1. 引言
在图像库中快速有效的检索到用户想要的图像,是很有价值的商业应用。已有许多图像检索算法被提出,而基于深度学习的图像检索技术取得了巨大进展。深度学习通过学习图像的特征表达,提取高级语义特征,相比传统的基于统计特征的图像检索,取得了较高的检索精度。Zhou等人 [1] 提出一种基于深度神经网络的图像检索方法,该方法采用卷积神经网络提取图像特征,并使用倒排索引进行检索。国外的Lowe等 [2] 学者则提出了基于局部不变特征的图像检索方法,该方法能够在旋转、平移等变换下依然能够提取出具有区分性的特征,实现了更加鲁棒的图像检索效果。2018年,中国科学院计算技术研究所的Liang和他的团队 [3] 提出了一种基于多特征融合的图像检索算法。该算法将多种特征融合在一起,包括局部特征、全局特征、颜色特征和纹理特征等。该算法利用深度学习方法进行特征提取,并采用对抗网络对图像进行重构,使得提取的特征更加具有代表性。在多个数据集上的实验结果表明,该算法能够取得较好的检索效果。董华、王涛等 [4] 学者则在卷积神经网络的不同层次提取不同的特征进行融合,实现了更加准确的图像检索结果。与单特征算法相比,多特征融合算法具有更强的鲁棒性和抗干扰能力,可以有效地解决特征冗余和过拟合等问题,同时也可以克服图像尺度变化和目标相似性等问题,从而提高检索结果的准确性和鲁棒性,渐成图像检索算法主流。Wu等人 [5] 研究利用多层特征融合的方法,包括全局特征、局部特征和颜色特征等。与其他方法相比,该算法在特征提取时使用了多个卷积神经网络,而且使用了反卷积神经网络进行图像重构,提高了特征的鲁棒性和鉴别性。在多个公共数据集上的实验表明,该算法在精度和效率方面都优于其他方法。除此之外,还有许多其他的多特征融合算法应用于图像检索中,比如基于视觉词袋模型的多特征融合算法 [6] 、基于卷积神经网络的多特征融合算法 [7] 等等。
但前述多特征融合的图像检索方法没有很好地区分图像中不同区域和内容的重要性。这会导致计算资源分配不合理,并且检索结果的准确率会受到影响。为了解决上述问题,本文提出了一个融合注意力特征的图像检索算法。该算法使用ResNet [8] 网络提取图像的特征,使用GAM注意力提取图像的重要信息,GAM注意力机制 [9] 可以学习到全局特征信息,从而增强网络对输入图像的泛化能力,同时通过GAM注意力机制,网络可以更加聚焦于重要的特征通道,避免了过多地关注无用特征通道。算法将原始特征与通过GAM模块获取的特征融合,使图像中的关键部分得到更多的关注。
2. 模型设计
2.1. GAM注意力机制
GAM注意力机制是一种用于图像分类和目标检测任务的注意力机制,旨在提高神经网络对图像中重要区域的关注度。GAM机制通常用于在特征图上进行全局加权操作,以获取图像中最具有代表性的特征。
与其他注意力机制不同,GAM机制是一种全局操作,它通过考虑整个特征图而不是单个通道来计算每个通道的权重,GAM由通道注意力和空间注意力模块组成。具体来说,对于给定的特征图,GAM会首先将其压缩为一维向量,然后使用一个全连接层来学习每个通道的权重。这些权重随后被应用于特征图上,以加权对应通道的每个特征。最终,加权的特征被级联在一起形成全局特征表示,该表示被馈送到分类器中以进行分类。GAM注意力结构图如图1所示。
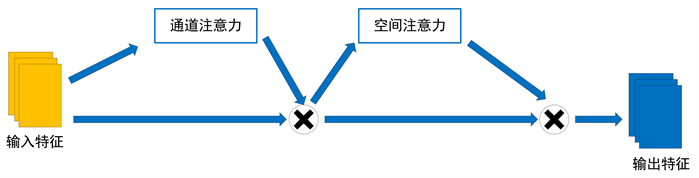
Figure 1. GAM attention structure diagram
图1. GAM注意力结构图
通道注意力结模块采用三维数组来保留三个维度上的信息,从而实现通道注意力。一个包含两个层的多层感知器(MLP)被用于放大通道与空间之间的依赖性。(MLP是编码–解码结构,类似于BAM,且其压缩比为r) 该通道注意子模块的结构如图2所示。
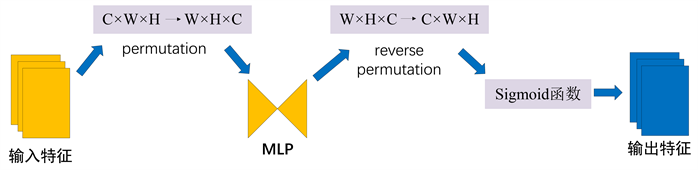
Figure 2. Channel attention structure diagram
图2. 通道注意力结构图
为了关注空间信息,空间注意力子模块使用两个卷积层进行空间信息融合,并从通道注意力子模块中使用了与BAM相同的缩减比r。由于最大池化操作减少了信息的使用,产生了消极的影响,因此该模块删除了池化操作,以进一步保留特性映射。空间注意力子模块示意如图3。

Figure 3. Spatial attention structure diagram
图3. 空间注意力结构图
GAM注意力机制的主要优点在于,它可以将注意力集中在最具代表性的特征上,从而提高模型的分类准确率。此外,由于GAM机制是一种全局操作,因此它可以自适应地计算每个通道的权重,而不受任何先验假设的约束,从而提高了模型的灵活性和鲁棒性。
2.2. 系统模型
系统的骨干网络采用Resnet50,采用Resnet作为骨干网络是因为其实分类网络的标准架构,系统模型结构即为Resnet50 + GAM。
3. 实验
3.1. 数据集与实验配置
采用COREL-10K数据集 [10] 。该数据集包含10,000张图像,涵盖了100个类别,每个类别有100张图像。这些图像涵盖了许多不同的主题,如动物、自然风景、建筑、运动、人物等,被用于许多不同的任务,如图像分类、图像检索、目标检测、目标跟踪等。
实验环境设置。操作系统为Ubuntu 16.04.7 LTS,Pytorch深度学习框架,版本为1.12.1 + cu116,GPU 为 NVIDIA Tesla T4 16G,运行系统为文理学院高性能服务器的一部分。
实验参数在Resnet50上微调,GAM参数的学习率为Resnet50参数的10倍,训练轮数为200 epochs。
3.2. 评价标准
采用工程上广泛应用的重要评价指标:Top-K分类精度(precision)。计算公式为:
(公式1)
检索出的前
个图像中,只要有一幅图像与检索图像标签相同,那么
。本实验检索标签为图像的类别。
3.3. 实验比较
为验证GAM注意力机制的有效性,我们研究了不使用注意力机制和GAM注意力机制与SENet [11] 、CBAM [12] 这两种常见注意力机制应用在图像检索上检索精度的对比。即Resnet50 + GAM与Resnet50、Resnet50 + SENet注意力机制和Resnet50 + CBAM注意力机制的对比。检索结果如下表1:

Table 1. Comparison of retrieval accuracy
表1. 检索精度对比
可以看出Resnet50 + GAM同其他三种方法比较,Top-1和Top-10上精度都是最高的,只是在Top-10上精度提升没那么明显,但在参数大小上Resnet50 + GAM几乎是其他三种方法的六倍,这也是本文模型精度更高的原因,也同当前大模型(如GPT)趋势一致。
4. 结束语
本文提出了Resnet + GAM网络模型,该模型把从ResNet50提取的特征通过GAM注意力机制进行特征融合,让模型学习到图像重要部分的关注,从而提高图像检索的性能。实验结果表明,与Resnet和SENet、CBAM注意力机制相比,本文模型有更高的检索精度。
基金项目
湖南省教育厅科学研究项目:2019年湖南省教育厅科学研究项目“基于三维建模的旅游图像处理技术研究”(19C1276);2017年湖南文理学院博士科研启动项目“旅游图像处理技术研究”(E07017005)。
参考文献