1. 引言
随着全球经济的快速发展和人口规模的增加,碳排放成为全球气候变化的主要原因之一。碳排放的增加不仅导致全球气温升高和极端天气的增多,还对生态环境和人类健康造成了重大威胁。作为全球最大的碳排放国之一,中国的碳排放量一直处于全球领先地位,根据国际能源署的数据,2019年中国二氧化碳排放量达到了10.17亿吨,占全球总排放量的28%。为了应对气候变化挑战,中国政府采取了一系列措施来减少碳排放量。2020年9月第七十五届联合国大会上国家主席首次明确提出碳达峰和碳中和的目标,承诺力争于2030年前达到峰值,2060年前实现碳中和的宏远目标。2021年10月国务院发布《2030年前碳达峰行动方案》,方案中提出将碳达峰贯穿于经济社会发展全过程和各方面,重点实施能源绿色低碳转型行动、城乡建设碳达峰行动、各地区梯次有序碳达峰行动等十大行动。尽管中国政府采取多项并行的举措以实现碳达峰目标,然而中国的碳排放量仍然面临许多挑战和压力,碳排放量增加的趋势仍然存在,中国在碳排放领域存在的一些不足,比如,高碳能源依赖——中国仍然依赖煤炭等高碳能源,这导致了较高的温室气体排放量;工业排放控制不足——工业部门是中国碳排放的主要来源之一,尤其是钢铁、水泥等重工业行业;建筑和交通行业碳排放问题——建筑和交通行业在中国的碳排放量也相当大,特别是在城市化进程中,与城市发展相关的建筑和交通需求也带来了碳排放的增加的压力;农业和森林保护——农业和森林保护领域也存在一些挑战,例如农用地的大规模开垦导致的碳排放和森林砍伐等;监测和数据不足——在中国,碳排放的准确监测和数据收集仍然存在一定的不足。要解决这些不足,中国需要进一步加强政策制定和执行,加大技术创新和投入,加强国际合作,推动低碳发展和绿色转型。鉴于此,为了更好地制定和实施碳减排政策,需要建立完善的碳排放数据监测体系,提高数据的准确性和及时性。本文基于2019年1月~2023年3月全国碳排放日频数据分析对比了不同模型的预测效果,对于未来中国碳排放量的预测具有重要的现实意义和科学价值,促进中国的低碳可持续发展。
2. 文献综述
在全球碳排放数据不断增加的环境下,国内外学术界针对碳排放问题进行了研究,主要集中在碳排放影响因素以及各行业碳排放量预测两个方面。
在研究碳排放影响因素方面,主要研究集中于指数分解法、改进的STIRPAT模型、回归模型等影响因素分析方法。Kaya恒等式和LMDI分解法作为指数分解法的代表被广大学者用于碳排放影响因素分析,冯相昭和邹骥(2008) [1] 对Kaya恒等式进行改进后对中国的CO2排放量进行了无残差分解,得出经济驱动和人口增长是碳排放增加的主要驱动因素。袁路和潘家华(2013) [2] 对Kaya恒等式对碳排放影响因素对发展现状及其存在对局限性进行了详细阐述。Pan Jiang & Xiu juan等(2023) [3] 基于LDMI模型对中国八个经济区域碳排放对时空差异及影响因素进行了研究。张矢宇、杨杰等(2023) [4] 通过LDMI分解法得出影响我国交通碳排放的主要因素为交通运输结构、单位运输能耗水平、城镇居民人均GDP等。STRIPAT作为从IPAT模型中改进得到的模型在近年来多用于碳排放分析,胡广阔、李春梅和惠树鹏(2016) [5] 通过贝叶斯法对于STRIPAT模型的解释变量重要性进行筛选,验证了我国碳排放强度宇选取解释变量的关联影响。刘茂辉、翟华欣等(2023) [6] 通过对比LMDI模型和STRIPAT模型分析了天津市的碳排放量,并从基准、低碳和超低碳三种情景预测了碳达峰和碳中和的情况。除此之外,杨青、彭若慧等(2023) [7] 基于地理加权回归分析了我国不同省份碳排放量情况,揭示了碳排放量宇区域社会经济发展的关系。
在各行业碳排放量的预测上,肇晓楠、谢新连等(2023) [8] 在利用灰色关联度获取主要影响因素的基础上通过滑动窗口动态输入LSTM网络对铁路运输碳排放量进行了预测。池小波、续泽晋等(2023) [9] 提出一种分量增广输入的WPD-ISSA-CA-CNN碳排放预测模型,利用该模型以山西某发电厂的历史数据为样本对电厂碳排放进行了预测,得出该模型在火力发电碳排放中预测效果交好的结论。Aryai Vahid & Goldsworthy Mark (2023) [10] 基于粒子群优化–极端随机树(PSO-ERT)回归器模型对澳大利亚国家电力市场的碳排放强度进行了预测。Zhao Jinjie & Kou Lei等人(2022) [11] 采用二次分配程序回归分析,从区域差异的角度分析了影响黄河流域碳排放的因素,并通过麻雀搜索算法优化的长短时记忆网络(SSA-LSTM)对黄河流域的碳排放量进行了预测。J B Yuan & Y S Liu (2019) [12] 将民用建筑分为城市住宅建筑、农村住宅建筑、公共建筑和北部城市供暖,根据改进的灰色预测方法构建碳排放模型,预测了2017年至2025年全国民用建筑总碳排放量。
基于以上对于现有碳排放相关文献的分析,国内外对于碳排放的研究已趋于成熟,并且主要集中于碳排放影响因素分析和不同行业的碳排放量预测等方面。本文主要集中于对碳排放量时间序列的分析,基于滑动窗口的思想利用SARIMA、LSTM、SVR等模型对2019~2023年全国二氧化碳日排放量进行研究,最后通过评估指标分析不同模型对碳排放量预测的效果。
3. 碳排放预测模型理论
3.1. 季节性差分自回归移动平均模型SARIMA
SARIMA模型(Seasonal Auto-regressive Integrated Moving Average)是将季节差分与差分自回归移动平均模型(ARIMA)模型相结合的用于处理具有周期性特征的时间序列数据的模型(1997) [13] 。应用于包含趋势和季节性的单变量数据,SARIMA由趋势和季节要素组成的序列构成。
自回归(AR)是描述当前值与历史值之间的关系,利用变量自身的历史时间数据对其进行预测,p阶自回归过程公式可表示为:
其中,
是当前值,
是常数项,
是阶数,
是自相关系数,
是误差项。
数据差分(I)是指将非平稳数据转换为平稳的过程,去除其非恒定的趋势。当时间序列
不平稳时需要按照d阶差分公式进行差分:
其中,u为差分算子,d为差分阶数。
移动平均模型(MA)主要考虑的是自回归模型中的误差项的累加,以有效消除预测中的随机波动。q阶自回归过程公式可表示为:
其中,
是t时刻的误差项。
ARIMA(p, d, q)模型通常是自回归(AR)、差分(I)和移动平均模型(MA)三部分的整合,是统计模型中可用于非平稳时间序列预测的线性模型(2019) [14] 。当原时间序列进行d阶差分转化为平稳序列后,可以通过自相关系数(ACF)和偏自相关函数(PACF)或者计算赤池信息准则(AIC)和贝叶斯信息(BIC)的值确定具体的p和q阶数的取值,如表1所示。

Table 1. ARIMA (p, d, q) order determination table
表1. ARIMA(p ,d, q)阶数确定表
其中,k为模型参数个数,n为样本数量,L为似然函数;在保证模型精度的情况下尽量使得k值越小越好。
尽管ARIMA模型能够很好的处理非平稳时间序列并对其进行拟合,但当原时间序列Yt带有趋势性和季节性时,仅仅利用ARIMA模型进行拟合会出现较大误差。SARIMA模型利用季节差分对ARIMA模型进行优化能很好地拟合带有季节性的时间序列数据。SARIMA模型参数可以分为非季节参数(p, d, q)和季节参数(P, D, Q, s)两大类(2016) [15] :
其中,p表示非季节自回归阶数,d表示一步差分次数,q表示非季节移动平均的阶数。季节参数中P表示季节自回归阶数,D表示季节差分次数,Q表示季节移动平均阶数,s表示季节长度,或者称为周期大小。
SARIMA (Seasonal Autoregressive Integrated Moving Average)模型是一种用于时间序列分析和预测的统计模型。SARIMA模型的主要用途包括以下几个方面:时间序列分析、时间序列预测、趋势和季节性调整、销售预测和需求预测、经济预测等,需要注意的是,它是ARIMA模型的扩展,SARIMA模型的应用需要根据具体问题和数据的特点进行调整和定制,模型的选择和参数设置也需要根据实际情况进行优化。
3.2. 长短时期记忆模型LSTM
传统的循环神经网络(RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络。利用RNN模型进行时间序列预测时无法捕获序列的长时间依赖关系,为解决这一问题,Hochreiter & Schmidhuber [16] 于1997年提出了一种RNN的特殊形式—长短期记忆网络(LSTM),如图1所示这一模型主要由遗忘门
、输入门
、细胞状态
和输出门
组成。
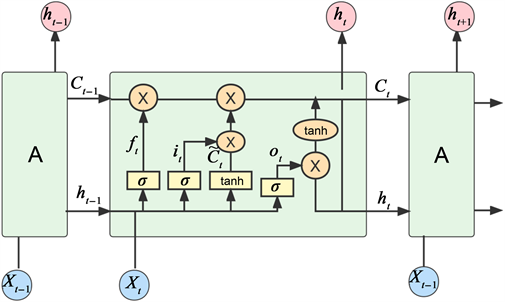
Figure 1. Schematic diagram of LSTM neural network
图1. LSTM神经网络结构示意图
LSTM神经网络通常由三步骤实现:
第一步:决定从单元状态中舍弃什么信息,由激活函数为sigmoid的遗忘门
决定:
为激活函数sigmoid,
是当前输入向量,
是当前隐含层向量,
、
分别是偏置和输入权重。
第二步:决定将要在单元状态(cell)中存储哪些新的信息,其中激活函数为sigmoid的输入门
决定将更新哪些值,激活函数为tanh的层
将创建一个新的候选值向量,添加到单元状态:
第三步:输出门
将决定LSTM模型输出的内容:
经过以上步骤构建的LSTM模型能够很好的序列数据,能够有效地处理长期依赖关系,进而提高模型预测精度。
LSTM是一种循环神经网络的变型,它在处理序列数据时能够更好地捕捉长期依赖关系。LSTM模型的应用非常广泛,主要用途包括以下几个方面:自然语言处理、语音识别、图像描述生成、时间序列预测、推荐系统等方面,并且它能够有效处理时序数据的长期依赖关系,提升模型的准确性和性能。
3.3. 支持向量回归SVR
支持向量回归(SVR)是一种基于支持向量机(support vector machine, SVM)的回归分析方法,用于预测连续变量或实数值(2003) [17] 。其主要思想是寻找训练数据中的支持向量,来构建一个能够最好地拟合训练数据的超平面。与传统的回归方法不同,支持向量回归使用核函数将数据映射到高维空间中,从而使得非线性关系也能够被拟合。对于回归函数:
其中w为权值向量,b为偏置项,SVR问题在引入损失函数的情况下可形式化为:
为保证所有训练数据都在间隔带内,需要引入松弛变量
和
,从而允许一些样本可以不在间隔带内。引入松弛变量的SVR模型可表示为:
定义一个低维到高维的映射
,并且引入核函数
将非线性回归问题转变为近似线性回归,则SVR映入核函数后可重写为(2007) [18] :
基于支持向量机回归对测试集数据进行预测,模型的精度取决于正则化系数C、核函数
的选取以及容忍偏差
大小。
SVR (支持向量回归)是一种回归模型,它通过将样本点映射到高维特征空间中,寻找最优超平面来进行回归分析。SVR模型也可用于以下几个方面:金融领域、医疗领域、工程领域、环境科学、数据挖掘等方面。
4. 实证分析
4.1. 数据源及其处理
研究中所涉及到的中国二氧化碳排放量数据主要来源于全球实时碳排放数据库(Carbon Monitor),选取了共计1551条2019年1月1日至2023年3月31日的每日碳排放量并绘制如图2所示折线图。
通过观察趋势变化图可以认为碳排放量呈现出周期性的特点,为了保证计算的有效性和模型可靠性,本文首先利用归一化公式对数据进行放缩处理,以消除量纲对于数据的影响。
其中,
为归一化后的值;
为原始值;
和
分别代表序列原始数据的最大值和最小值。其次采用如图2所示的滑动窗口法对归一化数据集进行分割,综合考虑数据集大小及碳排放受季节性影响,本次滑动窗口大小s设置为90。最后选择75%的数据作为训练集,25%的数据作为测试集分别利用SARIMA、SVR和LSTM模型对数据进行建模。整体研究思路如图3所示。
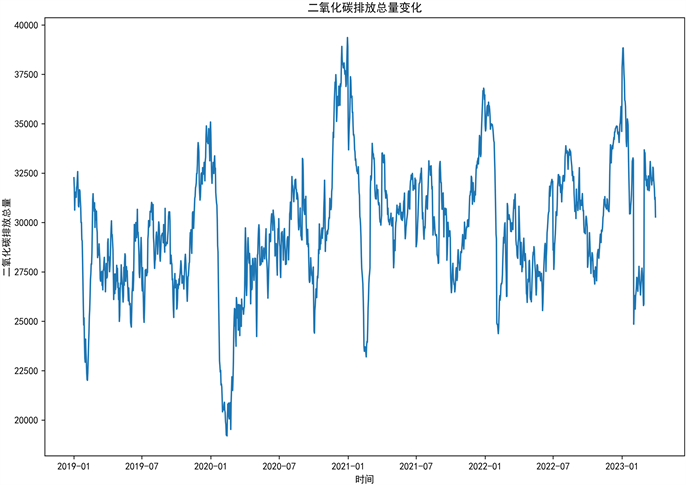
Figure 2. The trend change of national carbon emission data from January 2019 to March 2019
图2. 2019.01~2023.03全国碳排放数据趋势变化图
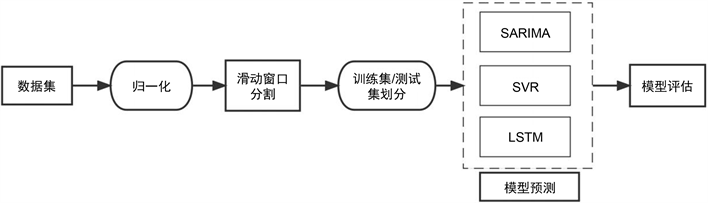
Figure 3. Overall design framework of carbon emission research
图3. 碳排放研究总体设计框架
4.2. 模型参数选择
SARIMA作为考虑周期性的ARIMA改进模型,在利用其进行时间序列预测时,首先需要对原始数据进行平稳性及白噪声检验。研究过程中首先对原时间序列绘制移动平均值和标准差,并进行ADF检验,根据对表2和图4结果进行分析可知时间序列具有平稳性。然后对数据进行白噪声检验,结果显示Q统计量的p值小于0.01,所以在0.01的显著性水平下拒绝原假设,可以认为序列是非白噪声序列。
Table 2. Results of unit root test of sequence Xt
表2. 序列Xt的单位根检验结果
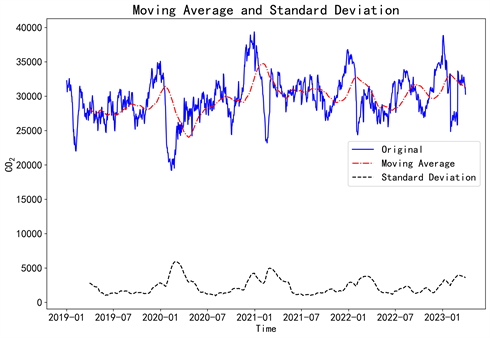
Figure 4. Moving average and standard deviation of sequence Xt
图4. 序列Xt的移动平均值和标准差
对通过平稳性检验和白噪声检验的时间序列数据绘制自相关函数(ACF)图和偏自相关系数(PACF)图,结果如图5所示,通过对其进行分析,可以初步确定p = 2,q = 2。为精确获得SARIMA模型中参数p,q,P,Q,研究过程中利用网格调参(Grid Search CV)的方法以赤池信息准则(AIC)为判断标准选择AIC最小的参数作为模型的具体参数值。利用python计算可得模型最优参数为SARIMA(2, 0, 2) × (0, 0, 1, 90)。
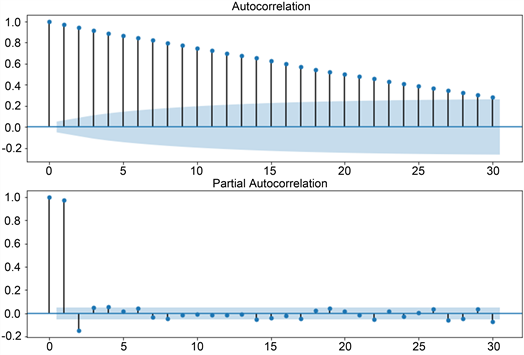
Figure 5. ACF and PACF plots of time series
图5. 时间序列ACF和PACF图
该研究基于tensorflow.keras框架,搭建LSTM长短时神经网络模型。模型采用单向编码方式,所使用的LSTM网络模型超参数具体设置如下:1层输入层、2层LSTM隐藏层以及两层全连接层,其中每层隐藏层中隐藏神经元数量分别为64和32。模型采用Adam优化算法寻找整体损失函数均方误差(MSE)的最优解,batch_size大小设置为3。如图6所示,迭代次数的不同,模型损失函数不同变化,当迭代次数为30时,训练集与测试集的损失函数均基本完全收敛,故迭代次数设置为30。模型最终参数如图7所示。
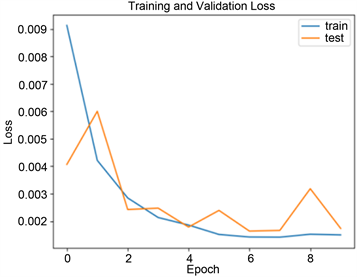
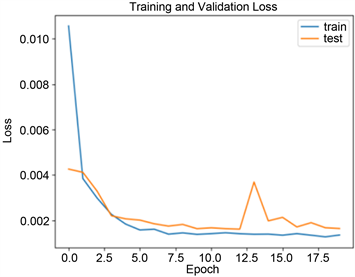
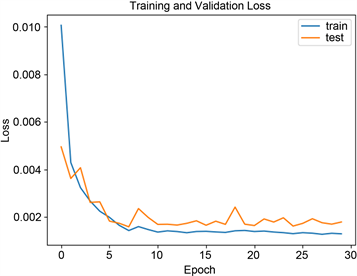
Figure 6. Trend chart of the number of iterations and loss function
图6. 迭代次数与损失函数的变化趋势图

Figure 7. Final parameters of LSTM neural network model
图7. LSTM神经网络模型最终参数
利用SVR对碳排放时间序列进行预测时,核函数选择高斯核函数(RBF)对模型进行优化,模型参数分别设置为C = 10,ϵ = 0.05,γ = 0.5。
4.3. 预测结果及其对比
4.3.1. 预测结果
按照训练集与测试集的划分比例,并且基于以上确定的模型参数,SARIMA、LSTM、SVR三个模型将在2019年1月至2022年3月的碳排放数据训练集上进行拟合,接着在2022年4月至2023年3月的碳排放测试集上进行预测。各模型的预测效果如图8所示,表3列举了最后10天的碳排放实际数据与不同模型的预测值对比情况。从图8可知SVR模型的预测效果相对较差,LSTM和SARIMA模型对于测试集的预测效果相对较好,从表3预测值的量化分析可知,SARIMA模型的平均相对误差为101.292,相对其他两个模型来说误差更小。因此,通过整体比较可知SARIMA模型具有更好的拟合预测效果。
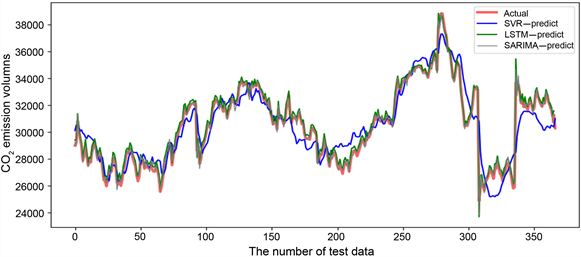
Figure 8. Comparison of carbon emission prediction results of different model test sets
图8. 不同模型测试集碳排放量预测结果对比
Table 3. Comparison of experimental relative errors of predicted values of the test set in the last 10 days
表3. 后10日测试集预测值对比实验相对误差
4.3.2. 模型对比
为了更为具体地比较模型之间的预测效果,研究过程中选用平均绝对误差(MAE)、均方根误差(RMSE)以及判定系数(R2)作为模型的评价指标,衡量预测值与真实值之间存在的差异。各指标的具体计算公式为:
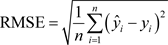
其中,
为真实值;
为预测值;
为样本均值;n为样本个数。
基于以上评价指标对不同模型的预测精度进行分析,得到结果如表4所示。SVR模型预测效果相对较差,MAE、RMSE指标都远大于其余模型的预测精度,R2仅为0.829相对较小。SARIMA模型与LSTM模型在预测精度上相差较小,但总体来说,SARIMA模型的R2达到0.912,模型具有更好的预测效果,预测误差更小。
Table 4. Comparison of prediction accuracy of different models
表4. 不同模型的预测精度对比
5. 结语
本文使用Python软件对2019年1月至2023年3月的全国碳排放实时数据,在考虑原时间序列具有趋势性的基础上,分别建立了SARIMA模型、LSTM模型以及SVR模型,利用MAE、RMSE以及R2三个指标分别对比分析了不同模型的预测精度。结果显示SARIMA模型对于具有趋势性的碳排放实时数据具有更好的预测效果,而SVR模型对碳排放的拟合度和准确性相对较差。