1. 引言
2021年12月6日,国际糖尿病联盟(IDF)发布了最新的全球糖尿病数据,据统计2021年全球约5.37亿成年人(20~79岁)患有糖尿病(10个人中就有1人为糖尿病患者);预计到2030年,该数字将上升到6.43亿;到2045年将上升到7.83亿。在此期间,世界人口估计增长20%,而糖尿病患者人数估计增加46%。低收入和中等收入国家的患病率上升速度高于高收入国家。糖尿病是失明、肾衰竭、心脏病发作、中风和下肢截肢的主要病因。2000年至2019年期间,糖尿病导致的死亡增加了3%。2019年,糖尿病以及糖尿病引起的肾脏疾病估计造成200万人死亡。可以看出糖尿病的经济成本似乎在全球范围内都有所增加。糖尿病是由于胰腺细胞产生的胰岛素不足或身体细胞对产生的胰岛素没有适当反应,导致碳水化合物、脂肪、蛋白质代谢紊乱,造成多种器官的慢性损伤、功能障碍甚至衰竭 [1] 。
糖尿病主要有四种类型 [2] ,它们分别是:
1) I型糖尿病:发病与T细胞介导的自身免疫导致胰岛β细胞的选择性破坏,胰岛素分泌减少和绝对缺乏有关,单用口服药无效,需要注射胰岛素来治疗 [3] 。
2) II型糖尿病:发病由遗传易感性和现代生活方式(膳食、运动)造成的胰岛素分泌缺陷造成 [3] 。
3) 其他特殊类型:肝脏疾病、慢性肾功能不全、多种内分泌疾病、急性感染、创伤,外科手术都可能导致血糖一过性升高 [3] 。
4) 妊娠糖尿病:妊娠期间引发的糖尿病,产后需控制恢复,仍是危险人群。一般情况下在婴儿出生之后就会消退 [3] 。
机器学习的分类算法广泛应用与医学领域的数据分类。糖尿病受身高、体重、遗传和胰岛素功能等功能的影响,我们考虑的主要因素就是血糖浓度。早期识别是唯一远离并发症的补救方法 [4] 。许多研究者进行疾病诊断实验时,会使用各种分类的机器学习算法,例如:支持向量机(SVM) [5] 、朴素贝叶斯 [6] 、决策树 [7] 、逻辑斯蒂回归 [8] 、神经网络 [9] 等等。数据挖掘 [10] 和机器学习方法对于来自不同数据源的数据的疾病诊断处理具有强大的能力 [11] 。在研究糖尿病,Nai-Arun等人 [12] 提出了一种分类集成学习来研究糖尿病,利用增益比特征选择技术对数据进行分析。Orabi等人 [13] 介绍了一种通过提高预防措施警报来帮助人们的方法。它是糖尿病疾病的预测系统,它将预测是否成为候选人以及在什么年龄。该系统基于机器学习概念,使用决策树技术,通过添加带有随机化代码的回归技术来预测年龄。Bamnote等人 [14] 提出了一种使用遗传编程(GP)检测糖尿病的分类器,使用分类表达式创建分类器。使用仅算术运算符的简化函数池,允许在交叉和突变期间进行较少的验证和宽大处理。Nai-Arun等人 [15] 首先研究了四个众所周知的分类模型,即决策树、人工神经网络、逻辑回归和朴素贝叶斯。然后,研究了袋装和增压技术以提高此类模型的鲁棒性。诸如对糖尿病的研究还有很多很多,如,Vijiya Kumar等人 [16] 提出的使用随机森林对糖尿病进行预测;Sisodia等人 [17] 研究的是使用分类算法预测糖尿病等等。
本次的研究工作是关注早期糖尿病这一疾病。在这项工作中采取了朴素贝叶斯、决策树、随机森林和逻辑斯蒂回归,这四种机器学习方法来对早期糖尿病进行预测。在四种机器学习方法下,都取得了良好的精度。
其余的研究讨论组织结构如下:第二部分,介绍机器学习分类算法。第三部分,进行数据集的实证分析及评估结果。第四部分,进行研究总结。
2. 相关理论及方法
2.1. 朴素贝叶斯
朴素贝叶斯分类(Naive Bayes)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入x求出使得后验概率最大的输出y [4] 。它适用于数据不平衡及数据缺失,而且还适用于维度非常高的数据集。朴素贝叶斯分类广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。
根据朴素贝叶斯算法可得:
,其中,
是目标类后验概率,
是预测类概率,
是Y概率是正确的,
是预测的先验概率 [6] 。
2.2. 决策树
决策树(Decision Tree)是一个监督机器学习算法,主要用于研究分类问题。一个决策树学习算法需要包含特征选择、决策树生成和决策树剪枝过程。本文使用的是ID3算法,它的核心是在决策树各个节点上应用信息增益准则选择特征,递归的构建决策树。信息增益
也就是:
,其中,
是数据集M的经验熵,
是数据集M的经验条件熵 [7] 。
决策树一般适合处理离散型数据,计算复杂度不高,对中间值的缺失不敏感,可以处理不相关特征数据。但是决策树方法可能产生过度匹配问题,对连续性的字段比较难以预测。它通常适用于金融分析、医疗诊断、营销推荐、交通安全等 [7] 。
2.3. 随机森林
随机森林(Random Forest)是建立多个决策树并将他们融合起来得到一个更加准确和稳定的模型,是bagging思想和随机选择特征的结合。随机森林构造了多个决策树,当需要对某个样本进行预测时,统计森林中的每棵树对该样本的预测结果,然后通过投票法从这些预测结果中选出最后的结果 [16] 。
随机森林适用于高维数据,不容易产生过拟合。对于大部分数据遗失,仍然可以维持高准确度。对于数据集的适应能力强,既能处理离散型数据,也能处理连续性数据,数据集也无需规范化 [16] 。
2.4. 逻辑斯蒂回归
二项逻辑斯蒂回归模型(binomial logistic regression)是一种分类模型,它属于对数线性模型,原理是根据现有的数据对分类边界线建立回归公式,以此进行分类。它常用于数据挖掘、疾病自动诊断、经济预测等领域。它仅能适用于线性问题,容易欠拟合,导致分类精度不高 [8] 。
3. 实证分析
3.1. 数据集说明
本次使用的数据是早期糖尿病风险预测数据集,从孟加拉国锡尔赫特的锡尔赫特糖尿病医院的患者那里收集的直接问卷。问卷中包含了年龄、性别、多尿等等,如表1,收集了520名患者数据。在实验中,随机选取80%的数据用于训练过程,20%的数据用于测试过程。
3.2. 结果与分析
3.2.1. 朴素贝叶斯
利用朴素贝叶斯进行建模,绘制出ROC曲线,如图1所示,可以看出AUC的值达到0.913,说明该分类器的性能比较好。然后使用混合矩阵,查看模型评估结果,如表2所示,计算出模型准确率为90.38%。由于该组数据没有空值,则不需要拉普拉斯平滑处理。

Table 2. Confusion matrix of naive Bayesian
表2. 朴素贝叶斯混合矩阵
3.2.2. 决策树
利用决策树进行建模,对树进行可视化,如图2所示,通过检查底部节点,可以看到有多少分类是正确的。决策树对于检查特征的重要性、每个特征的预测能力也很有用,特征重要性按降序排序,如表3所示,可以看出对于早期糖尿病来说重要的因素是烦渴(Polydipsia),多尿(Polyuria),最不重要的因素是年龄(Age),视觉模糊(visual blurring)。绘制出ROC曲线,如图3所示,可以看出AUC的值达到了0.915,说明该分类器的性能比较好。然后使用混合矩阵,查看模型评估结果,如表4所示,计算出模型准确率为91.35%。
Table 3. Importance of decision tree feature variables
表3. 决策树特征变量重要性
Table 4. Confusion matrix of decision tree
表4. 决策树混合矩阵
3.2.3. 随机森林
利用随机森林模型进行建模,该模型对于mtry和ntree两个参数的选取十分重要,由此在训练集中分出80%的数据作为新的训练集,20%的数据作为验证集。在验证集上选取最佳的mtry为3。如图4所示,当ntree取100时,模型内的误差就基本稳定了,出于更保险的考虑,我们确定ntree值为100。
随机森林与决策树一样也可以检查对变量的重要性,如图5所示。在随机森林中变量的重要性计算时通过将相应变量替换成一列随机的数后,计算模型准确率或者GINI系数的降低。Mean Decrease Accuracy:表示变量替换后准确率的下降;Mean Decrease Gini:表示变量替换后GINI系数的降低。数值越大表示变量越重要。绘制出ROC曲线,如图6所示,可以看出AUC的值达到了0.979,该值已经快要接近1,说明该分类器的性能好。然后使用混合矩阵,查看模型评估结果,如表5所示,计算出模型准确率为98.07%。
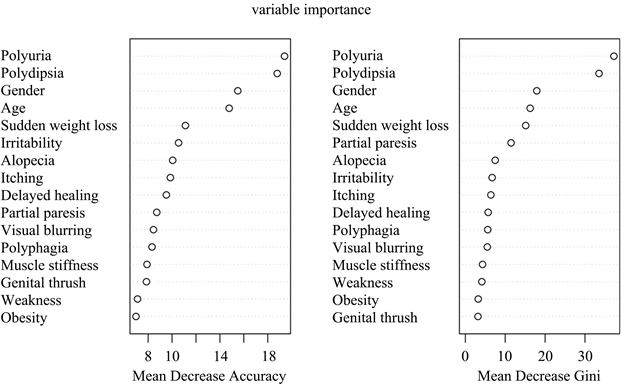
Figure 5. Importance of random forest variables
图5. 随机森林变量重要性
Table 5. Confusion matrix of random forest
表5. 随机森林混合矩阵
3.2.4. 逻辑斯蒂回归
利用逻辑斯蒂回归,创建模型,可以看到大部分变量都通过显著性检验,只有极少数的变量不显著,如表6所示。计算出在训练集上的𝑅2为0.7559,绘制出ROC曲线图,如图7所示,可以看出AUC的值达到了0.944,说明该分类器的性能比较好。然后使用混合矩阵,查看模型评估结果,如表7所示,计算出模型准确率为94.23%。
Table 7. Confusion matrix of logistic regression
表7. 逻辑斯蒂混合矩阵
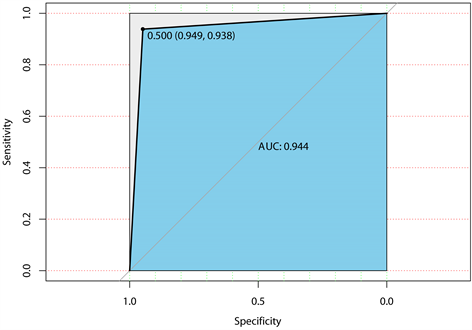
Figure 7. Logistic regression ROC curve
图7. 逻辑斯蒂ROC曲线
3.2.5. 模型评价
本次分析采用了四种不同的模型,分别是:朴素贝叶斯,决策树,随机森林和逻辑斯蒂回归,获得了四种不同的计算结果。观察得到四种不同的结果准确率都高达90%以上,如表8所示,由此可以得出这些模型对该数据集非常适用。本次模型训练集建议选取80%,剩下20%做测试集。此外通过决策树、随机森林及逻辑斯蒂回归分析糖尿病风险因素,发现多尿(polyuria)和烦渴(polydipsia)是导致糖尿病的主要因素。从结果分析中可以看出,随机森林算法获得了98.07%的高精度,这比剩下的三种模型都要好得多。由此可以看出,利用随机森林模型可以很好的预测早期糖尿病这一类疾病。
Table 8. Models prediction accuracy
表8. 模型预测精度
4. 总结
本文采用早期糖尿病风险预测数据集,通过使用朴素贝叶斯、决策树、随机森林及逻辑斯蒂回归模型,探讨了早期糖尿病风险因素的预测。风险因素预测在识别摆脱早期糖尿病疾病的风险方面起着重要的作用。从决策树、随机森林及逻辑斯蒂回归分析糖尿病风险因素,发现多尿(polyuria)和烦渴(polydipsia)是导致糖尿病的主要因素。
其次从模型预测结果上来分析,四种模型的精度都达到90%以上,说明这四种模型都能很好的预测早期糖尿病疾病。在所使用模型中随机森林模型的精度较高(98.07%),所以预测早期糖尿病疾病来说采用随机森林效果更佳。
致谢
在本论文的写作中,我也参照了大量的著作和文章,许多学者的科研成果及写作思路给我很大启发,在此向这些学者们表示由衷的感谢。感谢我的老师、家人、同学、朋友对我的大力支持,他们的无私奉献、关爱和支持使我能够继续去追求自己的人生理想和目标。感谢所有关心、帮助和支持我的人。