1. 引言
研究卷积型Volterra积分微分方程(下面简称为卷积型VIDE)的快速算法,其方程形式如下
(1)
其中
,
是区域
上的连续函数,这些条件保证了式(1)解的存在唯一性 [1] 。
由于卷积型VIDE在生物学、经济学中有着广泛的应用,如计算生物学 [2] 、风险管理 [3] 等,因此对卷积型VIDE解的研究受到大量学者的关注。通常情况下,方程(1)的解析解很难求出,因此研究该方程的数值解法具有重要意义。迄今为止,国内外研究者提出和改进了很多有效求解VIDE数值解的方法,如差分求积法 [4] 、龙格–库塔法 [5] 、可约求积规则 [6] 、一般线性法 [7] [8] 、伽辽金法 [9] [10] 、配置方法 [1] 等。在文献 [10] 中的配置方法是显式类型的求解格式,可以逐步求解得到整个
在I上的数值逼近。 [11] 中的数值稳定性分析表示一些特殊的配置节点选取,可以导出
稳定方法。此外,VDIE稳定数值解的另一种方法是使用超隐式技术 [12] 。通过使用下一个子区间的配置节点和Hermite-Birkhoff插值来研究求解非判别和刚性VIDE的多步配置方法。研究发现,使用计算的配置点明显扩大了稳定域。
在本文中,我们使用广义多步配置方法求解卷积型VIDE,广义多步配置方法通过在大区间上划分均匀网格,使用子区间两侧的网格节点构造局部多项式,类似的方法已经广泛用于Volterra积分方程中 [13] [14] [15] [16] ,这种方法具有简洁的形式,在不改变线性系统维度的情况下能够取得较高收敛阶的数值解。根据离散时产生线性系统的结构研究他的快速算法。在第2节中,构造求解卷积型VIDE的广义多步配置方法,分析求解卷积型VIDE的广义多步配置方法产生线性系统的结构,并结合GMRES [17] 算法得到快速求解算法。在第3节中,我们使用数值算例验证数值方法的高效性。
2. 快速广义多步配置方法
考虑使用广义多步配置方法
离散Volterra积分微分方程。设均匀网格
,其中步长
。基于
,定义局部基函数
(2)
进而导数在
上的导数
具有如下表示
(3)
其中
,
是非负整数。
在
上对(3)积分
(4)
其中
,
。为了描述方程,定义下列符号
,
。
进而我们得到
注意到
(5)
因此,我们有,
(6)
其中
表示元素全是1的N行1列的列向量,上述矩阵描述中
,
。注意到
,
,
。
当
时,
,进而
,因此,式(6)可以写为如下形式,
(7)
即
,其中
是Toeplitz矩阵,其第一行元素为
,第一列元素为
,
,
,
是Toeplitz矩阵,其第一行元素为
,第一列元素为
,
是稀疏矩阵,其非零元素及位置为
,
,
,
。
是Toeplitz矩阵,其第一行元素为
,第一列元素为
,
是稀疏矩阵,其非零元素及位置为
,
,
,
。注:上述过程中矩阵元素的选择参考Matlab矩阵元素的选取。此外在表1中,我们给出式子(7)中组成系数矩阵
的各部分矩阵的情况。

Table 1. Detailed table of matrices for each part during coefficient matrix P ^ decomposition
表1. 系数矩阵
分解时各部分矩阵详细表
其中,
对于Toeplitz矩阵,仅需要存储第一行和第一列即可,因此其存储量为2N。
如果不考虑
的结构,那么我们可以选择直接求解(6)式,需要
的计算量,或者使用迭代算法广义极小残差(GMRES)求解(6)式,其计算量主要来自于
与向量的乘法运算,因此需要
的计算量。根据表1可知,系数矩阵
由Toeplitz矩阵,稀疏矩阵,以及对角矩阵组合而成,充分利用
的结构,优化
与向量相乘时的计算量。
首先考虑Toeplitz矩阵与向量的快速计算,即根据已有的Toeplitz矩阵构造循环矩阵,进而通过快速Fourier方法计算。由Toeplitz矩阵T构造
,
将T与向量b的乘法嵌入式(8)计算,
(8)
其中,
是循环矩阵,与向量
的乘法使用快速Fourier方法计算,计算量为
。而稀疏矩阵与向量的乘法所需计算量为
,对角矩阵与向量的乘法也是
。进而
与任意向量H的乘法
可分为公式(9)中的5个步骤计算:
(9)
Table 2. Formula (9) Calculation amount for each step
表2. 公式(9)各步的计算量
如表2所示,我们给出了使用公式(9)计算
的各步骤的计算量,其中计算量最大的是Toeplitz矩阵与向量的快速计算,为
,其余矩阵与向量的乘积中,计算量均为
,因此使用公式(9)计算
的计算量为
。
进而我们考虑GMRES算法(如算法1所示),该算法中计算量主要来源于矩阵
与向量的乘法即第2行
与第4行
的计算,这个两步的计算量均为
。考虑矩阵
与向量的快速计算格式公式(9),结合GMRES算法,我们得到算法2所示的改进算法,进而可以将第2行
与第4行
的计算量降为
,从而优化整个算法的计算量。
Algorithm 1. GMRES algorithm for solving linear systems
算法1. GMRES算法求解线性系统
Algorithm 2. Improved algorithm for solving linear systems
算法2. 改进算法求解线性系统
Algorithm 3. UPDATA
algorithm
算法3. UPDATA
算法
3. 实例分析与应用
在本节中,我们通过数值算例说明改进算法求解线性系统(7)的高效性,实验主要对比GMRES求解线性系统(7)与改进算法求解线性系统(7)的CPU计算时间,收敛时的相对残差,迭代次数,迭代过程中的相对残差变化情况。
例:求解卷积型Volterra积分微分方程
其中
,其解析解是
。数值实验是在Matlab2019a中实现的,其中,给定收敛条件为相对残
,
Table 3. GMCM 0 , 2 : Comparison of GMRES and improved algorithm solution time
表3.
:GMRES与改进算法求解时长对比
Table 4. GMCM 1 , 1 : Comparison of GMRES and improved algorithm solution time
表4.
:GMRES与改进算法求解时长对比
对区间
作等距划分,取不同N,对于
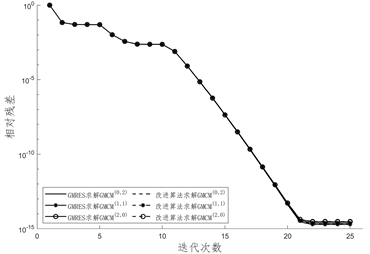
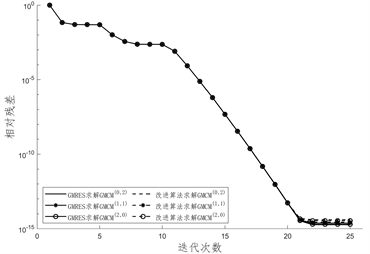
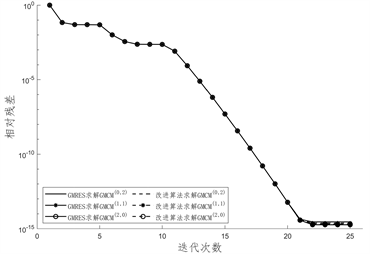
得到的线性系统分别使用GMRES算法和改进算法求解所得CPU计算时长如表3,表4和表5,图1给出了迭代过程中相对残差的变化情况,图2给出了两种求解算法的CPU计算时间。
从表3、表4和表5中可知对于指定算法结束条件相对残
,GMRES算法和改进算法结束时相对残差几乎相同,且迭代次数相同,但随N增大,改进算法的CPU计算时间会小于GMRES算法的
Table 5. GMCM 2 , 0 : Comparison of GMRES and improved algorithm solution time
表5.
:GMRES与改进算法求解时长对比
 (a) N = 100(b) N = 200
(a) N = 100(b) N = 200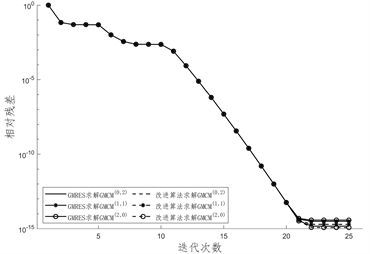
 (c) N = 400 (d) N = 800
(c) N = 400 (d) N = 800
Figure 1. Changes in relative residuals during the iteration process
图1. 迭代过程中相对残差变化情况
CPU计算时间,当N增大一倍,GMRES算法的计算时间增加倍数逐渐趋近于4,改进算法的CPU计算时间增长倍数逐渐趋近于2。
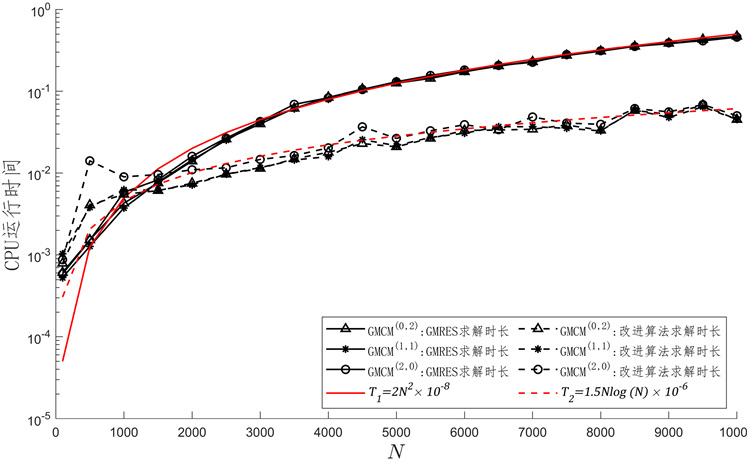
Figure 2. Comparison between GMRES and improved algorithms in solving problems
图2. GMRES 与改进算法求解时对比
图1给出迭代过程中相对残差的变化情况,针对本文所取的例子,不同方法获得的线性系统在求解过程中相对残差没有较大差距,且GMRES方法和改进算法的相对残差也没有较大差距。在图2中,我们绘制了GMRES算法与改进算法求解
的CPU计算时长,以及两条参考曲线
。当N增大时,GMRES算法的求解时间靠近
,改进算法的求解时间靠近
,也就是说GMERS的算法求解时间为
,GMRES的求解时间为
,验证了第1节GMRES算法的计算量为
,改进算法的计算量为
。而且
的值对GMRES和改进算法的CPU计算时间影响不大,两种求解线性系统的算法与线性系统的维度 有关。此外,从图中可知随着N变大,改进算法的计算时间小于GMRES的计算时间且改进算法的CPU计算时间的增长率小于GMRES,因此改进算法能够快速高效计算卷积型VIDE离散出的大型线性系统。
4. 结论
使用广义多步配置方法(
)离散卷积型VIDE,分析离散后的线性系统的结构组成,结合Toeplitz矩阵与向量的快速计算,进而得到系数矩阵与向量的快速计算。使用GMRES算法与快速计算格式结合,构建了一种适合求解该类线性系统的改进算法,改进后的算法的计算量只需
,比GMRES算法的计算量更小,从实验结果看,改进算法与GMRES算法在求解同一问题时,改进算法需要的求解时间比GMRES算法的求解时间更短,当N值增大时,改进算法在计算时间上更小,更具优势。因此改进算法可以高效求解这一类大规模线性系统。