摘要: 如今,无人机(UAV)逐渐被用于各个领域,例如交通监控和智能停车,其中对车辆的实时监测和分类是关键任务之一。在车辆检测方面存在许多挑战,例如小型车辆目标和无人机工作时飞行角度的变化导致目标尺度变化从而给车辆检测网络模型的优化带来的负担。此外,由于高空飞行时航拍图像目标较小、可提取特征较少,而导致模型检测精度较低。为解决上述问题,本文旨在基于YOLOv5算法,提出了一种准确、高效、实时的车辆检测网络。首先,为了使模型更好地提取小目标特征,在Neck部分添加了一个新的连接层,将第一个C3层的高分辨率特征映射连接到Neck部分。其次,为使模型更加专注小目标,添加一个步幅为4的输出层作为新的头部。同时优化模型对较大车辆目标的检测较少,我们去除掉了Head中输出特征图为20 × 20的检测头。同时,考虑到模型的推理速度,将Neck部分的C3模块替换为更轻量化的DS_C3模块。最后,为了进一步提高基于IOU损失函数的性能,将CIOU替换为α-IOU。本文使用VisDrone2019数据集,并基于改进算法和原始算法分别进行了实验,结果表明,本文的算法能够对对小目标进行有效的实时检测。
Abstract:
Today, unmanned aerial vehicles (UAVs) are gradually being used in various fields, such as traffic monitoring and smart parking, where real-time monitoring and classification of vehicles is one of the key tasks. There are many challenges in vehicle detection, such as changes in flight angle when small vehicle targets and drones are working, resulting in changes in target scale, which puts a burden on the optimization of vehicle detection network models. In addition, due to the small aerial image target and fewer extractable features during high-altitude flight, the model detection accuracy is low. To solve the above problems, this paper aims to propose an accurate, efficient and real-time vehicle detection network based on the YOLOv5 algorithm. First, in order to make the model better extract small target features, a new connection layer is added to the Neck part, connecting the high-resolution feature mapping of the first C3 layer to the Neck section. Second, to make the model more focused on small targets, an output layer with a stride length of 4 is added as a new head. At the same time, the optimization model has less detection of larger vehicle targets, and we remove the detection head with an output feature map of 20 × 20 in Head. At the same time, considering the inference speed of the model, the C3 module of the Neck part was replaced with a more lightweight DS_C3 module. Finally, to further improve the performance of the IOU-based loss function, the CIOU is replaced with a α-IOU. This paper uses the VisDrone2019 dataset and conducts experiments based on the improved algorithm and the original algorithm, and the results show that the algorithm in this paper can effectively detect small targets in real time.
1. 引言
近年来,无人机(UAV)普遍被应用于各个领域,例如农业中的无人机农药喷洒、快递行业的无人机送货和智慧交通中的智能停车。由于其灵活性,无人机可以从不同的位置、高度和角度使用高分辨率相机收集数据。同时,由于硬件计算能力和人工智能的发展也促进了无人机的实际应用。在交通领域,迸发了许多创新研究,本文重点关注智慧交通中的车辆检测,它也是道路和城市交通检测的第一步 [1] 。
针对无人机航拍图像中的车辆检测目标,由于相机角度和无人机高度、目标的大小急剧变化,同时,复杂的背景、光照强度以及目标不同外观等因素都会导致无人机拍摄的图像普遍都存在高分辨率、背景复杂、目标较小和微小目标聚集等特点。为此,针对这些问题。研究者们对目标检测器不断的进行改进。例如,Zhu X等 [2] 以YOLOv5为基础,通过在Neck部分融入注意力机制并增加检测头,使得该模型的精准度大大提升。Mahaur [3] 通过改进YOLOv5Neck部分并融入空洞卷积,在未显著增大模型的情况下,提升网络的精准度。Wang T [4] 等人针对多尺度目标的检测精度低、目标特征信息易丢失等问题。在YOLOv4的基础提出了上一种先验增强的PETNet网络。为了解决小目标过采样而导致特征丢失的问题,Li R. & Shen Y [5] 在输入端对图像进行超分辨率处理,并以YOLOv5模型为基础进行改进,提出了YOLOSR-IST网络。Huang Y [6] 等将transformer融入YOLOv5Backbone部分,使模型充分提取小目标特征。Cui,M [7] 等人出基于改进的YOLOv4-tiny,该模型使用轻量级和增强的ShuffleNet取代默认的骨干网络,并使用交叉熵损失函数,使该模型相比较基模型更为准确。此外,Zhou J [8] 等人在YOLOv5的基础上通过增加特征融合层,并添加注意力机制,来解决目标遮挡与复杂背景的问题。以上方法对小目标检测具有重要意义,大多数方法都提高了准确度,但存在模型较大导致推理速度慢的问题。再加上无人机上携带的计算资源有限,因此提升模型检测精度和模型轻量化,是本文的研究重点。
2. YOLOv5网络模型介绍
目标检测方法主要分为单阶段两阶段方法,其中经典的两阶段检测方法主要有R-CNN系列 [9] [10] [11] ,单阶段检测方法的代表为SSD [12] 以及YOLO [13] [14] [15] 系列。YOLO系列检测方法一直保持更新换代。YOLOv5 (You Only Look Once)模型在2020年5月由Ultralytics提出,模型在工业界被广泛使用。该模型是以YOLOv4为基础改进而来的一阶段检测器,YOLOv5有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型。其中,YOLOv5s的权重文件仅为上一代模型的1/9,其结构也更加小巧,其网络模型结构如图所示。为了平衡精度和速度,本文选择YOLOv5s作为基础算法模型。
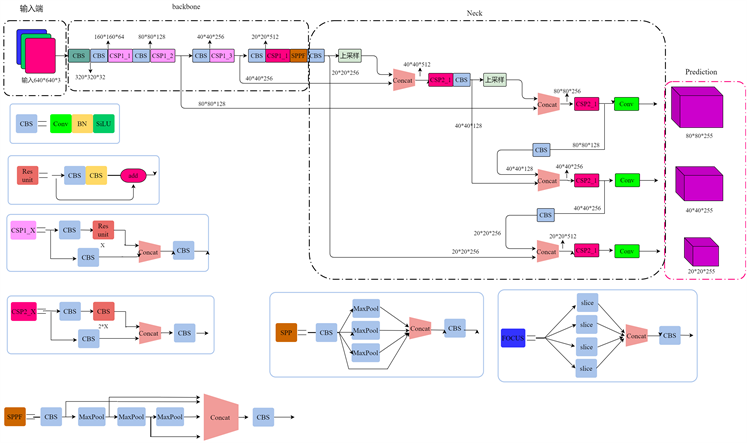
Figure 1. Structure diagram of the YOLOv5 network model
图1. YOLOv5网络模型结构图
由上图1可知,该模型主要分为Input、Backbone、Neck和Prediciton四个部分。
Input端由Mosaic数据增强、图片尺寸处理、自适应锚框计算三个部分组成。与YOLOv4相同,YOLOv5使用Mosaic进行数据增强,该方法对小目标检测有显著效果,符合本文对无人机航拍图像的这种小目标检测的需求。
Backbone是网络的主干部分,主要负责特征提取,其中包括一系列的卷积层和C3层,卷积层由卷积、batch normalization (BN)层和Sigmoid Linear Unit (SiLU)激活函数三个部分组成。此外,C3模块包括三个卷积层和一系列的瓶颈模块,这些模块减少了模型的参数和计算量。在Backbone的末端,为SPPF模块,它融合了不同分辨率的特征,该模块包含三个最大池化层和卷积层,在这些模块的作用下,网络能够提取更多特征信息。
Neck处于Backbone与Prediciton之间,由The Path Aggregation Network (PAN)组成,它聚合了Backbone从不同阶段提取的特征。由于Backbone浅层部分,特征图的空间特征很强,但语音特征较弱。而Backbone深层部分则具有丰富的语义特征而缺乏空间特征。路径聚合网络(PAN)将不同阶段的特征图按两个方向(从上到下和从下到上)进行连接,从而获得较强的空间信息和语义信息的特征图。
Prediciton单元预测三种不同尺度的特征图,默认的输出尺寸为20 × 20、40 × 40、80 × 80。多尺度目标检测有助于检测出图像中的大、中、小目标。最后,使用非极大值抑制(NMS)计算出每个目标最精确的边界框。
3. 改进YOLOv5以实现高效的实时航拍车辆检测
3.1. 改进思路
与自然图像相比,无人机航拍图像的目标信息一般较小,并且,由于飞行过程中相机轻微抖动,导致拍摄图像模糊使小目标特征不能被充分提取等问题。为了解决这些问题,常用的方法是对模型进行改进,例如改变损失函数、修改模型结构、增加注意力机制、优化检测锚框等。而很少将模块轻量化融入模型中,因为往往在修改的过程中往往不能使精度和速度达到平衡。YOLOv5在进行自然图像检测上有较好的效果,而航拍图像大多是为小目标,原始YOLOv5模型用于无人机航拍图像检测时,模型提取到的小目标特征较少,所以实际效果并不理想。为此,对YOLOv5模型进行了以下改进:
1) 为了提高模型对小目标特征的提取与融合能力,添加一个步长为4的检测头,同时,为了由于目标中很少有大目标并且防止模型过大影响推理速度,去除步长为32的输出层及在Neck部分的对应层。
2) 由于模型添加新的检测头,模型变大,为防止严重影响模型的推理速度,将C3原始BottleNeck替换成为DC_C3,达到模型精度与速度的平衡。
3) 为了进一步提高基于IOU的损失函数的效率,将原始模型的C-IOU替换为 -IoU。
3.2. 小目标检测头
航拍图像由于包含较多小目标,而YOLOv5原始模型包含下采样模型,随着模型的深入,小目标特征丢失越来越多,即模型的Neck部分并未充分提取到网络浅层空间特征,为了改善这个问题,将第一个C3层的高分辨率特征映射连接到Neck部分,即在Neck部分添加卷积、上采样、连接和C3层,这有效的保留了空间特征。同时,增加一个输出特征图为160 × 160的检测头,并且为了使模型对小目标更为敏感,去除输出特征图为20 × 20的检测头,并删除其相关模块。这使模型更加专注小目标同时使模型结构的改变对模型的推理速度影响较小。其具体改进如图2所示。
3.3. DS_C3模块
由于网络层数增加,减缓了模型的推理速度,为了使改进对模型的实时检测能力影响最小化,将原始YOLOv5中的BottleNeck模块进行改造为BottleNeck_DSConv,即将其中的将普通卷积替换为DSConv。DSConv是Marcelo Gennari [16] 在2019年ICCV中所提出的,该结构为卷积层的变体,相比原始卷积层,改变体牺牲了部分精度换来了速度的提升。DSConv将传统的卷积内核分为两个组件:可变了化内核(VQK)和分布偏移,通过在VQK中仅储存整体数值来实现较低的储存器使用并较高的运行速度,同时通过应用基于内核和基于通道的分布偏移来保持与原始卷积的输出。DSConv替换YOLOv5中的BottleNeck中的卷积层,增强了模型的推理速度,虽然精度有所下降,但这是值得的。DSConv结构如图3所示。

Figure 2. YOLOv5 improves the network model structure diagram
图2. YOLOv5改进网络模型结构图
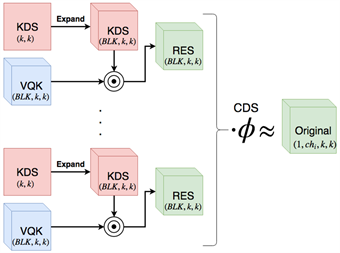
Figure 3. DSConv model structure diagram
图3. DSConv模型结构图
3.4. 替换损失函数
YOLOv5的损失函数由三个不同部分组成,边界框回归损失、置信度损失和分类损失,置信度损失和分类损失采用二元交叉熵损失函数,而边界框回归损失函数默认为C-IOU。C-IOU的计算公式如下:
(1)
(2)
(3)
其中,b和bgt分别为预测框和Ground Truth的中心坐标,
表示两点的欧氏距离,c为两框之间最小的边界框的对角线长度,
为正参数,v表示两框长宽比的一致性,
、h和
、
分别为预测框的长宽和Ground Truth的长宽。虽然C-IoU的收敛速度和精度相比IOU有所提高,但在小目标数据集上,α-IoU效果优于C-IoU,并且在模型上具有更好的鲁棒性。所以,为了提升模型精度,将C-IoU进行替换,其中,α为权重系数。同时,经实验分析,α = 2时模型精度提升最为显著。α-IoU的计算公式如下:
(4)
4. 模型训练
4.1. 数据集
使用的数据集为公开数据集VisDrone2019,该数据集包含6471张训练图像,548张验证图像和1610张测试图像。该数据集包含10个类。为了专注于车辆检测,只使用其中Car、Van、Bus和Truck 4个类别对网络进行训练和评估,数据集中没有删除任何图像。
4.2. 实验环境
本实验所使用的软硬件环境如表1所示,训练参数如表2所示。

Table 1. Experiment environment configuration table
表1. 实验环境配置表
Table 2. Table of training parameters
表2. 训练参数表
5. 实验结果与分析
5.1. 评估指标
使用的评估指标为精确率(Precision)、召回率(Recall)、平均精确率(Mean Average Precision)。其中TP表示被模型正确识别为车辆的目标数量,FP表示被模型错误识别为车辆的目标数量,FN表示模型遗漏识别车辆的目标数量。因此,精确率表示模型正确识别车辆占所有识别为车辆的所以目标的比例,召回率表示模型正确识别为车辆的目标数量占数据集中所有车辆的比例,N表示为类的数量。
表示第i类在不同IoU阈值上的平均精度。我们使用mAP50和mAP95来评估模型的准确度。
(5)
(6)
(7)
5.2. 实验结果与分析
为了验证改进算法的效果,模型的超参数设置都相同,不同改进对模型检测车辆能力的影响如表3、表4所示。在VisDrone2019数据集的四个类别中,相比于原始模型,改进后的模型对车辆的检测能力和在密集场景下的效果显著提升。效果如图4、图5所示。
从表3中可以看出,每个模型对模型检测性能均有提升。由于VisDrone2019数据集中小目标较多,原始模型在进行逐层卷积下采样后,小目标特征丢失较多,将第一个C3层的高分辨率特征映射连接到Neck部分后并增加小目标检测头,模型的小目标检测性能大大提升。改进后,模型的mAP50和Map95分别提高了6.24%和4.93%。这表明了新的高分辨率特征图拼接层和小目标检测头的重要性。 -IoU替换C-IoU后提升了模型的检测精度,并且改进后对模型的推理速度影响较为微小。DS_C3的替换,虽然模型的检测精度有所下降,但模型的推理速度有所提升,所以改进是有效的。为了得到更好的效果,将两两改进组合使用,实验结果表明,两两改进组合结合了各自的优点,模型的检测精度均有明显的提升。最后,将三种改进同时融入模型,与原始模型相比,新模型的精确率提高了3.31%、召回率提高了7.03%、mAP50和Map95分别提高了6.41%和5.32%,并且,修改后的模型相比于原始模型虽然FPS有所下降,但与未加入DS_C3的模型相比,FPS提升了4.28,同时,新模型的FPS达到了94.26,具有实时检测能力。说明总体改进方法是有效的。
Table 3. Table of the effects of different modifications on model accuracy
表3. 不同修改对模型精度的影响表
Table 4. Each category is in the mAP50 table on two models
表4. 每个类别在两个模型上的mAP50表
6. 结论
本文提出了一种基于YOLOV5s的改进模型,用于无人机航拍图像中的实时车辆检测,并且在VisDrone2019数据集中进行了评估。与原始模型相比,所提出的方法进行了以下修改:1) 添加一个新的检测头来检测小目标同时改进了网络的Neck部分以获得更好的特征图。2) 边界框回归损失函数替换为自适应损失函数来提高模型的检测性能。3) 将Neck部分的C3替换为DS_C3,提高模型的推理能力。总体来说,修改的模型的检测性能相比原始模型具有显著提升。在后续的工作中,继续着重对模型的轻量化,实现在计算能力较差的设备上运行。