1. 引言
随着互联网的发展,对在线评论进行情感分析逐渐显露巨大价值 [1] ,研究方法从机器学习 [2] [3] 发展到深度学习 [4] [5] 和预训练模型 [6] [7] 。随着研究的深入,细粒度情感分析逐渐走入研究视野,方面类别情感分析作为细粒度情感分析中的一个重要子任务,到目前为止已取得了广泛的研究关注 [8] [9] [10] 。旅游作为现如今人们放松身心的必要项目,近年来已取得飞速发展,根据国家统计局公布的数据显示,近十年我国住宿业营业额呈上涨趋势,在2021年我国住宿业营业额达到4071.59亿元 [11] 。对酒店在线评论情感分析,可进一步促进酒店行业发展,但目前对中文酒店评论进行情感分析的研究大多从粗粒度角度出发。邬小燕 [12] 通过改进Stacking中的SVM和KNN两个基分类器,以及改进TF-IDF加权方法,提高模型对酒店评论的情感极性分类效果。高华玲和张晶 [13] 将通用情感词典Hownet和酒店评论相关的评论领域专业词典进行结合,通过构建的领域情感词典对高端酒店评论进行情感分析并进行可视化展示,最终对高端酒店的经营策略给出可行建议。丁美荣等 [14] 提出两种方法对酒店评论进行情感分析,一种是基于扩展情感词典的方法,通过计算情感值进行分类,另一种是采用 双向长短时记忆模型(Bi-directional Long Short-Term Memory, BiLSTM)对预训练数据集进行情感分析。
基于以上研究,针对酒店评论情感分析,本文提出进行方面类别情感分析,并利用所提出的GCGAT (GTU-CNN-GRU-Attention)模型进行分析,该模型由四层网络构成,分别为:特征提取层、语义信息提取层、特征信息权重分配层和最后的全连接层。其中,特征提取层利用卷积神经网络(Convolutional Neural Net-works, CNN)和门控机制 [15] 对评论信息和嵌入方面类别的评论信息进行情感特征和方面类别特征提取;语义信息提取层利用双向门控循环单元(Bi-directional Gate Recurrent Unit, BiGRU)进行上下文信息的提取;特征信息权重分配层利用最大池化和注意力机制 [16] 引导权重分配;最终通过具有 输出的全连接层进行情感极性判定。在数据集方面,本文使用数据采集软件获取多平台的酒店评论作为原始数据,通过LDA-Jaccard主题模型对数据进行主题分析并确定方面类别,根据确定的方面类别对数据进行人工标注。本文主要贡献如下:
1) 利用LDA-Jaccard主题模型对预处理后的数据进行分析确定方面类别,建立了细粒度酒店评论数据集;
2) 本文提出对酒店评论进行方面类别情感分析,并提出基于门控机制和BiGRU的深度学习模型,该模型通过四层网络结构对评论中的情感特征、方面类别特征和上下文信息进行充分提取,并合理分配权重,有效提高了情感极性判定准确率;
3) 细粒度酒店评论数据集上的实验结果表明,GCGAT模型性能要优于其他模型。
2. 相关工作
2.1. 情感分析
在早期的情感分类任务中,研究学者主要运用基于统计的非深度学习方法进行研究,Kiritchenko [17] 通过使用基于SVM模型的词典、语法和n-gram特征方法进行情感分析,并在SemEval2014数据集上取得了最佳性能。王新宇 [18] 对旅游平台的线上评论进行研究分析,采用TF-IDF方法对各个特征分配权重,最后使用SVM作为分类器,对情感极性进行分类。由于Mikolov等 [19] 提出的word2vec模型提供了一种简单并有效的分布式表示方法,使深度学习方法在情感分析中得到了广泛的应用。徐菲菲和芦霄鹏 [20] 将注意力机制和最小门控单元MGU引入CNN,进行文本情感分析。Tang等 [21] 提出了一种联合方面类别的主题模型,并使用最大熵来提高方面类别情感极性分类的表现。Tang等 [22] 通过引入方面类别的词向量,并改进传统的LSTM模型,使模型达到在不使用情感词典情况下的最优结果。Xue和Li [23] 提出了一种有效的神经单元,通过将CNN和GRU结合使用,对原始文本词向量和带有方面类别的词向量同时进行处理,提高方面类别情感分类准确率。
2.2. 中文酒店在线评论情感分析
对中文酒店在线评论进行情感分析的研究中,Yao [24] 提出一种基于CNN-LSTM的模型对中文酒店评论进行情感分析。马桂真和彭霞 [25] 通过运用LDA主题模型与构建情感词典相结合的方法,对酒店评论数据进行游客关注的主题和情感倾向之间进行交叉挖掘分析。王宏鹏 [26] 分别提出构建酒店领域的情感词典和基于机器学习两种方法对酒店评论进行细粒度情感分析。池毛毛等 [27] 针对两大酒店预订平台上评论主题、主题社会网络和用户情感倾向的差异研究,提出基于LDA的主题社会网络和情感分析方法。
3. 模型
本文提出的基于门控机制和BiGRU的GCGAT模型由4层网络结构构成,分别为:特征提取层、语义信息提取层、特征信息权重分配层和全连接层。模型以CNN和BiGRU为主体,网络结构如图1所示。
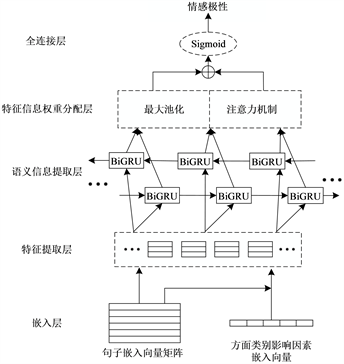
Figure 1. GCGAT model network structure
图1. GCGAT模型网络结构
3.1. 特征提取层
特征提取层为双通道结构,其中,通道1对句子嵌入矩阵进行特征提取,通道2对同时嵌入方面类别影响因素词向量的嵌入矩阵进行特征提取。通过卷积层进行特征提取,并使用门控机制控制输出,门控机制选择ReLU和GTU (Gated Tanh Unit) [28] 两种,其中GTU是基于门控机制所提出来的激活函数,将
激活单元与
激活单元相结合,不仅加快收敛速度,还提高模型性能,其计算公式如公式(1)。
(1)
根据激活函数的函数特性,通过GTU控制通道1的输出,得到情感特征,这样选择是因为细粒度酒店评论数据集中的情感倾向即包含负向情感倾向又包含正向情感倾向,而GTU激活函数的值域为(−1, 1)可以避免情感倾向的丢失,而对于方面类别,评论中只有包含和不包含两种情况,不包含即为0,包含即为大于0,这与ReLU激活函数的值域是相对应的,所以将使用ReLU控制通道2的输出,得到方面特征,之后将二者输出进行相乘得到既包含情感特征又包含方面特征的特征信息。其结构如图2所示。
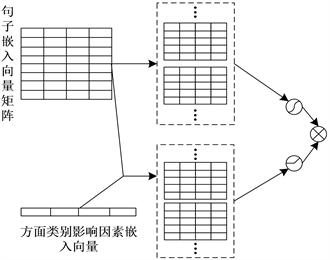
Figure 2. Feature extraction layer structure diagram
图2. 特征提取层结构图
3.2. 语义信息提取层
语义信息提取层由BiGRU构成,用来学习情感特征和方面类别特征的上下文信息,其具有两层GRU,一层从顺序数据学习信息,另外一层从反向输入数据学习信息。相较于传统循环神经网络(Recurrent Neural Networks, RNN)和长短时记忆网络(Long Short Term Memory Network, LSTM),GRU引入了复位门和更新门来控制其输入和输出,时刻结构如图3所示。
其中,
、
表示
时刻的输入,
、
表示
时刻的输出,参数更新公式见公式(2)、(3)、(4)、(5)、(6)。
(2)
(3)
(4)
(5)
(6)
其中,
,
,
和
是GRU的参数,
表示将
和
两个向量进行串联,
表示复位门,
表示更新门,
表示候选隐藏层,
表示元素乘法,
表示
函数,
表示
函数。
3.3. 特征信息权重分配层
特征信息权重分配层由最大池化和注意力机制组成,通过最大池化获得最关键的特征信息,注意力机制分配不同特征信息对方面类别情感倾向的影响权重,以此保证不漏掉关键信息。注意力机制运用交互式建模可以通过判定对方面类别的情感做出贡献多少来赋予合适权重,从而提高分类模型准确率,其计算方法如公式(7)。
(7)
其中,
表示注意力机制的输入向量,
表示文本中的每个键向量,通过进行
和
的相关性计算和归一化处理,得到
的注意力权重。
3.4. 全连接层
由于本文提出的方面类别情感分析任务是四分类任务,所以选择具有
输出的全连接层进行最终的情感极性判定,同时将特征信息权重分配层的输出结果进行拼接作为其输入。情感极性预测值
的计算公式如公式(8)。
(8)
其中,
表示第
个样本的预测值,
和
分别表示权重和偏置。
4. 数据
4.1. 数据获取
本文运用“八爪鱼”采集器这一数据采集软件从多个酒店预订平台获取酒店评论数据,酒店的价格区间设定为150~300元之间,酒店的范围包括北京、上海和深圳等一线城市。原始数据获取后通过数据清洗、数据去重、去除无效数据、以及去除数据长度大于300的数据后,最终获得一万四千条有效数据。
4.2. 数据集建立
将最终获得的酒店评论数据进行分词和去停用词,分词选择jieba分词方法,停用词表选择哈工大停用词表、中文停用词表和百度停用词表的结合停用词表。将去停用词后的分词结果构建为词典,用于LDA-Jaccard模型训练,在1~20个主题个数之间选择最佳主题个数。训练结果如图4所示。
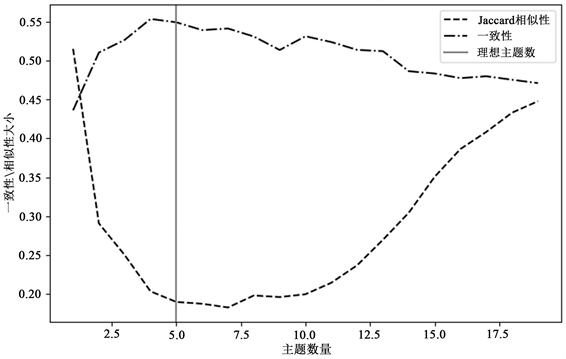
Figure 4. Topic-consistency, similarity change map
图4. 主题–一致性、相似性变化图
根据图4,一致性得分会随着主题数的增加先升高后趋于平稳,这是因为当主题数达到一定时,主题内部一致性会达到最高,再继续进行主题划分对一致性得分并不会产生太大影响,但会使主题之间产生交叉,为避免这种情况的出现,本文引入了Jaccard相似性的计算,通过计算主题之间的Jaccard相似性,来判断主题之间的交叉程度。当主题数量为5时,一致性得分与Jaccard相似性值之间的差值达到最大,并且此时的一致性得分趋于平缓,Jaccard相似性值接近最低,说明当主题数为5时,各主题内部的一致性达到稳定变化,主题之间的交叉程度接近最低,所以选取5个主题是合理的。此时,各主题下频率最高的25个词如表1所示。

Table 1. High frequency words for each topic
表1. 各主题下的高频词
根据表1,经过综合考虑将5个方面类别名称分别定为环境好、服务周到、位置优越、交通便利和干净整洁,并确定每个方面类别的影响因素如表2所示。
Table 2. Various categories of influencing factors
表2. 各方面类别影响因素
在数据标注过程中,每一个方面类别都包含4种标签,其中,−2代表不涉及这一方面类别,−1代表消极情感倾向,0代表中性情感倾向,1代表积极情感倾向。
5. 实验与分析
5.1. 参数设置与评价指标
本文选择word2vec模型训练词向量,模型参数设置为:词向量维数为300,训练算法选择skip-gram算法,窗口大小为15,训练轮数为20,最小词频为5。将训练好的词向量作为GCGAT模型的输入进行训练,由于有5个方面类别,所以本文选择将每个方面类别训练一次,最终得到5个训练好的模型和结果。评价指标选择Acc值和F1值,以及ROC曲线和auc值。Acc值和F1值的计算公式为公式(9)、(10)。
(9)
(10)
其中,公式(9)中的指标分别为:
表示真正例,即预测为正例实际也为正例;
表示真负例,即预测为负例实际也为负例;
表示假正例,即预测为正例而实际为负例;
表示假负例,即预测为负例而实际为正例。公式(10)中的
表示精确度,
表示召回率,二者计算公式为公式(11)、(12)。
(11)
(12)
auc值定义为ROC曲线下与坐标轴围成的面积,ROC曲线的横坐标为假阳率,即真负例中判为正例的概率,纵坐标为真阳率,即真正例中判为正例的概率,与召回率相同。
模型优化器选择Adam优化器,学习率设置为0.0001,为避免过拟合,模型选择Spatial Dropout 1D [29] 和Dropout,二者值均设置为0.2,Spatial Dropout 1D用于对包含情感特征和方面特征的特征信息进行处理,Dropout用于对包含情感特征、方面特征和上下文特征的特征信息进行处理。由于模型是多分类模型,所以损失函数选择分类交叉熵,计算公式为公式(13)。
(13)
其中,
表示句子编码,
表示分类编码,
表示目标分类,
表示预测分类。
5.2. 对比实验
本文选择对比的模型包括:SVM,CNN,GRU,BiGRU,BiLSTM-aspect,和GCAE [9] ,其中-aspect表示模型输入的词向量是包含方面类别影响因素的词向量,模型对比实验结果的准确率见表3,F1值见表4。
Table 3. Comparative experimental accuracy
表3. 对比实验准确率
Table 4. The F1 values of the experiment were compared
表4. 对比实验F1值
由表3和表4可以发现,SVM作为机器学习中的一种经典算法,在服务周到、交通便利和干净整洁这三个方面类别中准确率和F1值甚至比CNN和GRU的更优,并且准确率和F1值在服务周到这一方面类别上分别为0.9405和0.9417,在交通便利这一方面类别上分别为0.9119和0.9141,在干净整洁这一方面类别上二者均取得最优结果,分别为0.9582和0.9595。CNN的准确率和F1值在服务周到这一方面类别上结果更好,分别为0.9108和0.9088,计算得出比GRU的准确率和F1值分别提升了2.1%和2.7%。BiGRU的准确率比GRU平均提升了3.6%,F1值比CNN平均提升了4.7%,并且在服务周到这一方面类别上取得了最优结果,准确率和F1值分别为0.9526和0.9513,相较于SVM,分别提升了1.2%和1%。BiLSTM-aspect基于BiLSTM引入了方面影响因素词向量,使模型分类结果进一步提升,其准确率相较于SVM平均提升了3.8%,F1值相较于CNN平均提升了4.8%,在服务周到和干净整洁这两个方面类别上准确率和F1值均达到了0.95以上。GCAE模型通过门控机制控制方面信息和情感信息的获取,极大提升了CNN的准确率和F1值,结果分别平均提升了5.4%和5.9%,在位置优越这一方面类别上F1值比BiLSTM-aspect的F1值提升了2.5%。同时,可以发现各模型在此数据集上的准确率和F1值都达到了0.8左右,甚至超过0.9,这说明该数据集的有效性。再将本文提出的深度学习模型GCGAT模型与这些模型的结果进行对比发现,GCGAT模型的准确率和F1值均有所提升,通过计算得出,比GRU的准确率平均提升了6%,比BiGRU的准确率平均提升了2.4%,比GCAE的准确率平均提升了1.6%,并且在各方面类别情感分类中的准确率都达到了0.9以上,在干净整洁这一类别中最高,达到了0.9796。GCGAT模型的F1值比SVM的F1值平均提升了5.2%,比CNN的F1值平均提升了6.8%,比BiLSTM-aspect的F1值平均提升了2%,在服务周到、交通便利和干净整洁这三个方面类别上均达到了0.95以上,虽然在环境好这一方面类别上的结果最低,但是仍达到了0.8995,证明了GCGAT模型的有效性。
进一步可以发现,模型在服务周到和干净整洁这两个方面类别上面的准确率和F1值比其他方面类别上面的准确率和F1值会更高,这可能是因为在标注服务周到和干净整洁这两个方面类别情感倾向时,评论中这两个方面的影响因素表示明确,而其他的方面类别情感倾向在标注过程中可能会因为评论的模糊而存在一些混淆,是模型在进行分析时产生偏差。
接下来选择SVM,BiLSTM-aspect和GCGAT作为对比模型与GCGAT模型比较ROC曲线和auc值,这样选择是以SVM代表机器学习,BiLSTM-aspect和GCGAT代表深度学习并且嵌入方面类别词向量。由于本文为多分类任务,所以在绘制ROC曲线和计算auc值时选择“micro”模式,并且将五个方面类别分类情况放在一起考虑,得到整体的假阳率和真阳率。由图5可以看出GCGAT模型取得了更好的效果,auc值达到了0.99,说明模型可以有效的将情感极性判定正确。BiLSTM-aspect模型也取得了很好的效果,auc值为0.97,说明考虑上下文信息很重要。
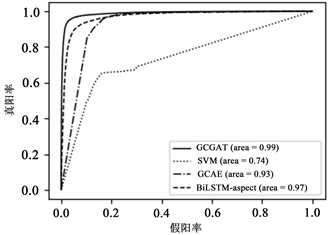
Figure 5. ROC curve comparison diagram
图5. ROC曲线对比图
5.3. 消融实验
为了检验GCGAT模型中引入的方面类别影响因素词向量、GTU激活函数、BiGRU和注意力机制的有效性,接下来对GCGAT模型进行了消融实验。其中,GCGAT/GTU模型是指将GCGAT模型中的GTU激活函数替换为tanh激活函数;GCGAT/BiGRU模型是指将GCGAT模型中的BiGRU去除;GCGAT/aspect模型是指将GCGAT模型中的方面类别影响因素的词向量去除;GCGAT/attention模型是指将GCGAT模型中的attention机制去除,仅通过最大池化保留关键的信息。实验结果的准确率见表5,F1值见表6。
Table 5. Accuracy of ablation experiment
表5. 消融实验准确率
Table 6. F1 of ablation experiment
表6. 消融实验F1值
通过表5和表6可以得出,方面类别影响因素向量和注意力机制的引入会对准确率的提升产生更大的影响,而GTU激活函数的引入会对F1值的提升产生更大影响,同时BiGRU的引入在环境好和位置优越这两个方面类别上对F1值的提高也起到了巨大作用。根据计算得到,GCGAT模型的准确率比GCGAT/aspect模型的准确率平均提高了1.5%,比GCGAT/attention模型的准确率平均提高了1.4%,并且均在环境好这一方面类别上提升最多,比GCGAT/aspect模型提升了2.1%,GCGAT/attention模型提升了2.3%。GCGAT模型的F1值比GCGAT/GTU模型的F1值平均提高了3.1%,并且也在环境好这个方面类别中提升最多,提升了4%,同时在位置优越这一方面类别上提升了3.7%。通过与GCGAT/BiGRU模型进行比较,GCGAT模型在环境好和位置优越这两个方面类别情感分析中的F1值分别提升了2%和1%。
根据上述分析可以总结出,由于此时模型提取了方面类别特征和与方面类别特征相关的情感特征,考虑了评论中的上下文信息,最后保留最重要的特征信息以及其他关键信息,并利用这些信息进行情感极性判定,这样做使方面类别与其情感倾向更加匹配,极大地提升了模型性能。
6. 结论
本文从方面级情感分析中的方面类别情感分析出发,提出一个同时融合方面类别信息,情感信息和上下文信息的深度学习模型GCGAT模型,并通过该模型对中文酒店评论进行方面类别情感分析。该模型有四层网络结构,分别为:特征提取层、语义信息提取层、特征信息权重分配层和全连接层,主体由CNN和BiGRU构成,通过并列使用两个卷积层同时提取评论中的情感特征和方面类别特征,将两种特征合并后,通过BiGRU学习合并特征在评论中的上下文的信息,运用最大池化保留的最重要的特征信息和注意力机制保留的其他关键信息,最后将全部信息输入到全连接层中进行方面类别的情感极性判定。在数据集方面,本文运用LDA-Jaccard模型对经过预处理的数据进行分类并确定方面类别,在此基础上进行数据标注。通过与其他模型进行对比,可以发现GCGAT模型取得了更好的结果,准确率比BiGRU的准确率平均提升了2.4%,同时,在全部方面类别上均达到了0.9以上。F1值比BiLSTM-aspect的F1值平均提升了2%,在服务周到、交通便利和干净整洁这三个方面类别上均达到了0.95以上。并且GCGAT模型在干净整洁这一方面类别上得到了最优结果,准确率达到了0.9796,F1值达到了0.9753。目前预训练模型在自然语言处理任务中取得了广泛并有效的使用,所以,在未来工作中将研究将预训练模型引入到酒店评论方面及情感分析当中。