1. 引言
强化学习方法起源于动物心理学的相关原理,模仿人类和动物学习的试错机制,是一种通过与环境交互,以获得最大累积期望回报的方法。强化学习通常使用指数函数对未来的奖励进行折现,以实现理论上的收敛。然而由于强化学习中奖励的延迟机制,通常会导致时间不一致性。来自神经科学、心理学和经济学的研究也表明,双曲折现模型可以更好地捕捉人类和动物的时间偏好。
作为双曲时间偏好的一个例子,考虑以下情境:假设一个陌生人向你提出一个交易。他立即给你100美元,没有风险,但如果你可以等到明天,他承诺给你110美元。由于没有进一步的信息。许多人对这位潜在的捐助者持怀疑态度,选择立即获得100美元,因为未来的承诺会有风险。然而,在另一个交易中,他承诺365天内给你100美元,366天内给你110美元。在这个交易中,许多人选择110美元。实际上贴现率已经进一步下降了,这表明人们相信,如果在365天没有违背承诺,那么在366天不太可能被违背 [1] 。
指数折现在这些选择之间总是保持一致,而双曲折现可以显示出时间偏好逆转。这种时间偏好之间的差异可能被认为是不合理的。然而,这种行为在数学上与智能体对环境中的风险率保持一定不确定性是一致的,奖励根据主体可能会遭受风险而被折现的可能性来进行计算,因此主体可能无法幸存以获得奖励 [2] 。强化学习环境也具有风险的特征,同时风险可能会随着值函数和策略的变化而变化。
纵观该领域的研究,已有不少研究成果。Alexander等 [3] 定义了一个学习算法,双曲贴现时间差分学习,它构成了双曲模型的递归公式。Alia等 [4] 研究了具有随机跳跃的随机微分方程驱动的时间不一致随机控制模型,在博弈论框架中表述时间不一致的问题,并寻找在时间不一致性下的时间一致的纳什均衡解。Schultheis等 [5] 研究了非指数折现下的强化学习,将环境的状态过程建模为扩散过程,并提出了一种任意折现函数下的强化学习方法。Nafi等 [6] 研究了双曲折现对泛化任务的影响,并提出了强化学习中的泛化双曲贴现。Ali等 [7] 论述了非指数折现函数对强化学习中智能体学习的影响,并研究其对多智能体系统和泛化任务的影响,同时指出使用非指数折现对强化学习的必要性。Kwiatkowski等 [8] 提出广义优势估计,允许以任意折扣计算优势值直接应用于现代策略行为批评算法。这些研究结果都表明,利用强化学习进行决策优化时,不能简单认为智能体是时间一致性的。
本文的主要贡献和创新体现为以下两点:第一,从研究方法上看,使用生存分析中的生存函数和风险率刻画折现函数,这种方法可以表示一般的折现函数,包括指数折现和非指数折现两种情况。从研究内容上看,使用跳跃–扩散过程对强化学习中的环境状态建模,研究跳跃–扩散过程下值函数和发生偏好逆转时间的变化。通常,使用跳跃–扩散过程建模具有不连续变化的变量,比如突发事件的冲击,这为决策者预测识别潜在的突发事件,从而采取相应的预防措施,也为开发出更具稳定性和适用性的算法提供有益的参考。
2. 理论分析
生存分析中涉及两个重要的概念生存函数和风险率。使用生存函数表示折现函数,风险率则表示未来的奖励无法实现的风险 [2] 。当假设风险率
为常数时,主体以指数函数的方式进行折。当假设风险率是一个恒定但未知的量
时,其概率分布假设为
,就可以得到关于预期生存函数的双曲形式。使用生存函数和风险率可以准确刻画指数折现和双曲折现的情况,能满足智能体具有时间不一致性的要求。
强化学习是在马尔科夫决策过程框架下进行的,跳跃–扩散过程是马尔科夫决策过程。使用跳跃–扩散过程建模强化学习中的环境状态是合理的。
3. 模型构建
3.1. 环境模型
考虑一个具有跳跃的状态空间
和有限的行动集U的随机控制系统 [9] ,使用生存函数
和基于时间依赖的风险率
刻画折现函数。这样生成的值函数是依赖于时间的。在强化学习中,将环境状态建模为由泊松过程驱动的具有跳跃的几何布朗运动,环境状态模型可表示如下:
(1)
其中,
,
是漂移函数,
是方差矩阵,
是n维布朗运动,
是泊松过程跳跃的幅度,
是泊松过程。
强化学习的目标是最大化长期奖励,因此将总的期望折现奖励作为智能体在执行策略时的预期的累积奖励:
(2)
其中,将预期回报定义为在某个状态或者状态–动作对下,根据当前策略和未来奖励的期望累积回报。值函数度量了智能体在达到某个状态或状态–动作对后,预期能够获得的累积奖励。智能体在特定状态或状态–动作对下采取特定策略时的长期回报期望可表示如下:
(3)
其中,
表示在时间τ之后存活到时间t的概率,假设个体已经在时间t存活。等式(3)中的值函数和最优策略与时间相关,这表明时间在决策和优化过程中时间需要被考虑。
3.2. 折现函数
生存分析理论涉及两个基本概念,即生存函数和风险率。在生存分析中,对事件发生前的持续时间非常感兴趣 [10] 。考虑单个事件时,可以将其持续时间描述为一个连续随机变量T,事件持续时间的累积
分布函数可以表示为
,其中
表示持续的时间。同时,使用概率密度函数
描述该持续时间的分布特征。一般情况下,
作为失效函数已知,并且定义生存函数为
。生存函数单调递减,并且满足
和
。
通过条件概率准则,可以得到
,
。这表明,在给定事件已经持续
的情况下,事件持续到
的概率等于这两个时刻的生存函数的比值。
风险率
定义为在给定
的条件下,单位时间内事件发生的概率。具体而言,
,风险率和生存函数之间的关系为:
(4)
考虑智能体获得单一奖励并对环境表现出一种时间偏好,将奖励值r建模成一个函数
,其中
,
是随时间递减的折现函数,
将
视为生存函数,存在一个风险率
,表示未来的奖励无法实现的风险 [2] 。当假设风险率
为常数时,智能体以指数函数的方式进行折现,即
。当假设风险率是一个恒定但未知的量时,其信念
的概率分布假设为
,就可以得到关于预期生存函数的双曲形式:
(5)
使用贝叶斯法则推导出关于 的后验信念,表示为
,根据后验分布,预期的风险率
由后验均值计算得出:
(6)
证明 见附录。
3.3. 基本假设
假设1:第2节中定义的随机过程具有强唯一解的性质,即漂移函数f和方差矩阵G以及跳跃幅度h是线性增长的,并且在相同变量上是Lipschitz连续 [11] 。即存在常数
,对所有的
和
,有
假设2:值函数通常不够平滑,以满足“经典”意义上的解。因此,考虑使用粘度解,它在适当的广义意义上满足HJB方程。解存在的一个充分条件是f和G有界,关于x和t具有有界连续的一阶导数。函数R和S是多项式增长的 [12] 。
即存在常数
,有对所有的
和
,有
假设3:等式(2)中的积分是收敛的,对具有双曲折现函数的情况时,以下定理成立:
定理1:对于等式(5)中的双曲折现函数,如果奖励函数
对于所有的
有上界,并且
,那么方程(3)中的值函数是符合定义的。如果奖励函数
对于所有的
有下界,并且
,那么方程(3)中的值函数不符合定义。
证明 见附录。
3.4. HJB方程的推导
这里简要概述一般折现函数的HJB方程的推导。首先,将等式中的积分分割成两项,从而得到值函数的递归形式:
(7)
对于第二项,利用泰勒展开和伊藤引理进行推导,得到:
(8)
将等式(8)代入等式(7),两边同时除以
,并取极限
,计算关于
的期望,可以得到所需的HJB方程:
(9)
代表生存函数对应的风险率,将HJB方程等式(9)的右边关于动作没有最大化时定义为:
因此所求的值函数表示为
,最优策略表示为
。
推导 见附录。
3.5. 求解HJB方程
基于配点法 [13] [14] [15] [16] 求解等式(9),首先将其重新表述为:
(10)
使用值函数
近似最优值函数
,其中参数
通过对状态
和时间
随机采样,关于
最小化
获得。选择神经网络作为函数逼近器,偏导数
,
,
可以通过自动微分直接计算得到。由于t不是有界的,t需要被重新参数化,因此将所有的t映射到区间
。
具体的做法如下:
假设一个有界的状态空间
,从这个状态空间随机均匀地采样 ,时间点
从指数分布中采样,让
,然后计算
,为了将一个标准化的时间值输入网络,使用
而不是
作为网络的输入,用
表示依赖于y的值函数网络。可以通过
计算一个特定的时
间值t的表示。当计算偏导数
时,必须考虑再参数化。根据链式法则,有:
根据所选变量的参数化,有以下结果:
4. 数值例子
使用一个投资问题作为数值模拟实验的案例 [5] 。在这个问题中,一个主体需要决定将其的收入投资到银行账户以获得未来的奖励,或者即时消费作为即时奖励。将状态建模为银行账户的当前余额和当前利率,当主体选择消费时,主体会获得利率为0.1的奖励,但账户的余额保持不变。当主体选择投资时,银行账户的余额以0.1的利率增加,但没有额外的奖励。在这两种情况下,主体通过利息获得奖励。奖励与银行账户的当前余额成比例。假设利率根据跳跃–扩散模型随时间变化,并且为了使状态有界,对账户余额引入一个最大余额的限制。具体模型的描述如下:
状态空间
,账户余额和利率建模为
行动空间
动态模型
奖励函数
风险率
,
5. 数值结果及讨论
5.1. 风险率和生存函数
在投资问题中,
,
,
。即双曲折现条件下的风险率为
,生存函数为
。指数折现下的风险率为3,生存函数为
。以下是风险率和生存函数图:
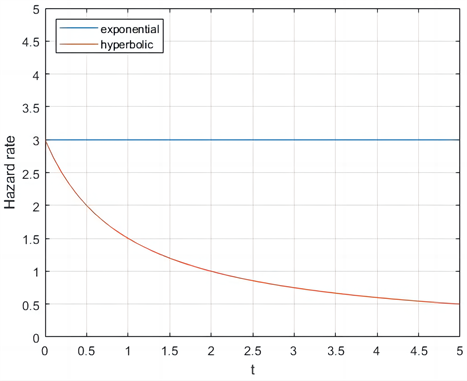 (a) 风险率
(a) 风险率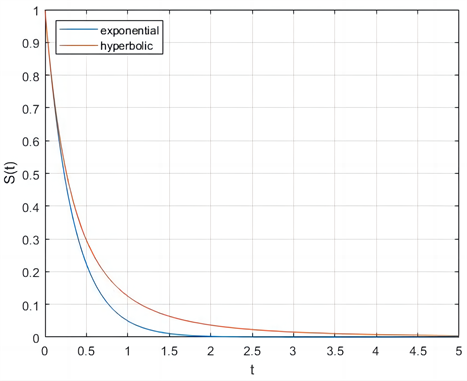 (b) 生存函数
(b) 生存函数
Figure 1. Hazard rate and survival function
图1. 风险率和生存函数
从图1中可以看出,双曲折现函数的风险率呈递减的趋势,随着时间的变化,风险率越来越低。指数折现的风险率保持不变。用生存函数刻画双曲折现和指数折现函数时,两种折现函数的递减趋势相同。
5.2. 跳跃过程对值函数和发生偏好逆转时间的影响
使用双指数分布建模跳跃幅度,其中双指数分布的参数为
,泊松过程的强度
和
。
图2给出了当
,即环境被建模为扩散过程时,双曲折现和指数折现下的结果。从图(a)可以看到随着账户余额的增加,值也会增加。因为余额增加,通过利息获得的预期回报会增加。随着时间的推移,值会进一步增加,因为当风险率比较低时,人们预期能够长期获得回报。图(b)和图(c)展示了学习到的策略和Q函数。在开始阶段,消费是有利的,但当风险相对较低时,投资变得更加吸引人,从而引发偏好逆转的现象。图(d)和图(e)展示了指数折现下的值函数和Q函数,由于风险率保持不变,可以看到值函数和Q函数不显示偏好逆转,并且随着时间保持不变,因此人们的偏好逆转不发生改变。
图3给出了
,即环境被建模为跳跃–扩散过程时,跳跃幅度为双指数分布时,双曲折现和指数折现下的结果。从图(a)可以看到环境被建模为跳跃–扩散过程时,账户余额基本保持不变,值函数与时间高度相关,并且在一定的时间范围内,值函数大小不发生变化。图(b)和图(c)展示了学习到的策略和Q函数。在开始阶段且账户余额小于0.7时消费是有利的,但当风险相对较低时,投资变得更加吸引人,从而引发偏好逆转的现象,并且与环境被建模为扩散过程相比,偏好逆转发生的时间较早。图(d)和图(e)展示了指数折现下的值函数和Q函数,可以看到值函数和Q函数同样不显示偏好逆转,并且随时间保持不变。
5.3. 不同强度的泊松过程对值函数和发生偏好逆转时间的影响
使用双指数分布建模突发事件的跳跃幅度,其中双指数分布的参数为
,泊松过程的强度
和
。
图4给出了跳跃幅度为双指数分布时,
和
,双曲折现下的结果。从图(a)看出,值函数与时间高度相关,账户余额基本保持不变。从图(d)看出,值与时间高度相关,在时间区间[3.5, 4.1]上,随着账户余额的增加,值函数的值也增加。可以看出,泊松过程的强度越大,值函数的范围越大。图(b)、图(c)和图(e)、图(f)展示了两种强度下的策略和Q函数。可以看出在开始阶段且账户余额小于0.7时消费是有利的,当风险相对较低时,投资变得更加吸引人,从而引发偏好逆转的现象,并且泊松过程的强度越大,偏好逆转发生的时间越早。
5.4. 同一强度下不同分布的跳跃幅度对值函数和偏好逆转时间的影响
使用正态分布、指数分布、双指数分布建模跳跃幅度,其中跳跃幅度
服从正态分布的参数为
,跳跃幅度
服从指数分布的参数为
,跳跃幅度
服从双指数分布的参数为
。
图5(a)、图5(d)、图5(g)展示了跳跃幅度的分布分别为正态分布、指数分布、双指数分布下的值函数,可以看出值函数与时间高度相关,在时间区间[3.2, 6]上,随着账户余额的增加,值函数的值也增加。
图5(b)、图5(c)和图5(e)、图5(f)和图5(h)、图5(g)展示了三种分布下的策略和Q函数。可以看出跳跃幅度为正态分布时,在开始阶段且账户余额小于0.6时消费是有利的,但当风险相对较低时,投资变得更加吸引人,从而引发偏好逆转的现象。当跳跃幅度为指数分布和双指数分布时,在开始阶段且账户余额小于0.64时消费是有利的,但当风险相对较低时,投资变得更加吸引人,从而引发偏好逆转的现象。同一强度下的跳跃幅度,当跳跃幅度为正态分布时,偏好逆转发生的时间更早。
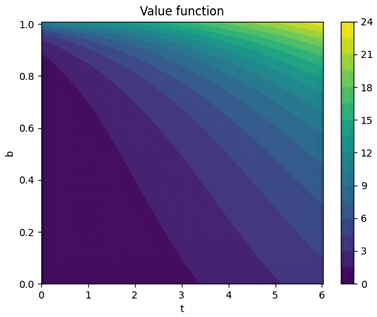
(a) 值函数
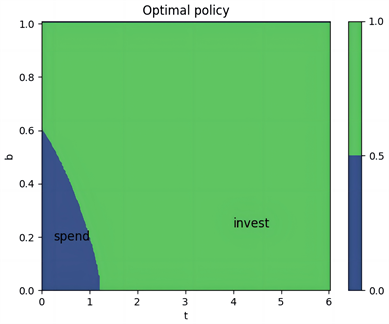
(b) 最优策略
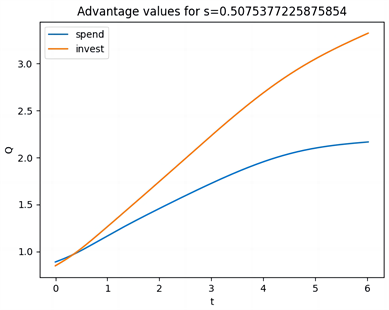
(c) Q函数

(d) 值函数
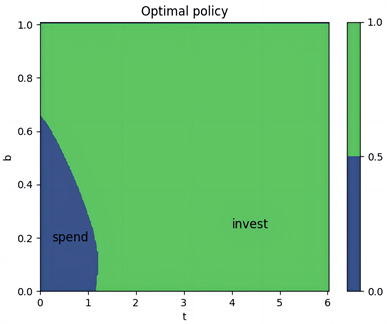
(e) 最优策略
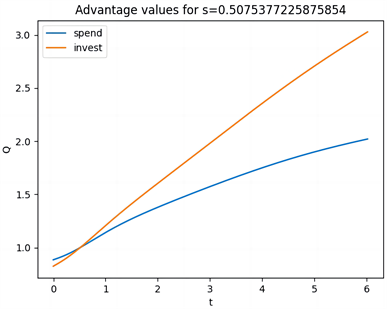
(f) Q函数

(g) 值函数
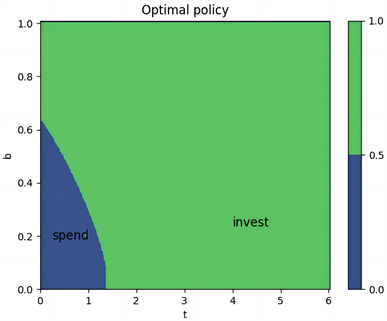 (h) 最优策略
(h) 最优策略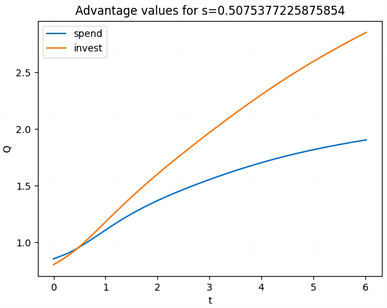 (i) Q函数
(i) Q函数
Figure 5. Value Function, Optimal Policy, and Q-function under Hyperbolic Discounting for λ = 5, with Three Distributions
图5. λ = 5,三种分布在双曲折现下的值函数、最优策略、Q函数
6. 研究结论与启示
本文首先利用生存函数和风险率刻画折现函数,其次基于跳跃–扩散过程对强化学习中的环境状态建模。给出了使用双曲折现函数时问题的限制条件,并且推导了一个HJB方程,给出了要使HJB方程有解,方程的限制条件。探讨了跳跃–扩散过程下值函数和发生偏好逆转时间的变化。主要的结论如下:
第一,跳跃–扩散过程下值函数与时间高度相关且发生偏好逆转的时间提前。第二,同一分布下的跳跃幅度,强度越大,值函数的值越大,偏好逆转发生的时间越早。第三,同一泊松过程的强度下,当跳跃幅度的分布为正态分布时,值函数的值最大,偏好逆转发生的时间最早。最后得出,在强化学习中,使用双曲折现函数能更好的模拟智能体做决策时的时间偏好。
基于上述的研究结论,立足于利用强化学习进行决策优化,针对跳跃–扩散过程和本文的实验过程,本文提出以下建议。
第一,使用强化学习进行投资决策时,应该使用双曲折现函数,这样能更好地模拟人类的时间偏好。利用强化学习进行决策优化时,当环境被建模为跳跃–扩散过程时,人们最好在原来时间的基础上提前调整自己的策略。
第二,在推导过程中,对跳跃项的近似处理、在数值实验时固定突发事件发生的次数。这样的处理在一定程度上会导致结果出现误差,未来的研究可以考虑更加灵活的跳跃模型,并探索使用其他方法求解HJB方程,以进一步提高实验结果的可靠性和准确性。