摘要: 高光谱图像具有高维度和高相关性,导致“维度灾难”和计算成本高。本文利用波段的标准差和相关系数,选择信息量大且相关性小的波段作为特征波段。为克服原始OIF难以在高光谱图像中采用的困境,提出分组式OIF (Grouping OIF, G-OIF)将高光谱图像分为若干子集,分别计算每个子集的最佳波段组合,然后并集得到整个图像的最佳波段组合。使用Indian Pines数据集,采用随机森林和支持向量机作为分类器,比较不同的分组和波段数对分类效果的影响。最后发现使用G-OIF时分组越多,波段数越多,分类效果越好。G-OIF能够在保证精度的同时实现降维,并缓解“维度灾难”。
Abstract:
Hyperspectral images are highly dimensional and highly correlated, leading to the “curse of di-mensionality” and high computational cost. In this paper, the standard deviation and correlation coefficient of the bands are used to select the bands with large amount of information and low correlation as the characteristic bands. In order to overcome the dilemma that the original OIF is difficult to use in hyperspectral images, a grouping OIF (Grouping OIF, G-OIF) is proposed to divide hyperspectral images into several subsets, calculate the best band combination for each subset, and then combine Get the best band combination for the entire image. Using the Indian Pines dataset, random forest and support vector machine are used as classifiers to compare the effects of different groups and band numbers on classification performance. Finally, it is found that when using G-OIF, there are more groups, more bands and better classification effect. G-OIF can achieve dimensionality reduction while ensuring accuracy, and alleviate the “curse of dimensionality”.
1. 引言
高光谱遥感图像(Hyperspectral Image, HSI)是由数百个连续窄带组成的图像,具有很高的光谱相关性,HIS的高维度数带来了“维度灾难”问题,即在固定的少量样本情况下,当维度降低时,HIS的分类精度会随着维度增加而下降 [1] [2] [3] 。在遥感地物分类的应用中,大量的训练样本是昂贵且耗时的,甚至不可能。因此一般考虑利用其中具有代表性的波段作为“特征波段”。“特征波段”的产生一般包括两种技术方法:波段提取和波段选择。波段提取是利用线性或非线性的方式对原始高维波段进行变换,从而实现数据降维,其“特征波段”中的信息是原始所有数据信息的综合,而波段选择,是在原始的高维波段中,通过某些准则或方式在原始波段中选择出若干个波段,强调的是在原始波段中通过什么方式进行选择。
虽然他们都是降低数据维度的技术,但波段提取与波段选择相比,波段选择具有两个个优势:1) 从原始数据选择出的波段子集,没有进行相关的其他处理,依旧保持波段代表的物理意义 [4] ;2) 一般而言,不同的物质在光谱上会有不同的表现,但也可能由于光谱分辨率及光谱范围的限制表现为异物同谱。在数百个波段中,往往只有少数波段在地物彼此区分中起到了关键作用。通过波段选择,可以找到这些特定波段,从而提高对物体光谱性质的认识。
在HIS中,相邻的波段具有高度的相关性,但可能不携带有用的鉴别信息,导致所谓的Hughes现象(即“维度灾难”)和处理中的高计算成本,为了避免这些问题,波段选择取得了很好的效果,它可以去除冗余的波段。根据其是否使用除影像本身外的其他先验性信息,分为非监督波段选择和监督波段选择 [5] 。与监督波段选择相比,非监督波段选择技术不要求特定的应用,拥有更加灵活的使用场景。对于非监督波段选择技术,根据是否考虑了相关性可以将其分为两类:1) 不考相关性的方法常通过某种单一波段的指标来实现,例如信息熵、信噪比和信息散度等。2) 最佳指数因子(Optimal Index Factor, OIF),计算波段的标准差和相关系数来衡量频带的重要性,并从中选择最优组合方案,这是一种考虑了多波段的相关性的方法。
OIF在多光谱被广泛使用,2016年赵庆展等人 [6] ,基于无人机多光谱遥感数据结合OIF方法、植被和水体指数等特征,提出了一种综合空–谱信息的最佳波段组合选择方法;2019年郭力娜等人 [7] ,研究了基于Landsat 8 OLI影像的城市土地利用OIF选择方法,并验证了其有效性;2022年王芳等人 [8] ,基于“高分二号”和“北京二号”卫星影像数据,考虑OIF来选择典型地物信息提取的最佳波段组合。这些学者采用OIF的场景有个典型的特点,即都是多光谱数据,原因在于OIF需要计算所有波段的方差和多个波段间的相关性系数,这对于高达数百波段的高光谱遥感数据来说几乎是不可能完成的。因此,本文将提出一种分组式OIF (Grouping OIF, G-OIF)的方式来选取高光谱遥感数据的“特征波段”,从而克服传统OIF在高光谱数据无法使用的困难。
2. 实验数据
本文选取高光谱数据集Indian Pines,这是一个高光谱图像分割数据集,包括了美国印第安纳州的一个单一景观上的高光谱波段,像素为145 × 145。对于每个像素,数据集包含220个光谱反射波段,代表了电磁光谱中不同部分的波长范围0.4~2.5 μm。Indian Pines由机载可视红外成像光谱仪(AVIRIS)于1992年对美国印第安纳州一块印度松树进行成像,然后截取尺寸为145 × 145的大小进行标注作为高光谱图像分类测试用途。Indian Pines的细节如下表1:

Table 1. Details of Indian Pines
表1. Indian Pines的细节
Indian Pines数据集包括了16个有具体意义的类别,除此之外的所有像素类别均为索引为0的背景。Indian Pines的彩色图像和真实地面(以灰度形式显示)如下图1:
 (a) 波段29,19,9的合成图像 (b) 真实地面
(a) 波段29,19,9的合成图像 (b) 真实地面
Figure 1. Visualization of the Indian Pines dataset
图1. Indian Pines数据集的可视化
3. 最佳指数因子的波段选取
3.1. 最佳指数因子的计算方式
OIF方法主要考虑了三个方面:1) 选取的特征波段信息量尽可能大;2) 特征波段间的相关性要小,因为相关性越大代表蕴含不同地物间的信息差异越小,这不利于像素级的分类;3) 特征波段对不同地物的光谱差异越大越好。本文选取的OIF计算方式如下所示:
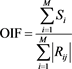 , (1)
, (1)
其中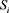 代表第i波段的标准差,
代表第i波段的标准差,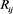 表示第i波段和第j波段之间的相关系数,M表示的波段数,且M需要预先设置。OIF的原理十分简单,通过计算考虑所有波段的标准差和多波段的相关系数,标准差越大和相关性越小,则选取的波段信息量越大。对于
表示第i波段和第j波段之间的相关系数,M表示的波段数,且M需要预先设置。OIF的原理十分简单,通过计算考虑所有波段的标准差和多波段的相关系数,标准差越大和相关性越小,则选取的波段信息量越大。对于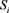 来说,计算出所有波段的标准差是不难的。但是在面对数百的波段的高光谱数据,在计算
来说,计算出所有波段的标准差是不难的。但是在面对数百的波段的高光谱数据,在计算 时,设置的M越大波段间的组合越多,会对计算机内存造成极大压力,甚至出现内存不足的情况。
时,设置的M越大波段间的组合越多,会对计算机内存造成极大压力,甚至出现内存不足的情况。
3.2. 分组式OIF (G-OIF)的计算方式
为了缓解面对高光谱数据时计算OIF造成的内存压力,本文受分段信息熵 [9] 的启发,采用分组式的OIF来选择特征波段。如果将Indian Pines数据看作是一个向量空间,则将每一个像元可以看作一个220维的向量,整个数据集的维度为(145, 145, 220)。Indian Pines数据集记作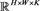 ,其中
,其中 代表影像尺寸,K等于波段数。
代表影像尺寸,K等于波段数。
以K这个维度为基准,先确定将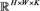 分为n组,记为
分为n组,记为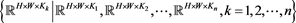 。每组都可以看作是原数据集的一个子集,且每个子集间是互斥的,即:
。每组都可以看作是原数据集的一个子集,且每个子集间是互斥的,即:
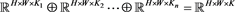 , (2)
, (2)
 意思是直和。
意思是直和。
在每个子集中根据公式(1)确定每个子集的最佳波段组合(Optimum Band Combinations, OBC),记为 。最后确定的整个数据集的最佳波段组合为:
。最后确定的整个数据集的最佳波段组合为:
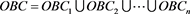 . (3)
. (3)
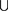 表示并集,完整的计算过程如下:
表示并集,完整的计算过程如下:
4. 实验与结果评价
4.1. 超参数初始化
G-OIF要求首先对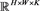 做分组处理,其中要求两个超参数M和n合理。在本文中n要求为n|K (“|”是整除符号),同时要求
做分组处理,其中要求两个超参数M和n合理。在本文中n要求为n|K (“|”是整除符号),同时要求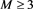 ,则在一个子集
,则在一个子集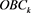 中,一共有
中,一共有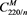 种组合。除此之外,若M,n设置不合理,计算组合时可能仍然会耗费大量时间和内存资源,在实验时不考虑这些不合理的情况。
种组合。除此之外,若M,n设置不合理,计算组合时可能仍然会耗费大量时间和内存资源,在实验时不考虑这些不合理的情况。
4.2. 实验方法
随机森林(Random Forest, RF)和支持向量机(Support Vector Machine, SVM)是两种常用的用于高光谱图像分类的机器学习算法。RF是一种集成学习方法,它构建多个决策树并输出类,即单个树的类的模式。它在高光谱图像分类中取得了巨大的成功。另一方面,SVM是一种监督学习模型,它在高维空间中构建一个超平面或一组超平面,可用于分类或回归。SVM已广泛应用于高光谱图像分类。
4.3. 结果分析比较
本文根据不同的超参数M和n,利用G-OIF确定最佳组合波段后,并通过RF和SVM进行分类,将不同的波段组合进行比较。n设置为4、5、10、22、44和55,过滤过于耗费时间的M,对应的M分别为3-6、3-6、3-9、3-9、3-4和3,并且根据不同M时的分类结果进行分析。采取的评价指标为Kappa系数、平均精确度(Average Accuracy, AA)和总体精确度(Overall Accuracy, OA),RF和SVM的分类结果具体如下表2和表3:
Table 2. Comparison of RF classification result indicators
表2. RF的分类结果指标对比
Table 3. Comparison of classification result indicators of SVM
表3. SVM的分类结果指标对比
首先讨论n对G-OIF的影响,为了容易观察,计算出每个子集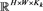 的各个指标的均值,然后可视化,如图2。能够明显的看出随着n的增大,RF和SVM的Kappa、AA和OA均呈现上升趋势。这说明随着M,n的变化,特征波段的数量也在变化,但其蕴含的信息量会越来越大,说明G-OIF的方法能够在实现减少计算成本的同时尽最大可能选出那些对分类有益的波段。
的各个指标的均值,然后可视化,如图2。能够明显的看出随着n的增大,RF和SVM的Kappa、AA和OA均呈现上升趋势。这说明随着M,n的变化,特征波段的数量也在变化,但其蕴含的信息量会越来越大,说明G-OIF的方法能够在实现减少计算成本的同时尽最大可能选出那些对分类有益的波段。
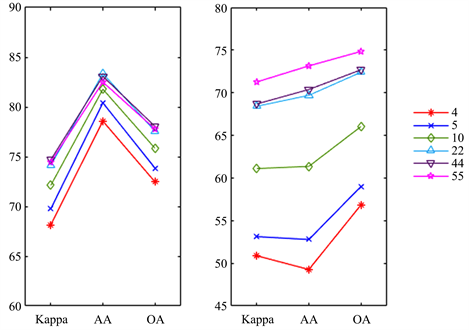 (a) RF (b) SVM
(a) RF (b) SVM
Figure 2. Mean values of various indicators of RF and SVM when n = 4, 5, 10, 22, 44, 45
图2. n = 4, 5, 10, 22, 44, 45时RF和SVM的各指标均值
接下来讨论当n固定时,即每个子集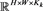 中,M变化时对RF和SVM产生的影响。从表2和表3能够很明显的看到,在每个子集中,选定的特征波段数量越多,其Kappa、AA和OA越大,说明分类效果与特征波段数量程正相关。
中,M变化时对RF和SVM产生的影响。从表2和表3能够很明显的看到,在每个子集中,选定的特征波段数量越多,其Kappa、AA和OA越大,说明分类效果与特征波段数量程正相关。
最后一个很明显的现象是:分组越多,同时设定的最佳波段组合的波段数越多,分类效果是越好的。原因是高光谱数据集的相邻波段相关性是很高的,分组越多时且选定的波段越多时更容易将那些蕴含更多差异性的波段选择出来。
5. 结论
原始的OIF计算方法在面对高光谱影像时,计算过多波段的组合会造成巨大的时间和内存压力,这甚至是无法完成的。本文受分段式信息熵的启发提出的G-OIF能够缓解这个问题,G-OIF通过对高光谱数据进行分组,在每个子集中获得该子集的最佳组合波段,最后并集获得完整的最佳组合波段。G-OIF在保证精度的同时实现了降维,并缓解了“维度灾难”。在未来,自适应的分组和波段数是一个具有潜力的研究方向。