似系数部分和细节系数部分,可表示为:
(3)
而本文对信号进行小波分解后就是为了得出
,并根据此系数进行信号重构。先将原始仿真信号作为输入信号,对正交小波函数进行缩放平移等运算,将信号分解成高频和低频两个部分,将得到的低频信号再作为输入信号,进行下一轮小波分解,得到新的高频部分和低频部分。以此类推,直到尽可能最大化保留输入信号的特征,即分辨率效果达到最优时,取所有高频部分系数进行重构后的信号作为聚类算法的输入,具体分析如图1所示。在信号的高频部分,小波变换为了获取精细的时间定位,用较低的频率分辨率来分析。
3.2. 最大熵模糊聚类算法
E.T. Jaynes于1957年首先提出最大熵原理 [16] ,其主要思想是:当仅掌握关于部分未知分布的信息时,应该选择熵值最大的概率分布。当所给信息越多,不确定性就越大,熵值也越大。熵最大时,不确定变量最随机,对其做预测就最困难,在所有满足约束条件的模型中选择熵值最大的模型,即在聚类过程中,使相似的一类尽量聚在最大熵的附近,利用最大熵原理可以得出不确定性最大的概率分布,使其聚类结果最优。
首先定义聚类模糊集熵,对于某个具体的聚类c,其聚类模糊集熵
为 [17]
(4)
其中,
是样本,
是
的隶属度,且约束条件为
,n是样本个数。然后确定总的聚类模糊集熵。将数据集X划分为c类,即有c个聚类中心,其总的聚类模糊集熵为 [18]
(5)
求解
的最小值就能使得模糊集熵最大。因此最大熵聚类的目标函数是 [18]
(6)
s.t.
(7)
且约束条件为
,且由熵的表达式可知,熵为凹函数,取反函数就是凸函数,因此反函数的最小值就是最大熵值。采用拉格朗日乘子法构造目标函数 [18]
(8)
对目标函数中
,
,
求偏导,使得导函数等于0,则可以求得
的表达式
(9)
将公式(9)代入
中,得
的迭代公式
(10)
其中,
表示样本点
到聚类中心点
的欧氏距离,将式(8)对
求导得到聚类中心点的迭代公式 [18]
(11)
最大熵聚类算法就是在满足所有约束条件的前提下,取熵值最大的情况进行聚类,它的聚类结果比较准确,得到的数据结果与已知数据高度契合,且精确估计了不完全数据和噪声数据,减小聚类结果的误差,提高聚类准确性。
3.3. 基于离散小波变换和最大熵模糊聚类的频谱感知
首先对仿真出的两种信号进行等增益合并,利用上述正交小波变换对多天线等增合并后的频谱信号进行分解,对各尺度上
的相应局部信号进行特征提取,提取细节信号并对信号进行重构,将细节因子重构后的信号作为特征向量,然后用最大熵模糊聚类进行频谱感知,进一步解决了噪声对信号影响大的问题。
聚类算法通过尽可能将相似原型分成一个类,来实现对未知信号自动分类。最大熵模糊聚类算法是在满足所有约束的条件下,将熵值最大情况下的数据进行聚类,可以防止复杂的判别门限阈值计算,减小误差。该算法的过程主要是基于划分方法来获得聚类结果,其目标函数包括最大化熵和最小化失真。根据熵集中原理,对信号进行聚类算法时大多数时候会集中在最大熵值的附近。因此,最大熵聚类算法的准确性较高,并且对于数据集来说,有一部分待聚类的样本数据并不具备理想化的特征,其中最影响聚类结果准确性的例如不完全数据(瑕疵数据)、噪声数据等,然而,最大熵聚类算法,准确而有效地解决了这类问题,最终得到的聚类结果与已知数据一致,且精确地估计了不完全数据和噪声数据,有效提高聚类准确性。与传统的FCM算法不同,通过计算熵值,将成员分配给特定样本,其中,熵较大的样本分配给一类,熵较小的样本分配给另一类。
具体步骤如下:
步骤一:对原始信号进行m层正交小波变换,分别提取第
到第
各个尺度上
的相应局部细节信号,其中
为原始信号;
步骤二:利用步骤1中m层分解并重构后的所有细节信号组成的特征向量作为输入向量;
步骤三:首先初始化中心点,设置迭代次数为0,输入必要的变量,即训练数据X,聚类数c,正则化参数
,隶属度
,阈值
等;
步骤四:使用公式(11)和(10)更新聚类中心点和隶属度,并判断如果不满足
,则重新更新隶属度和聚类中心,否则算法终止。训练最大熵模糊聚类分类器并获取输出的聚类中心
和目标域中的隶属度
;
步骤五:用训练好的最大熵模糊聚类分类器对频谱分类判断。
4. 实验仿真与性能分析
本节介绍了为强调所提出的频谱感知算法的性能而进行的仿真结果。仿真实验首先分别仿真主用户信号和噪声信号,其中噪声为均值为0,方差为1,瑞丽衰落系数为0.6的加性高斯白噪声。仿真信号H0和H1分别表示主用户存在与否,即信道可用和信道不可用;分别对两个信道信号进行小波变换,离散小波采用的是db9小波;最大熵模糊聚类分别将信道信号仿真5000次,分别得出5000个H0信号和5000个H1信号作为聚类的输入,其中,3000组作为训练集用来训练聚类分类器,剩余的2000组作为测试集用来测试聚类分类器的可靠性和有用性。
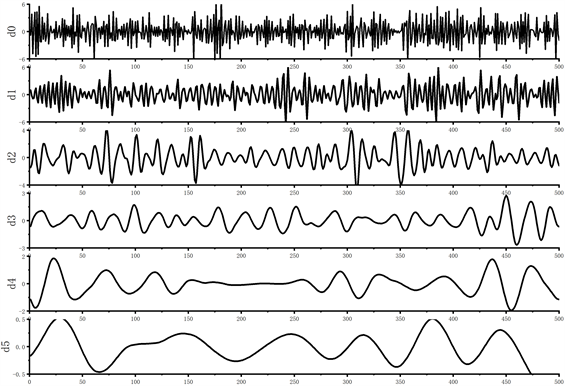
从结果图可看出:当分解层数越多,函数曲线更加平滑,局部信号的正则性越强,且不断将非平稳信号转化为趋于平稳信号,信息也逐渐丢失。因此在选取小波分解层数时,要将信号平稳性与有效性综合考虑,避免丢失更多有用信号。
 (a)
(a)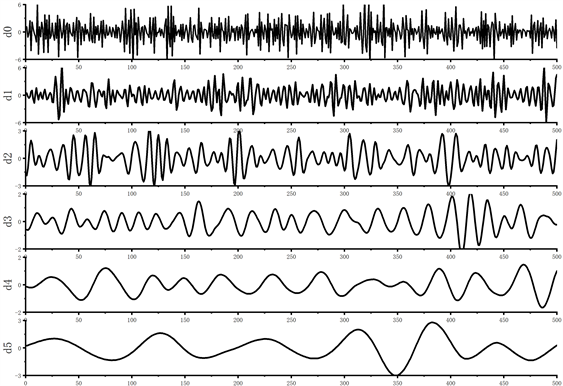 (b)
(b)
Figure 2. Wavelet exploded pattern of the signal. (a) Exploded view of the H0 signal; (b) Exploded view of the H1 signal
图2. 信号的小波分解图。(a) H0信号分解图;(b) H1信号分解图
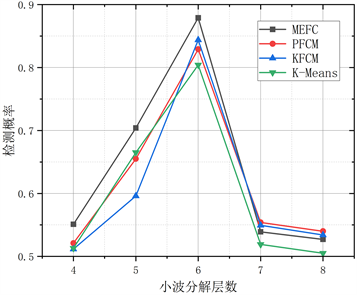
由图2和图3可知,在小波分解6层且重构后,将非平稳信号变换为趋于平稳的信号,将小波分解并重组后的特征作为聚类的输入进行频谱感知。
 (a)
(a) 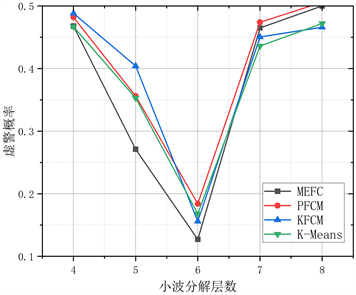 (b)
(b)
Figure 3. The effect of wavelet decomposition layers on detection performance. (a) The effect of the number of wavelet decomposition layers on the probability of detection; (b) The effect of wavelet decomposition layers on the probability of virtual alarm
图3. 小波分解层数对检测性能的影响。(a) 小波分解层数对检测概率的影响;(b) 小波分解层数对虚警概率的影响
4.1. 所提技术的感知性能
本文研究了基于离散小波变换和最大熵模糊聚类的频谱感知研究,相较于传统的频谱感知,表现出良好的检测性能,本文着重对比了传统频谱感知中的能量检测法和特征值检测法,本文还对比了4根天线的等增益合并准则对频段信号进行分析,对频段信号的协方差矩阵的所有特征值提取作为特征向量进行聚类的频谱感知方法,由图4可知:本文所提算法性能最好,能量检测法的性能最差,其中,在低信噪比情况下,传统的频谱感知算法受噪声影响较大,而所提算法的曲线的坡度则缓慢下降,在信噪比−20时,用小波变换提取特征组成特征向量用于MEFC的检测概率为87.9%,比特征值组成特征向量的检测概率66.7%提升了20.2%,充分说明在小波变换在对于非平稳信号进行预处理时的优越性能。
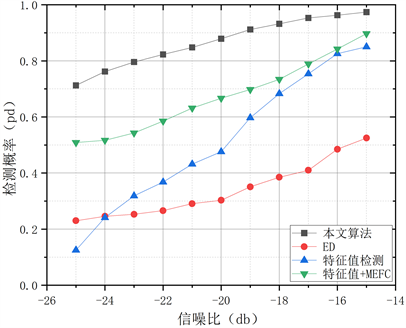
Figure 4. Comparison of detection probabilities of different perception algorithms
图4. 不同感知算法的检测概率对比
本文为了便于观察,利用主成分分析对小波特征进行降维处理并对其感知效果可视化,聚类后的散点图如图5所示。红色的点代表两个聚类中心,蓝色代表H0信号,绿色代表H1信号。
4.2. 不同参数对检测性能影响
本文还将最大熵模糊聚类(MEFC)与K-Means聚类算法、模糊C均值、可能性模糊C均值(PFCM) [19] 、核模糊C均值进行仿真测试对比。为了进一步衡量所提算法的可靠性,本文测试了更低信噪比下信号的检测性能,图6分别测试了采样点数为256时,信噪比为[−15, −25] dB区间内对频谱信号进行小波分解6层后各聚类算法的检测概率和虚警概率对比,由图可以看出:当信噪比相同条件下,MEFC算法在性能准确率上优于其他的传统聚类算法,特别是在信噪比较低为−25时,FCM、KFCM、PFCM、K-Means和MEFC的检测概率分别达到60.7%、63.3%、61.5%、61.1%和71.27%,相同条件下,本文所提算法的检测概率分别比传统聚类算法K-Means和FCM提升10.17%和10.57%;而虚警概率也分别达到42%、36.7%、38.4%、40.4%、26%,相同条件下虚警概率也分别比传统聚类算法提升14.4%和16%。
 (a)
(a) 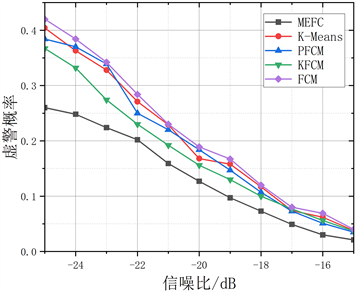 (b)
(b)
Figure 6. Comparison of detection performance of different clustering algorithms. (a) Comparison of detection probabilities of different clustering algorithms; (b) Comparison of false alarm probabilities of different clustering algorithms
图6. 不同聚类算法的检测性能比较。(a) 不同聚类算法的检测概率比较;(b) 不同聚类算法的虚警概率比较
图7反映了相同信噪比下,采样点数对检测性能的影响。由图看出,当采样点数为256且信噪比大于−22时,检测概率能达到90%以上且虚警概率也都低于20%,也就是说,在相同信噪比下,采样点数与检测概率成正比,与虚警概率成反比,采样点数越多,检测概率越高,虚警概率越低,频谱感知性能就越好。
 (a)
(a) 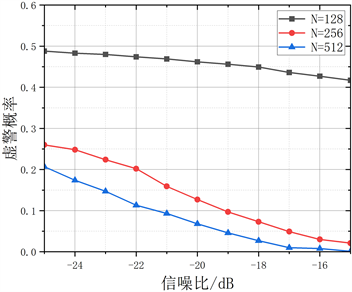 (b)
(b)
Figure 7. Comparison of detection performance with different sampling points. (a) Comparison of the detection probabilities with different sampling points; (b) Comparison of false alarm probabilities with different sampling points
图7. 不同采样点数对检测性能对比。(a) 不同采样点数对检测概率对比;(b) 不同采样点数的虚警概率对比
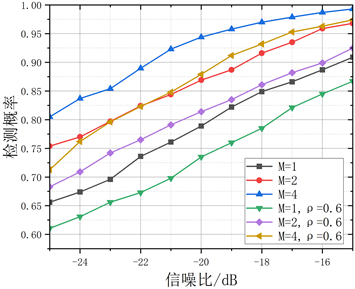
图8表示了不同的天线数量对检测性能的影响。对多天线进行等增益合并后,当天线数越多的时候,检测概率越高,检测性能越好,特别是在较低信噪比情况下,性能改进尤为明显。由图8可知,在相同采样点数且信噪比为−25时,天线数M = 1、2、4时所提算法的检测概率分别为65.6%、75.4%、80.5%;虚警概率分别为:35.1%、30.3%、21.8%。
 (a)
(a) 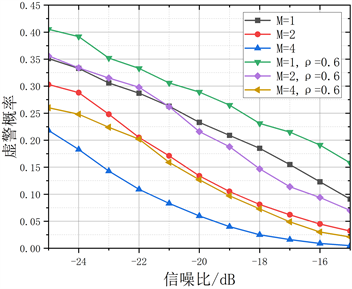 (b)
(b)
Figure 8. Comparison of detection performance with different antenna numbers. (a) Comparison of detection probabilities with different numbers of antennas; (b) Comparison of false alarm probabilities with different antenna numbers
图8. 不同天线数的检测性能对比。(a) 不同天线数的检测概率对比;(b) 不同天线数的虚警概率对比
5. 结论
传统的频谱感知算法如能量检测算法,检测性能面临着受噪声影响大,需要计算复杂的门限值等问题。在检测门限不确定、认知用户数量较少或低信噪比情况下,检测性能受到很大的影响。
为了解决以上问题,本文提出了一种基于离散小波变换和最大熵模糊聚类的频谱感知技术,则很大程度上避免了以上问题,首先,利用小波变换将信号矩阵进行分解,提取信号的小波细节系数并根据此系数重构信号,重构后的信号作为特征向量用于训练最大熵模糊聚类分类器,最后利用此聚类分类器检测未知信号,判断信道可用或信道不可用,从而实现频谱感知。模拟仿真实验也验证了该方案的可行性且具有较好的检测性能,在相同信噪比条件下,该算法的检测结果比传统频谱感知算法更准确,检测概率随天线数的增加而提高,且与采样点数成正比,多径衰落的情况下,此算法的检测性能受瑞利衰落影响最小,在低信噪比条件下更为明显,表现出较好的检测性能。在特征提取过程中,本文用到的离散小波变换方法,通过对信号进行小波分解重构,将非平稳信号变换为趋于平稳信号,降低噪声对检测性能的影响,在一定程度上对提高聚类准确性和降低算法复杂度作出贡献;最大熵模糊聚类由于受噪声影响更小,因此在低信噪比下提升更明显。