1. 引言
随着基本医疗保险覆盖面进一步扩大,中国的医疗保险基金支出也在不断增加。根据国家统计局的数据,截至2022年年末,全国城镇居民参加基本医疗保险人数达到9.8亿人,医疗保险基金支出从2016年的1.1万亿元增长到2022年的3万亿元,年均复合增速为18%。医疗保险欺诈是指医疗机构或个人通过各种手段骗取医疗保险基金的行为。随着医疗保险基金的扩张,医疗保险欺诈问题也日益突出。中国社会保障学会指出,全球因欺诈导致的医疗保险基金损失占医疗保险基金支出的4.57%。以此为依据,可以计算出2022年全国医保基金因欺诈的损失要高达1371亿元,医疗保险欺诈问题日益突出,已经成为各国政府和医疗机构关注的焦点。
医疗保险欺诈是指个人或组织利用医疗保险制度中的漏洞、优惠政策或者非法手段,骗取、盗取医疗保险基金或者其他医疗资源的行为。这种行为通常包括虚假申报、虚开发票、虚构病情、假冒身份等等,旨在非法获得医疗保险待遇。医疗保险反欺诈则是对医疗保险欺诈进行有效的判断,目的是识别和防止医疗保险欺诈行为,保障医疗保险基金的安全和有效利用。目前医疗保险检测已然成为医疗保险领域的一项重要任务。
2. 文献综述
国内关于医疗保险反欺诈已有不少的研究成果。从研究内容来看,保险反欺诈工作主要分为事前监管和事中监管,事前监管是指保险机构在开展业务之前,通过申请人提交的申请信息来判断是否给出保险以及保费如何定价;事中监管是指保险机构在业务进行的过程中,对被保险人的行为进行监管与规范,从而识别其行为是否存在欺诈的事实。陈清华等(2023) [1] 通过对31个省市共111起骗保数据进行分析,采用fsQCA方法概括出参保人群妨碍、政治压力缺位、政策过程艰难和社会意识缺乏4种典型骗保模式。郑文珍等 [2] [3] 采用深圳市某家医院一个月的医保数据记录,在对原始数据进行预处理后,分别建立RF模型和XGB模型对医保正常数据和欺诈数据进行分类预测,最终F1和AUC的结果显示XGB模型具有更好地评估识别能力。李杰等 [4] 认为,XGBoost模型能够有效建立医保反欺诈系统,识别出潜在的医保欺诈现象,能够对医疗欺诈领域起到拨乱反正的作用。林源(2015) [5] 采用PCA和BP神经网络模型对新农合医疗机构的住院服务的滥用行为进行识别,研究显示BP神经网络模型能够有效检测出医疗欺诈行为,模型结果显著优于logistic回归模型。周杰辉等(2021) [6] 设计了医保反欺诈的可视化系统Medicare Vis,通过可视化对实例研究进行分析,结果显示该方法能够有效检测出欺诈行为的关联性。曹鲁慧等(2020) [7] 采用TLSTM的方法来挖掘用户的就医时间序列信息,判断用户存在就医欺诈的可能性。李金灿等(2021) [8] 介绍了运用在医保欺诈检测领域的有监督学习方法:神经网络和决策树,以及无监督学习方法:聚类分析、离群检测和关联法则挖掘,并分析了不同模型的优势与不足。有监督学习方法需要较多的参数与迭代,无监督学习法对异常值敏感,并且处理海量数据的效率低下。易东义 [9] 和易东义等 [10] 提出了病人与医生关系网络,采用GCN算法来挖掘欺诈信息,并结合主动学习方法来标注医保欺诈标签。同时在保险欺诈检测中,遇到的一个主要问题是欺诈数据的不平衡,原因是申请信息并不包含参保人在参保后的行为信息,通过行为信息(如消费信息)对参保人进行行为评分来实时识别欺诈的办法开始得到重视。吴文龙等(2021) [11] 采用生成对抗网络将得到的仿真数据加入到医保数据中,克服类别不平衡的影响。
事前监管的弊端不仅体现在无法监管参保人的事中行为,还无法对出现的团伙欺诈和医疗机构违规行为进行监督。本文将从以下三个方面进行研究:第一,观测样本存在多条行为信息,包含了在一个医院的多次就诊信息与在多个医院的就诊信息,研究如何通过知识图谱和行为信息来搭建医院与被保险人、被保险人与被保险人之间的关系。第二,根据医院的就诊项目与欺诈人群的就诊信息来识别易发生欺诈的处方、病情信息;第三,研究如何对就诊的行为信息进行更新与补充。在识别医疗保险欺诈的过程中可能的贡献有:1) 是将医院作为连接关系网络的判断依据,被保险人作为图的节点,为两个去过同一家医院的被保险人建立联系,增强反欺诈的识别能力;2) 是通过GCN来学习自身节点和邻接节点的信息,通过聚合–更新–聚合的方式来生成节点表征;3) 是通过在损失函数中对不同标签数据附加权重的方式来平衡类别权重,提升欺诈样本的影响,并结合Cluster-GCN的算法来减少算法的复杂度。
3. 评估方法介绍
3.1. GCN模型
图卷积网络(GCN)是图神经网络(Graph Neural Networks, GNN)的一种。GNN是一种深度学习模型,它用于处理图数据,例如社交网络、化学分子和交通网络等。GNN通过对节点特征进行聚合和信息传递,从而实现对整个图的建模和分析。GNN的基本思想是通过聚合每个节点周围的信息来更新节点的特征表示,并利用这些更新的节点特征来预测节点的标签或执行其他任务。GNN主要包括两个主要组成部分:节点嵌入(node embedding)和图嵌入(graph embedding)。
节点嵌入主要是将每个节点的特征表示为低维向量,同时考虑节点周围的邻居节点。节点嵌入可以通过各种各样的方式来计算,例如GCN (Graph Convolutional Network)、Graph SAGE、GAT (Graph Attention Network)等。图嵌入则是将整个图表示为一个低维向量,可以用于图分类或图生成等任务。图嵌入可以通过池化(pooling)或图卷积等方式实现除了一些众所周知的英文缩写,如IP、CPU、FDA,所有的英文缩写在文中第一次出现时都应该给出其全称。文章标题中尽量避免使用生僻的英文缩写。
图1为节点信息更新的方式。以A点为例,A点的邻接节点是B、C、D,B节点通过将自身节点的信息与聚合过来的A、C节点的信息进行变换,得到新的B节点信息。同样的过程发生在C和D节点上。A再将聚合得到的B、C、D节点信息与自身节点信息进行变换得到新的节点信息。多次更新后的节点信息就作为节点的特征表示。
在GCN模型中,记一个图的节点个数为N,图的邻接矩阵为A,X(l)是第l层的节点表征。一个L层的图卷积神经网络由L个图卷积层组成,每一层都通过聚合邻接节点的上一层的表征来生成中心节点的当前层的表征:
(1)
(2)
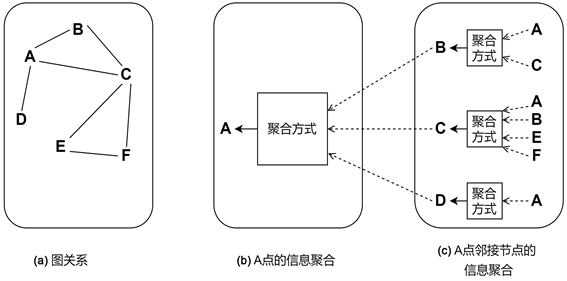
Figure 1. Mode of the node information updated
图1. 节点信息更新的方式
公式(1)中,X(l)表示l层的N个节点表征;X(0) = X,X是输入的初始节点属性;
是归一化和规范化后的邻接矩阵,用于聚合其他节点的信息;W(l)是权重矩阵,包含了要训练的参数;激活函数σ(·)设定为ReLU,用于传递当前层的节点信息。
训练的目标是通过最小化损失函数来学习公式(1)中的权重矩阵:
(3)
由于样本存在类别不平衡,为了消除影响,通过附加权重的方法来提升欺诈样本的影响。式(3)中,
表示未发生欺诈的用户,
表示欺诈用户。
表示
的类别权重,
表示第i个节点的真实类别,
表示第i个节点的预测类别。
3.2. Cluster-GCN模型
为了减少计算的复杂度,在实际训练阶段,本文采用了Cluster-GCN的方法,通过图聚类算法将节点分为多个簇,在每个epoch中,不放回地抽取随机的q个簇来构成一个batch。GCN和Cluser-GCN的复杂度如表1所示,其中b表示每个batch的节点数。

Table 1. Time complexity and spatial complexity
表1. 时间复杂度与空间复杂度
4. 模型建立与结果分析
4.1. 数据预处理
本文一共收集了2016年20,000个医保用户的医疗数据,共包含了183万条就诊记录。数据集包含了诊断病种名称与处方中的药物名称,还根据每次就诊中的处方信息对就诊记录进行了细分,共记录了530多万条就诊的具体项目信息。在20,000个医保用户中,欺诈人数1000,占总人数的5%。由于数据过多,研究采用文本识别的方法来对诊断病种和处方药物进行分类,同时对出现频率较高的文本信息进行了one-hot编码,对编码取值为1的处方药物用相应的费用数据来代替,具体的特征编码见表2。
4.2. 建模过程
在生成节点信息的过程中,本文以个人编码为主键,分别采用平均和加总两种方式对各用户的处方项目费用特征与诊断病种进行处理,最终获得20,000条动态就诊数据和82个特征。在这基础上,记录参保人曾经就诊过的医院,并为去过同一个医院的参保人建立关系,最终得到一个包含了20,000个节点和3200多万条边的图数据集,并根据6:2:2的比例将数据集分为训练集、验证集和测试集。在实际应用中,节点的特征会在每一次就诊后都发生更新,节点之间也可能会产生新的边关系,由此实现实时识别医疗欺诈。
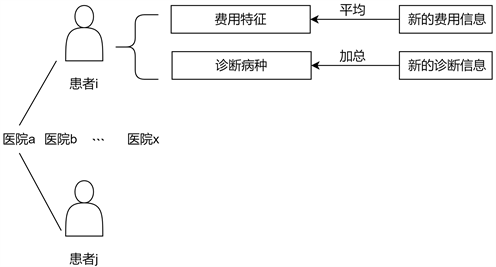
Figure 2. The way to update the doctor-patient information in real time
图2. 实时更新医患信息的方式
实时更新医患信息的方式如图2所示,患者i和j由于都去过同一家医院,就为两个节点添上边,i和j互为邻接节点,通过图2的方式对节点信息进行更新。节点的信息包含了费用信息和诊断病种信息。为了保留过去的就诊记录,并对未来的就诊行为信息进行更新,本文采用平均法对每个项目的费用信息进行记录并在未来进行更新,平均法得到的费用能够用于检验患者该项费用是否异常;采用加总的方式对诊断病种信息进行记录。由于每条就诊记录的诊断病种进行过one-hot编码,所以将个人的诊断病种特征进行加总就能得到患者被诊断出某一病种的次数。
本文采用图卷积神经网络(GCN)来学习节点表征,并对节点的类别做出预测。通过设置三层卷积层来对患者的行为特征进行处理,并分别将隐藏层特征节点设置为60、40、20,每一层患者的节点表征都受到上一层与他去过同一家医院的患者节点表征的影响。本文将学习率设置为0.001,分别把图分为了400、700和1000簇,并将batch_size设置为10。最终输出欺诈或非欺诈的二分类预测。因此文章的算法考虑了医疗机构监管缺位对患者行为可能存在的引导作用,以及患者之间的行为影响机制。
4.3. 结果分析
本文分别训练了400、700和1000簇的Cluster-GCN模型,并比较了模型在测试集上的AUC、Recall、F1值和Accuracy,具体的结果见表3。Accuracy是总体的预测准确率,Accuracy0和Accuracy1分别代表非欺诈样本的预测准确率和欺诈样本的预测准确率。
Table 3. Classification performance of the models on the test set
表3. 模型在测试集上的分类性能
从AUC、Recall和F1指标来看,簇数对模型的分类性能影响不大。从Accuracy来看,簇数为400的训练策略的总体预测准确率和在非欺诈样本上的预测准确率较低,但在欺诈样本上的预测准确率最高,这是因为非欺诈样本数量较多,所以对总体预测准确率的影响权重更大。随着簇数的增加,模型在欺诈样本上的预测准确率反而下降。
除了搭建Cluster-GCN以外,本文还训练了多层感知机(MLP)模型。比较二者的分类结果发现,Cluster-GCN拥有更高的AUC和Accuracy1。虽然MLP有着较高的总体预测准确率89.1%,但反欺诈的预测能力即Accuracy1只有51.2%。在实际应用中,医保基金更注重于识别欺诈用户,所以Cluster-GCN具有更强的医疗保险反欺诈的能力。
5. 结论
随着医疗保险基金规模的日益壮大与就诊信息的爆炸式增长,医疗保险系统亟需一个能够高效、实时处理大数据的模型来应对欺诈带来的挑战,减少欺诈损失。本文通过图神经网络来对医疗保险欺诈行为进行检测,并利用文本分析的方法对诊断病种和处方药物两类特征进行分类。为了实现实时识别欺诈,设计了个人就诊行为信息的处理方式,以去过同一家医院为标准建立被保险人与医院、被保险人之间的关系,并通过GCN图神经网络来更新节点之间的信息。研究结果表明,Cluster-GCN模型在检测医疗保险欺诈行为上具有更好的分类性能,其AUC达到0.86以上,总体识别欺诈的准确程度达到83.37%,反欺诈的识别率为77.25%。
基金项目
国家社会科学基金项目(17BJY233)资助。